Introducción a Semantic Kernel para los entusiastas de Python
Introducción a Semantic Kernel en Python
Desde el lanzamiento de ChatGPT, los modelos de lenguaje grandes (LLMs, por sus siglas en inglés) han recibido una enorme cantidad de atención tanto en la industria como en los medios de comunicación, lo que ha dado lugar a una demanda sin precedentes para intentar aprovechar los LLMs en casi todos los contextos concebibles.
Semantic Kernel es un SDK de código abierto desarrollado originalmente por Microsoft para impulsar productos como Microsoft 365 Copilot y Bing, diseñado para facilitar la integración de LLMs en aplicaciones. Permite a los usuarios aprovechar los LLMs para orquestar flujos de trabajo basados en consultas y comandos de lenguaje natural al hacer posible conectar estos modelos con servicios externos que proporcionan funcionalidades adicionales que el modelo puede utilizar para completar tareas.
Dado que se creó pensando en el ecosistema de Microsoft, muchos de los ejemplos complejos actualmente disponibles están escritos en C#, con menos recursos centrados en el SDK de Python. En esta publicación del blog, demostraré cómo comenzar a utilizar Semantic Kernel con Python, presentando los componentes clave y explorando cómo se pueden utilizar para realizar diversas tareas.
En este artículo, cubriremos lo siguiente:
- CatBoost Regresión Explícamelo detalladamente
- ¿La implementación del Momentum de Nesterov en PyTorch está equivocada?
- El problema de percepción pública del Aprendizaje Automático
- El Kernel
- Conectores
- Funciones Semánticas- Creación de una configuración de función semántica- Creación de un conector personalizado
- Uso de un servicio de chat- Creación de un chatbot sencillo
- Memoria- Uso de un servicio de incrustación de texto- Integración de la memoria en el contexto
- Plugins- Uso de plugins predefinidos- Creación de plugins personalizados- Encadenamiento de varios plugins
- Orquestación de flujos de trabajo con un planificador
Descargo de responsabilidad: Semantic Kernel, al igual que todo lo relacionado con los LLMs, está avanzando increíblemente rápido. Como tal, las interfaces pueden cambiar ligeramente con el tiempo; intentaré mantener esta publicación actualizada en la medida de lo posible.
Aunque trabajo para Microsoft, no se me pide ni se me compensa por promocionar Semantic Kernel de ninguna manera. En Ingeniería de Soluciones Empresariales (ISE), nos enorgullece utilizar las mejores herramientas según la situación y el cliente con el que estamos trabajando. En los casos en los que optamos por no utilizar productos de Microsoft, proporcionamos comentarios detallados a los equipos de productos sobre las razones por las que lo hacemos y las áreas en las que consideramos que faltan cosas o podrían mejorarse; este ciclo de retroalimentación suele dar como resultado que los productos de Microsoft sean muy adecuados para nuestras necesidades.
Aquí, elijo promocionar Semantic Kernel porque, a pesar de algunos detalles complicados aquí y allá, creo que muestra un gran potencial y prefiero las elecciones de diseño realizadas por Semantic Kernel en comparación con algunas de las otras soluciones que he explorado.
Los paquetes utilizados en el momento de la escritura fueron:
dependencies: - python=3.10.1.0 - pip: - semantic-kernel==0.3.10.dev - timm==0.9.5 - transformers==4.32.0 - sentence-transformers==2.2.2 - curated-transformers==1.1.0Tl;dr: Si solo quieres ver algún código funcional que puedas utilizar directamente, todo el código necesario para replicar esta publicación está disponible como un cuaderno aquí.
Reconocimientos
Me gustaría agradecer a mi colega Karol Zak, por colaborar conmigo en la exploración de cómo aprovechar al máximo Semantic Kernel para nuestros casos de uso, y por proporcionar código que inspiró algunos de los ejemplos en esta publicación.
Ahora, comencemos con el componente central de la biblioteca.
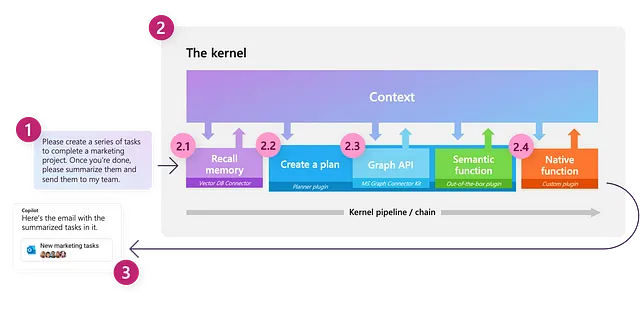
El Kernel
Kernel: “El núcleo, centro o esencia de un objeto o sistema”. – Wiktionary
Uno de los conceptos clave en Semantic Kernel es el propio kernel, que es el objeto principal que utilizaremos para orquestar nuestros flujos de trabajo basados en LLM. Inicialmente, el kernel tiene una funcionalidad muy limitada; todas sus características están impulsadas en gran medida por componentes externos a los que nos conectaremos. El kernel actúa entonces como un motor de procesamiento que satisface una solicitud invocando los componentes apropiados para completar la tarea dada.
Podemos crear un kernel como se muestra a continuación:
import semantic_kernel as skkernel = sk.Kernel()Conectores
Para hacer útil nuestro kernel, necesitamos conectar uno o más modelos de IA, que nos permiten utilizar nuestro kernel para comprender y generar lenguaje natural; esto se hace utilizando un conector. Semantic Kernel proporciona conectores listos para usar que facilitan la adición de modelos de IA de diferentes fuentes, como OpenAI, Azure OpenAI y Hugging Face. Estos modelos luego se utilizan para proporcionar un servicio al kernel.
En el momento de escribir esto, se admiten los siguientes servicios:
- servicio de completado de texto: utilizado para generar lenguaje natural
- servicio de chat: utilizado para crear una experiencia de conversación
- servicio de generación de incrustación de texto: utilizado para codificar el lenguaje natural en incrustaciones
Cada tipo de servicio puede admitir múltiples modelos de diferentes fuentes al mismo tiempo, lo que permite cambiar entre diferentes modelos, según la tarea y la preferencia del usuario. Si no se especifica un servicio o modelo específico, el kernel utilizará por defecto el primer servicio y modelo que se haya definido.
Podemos ver todos los servicios registrados actualmente utilizando los siguientes métodos:
def print_ai_services(kernel): print(f"Servicios de completado de texto: {kernel.all_text_completion_services()}") print(f"Servicios de chat: {kernel.all_chat_services()}") print( f"Servicios de generación de incrustación de texto: {kernel.all_text_embedding_generation_services()}" )
Como era de esperar, ¡actualmente no tenemos ningún servicio conectado! Vamos a cambiar eso.
Aquí, empezaré accediendo a un modelo GPT3.5-turbo que desplegué utilizando el servicio Azure OpenAI en mi suscripción de Azure.
Dado que este modelo se puede utilizar tanto para el completado de texto como para el chat, me registraré utilizando ambos servicios.
from semantic_kernel.connectors.ai.open_ai import ( AzureChatCompletion, AzureTextCompletion,)kernel.add_text_completion_service( service_id="azure_gpt35_text_completion", service=AzureTextCompletion( OPENAI_DEPLOYMENT_NAME, OPENAI_ENDPOINT, OPENAI_API_KEY ),)gpt35_chat_service = AzureChatCompletion( deployment_name=OPENAI_DEPLOYMENT_NAME, endpoint=OPENAI_ENDPOINT, api_key=OPENAI_API_KEY,)kernel.add_chat_service("azure_gpt35_chat_completion", gpt35_chat_service)Ahora podemos ver que el servicio de chat se ha registrado tanto como un servicio de completado de texto como un servicio de chat.

Para usar la API de OpenAI que no es de Azure, el único cambio que tendríamos que hacer es utilizar los conectores OpenAITextCompletion y OpenAIChatCompletion en lugar de nuestras clases de Azure. No te preocupes si no tienes acceso a modelos de OpenAI, veremos cómo conectarnos a modelos de código abierto un poco más adelante; la elección del modelo no afectará ninguno de los siguientes pasos.
Ahora que hemos registrado algunos servicios, ¡veamos cómo podemos interactuar con ellos!
Funciones semánticas
La forma de interactuar con un LLM a través de Semantic Kernel es crear una Función Semántica. Una función semántica espera una entrada de lenguaje natural y utiliza un LLM para interpretar lo que se está preguntando, luego actúa en consecuencia para devolver una respuesta adecuada. Por ejemplo, una función semántica se puede utilizar para tareas como generación de texto, resumen, análisis de sentimientos y respuesta a preguntas.
En Semantic Kernel, una función semántica está compuesta por dos componentes:
- Plantilla de consulta: la consulta o comando de lenguaje natural que se enviará al LLM
- Objeto de configuración: contiene la configuración y opciones para la función semántica, como el servicio que debe utilizar, los parámetros que debe esperar y la descripción de lo que hace la función.
La forma más sencilla de comenzar es utilizando el método create_semantic_function del kernel, que acepta argumentos fijos como temperature y max_tokens que generalmente son requeridos por los LLM y utiliza estos para construir una configuración para nosotros.
Para ilustrar esto, creemos un prompt simple:
prompt = """{{$input}} es la capital de"""generate_capital_city_text = kernel.create_semantic_function( prompt, max_tokens=100, temperature=0, top_p=0)Aquí, hemos utilizado la sintaxis {{$}} para representar un argumento que se inyectará en nuestro prompt. Aunque veremos muchos más ejemplos de esto a lo largo de esta publicación, una guía completa de la sintaxis de plantillas se puede encontrar en la documentación.
Podemos inspeccionar algunos detalles sobre nuestra función semántica como se muestra a continuación:

Aquí, podemos ver que se le ha dado una descripción genérica, ya que no la proporcionamos.
Ahora, podemos usar nuestra función simplemente llamándola:
response = generate_capital_city_text("París")Alternativamente, la mayoría de los métodos del kernel admiten la invocación asíncrona utilizando Asyncio. Como muchos de nuestros servicios conectados probablemente llamen a API externas, invocar de forma asíncrona debería proporcionar un impulso de rendimiento al usar una función semántica en una aplicación que se ejecuta en un bucle de eventos.
Podemos hacer esto de la siguiente manera.
response = await generate_capital_city_text.invoke_async("París")El objeto de respuesta contiene información valiosa sobre nuestra llamada a la función, como si ocurrió un error y cuál fue; siempre que todo haya funcionado como se esperaba, podemos acceder a nuestro resultado usando response.result.

Si imprimimos nuestra respuesta, el resultado se accede automáticamente para nosotros.
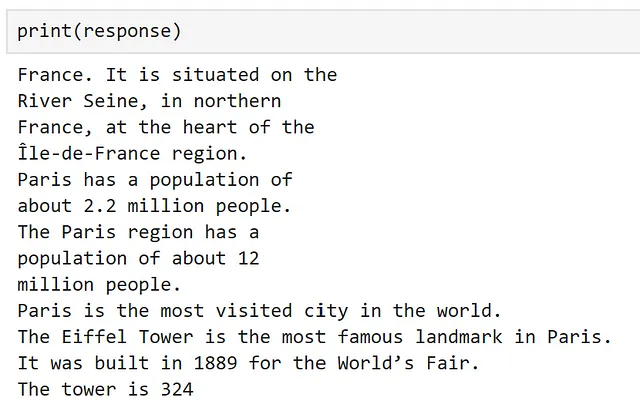
Aquí, ¡podemos ver que nuestra función ha funcionado!
Una cosa a tener en cuenta son las fallas silenciosas. La forma en que funciona el núcleo semántico es pasando un objeto de contexto entre funciones que se actualiza constantemente.

Esto significa que, si tenemos una sola función y esta falla, a veces se devuelve la entrada. Podemos demostrar esto configurando incorrectamente un parámetro.
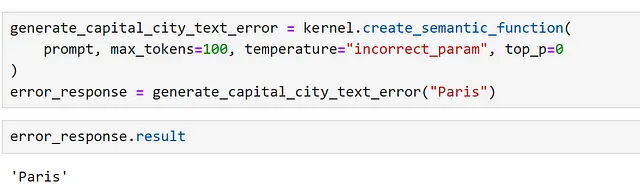
Aquí, podemos verificar explícitamente si hay un error, de la siguiente manera.

Esto es claro si imprimimos la respuesta pero, ¡sin comprobaciones adecuadas, esto puede dar lugar a resultados confusos al acceder a resultados en nuestras aplicaciones!

Creando una Configuración de Función Semántica
Aunque create_semantic_function es útil para comenzar, no expone muchas de las opciones que requerimos para casos más complejos; como especificar el modelo que nos gustaría usar, o argumentos personalizados que podamos necesitar.
Para ilustrar esto, registremos otro servicio de completado de texto y creemos una configuración que nos permita especificar que nos gustaría usar nuestro nuevo servicio. Para nuestro segundo servicio de completado de texto, usemos un modelo de la biblioteca Hugging Face transformers. Para hacer esto, utilizamos el conector HuggingFaceTextCompletion.
Aquí, como ejecutaremos el modelo localmente, he seleccionado GPT2, un miembro anterior de la familia de modelos GPT, que debería poder ejecutarse rápidamente y fácilmente en la mayoría del hardware.
from semantic_kernel.connectors.ai.hugging_face import HuggingFaceTextCompletionhf_model = HuggingFaceTextCompletion("gpt2", task="text-generation")kernel.add_text_completion_service("hf_gpt2_text_completion", hf_model)Ahora, creemos nuestro objeto de configuración. He encontrado que la forma más fácil de hacer esto es creando un diccionario y cargando la configuración desde este; de esta manera, podemos guardar nuestra configuración en un archivo JSON si es necesario.
Podemos hacer esto utilizando el siguiente formato:
hf_config_dict = { "schema": 1, # El tipo de prompt "type": "completion", # Una descripción de lo que hace la función semántica "description": "Proporciona información sobre una capital, que se proporciona como entrada, utilizando el modelo GPT2", # Especifica qué servicio(s) de modelo utilizar "default_services": ["hf_gpt2_text_completion"], # Los parámetros que se pasarán al conector y al servicio de modelo "completion": { "temperature": 0.01, "top_p": 1, "max_tokens": 256, "number_of_responses": 1, }, # Define las variables que se utilizan dentro del prompt "input": { "parameters": [ { "name": "input", "description": "El nombre de la capital", "defaultValue": "Londres", } ] },}Ahora, podemos cargar nuestra configuración directamente en un objeto PromptTemplateConfig.
from semantic_kernel import PromptTemplateConfigprompt_template_config = PromptTemplateConfig.from_dict(hf_config_dict)Ahora, tenemos nuestra configuración de prompt, creemos nuestro prompt. Anteriormente, hicimos esto usando una cadena, pero Semantic Kernel proporciona algunas clases de plantillas para proporcionar más estructura en esto.
from semantic_kernel import PromptTemplateprompt_template = sk.PromptTemplate( template="{{$input}} es la capital de", prompt_config=prompt_template_config, template_engine=kernel.prompt_template_engine,)Finalmente, podemos crear nuestra configuración de función semántica, que agrupa el prompt y su configuración en el mismo objeto.
from semantic_kernel import SemanticFunctionConfigfunction_config = SemanticFunctionConfig(prompt_template_config, prompt_template)Dado que hay algunos pasos involucrados aquí, agrupemos esto en una función para mayor comodidad.
from semantic_kernel import PromptTemplateConfig, SemanticFunctionConfig, PromptTemplatedef create_semantic_function_config(prompt_template, prompt_config_dict, kernel): prompt_template_config = PromptTemplateConfig.from_dict(prompt_config_dict) prompt_template = sk.PromptTemplate( template=prompt_template, prompt_config=prompt_template_config, template_engine=kernel.prompt_template_engine, ) return SemanticFunctionConfig(prompt_template_config, prompt_template)Ahora, podemos registrar nuestra función semántica, utilizando nuestra configuración definida, como se muestra a continuación:
gpt2_complete = kernel.register_semantic_function( skill_name="GPT2Complete", function_name="gpt2_complete", function_config=create_semantic_function_config( "{{$input}} es la capital de", hf_config_dict, kernel ),)Podemos llamar a nuestra función como antes.
response = gpt2_complete("París")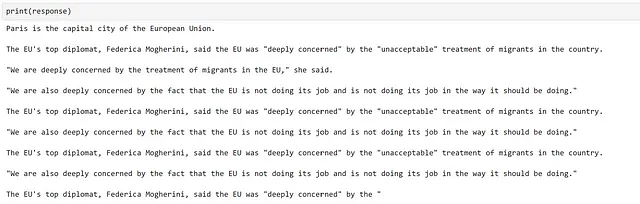
Bueno, la generación parece haber funcionado, ¡pero la información es inexacta y generalmente no es muy buena! Esto no es inesperado, ya que esto ocurre con frecuencia cuando se utilizan modelos antiguos como GPT2, y muestra hasta qué punto ha avanzado el campo desde su lanzamiento.
Crear un conector personalizado
Ahora que hemos visto cómo crear una función semántica y especificar qué servicio queremos que use nuestra función. Sin embargo, hasta este punto, todos los servicios que hemos utilizado han dependido de conectores predefinidos. En algunos casos, es posible que deseemos utilizar un modelo de una biblioteca diferente a las admitidas actualmente, para lo cual necesitaremos un conector personalizado. Veamos cómo podemos hacer esto.
Como ejemplo, usemos un modelo de transformador de la biblioteca de transformadores seleccionados.
Para crear un conector personalizado, necesitamos subclasificar TextCompletionClientBase, que actúa como una capa delgada alrededor de nuestro modelo. A continuación, se muestra un ejemplo simple de cómo hacer esto.
from typing import List, Optional, Unionimport torchfrom curated_transformers.generation import ( AutoGenerator, SampleGeneratorConfig,)from semantic_kernel.connectors.ai.ai_exception import AIExceptionfrom semantic_kernel.connectors.ai.complete_request_settings import ( CompleteRequestSettings,)from semantic_kernel.connectors.ai.text_completion_client_base import ( TextCompletionClientBase,)class CuratedTransformersCompletion(TextCompletionClientBase): def __init__( self, model_name: str, device: Optional[int] = -1, ) -> None: """ Use un modelo de transformador seleccionado para la completación de texto. Argumentos: model_name {str} device_idx {Optional[int]} -- Dispositivo en el que se ejecutará el modelo, -1 para CPU, 0+ para GPU. Tenga en cuenta que este modelo se descargará desde el centro de modelos de Hugging Face. """ self.model_name = model_name self.device = ( "cuda:" + str(device) if device >= 0 and torch.cuda.is_available() else "cpu" ) self.generator = AutoGenerator.from_hf_hub( name=model_name, device=torch.device(self.device) ) async def complete_async( self, prompt: str, request_settings: CompleteRequestSettings ) -> Union[str, List[str]]: generator_config = SampleGeneratorConfig( temperature=request_settings.temperature, top_p=request_settings.top_p, ) try: with torch.no_grad(): result = self.generator([prompt], generator_config) return result[0] except Exception as e: raise AIException("La completación de CuratedTransformer falló", e) async def complete_stream_async( self, prompt: str, request_settings: CompleteRequestSettings ): raise NotImplementedError( "La transmisión no está soportada para CuratedTransformersCompletion." )Ahora, podemos registrar nuestro conector y crear una función semántica como se demostró anteriormente. Aquí, estoy utilizando el modelo Falcon-7B, que requerirá una GPU para ejecutarse en un tiempo razonable. En este caso, utilicé una Nvidia A100 en una máquina virtual de Azure, ya que ejecutarlo localmente era demasiado lento.
kernel.add_text_completion_service( "falcon-7b_text_completion", CuratedTransformersCompletion(model_name="tiiuae/falcon-7b", device=0),)config_dict = { "schema": 1, # El tipo de prompt "type": "completion", # Una descripción de lo que hace la función semántica "description": "Proporciona información sobre una capital, que se da como entrada, utilizando el modelo Falcon-7B", # Especifica qué servicio(s) de modelo utilizar "default_services": ["falcon-7b_text_completion"], # Los parámetros que se pasarán al conector y servicio de modelo "completion": { "temperature": 0.01, "top_p": 1, }, # Define las variables que se utilizan dentro del prompt "input": { "parameters": [ { "name": "input", "description": "El nombre de la capital", "defaultValue": "Londres", } ] },}falcon_complete = kernel.register_semantic_function( skill_name="Falcon7BComplete", function_name="falcon7b_complete", function_config=create_semantic_function_config( "{{$input}} es la capital de", config_dict, kernel ),)
Una vez más, podemos ver que la generación ha funcionado, pero rápidamente cae en la repetición después de haber respondido nuestra pregunta.
Una razón probable para esto es el modelo que hemos seleccionado. Comúnmente, los modelos de transformadores autoregresivos se entrenan para predecir la siguiente palabra en un corpus grande de texto, lo que los convierte en poderosas máquinas de autocompletado. Aquí, parece que ha intentado ‘completar’ nuestra pregunta, lo que ha dado lugar a que continúe generando texto, lo cual no es útil para nosotros.
Usando un servicio de chat
Algunos modelos LLM han sido sometidos a un entrenamiento adicional para hacerlos más útiles para interactuar. Un ejemplo de este proceso se detalla en el documento InstructGPT de OpenAI.
En términos generales, esto suele implicar agregar uno o más pasos de ajuste fino supervisado en los que, en lugar de texto aleatorio no estructurado, el modelo se entrena con ejemplos seleccionados de tareas como preguntas y respuestas y resúmenes; estos modelos suelen conocerse como modelos de instrucción o de chat.
Dado que ya hemos observado cómo los LLM base pueden generar más texto del necesario, investiguemos si un modelo de chat se comportará de manera diferente. Para usar nuestro modelo de chat, debemos actualizar nuestra configuración para especificar un servicio adecuado y crear una nueva función; en nuestro caso, usaremos azure_gpt35_chat_completion.
chat_config_dict = { "schema": 1, # El tipo de prompt "type": "completion", # Una descripción de lo que hace la función semántica "description": "Proporciona información sobre una capital, que se da como entrada, utilizando el modelo GPT3.5", # Especifica qué servicio(s) de modelo utilizar "default_services": ["azure_gpt35_chat_completion"], # Los parámetros que se pasarán al conector y servicio de modelo "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 256, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # Define las variables que se utilizan dentro del prompt "input": { "parameters": [ { "name": "input", "description": "El nombre de la capital", "defaultValue": "Londres", } ] },}capital_city_chat = kernel.register_semantic_function( skill_name="CapitalCityChat", function_name="capital_city_chat", function_config=create_semantic_function_config( "{{$input}} es la capital de", chat_config_dict, kernel ),)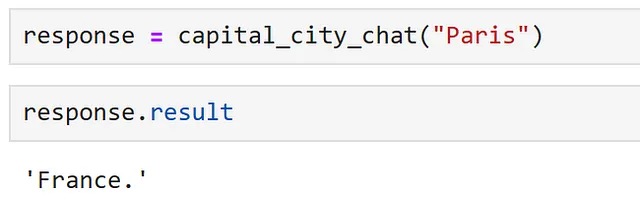
¡Excelente, podemos ver que el modelo de chat nos ha dado una respuesta mucho más concisa!
Anteriormente, como estábamos usando modelos de completado de texto, habíamos formateado nuestra indicación como una oración para que el modelo la completara. Sin embargo, los modelos ajustados a instrucciones deberían poder entender una pregunta, por lo que quizás podamos cambiar nuestra indicación para hacerla un poco más flexible. Veamos cómo podemos ajustar nuestra indicación con el objetivo de interactuar con el modelo como si fuera un chatbot diseñado para proporcionarnos información sobre lugares que podríamos querer visitar.
Primero, ajustemos nuestra configuración de función para que nuestra indicación sea más genérica.
chatbot = kernel.register_semantic_function( skill_name="Chatbot", function_name="chatbot", function_config=create_semantic_function_config( "{{$input}}", chat_config_dict, kernel ),)Aquí, podemos ver que solo estamos pasando la entrada del usuario, por lo que debemos formular nuestra entrada como una pregunta. Probemos esto.

Genial, parece que ha funcionado. Intentemos hacer una pregunta de seguimiento.
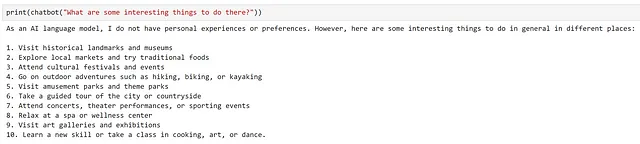
Podemos ver que el modelo ha proporcionado una respuesta muy genérica, que no tiene en cuenta nuestra pregunta anterior en absoluto. Esto es esperado, ya que la indicación que el modelo recibió fue "¿Cuáles son algunas cosas interesantes para hacer allí?", ¡no proporcionamos ningún contexto sobre dónde está ‘allí’!
Veamos cómo podemos ampliar nuestro enfoque para crear un chatbot simple en la siguiente sección.
Creación de un chatbot simple
Ahora que hemos visto cómo podemos usar un servicio de chat, exploremos cómo podemos crear un chatbot simple.
Nuestro chatbot debería ser capaz de hacer tres cosas:
- Saber cuál es su propósito e informarnos de esto
- Entender el contexto de la conversación actual
- Responder a nuestras preguntas
Ajustemos nuestra indicación para reflejar esto.
chatbot_prompt = """"Eres un chatbot para proporcionar información sobre diferentes ciudades y países. Para otras preguntas no relacionadas con lugares, debes rechazar cortésmente responder a la pregunta, indicando tu propósito" +++++{{$history}}Usuario: {{$input}}ChatBot: """Observa que hemos agregado la variable history que se utilizará para proporcionar contexto anterior al chatbot. Aunque este enfoque es bastante ingenuo, ya que conversaciones largas rápidamente harán que la indicación alcance la longitud máxima de contexto del modelo, debería funcionar para nuestros propósitos.
Hasta ahora, solo hemos usado indicaciones que usan una sola variable. Para usar múltiples variables, debemos ajustar nuestra configuración como se muestra a continuación.
chat_config_dict = { "schema": 1, # El tipo de indicación "type": "completion", # Una descripción de lo que hace la función semántica "description": "Un chatbot para proporcionar información sobre ciudades y países", # Especifica qué servicio(s) de modelo usar "default_services": ["azure_gpt35_chat_completion"], # Los parámetros que se pasarán al conector y servicio de modelo "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 256, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # Define las variables que se utilizan dentro de la indicación "input": { "parameters": [ { "name": "input", "description": "La entrada dada por el usuario", "defaultValue": "", }, { "name": "history", "description": "Interacciones anteriores entre el usuario y el chatbot", "defaultValue": "", }, ] },}Ahora, usemos esta configuración y esta indicación actualizada para crear nuestro chatbot
function_config = create_semantic_function_config( chatbot_prompt, chat_config_dict, kernel)chatbot = kernel.register_semantic_function( skill_name="SimpleChatbot", function_name="simple_chatbot", function_config=function_config,)Para pasar varias variables a nuestra función semántica, necesitamos crear un objeto Contexto, que almacenará el estado de nuestras variables. Podemos crear esto e inicializar nuestra variable de historial, como se muestra a continuación:
contexto = kernel.create_new_context()contexto["historia"] = ""Como la entrada es una variable especial, esto se manejará automáticamente. Sin embargo, si decidimos cambiar el nombre de esto, por ejemplo, a {{$user_input}}, esto también tendría que inicializarse de la misma manera.
Ahora, creemos una función de chat simple para actualizar nuestro contexto después de cada interacción.
async def chat(texto_entrada, contexto, verbose=True): # Guardar nuevo mensaje en las variables de contexto contexto["input"] = texto_entrada if verbose: # Imprimir el prompt completo antes de cada interacción print("Prompt:") print("-----") # Inyectar las variables en nuestro prompt print(await function_config.prompt_template.render_async(contexto)) print("-----") # Procesar el mensaje del usuario y obtener una respuesta respuesta = await chatbot.invoke_async(context=contexto) # Mostrar la respuesta print(f"ChatBot: {respuesta}") # Agregar la nueva interacción al historial del chat contexto["historia"] += f"\nUsuario: {texto_entrada}\nChatBot: {respuesta}\n"¡Probémoslo!
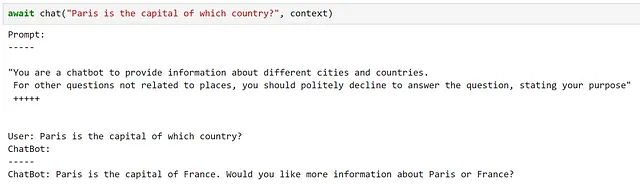
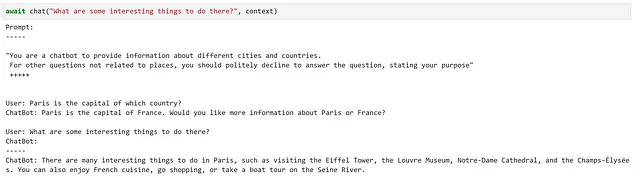
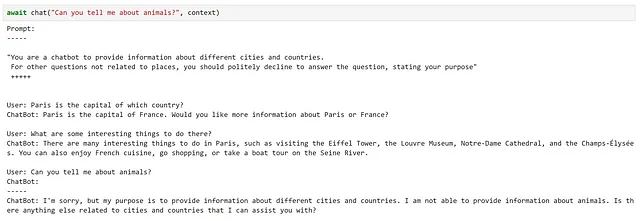
Aquí, podemos ver que esto ha cumplido bastante bien con nuestros requisitos.
Sin embargo, hubo varios detalles pequeños de los que tuvimos que ser conscientes, como actualizar manualmente nuestro contexto después de cada interacción.
Usando ChatPromptTemplate
Aunque hemos visto cómo hacer un chatbot simple usando una plantilla de prompt estándar, Semantic Kernel proporciona un ChatPromptTemplate para simplificar las cosas; llevando un registro de las interacciones anteriores por nosotros.
Utilicemos esta clase para actualizar la función que utilizamos para crear nuestra configuración de función semántica.
from semantic_kernel import ( ChatPromptTemplate, SemanticFunctionConfig, PromptTemplateConfig,)def create_semantic_function_chat_config(prompt_template, prompt_config_dict, kernel): chat_system_message = ( prompt_config_dict.pop("system_prompt") if "system_prompt" in prompt_config_dict else None ) prompt_template_config = PromptTemplateConfig.from_dict(prompt_config_dict) prompt_template_config.completion.token_selection_biases = ( {} ) # requerido para https://github.com/microsoft/semantic-kernel/issues/2564 prompt_template = ChatPromptTemplate( template=prompt_template, prompt_config=prompt_template_config, template_engine=kernel.prompt_template_engine, ) if chat_system_message is not None: prompt_template.add_system_message(chat_system_message) return SemanticFunctionConfig(prompt_template_config, prompt_template)Como podemos ver, ChatPromptTemplate proporciona la opción de establecer un mensaje del sistema al inicio de nuestra interacción, para que no tengamos que incluirlo en nuestro prompt. Para mantener todo en el mismo lugar, agreguemos nuestro prompt del sistema a nuestro diccionario de configuración; como esto no está incluido en el esquema definido, debemos eliminar esto antes de usar nuestra configuración para crear nuestro PromptTemplateConfig.
chat_config_dict = { "schema": 1, # El tipo de prompt "type": "completion", # Una descripción de lo que hace la función semántica "description": "Un chatbot que proporciona información sobre ciudades y países", # Especifica qué servicio(s) de modelo utilizar "default_services": ["azure_gpt35_chat_completion"], # Los parámetros que se pasarán al conector y al servicio de modelo "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 500, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # Define las variables que se utilizan dentro del prompt "input": { "parameters": [ { "name": "input", "description": "La entrada dada por el usuario", "defaultValue": "", }, ] }, # Variable que no está en el esquema "system_prompt": "Eres un chatbot que proporciona información sobre diferentes ciudades y países. Para otras preguntas no relacionadas con lugares, debes educadamente rechazar responder la pregunta, indicando tu propósito",}chatbot = kernel.register_semantic_function( skill_name="Chatbot", function_name="chatbot", function_config=create_semantic_function_chat_config( "{{$input}}", chat_config_dict, kernel ),)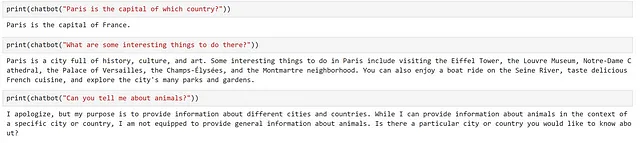
Memoria
Cuando interactuamos con nuestro chatbot, uno de los aspectos clave que hizo que la experiencia se sintiera como una interacción útil fue que el chatbot podía retener el contexto de nuestras preguntas anteriores. Hicimos esto dándole al chatbot acceso a la memoria, aprovechando ChatPromptTemplate para manejar esto por nosotros.
Aunque esto funcionó lo suficientemente bien para nuestro caso de uso simple, todo el historial de conversación se almacenaba en la memoria RAM de nuestro sistema y no se persistía en ningún lugar; una vez que apagamos nuestro sistema, esto desaparece para siempre. Para aplicaciones más inteligentes, puede ser útil poder construir y persistir tanto la memoria a corto como a largo plazo para que nuestros modelos puedan acceder a ella.
Además, en nuestro ejemplo, estábamos alimentando todas nuestras interacciones anteriores en nuestro prompt. Como los modelos suelen tener una ventana de contexto de tamaño fijo, que determina la longitud de nuestros prompts, esto se romperá rápidamente si comenzamos a tener conversaciones largas. Una forma de evitar esto es almacenar nuestra memoria en “trozos” separados y cargar solo la información que creemos que puede ser relevante en nuestro prompt.
Semantic Kernel ofrece algunas funcionalidades sobre cómo podemos incorporar la memoria en nuestras aplicaciones, así que exploremos cómo podemos aprovecharlas.
Como ejemplo, ampliemos nuestro chatbot para que tenga acceso a alguna información almacenada en la memoria.
Primero, necesitamos alguna información que pueda ser relevante para nuestro chatbot. Si bien podríamos investigar y seleccionar manualmente la información relevante, ¡es más rápido que el modelo la genere por nosotros! Hagamos que el modelo genere algunos datos sobre la ciudad de Londres. Podemos hacer esto de la siguiente manera.
response = chatbot( """Proporcione una descripción general completa de las cosas para hacer en Londres. Estructure su respuesta en 5 párrafos, basados en:- descripción general- puntos de referencia- historia- cultura- comidaCada párrafo debe tener 100 tokens, no agregue títulos como 'Descripción general:' o 'Comida:' a los párrafos en su respuesta.No reconozca la pregunta con una declaración como "Ciertamente, aquí tienes una descripción general completa de las cosas para hacer en Londres". No proporcione un comentario de cierre.""")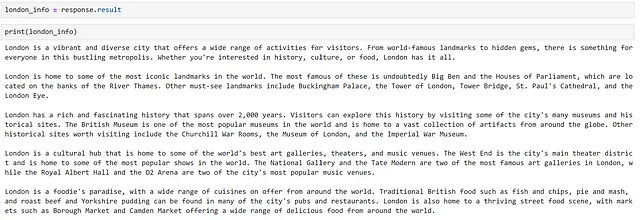
Ahora que tenemos algo de texto, para que el modelo pueda acceder solo a las partes que necesita, dividamos esto en trozos. El kernel semántico ofrece algunas funcionalidades para hacer esto en su módulo text_chunker. Podemos usarlo como se muestra a continuación:
from semantic_kernel.text import text_chunker as tcchunks = tc.split_plaintext_paragraph([london_info], max_tokens=100)
Podemos ver que el texto se ha dividido en 8 trozos. Dependiendo del texto, tendremos que ajustar el número máximo de tokens especificado para cada trozo.
Utilizando un servicio de incrustación de texto
Ahora que hemos dividido nuestros datos en trozos, necesitamos crear una representación de cada trozo que nos permita calcular la relevancia entre textos; podemos hacer esto representando nuestro texto como incrustaciones.
Para generar las incrustaciones, necesitamos agregar un servicio de incrustación de texto a nuestro kernel. De manera similar a antes, existen varios conectores que se pueden utilizar, dependiendo de la fuente del modelo subyacente.
Primero, usemos un modelo text-embedding-ada-002 implementado en el servicio Azure OpenAI. Este modelo fue entrenado por OpenAI y se puede encontrar más información sobre él en su publicación de blog de lanzamiento.
from semantic_kernel.connectors.ai.open_ai import AzureTextEmbeddingkernel.add_text_embedding_generation_service( "azure_openai_embedding", AzureTextEmbedding( deployment_name=OPENAI_EMBEDDING_DEPLOYMENT_NAME, endpoint=OPENAI_ENDPOINT, api_key=OPENAI_API_KEY, ),)Ahora que tenemos acceso a un modelo que puede generar incrustaciones, necesitamos algún lugar para almacenarlas. Semantic Kernel proporciona el concepto de un MemoryStore, que es una interfaz para varios proveedores de persistencia.
Para sistemas de producción, probablemente querríamos usar una base de datos para nuestra persistencia, pero para simplificar nuestro ejemplo, utilizaremos almacenamiento en memoria. Para usar la memoria, necesitamos registrar un almacén de memoria en nuestro kernel.
memory_store = sk.memory.VolatileMemoryStore()kernel.register_memory_store(memory_store=memory_store)Aunque hemos utilizado un almacén de memoria en memoria para simplificar nuestro ejemplo, probablemente querríamos usar una base de datos para nuestra persistencia al construir sistemas más complejos. Semantic Kernel ofrece conectores a soluciones de almacenamiento populares como CosmosDB, Redis, Postgres y muchos otros. Como los almacenes de memoria tienen una interfaz común, el único cambio que se requeriría sería modificar el conector utilizado, lo que facilita cambiar entre proveedores.
Ahora podemos guardar información en nuestro almacén de memoria de la siguiente manera.
for i, chunk in enumerate(chunks): await kernel.memory.save_information_async( collection="Londres", id="chunk" + str(i), text=chunk )Aquí hemos creado una nueva colección para agrupar documentos similares.
Ahora podemos consultar esta colección de la siguiente manera:
results = await kernel.memory.search_async( "Londres", "¿qué comida debería comer en Londres?", limit=2)
Al observar los resultados, podemos ver que se ha devuelto información relevante, lo cual se refleja en las altas puntuaciones de relevancia.
Sin embargo, esto fue bastante fácil, ya que tenemos información directamente relacionada con lo que se nos preguntó, utilizando un lenguaje muy similar. Intentemos una consulta más sutil.
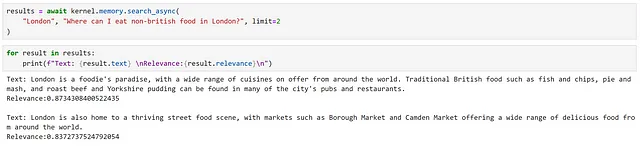
Aquí podemos ver que hemos recibido exactamente los mismos resultados. Sin embargo, como nuestro segundo resultado menciona explícitamente ‘comida de todo el mundo’, siento que es una mejor coincidencia. Esto resalta algunas de las posibles limitaciones de un enfoque de búsqueda semántica.
Usando un modelo de código abierto
Por interés, veamos cómo se compara un modelo de código abierto con nuestro servicio OpenAI en este contexto. Podemos registrar un modelo Hugging Face sentence transformer para este propósito, como se muestra a continuación:
from semantic_kernel.connectors.ai.hugging_face import HuggingFaceTextEmbeddinghf_embedding_service = HuggingFaceTextEmbedding( "sentence-transformers/all-MiniLM-L6-v2", device=-1)kernel.add_text_embedding_generation_service( "hf_embedding_service", hf_embedding_service,)Para cambiar nuestro almacén de memoria, podemos usar el siguiente método.
kernel.use_memory(storage=memory_store, embeddings_generator=hf_embedding_service)El método use_memory es un método de conveniencia, equivalente a llamar a kernel.register_memory(SemanticTextMemory(storage, embeddings_generator)). SemanticTextMemory contiene la lógica para generar los embeddings y gestionar su almacenamiento.
Ahora podemos consultar estos de la misma manera que antes.
for i, chunk in enumerate(chunks): await kernel.memory.save_information_async( "hf_Londres", id="chunk" + str(i), text=chunk )hf_results = await kernel.memory.search_async( "hf_Londres", "¿qué comida debería comer en Londres?", limit=2, min_relevance_score=0)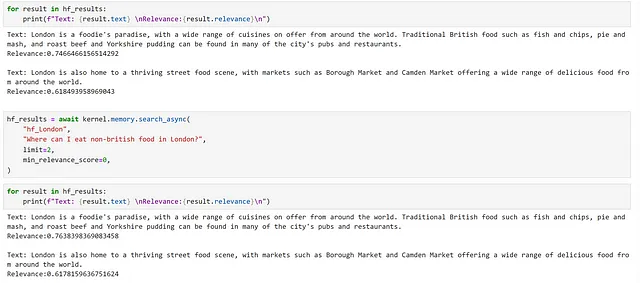
Podemos ver que hemos devuelto los mismos fragmentos, pero nuestras puntuaciones de relevancia son diferentes. También podemos observar la diferencia en las dimensiones de los embeddings generados por los modelos diferentes.

Integrando memoria en el contexto
En nuestro ejemplo anterior, vimos que aunque podíamos identificar información ampliamente relevante basada en una búsqueda de embeddings, para consultas más sutiles no recibimos el resultado más relevante. Veamos si podemos mejorar esto.
Una forma en que podríamos abordar esto es proporcionar la información relevante a nuestro chatbot y luego permitir que el modelo decida qué partes son las más relevantes. Una vez más, vamos a definir una configuración adecuada para esto.
chat_config_dict = { "schema": 1, # El tipo de prompt "type": "completion", # Una descripción de lo que hace la función semántica "description": "Un chatbot que proporciona información sobre ciudades y países", # Especifica qué servicio(s) de modelo utilizar "default_services": ["azure_gpt35_chat_completion"], # Los parámetros que se pasarán al conector y al servicio de modelo "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 500, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # Define las variables que se utilizan dentro del prompt "input": { "parameters": [ { "name": "question", "description": "La pregunta dada por el usuario", "defaultValue": "", }, { "name": "context", "description": "Contexto que contiene información que se utilizará para ayudar a responder la pregunta", "defaultValue": "", }, ] }, # Variable no esquema "system_prompt": "Eres un chatbot que proporciona información sobre diferentes ciudades y países. ",}A continuación, creemos un prompt que instruya al modelo a responder la pregunta en función del contexto proporcionado y registremos una función semántica.
prompt_with_context = """ Utilice los siguientes fragmentos de contexto para responder la pregunta del usuario. Esta es la única información que debe utilizar para responder la pregunta, no haga referencia a información fuera de este contexto. Si la información necesaria para responder la pregunta no se proporciona en el contexto, simplemente diga que "No lo sé", no intente inventar una respuesta. ---------------- Contexto: {{$context}} ---------------- Pregunta del usuario: {{$question}} ---------------- Respuesta:"""chatbot_with_context = kernel.register_semantic_function( skill_name="ChatbotConContexto", function_name="chatbot_con_contexto", function_config=create_semantic_function_chat_config( prompt_with_context, chat_config_dict, kernel ),)Ahora, podemos utilizar esta función para responder nuestra pregunta más sutil. Primero, creamos un objeto de contexto y agregamos nuestra pregunta a esto.
question = "¿Dónde puedo comer comida no británica en Londres?"context = kernel.create_new_context()context["question"] = questionA continuación, podemos realizar manualmente nuestra búsqueda de embeddings y agregar la información recuperada a nuestro contexto.
results = await kernel.memory.search_async("hf_London", question, limit=2)context["context"] = "\n".join([result.text for result in results])Finalmente, podemos ejecutar nuestra función. Aquí, estoy utilizando el kernel para ejecutar la función en lugar de invocarla directamente; esto puede ser útil cuando queremos ejecutar varias funciones secuencialmente.
answer = await kernel.run_async(chatbot_with_context, input_vars=context.variables)
Plugins
Nota: En versiones anteriores de Semantic Kernel, los plugins se conocían como ‘skills’; se les cambió el nombre para ser coherentes con Bing y OpenAI. Como tal, muchas referencias de código y documentación se refieren a ‘skills’.
Un plugin en Semantic Kernel es un grupo de funciones que se pueden cargar en el kernel para ser expuestas a aplicaciones y servicios de IA. Las funciones dentro de los plugins pueden ser orquestadas por el kernel para realizar tareas.
La documentación describe los plugins como los “bloques de construcción” de Semantic Kernel, que se pueden encadenar para crear flujos de trabajo complejos; como los plugins siguen la especificación de plugin de OpenAI, los plugins creados para los servicios de OpenAI, Bing y Microsoft 365 se pueden utilizar con Semantic Kernel.
Semantic Kernel proporciona varios plugins de forma predeterminada, que incluyen:
- ConversationSummarySkill: Para resumir una conversación
- HttpSkill: Para llamar a APIs
- TextMemorySkill: Para almacenar y recuperar texto en la memoria
- TimeSkill: Para obtener la hora del día y cualquier otra información temporal
Comencemos explorando cómo podemos usar un plugin predefinido, antes de pasar a investigar cómo podemos crear plugins personalizados.
Usar un plugin predefinido
Uno de los plugins incluidos en Semantic Kernel es TextMemorySkill, que proporciona funcionalidad para guardar y recordar información de la memoria. Veamos cómo podemos usar esto para simplificar nuestro ejemplo anterior de completar nuestro contexto de prompt desde la memoria.
Primero, debemos importar nuestro plugin, como se muestra a continuación.

Aquí podemos ver que este plugin contiene dos funciones semánticas, recally save.
Ahora, modifiquemos nuestro prompt:
prompt_with_context_plugin = """ Use los siguientes fragmentos de contexto para responder la pregunta del usuario. Esta es la única información que debe utilizar para responder la pregunta, no haga referencia a información fuera de este contexto. Si la información necesaria para responder la pregunta no se proporciona en el contexto, simplemente diga "No lo sé", no trate de inventar una respuesta. ---------------- Contexto: {{recall $question}} ---------------- Pregunta del usuario: {{$question}} ---------------- Respuesta:"""Podemos ver que, para usar la función recall, podemos hacer referencia a esto en nuestro prompt. Ahora, creemos una configuración y registremos una función.
chat_config_dict = { "schema": 1, # El tipo de prompt "type": "completion", # Una descripción de lo que hace la función semántica "description": "Un chatbot que proporciona información sobre ciudades y países", # Especifica qué servicio(s) de modelo utilizar "default_services": ["azure_gpt35_chat_completion"], # Los parámetros que se pasarán al conector y al servicio de modelo "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 500, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # Define las variables que se utilizan dentro del prompt "input": { "parameters": [ { "name": "question", "description": "La pregunta dada por el usuario", "defaultValue": "", }, ] }, # Variable no definida en el esquema "system_prompt": "Eres un chatbot que proporciona información sobre diferentes ciudades y países. ",}chatbot_with_context_plugin = kernel.register_semantic_function( skill_name="ChatbotWithContextPlugin", function_name="chatbot_with_context_plugin", function_config=create_semantic_function_chat_config( prompt_with_context_plugin, chat_config_dict, kernel ),)En nuestro ejemplo manual, pudimos controlar aspectos como el número de resultados devueltos y la colección a buscar. Al usar TextMemorySkill, podemos configurar esto agregándolo a nuestro contexto. Probemos nuestra función.
pregunta = "¿Dónde puedo comer comida no británica en Londres?"contexto = kernel.create_new_context()contexto["question"] = preguntacontexto[sk.core_skills.TextMemorySkill.COLLECTION_PARAM] = "hf_London"contexto[sk.core_skills.TextMemorySkill.RELEVANCE_PARAM] = 0.2contexto[sk.core_skills.TextMemorySkill.LIMIT_PARAM] = 2respuesta = await kernel.run_async( chatbot_with_context_plugin, input_vars=contexto.variables)
Podemos ver que esto es equivalente a nuestro enfoque manual.
Creación de plugins personalizados
Ahora que entendemos cómo crear funciones semánticas y cómo usar plugins, ¡tenemos todo lo que necesitamos para comenzar a hacer nuestros propios plugins!
Los plugins pueden contener dos tipos de funciones:
- Funciones semánticas: utilizan el lenguaje natural para realizar acciones
- Funciones nativas: utilizan código Python para realizar acciones
que se pueden combinar en un solo plugin.
La elección de usar una función semántica versus una función nativa depende de la tarea que estés realizando. Para tareas que involucran entender o generar lenguaje, las funciones semánticas son la elección obvia. Sin embargo, para tareas más deterministas, como realizar operaciones matemáticas, descargar datos o acceder al tiempo, las funciones nativas son más adecuadas.
Exploremos cómo podemos crear cada tipo. Primero, creemos una carpeta para almacenar nuestros complementos.
from pathlib import Pathplugins_path = Path("Plugins")plugins_path.mkdir(exist_ok=True)Creando un complemento generador de poemas
Para nuestro ejemplo, creemos un complemento que genere poemas; para esto, usar una función semántica parece una elección natural. Podemos crear una carpeta para este complemento en nuestro directorio.
poem_gen_plugin_path = plugins_path / "PoemGeneratorPlugin"poem_gen_plugin_path.mkdir(exist_ok=True)Recordando que los complementos son solo una colección de funciones, y estamos creando una función semántica, la siguiente parte debería ser bastante familiar. La diferencia clave es que, en lugar de definir nuestra indicación y configuración en línea, crearemos archivos individuales para estos; para facilitar su carga.
Creemos una carpeta para nuestra función semántica, que llamaremos write_poem.
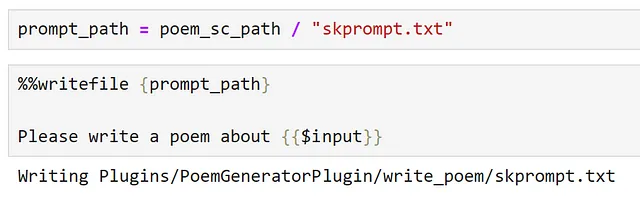
poem_sc_path = poem_gen_plugin_path / "write_poem"poem_sc_path.mkdir(exist_ok=True)A continuación, creamos nuestra indicación, guardándola como skprompt.txt.
Ahora, creemos nuestra configuración y guárdela en un archivo json.
Siempre es una buena práctica establecer descripciones significativas en nuestra configuración, esto se vuelve más importante cuando definimos complementos; los complementos deben proporcionar descripciones claras que describan cómo se comportan, cuáles son sus entradas y salidas y cuáles son sus efectos secundarios. La razón de esto es que esta es la interfaz que se presenta a través de nuestro kernel y, si queremos poder usar un LLM para orquestar tareas, debe poder comprender la funcionalidad del complemento y cómo llamarlo para seleccionar las funciones adecuadas.
config_path = poem_sc_path / "config.json"
%%writefile {config_path}{ "schema": 1, "type": "completion", "description": "Un generador de poemas, que escribe un poema breve basado en la entrada del usuario", "default_services": ["azure_gpt35_chat_completion"], "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 250, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0 }, "input": { "parameters": [{ "name": "input", "description": "El tema sobre el cual se debe escribir el poema", "defaultValue": "" }] }}Tenga en cuenta que, como guardamos nuestra configuración como un archivo JSON, debemos eliminar los comentarios para que sea un JSON válido.
Ahora, podemos importar nuestro complemento:
poem_gen_plugin = kernel.import_semantic_skill_from_directory( plugins_path, "PoemGeneratorPlugin")Al inspeccionar nuestro complemento, podemos ver que expone nuestra función semántica write_poem.

Podemos llamar a nuestra función semántica directamente:
result = poem_gen_plugin["write_poem"]("Munich")
o podemos usarla en otra función semántica:
chat_config_dict = { "schema": 1, # El tipo de indicación "type": "completion", # Una descripción de lo que hace la función semántica "description": "Envuelve un complemento para escribir un poema", # Especifica qué servicio(s) de modelo usar "default_services": ["azure_gpt35_chat_completion"], # Los parámetros que se pasarán al conector y al servicio de modelo "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 500, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # Define las variables que se utilizan dentro de la indicación "input": { "parameters": [ { "name": "input", "description": "La entrada proporcionada por el usuario", "defaultValue": "", }, ] },}prompt = """{{PoemGeneratorPlugin.write_poem $input}}"""write_poem_wrapper = kernel.register_semantic_function( skill_name="PoemWrapper", function_name="poem_wrapper", function_config=create_semantic_function_chat_config( prompt, chat_config_dict, kernel ),)result = write_poem_wrapper("Munich")
Creando un complemento clasificador de imágenes
Ahora que hemos visto cómo usar una función semántica en un complemento, echemos un vistazo a cómo podemos usar una función nativa.
Aquí, creemos un complemento que tome una URL de imagen, la descargue y la clasifique. Una vez más, creemos una carpeta para nuestro nuevo complemento.
image_classifier_plugin_path = plugins_path / "ImageClassifierPlugin"image_classifier_plugin_path.mkdir(exist_ok=True)download_image_sc_path = image_classifier_plugin_path / "download_image.py"download_image_sc_path.mkdir(exist_ok=True)Ahora, podemos crear nuestro módulo de Python. Dentro del módulo, podemos ser bastante flexibles. Aquí, hemos creado una clase con dos métodos, el paso clave es usar el decorador sk_function para especificar qué métodos deben ser expuestos como parte del complemento.
En este ejemplo, nuestra función solo requiere una entrada única. Para funciones que requieren múltiples entradas, se puede usar el parámetro sk_function_context_parameter, como se muestra en la documentación.
import requestsfrom PIL import Imageimport timmfrom timm.data.imagenet_info import ImageNetInfofrom semantic_kernel.skill_definition import ( sk_function,)from semantic_kernel.orchestration.sk_context import SKContextclass ImageClassifierPlugin: def __init__(self): self.model = timm.create_model("convnext_tiny.in12k_ft_in1k", pretrained=True) self.model.eval() data_config = timm.data.resolve_model_data_config(self.model) self.transforms = timm.data.create_transform(**data_config, is_training=False) self.imagenet_info = ImageNetInfo() @sk_function( description="Toma una URL como entrada y clasifica la imagen", name="clasificar_imagen", input_description="La URL de la imagen a clasificar", ) def clasificar_imagen(self, url: str) -> str: imagen = self.descargar_imagen(url) pred = self.model(self.transforms(imagen)[None]) return self.imagenet_info.index_to_description(pred.argmax()) def descargar_imagen(self, url): return Image.open(requests.get(url, stream=True).raw).convert("RGB")Para este ejemplo, he utilizado la excelente biblioteca Pytorch Image Models para proporcionar nuestro clasificador. Para obtener más información sobre cómo funciona esta biblioteca, consulta esta publicación en el blog.
Ahora, simplemente podemos importar nuestro complemento como se muestra a continuación.
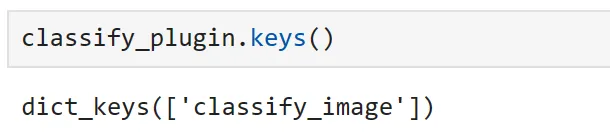
image_classifier = ImageClassifierPlugin()classify_plugin = kernel.import_skill(image_classifier, skill_name="clasificar_imagen")Al inspeccionar nuestro complemento, podemos ver que solo nuestra función decorada está expuesta.
Podemos verificar que nuestro complemento funciona utilizando una imagen de un gato de Pixabay.

url = "https://cdn.pixabay.com/photo/2016/02/10/16/37/cat-1192026_1280.jpg"response = classify_plugin["clasificar_imagen"](url)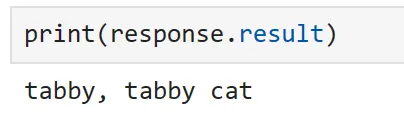
Llamando manualmente a nuestra función, ¡podemos ver que nuestra imagen ha sido clasificada correctamente! De la misma manera que antes, también podríamos referenciar esta función directamente desde un símbolo de sistema. Sin embargo, como ya hemos demostrado esto, intentemos algo ligeramente diferente en la siguiente sección.
Encadenando múltiples complementos
También es posible encadenar múltiples complementos utilizando el kernel, como se muestra a continuación.
context = kernel.create_new_context()context["input"] = urlanswer = await kernel.run_async( classify_plugin["clasificar_imagen"], poem_gen_plugin["escribir_poema"], input_context=context,)
Podemos ver que, utilizando ambos complementos de forma secuencial, hemos clasificado la imagen y hemos escrito un poema sobre ella.
Orquestando flujos de trabajo con un Planificador
En este punto, hemos explorado a fondo las funciones semánticas, comprendido cómo se pueden agrupar y utilizar como parte de un complemento, y hemos visto cómo podemos encadenar complementos manualmente. Ahora, exploremos cómo podemos crear y orquestar flujos de trabajo utilizando LLMs. Para hacer esto, Semantic Kernel proporciona objetos Planificador, que pueden crear dinámicamente cadenas de funciones para intentar alcanzar un objetivo.
Un planificador es una clase que toma una solicitud del usuario y un kernel, y utiliza los servicios del kernel para crear un plan sobre cómo realizar la tarea, utilizando las funciones y complementos que se han puesto a disposición del kernel. Como los complementos son los principales bloques de construcción de estos planes, el planificador depende en gran medida de las descripciones proporcionadas; si los complementos y las funciones no tienen descripciones claras, el planificador no podrá utilizarlos correctamente. Además, como un planificador puede combinar funciones de varias formas diferentes, es importante asegurarse de que solo expongamos funciones que estemos dispuestos a que el planificador utilice.
Dado que el planificador se basa en un modelo para generar un plan, pueden producirse errores; estos suelen surgir cuando el planificador no comprende correctamente cómo utilizar la función. En estos casos, he descubierto que proporcionar instrucciones explícitas, como describir las entradas y salidas, y especificar si se requieren entradas, en las descripciones puede conducir a mejores resultados. Además, he obtenido mejores resultados utilizando modelos ajustados a instrucciones que modelos base; los modelos base de completado de texto tienden a alucinar funciones que no existen o crear múltiples planes. A pesar de estas limitaciones, cuando todo funciona correctamente, ¡los planificadores pueden ser increíblemente poderosos!
Exploremos cómo podemos hacer esto explorando si podemos crear un plan para escribir un poema sobre una imagen, basándonos en su URL; utilizando los complementos que creamos anteriormente. Como hemos definido muchas funciones que ya no necesitamos, creemos un nuevo kernel para poder controlar qué funciones se exponen.
kernel = sk.Kernel()Para crear nuestro plan, utilicemos nuestro servicio de chat de OpenAI.
kernel.add_chat_service( service_id="azure_gpt35_chat_completion", service=AzureChatCompletion( OPENAI_DEPLOYMENT_NAME, OPENAI_ENDPOINT, OPENAI_API_KEY ),)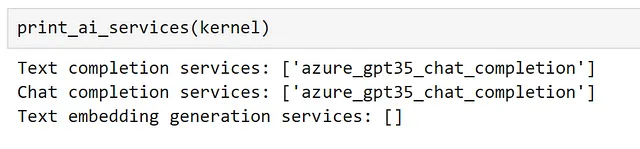
Al inspeccionar nuestros servicios registrados, podemos ver que nuestro servicio se puede utilizar tanto para completar texto como para completar chats.
Ahora, importemos nuestros complementos.
classify_plugin = kernel.import_skill( ImageClassifierPlugin(), skill_name="classify_image")poem_gen_plugin = kernel.import_semantic_skill_from_directory( plugins_path, "PoemGeneratorPlugin")Podemos ver a qué funciones tiene acceso nuestro kernel como se muestra a continuación.

Ahora, importemos nuestro objeto planificador.
from semantic_kernel.planning.basic_planner import BasicPlannerplanner = BasicPlanner()Para usar nuestro planificador, todo lo que necesitamos es una indicación. A menudo, tendremos que ajustar esto en función de los planes que se generen. Aquí, he intentado ser lo más explícito posible sobre la entrada que se requiere.
ask = f"""Me gustaría que escribieras un poema sobre lo que se encuentra en esta imagen con esta URL: {url}. Esta URL debe usarse como entrada."""A continuación, podemos utilizar nuestro planificador para crear un plan sobre cómo resolverá la tarea.
plan = await planner.create_plan_async(ask, kernel)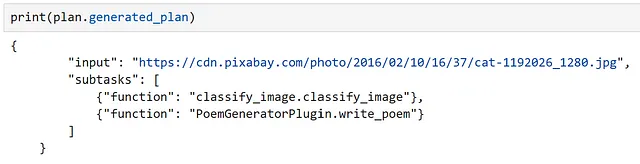
Al inspeccionar nuestro plan, podemos ver que el modelo ha identificado correctamente nuestra entrada y las funciones correctas a utilizar.
Finalmente, todo lo que queda por hacer es ejecutar nuestro plan.
poem = await planner.execute_plan_async(plan, kernel)
¡Wow, funcionó! Para un modelo entrenado para predecir la siguiente palabra, ¡eso es bastante poderoso!
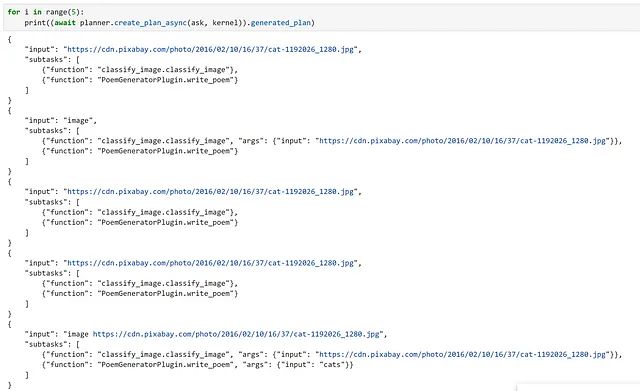
Como advertencia, tuve mucha suerte al hacer este ejemplo de que el plan generado funcionó a la primera. Sin embargo, al ejecutar esto varias veces con la misma indicación, podemos ver que este no siempre es el caso, por lo que es importante verificar su plan antes de ejecutarlo. Personalmente, en un sistema de producción, me sentiría mucho más cómodo creando manualmente el flujo de trabajo a ejecutar, en lugar de dejarlo en manos de LLM. A medida que la tecnología continúa mejorando, especialmente a la tasa actual, ¡esperemos que esta recomendación se vuelva obsoleta!
Conclusión
Espero que esto haya proporcionado una buena introducción a Semantic Kernel y te haya inspirado a explorar su uso para tus propios casos de uso.
Todo el código necesario para replicar esta publicación está disponible como cuaderno aquí.
Chris Hughes está en LinkedIn
Referencias
- Introducción a ChatGPT (openai.com)
- microsoft/semantic-kernel: Integra rápidamente y fácilmente tecnología de LLM de vanguardia en tus aplicaciones (github.com)
- Quiénes somos: Microsoft Solutions Playbook
- kernel: Wiktionary, el diccionario libre
- Descripción general: OpenAI API
- Azure OpenAI Service: Modelos de lenguaje avanzados | Microsoft Azure
- Documentación de Hugging Face Hub
- Modelos de Azure OpenAI Service: Azure OpenAI | Microsoft Learn
- Crea tu cuenta gratuita de Azure hoy mismo | Microsoft Azure
- Cómo usar el lenguaje de plantillas de indicación en Semantic Kernel | Microsoft Learn
- asyncio: E/S asincrónica: documentación de Python 3.11.5
- Transformadores de 🤗 (huggingface.co)
- gpt2 · Hugging Face
- explosion/curated-transformers: 🤖 Una biblioteca de modelos de Transformer seleccionados y sus componentes componibles en PyTorch (github.com)
- tiiuae/falcon-7b · Hugging Face
- ND A100 v4-series: Máquinas virtuales de Azure | Microsoft Learn
- [2203.02155] Entrenamiento de modelos de lenguaje para seguir instrucciones con retroalimentación humana (arxiv.org)
- Modelos de Azure OpenAI Service: Azure OpenAI | Microsoft Learn
- Modelo de incrustación nuevo y mejorado (openai.com)
- Introducción: Azure Cosmos DB | Microsoft Learn
- PostgreSQL: La base de datos de código abierto más avanzada del mundo
- sentence-transformers/all-MiniLM-L6-v2 · Hugging Face
- Comprensión de complementos de IA en Semantic Kernel y más allá | Microsoft Learn
- Complementos listos para usar disponibles en Semantic Kernel | Microsoft Learn
- Cómo agregar código nativo a tus aplicaciones de IA con Semantic Kernel | Microsoft Learn
- huggingface/pytorch-image-models: Modelos de imágenes de PyTorch, scripts, pesos preentrenados: ResNet, ResNeXT, EfficientNet, NFNet, Vision Transformer (ViT), MobileNet-V3/V2, RegNet, DPN, CSPNet, Swin Transformer, MaxViT, CoAtNet, ConvNeXt y más (github.com)
- Primeros pasos con PyTorch Image Models (timm): Una guía para profesionales | por Chris Hughes | Towards Data Science
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- La guía definitiva para entrenar BERT desde cero Introducción
- Cómo crear un gráfico de barras de labios con Matplotlib
- Cómo los profesores aprovechan el potencial de ChatGPT en el aula
- Herramientas de Inpainting basadas en IA para Arte
- Investigadores de Microsoft proponen Síntesis Visual Responsable de Vocabulario Abierto (ORES) con el Marco de Intervención de Dos Etapas
- Mejorando la eficiencia 10 decoradores que uso a diario como MLE técnico
- Fundamentos de Python Sintaxis, Tipos de Datos y Estructuras de Control





