Introducción práctica a los modelos de Transformer BERT
Introducción a los modelos de Transformer BERT
Tutoriales Prácticos
Tutorial práctico sobre cómo construir tu primer modelo de análisis de sentimientos utilizando BERT
Prefacio: Este artículo presenta un resumen de información sobre el tema dado. No debe considerarse una investigación original. La información y el código incluidos en este artículo pueden verse influenciados por cosas que he leído o visto anteriormente en varios artículos en línea, documentos de investigación, libros y código de código abierto.
Tabla de contenido
- Introducción a BERT
- Pre-entrenamiento y Ajuste fino
- Práctica: Uso de BERT para análisis de sentimientos
- Interpretación de resultados
- Pensamientos finales
En NLP, la arquitectura del modelo de transformador ha sido una revolución que ha mejorado en gran medida la capacidad de comprender y generar información textual.
En este tutorial, vamos a profundizar en BERT, un modelo basado en transformadores bien conocido, y proporcionar un ejemplo práctico para ajustar el modelo base de BERT para el análisis de sentimientos.
Introducción a BERT
BERT, presentado por investigadores de Google en 2018, es un poderoso modelo de lenguaje que utiliza la arquitectura de transformador. Empujando los límites de las arquitecturas de modelos anteriores, como LSTM y GRU, que eran unidireccionales o bidireccionales de forma secuencial, BERT considera el contexto tanto del pasado como del futuro simultáneamente. Esto se debe al innovador “mecanismo de atención”, que permite que el modelo ponderar la importancia de las palabras en una oración al generar representaciones.
- Principios efectivos de ingeniería de indicaciones para la aplicación de IA generativa
- Esta es la razón por la que deberías leer esto antes de usar Pandas en la limpieza de datos
- ChatGPT destronado cómo Claude se convirtió en el nuevo líder de IA
El modelo de BERT se pre-entrena en las siguientes dos tareas de NLP:
- Modelo de Lenguaje Enmascarado (MLM)
- Predicción de la Siguiente Oración (NSP)
y generalmente se utiliza como modelo base para varias tareas de NLP posteriores, como el análisis de sentimientos que cubriremos en este tutorial.
Pre-entrenamiento y Ajuste fino
El poder de BERT proviene de su proceso de dos pasos:
- Pre-entrenamiento es la fase en la que BERT se entrena con grandes cantidades de datos. Como resultado, aprende a predecir palabras enmascaradas en una oración (tarea MLM) y a predecir si una oración sigue a otra (tarea NSP). La salida de esta etapa es un modelo de NLP pre-entrenado con una “comprensión” general del lenguaje.
- Ajuste fino es donde el modelo de BERT pre-entrenado se entrena aún más en una tarea específica. El modelo se inicializa con los parámetros pre-entrenados y se entrena el modelo completo en una tarea posterior, lo que permite a BERT ajustar su comprensión del lenguaje a las especificidades de la tarea en cuestión.
Práctica: Uso de BERT para análisis de sentimientos
El código completo está disponible como un cuaderno de Jupyter en GitHub
En este ejercicio práctico, entrenaremos el modelo de análisis de sentimientos en el conjunto de datos de reseñas de películas de IMDB [4] (licencia: Apache 2.0), que está etiquetado si una reseña es positiva o negativa. También cargaremos el modelo utilizando la biblioteca transformers de Hugging Face.
Carguemos todas las bibliotecas
import pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltfrom sklearn.metrics import confusion_matrix, roc_curve, aucfrom datasets import load_datasetfrom transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer# Variables para establecer el número de épocas y muestrasnum_epochs = 10num_samples = 100 # establecer esto en -1 para usar todos los datosPrimero, necesitamos cargar el conjunto de datos y el tokenizador del modelo.
# Paso 1: Cargar el conjunto de datos y el tokenizador del modelodataset = load_dataset('imdb')tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')A continuación, crearemos un gráfico para ver la distribución de las clases positivas y negativas.
# Exploración de datos train_df = pd.DataFrame(dataset["train"])sns.countplot(x='label', data=train_df)plt.title('Distribución de clases')plt.show()
A continuación, preprocesamos nuestro conjunto de datos mediante la tokenización de los textos. Utilizamos el tokenizador de BERT, que convertirá el texto en tokens que corresponden al vocabulario de BERT.
# Paso 2: Preprocesar el conjuto de datosdef tokenizar_funcion(ejemplos): return tokenizer(ejemplos["texto"], padding="max_length", truncation=True)conjunto_datos_tokenizados = conjunto_datos.map(tokenizar_funcion, batched=True)
Después, preparamos nuestros conjuntos de datos de entrenamiento y evaluación. Recuerda, si deseas utilizar todos los datos, puedes establecer la variable num_muestras en -1.
if num_muestras == -1: conjunto_entrenamiento_pequeño = conjunto_datos_tokenizados["entrenamiento"].shuffle(seed=42) conjunto_evaluacion_pequeño = conjunto_datos_tokenizados["prueba"].shuffle(seed=42)else: conjunto_entrenamiento_pequeño = conjunto_datos_tokenizados["entrenamiento"].shuffle(seed=42).select(range(num_muestras)) conjunto_evaluacion_pequeño = conjunto_datos_tokenizados["prueba"].shuffle(seed=42).select(range(num_muestras)) Luego, cargamos el modelo pre-entrenado de BERT. Utilizaremos la clase AutoModelForSequenceClassification, un modelo BERT diseñado para tareas de clasificación.
Para este tutorial, utilizaremos la versión ‘bert-base-uncased’ de BERT, que está entrenada en texto en inglés en minúsculas.
# Paso 3: Cargar el modelo pre-entrenadomodelo = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)Ahora, estamos listos para definir nuestros argumentos de entrenamiento y crear una instancia de Trainer para entrenar nuestro modelo.
# Paso 4: Definir los argumentos de entrenamientotraining_args = TrainingArguments("test_trainer", evaluation_strategy="epoch", no_cuda=True, num_train_epochs=num_epocas)# Paso 5: Crear una instancia de Trainer y entrenar el modelotrainer = Trainer( model=modelo, args=training_args, train_dataset=conjunto_entrenamiento_pequeño, eval_dataset=conjunto_evaluacion_pequeño)trainer.train()Interpretación de los Resultados
Después de entrenar nuestro modelo, evaluémoslo. Calcularemos la matriz de confusión y la curva ROC para entender qué tan bien se desempeña nuestro modelo.
# Paso 6: Evaluacióndecisiones = trainer.predict(conjunto_evaluacion_pequeño)# Matriz de confusióncm = confusion_matrix(conjunto_evaluacion_pequeño['etiqueta'], decisiones.predicciones.argmax(-1))sns.heatmap(cm, annot=True, fmt='d')plt.title('Matriz de Confusión')plt.show()# Curva ROCfpr, tpr, _ = roc_curve(conjunto_evaluacion_pequeño['etiqueta'], decisiones.predicciones[:, 1])roc_auc = auc(fpr, tpr)plt.figure(figsize=(1.618 * 5, 5))plt.plot(fpr, tpr, color='darkorange', lw=2, label='Curva ROC (área = %0.2f)' % roc_auc)plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('Tasa de Falsos Positivos')plt.ylabel('Tasa de Verdaderos Positivos')plt.title('Característica de operación del receptor')plt.legend(loc="lower right")plt.show()
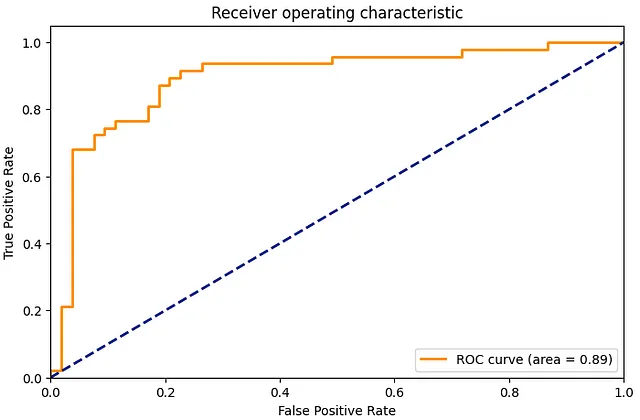
La matriz de confusión proporciona un desglose detallado de cómo nuestras predicciones se comparan con las etiquetas reales, mientras que la curva ROC nos muestra el equilibrio entre la tasa de verdaderos positivos (sensibilidad) y la tasa de falsos positivos (1 – especificidad) en diferentes configuraciones de umbral.
Finalmente, para ver nuestro modelo en acción, vamos a usarlo para inferir el sentimiento de un texto de muestra.
# Paso 7: Inferencia en una nueva muestra
sample_text = "Esta es una película fantástica. Realmente la disfruté."
sample_inputs = tokenizer(sample_text, padding="max_length", truncation=True, max_length=512, return_tensors="pt")
# Mover las entradas al dispositivo (si hay una GPU disponible)
sample_inputs.to(training_args.device)
# Realizar la predicción
predictions = model(**sample_inputs)
predicted_class = predictions.logits.argmax(-1).item()
if predicted_class == 1:
print("Sentimiento positivo")
else:
print("Sentimiento negativo")
Reflexiones finales
Al seguir el ejemplo de análisis de sentimientos en las reseñas de películas de IMDb, espero que hayas obtenido una comprensión clara de cómo aplicar BERT a problemas reales de procesamiento del lenguaje natural. El código Python que he incluido aquí se puede ajustar y ampliar para abordar diferentes tareas y conjuntos de datos, abriendo el camino a modelos de lenguaje aún más sofisticados y precisos.
Referencias
[1] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805
[2] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. En Advances in neural information processing systems (pp. 5998–6008).
[3] Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., … & Rush, A. M. (2019). Huggingface’s transformers: State-of-the-art natural language processing. ArXiv, abs/1910.03771.
[4] Lhoest, Q., Villanova del Moral, A., Jernite, Y., Thakur, A., von Platen, P., Patil, S., Chaumond, J., Drame, M., Plu, J., Tunstall, L., Davison, J., Šaško, M., Chhablani, G., Malik, B., Brandeis, S., Le Scao, T., Sanh, V., Xu, C., Patry, N., McMillan-Major, A., Schmid, P., Gugger, S., Delangue, C., Matussière, T., Debut, L., Bekman, S., Cistac, P., Goehringer, T., Mustar, V., Lagunas, F., Rush, A., & Wolf, T. (2021). Datasets: A Community Library for Natural Language Processing. En Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (pp. 175–184). Online and Punta Cana, Dominican Republic: Association for Computational Linguistics. Recuperado de https://aclanthology.org/2021.emnlp-demo.21
Gracias por leer. Si tienes algún comentario, no dudes en comunicarte dejando un comentario en esta publicación, enviándome un mensaje en LinkedIn o enviándome un correo electrónico (smhkapadia[at]gmail.com)
Si te gustó este artículo, visita mis otros artículos
Adaptación de dominio: Ajuste fino de modelos de procesamiento del lenguaje natural pre-entrenados
Una guía paso a paso para el ajuste fino de modelos de procesamiento del lenguaje natural pre-entrenados para cualquier dominio
towardsdatascience.com
La evolución del procesamiento del lenguaje natural
Una perspectiva histórica sobre el desarrollo de los modelos de lenguaje
VoAGI.com
Sistema de recomendación en Python: LightFM
Una guía paso a paso para construir un sistema de recomendación en Python usando LightFM
towardsdatascience.com
Evaluar modelos de temas: Asignación Latente de Dirichlet (LDA)
Una guía paso a paso para construir modelos de temas interpretables
towardsdatascience.com
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Justin McGill, Fundador y CEO de Content at Scale – Serie de entrevistas
- Conoce a Tongyi Qianwen, el competidor de ChatGPT de Alibaba un modelo de lenguaje grande que se integrará en sus altavoces inteligentes Tmall Genie y en la plataforma de mensajería laboral DingTalk.
- Sobre el aprendizaje en presencia de grupos subrepresentados
- Desbloqueando los secretos de la Dimensión de Cambio Lento (SCD) Una Visión Integral de 8 Tipos
- Crea tu propio sitio web impresionante en minutos de forma gratuita
- Creando gráficos científicos de forma sencilla con scienceplots y matplotlib
- Hacia la Agnosticidad de Herramientas en Ciencia de Datos SQL Case When y Pandas Where






