Comenzando con JAX
'Introducción a JAX'
Impulsando el futuro de la computación numérica de alto rendimiento y la investigación en ML
Introducción
JAX es una biblioteca de Python desarrollada por Google para realizar computación numérica de alto rendimiento en cualquier tipo de dispositivo (CPU, GPU, TPU, etc.). Una de las principales aplicaciones de JAX es la investigación y el desarrollo de aprendizaje automático y aprendizaje profundo, aunque la biblioteca está diseñada principalmente para proporcionar todas las capacidades necesarias para realizar tareas de computación científica de propósito general (operaciones de matrices de alta dimensionalidad, etc.).
Teniendo en cuenta el enfoque específico en la computación de alto rendimiento, JAX ha sido diseñado para ser extremadamente rápido, ya que se construye sobre XLA (Álgebra Lineal Acelerada). XLA es en realidad un compilador diseñado para acelerar las operaciones de álgebra lineal y se puede utilizar también en otros frameworks como TensorFlow y Pytorch. Además, las matrices de JAX han sido diseñadas para seguir los mismos principios que Numpy, lo que facilita la migración de código antiguo de Numpy a JAX y aprovechar las mejoras de rendimiento a través de GPU y TPU.
Algunas de las principales características de JAX son:
- Compilación Just in Time (JIT): La compilación JIT y el hardware acelerado son lo que permite que JAX sea mucho más rápido que Numpy común. Usando la función jit() es posible compilar y almacenar en caché funciones personalizadas con el kernel XLA. Al utilizar la caché, aumentaremos el tiempo de ejecución general cuando ejecutamos la función por primera vez, para luego reducir drásticamente el tiempo en ejecuciones posteriores. Cuando se utiliza la caché, es importante asegurarse de borrar la caché cuando sea necesario para evitar resultados obsoletos (por ejemplo, cambios en las variables globales).
- Paralelización Automática: La Despacho Asíncrono permite que los vectores de JAX se evalúen de forma perezosa, materializando el contenido solo cuando se accede a él (el control se devuelve al programa antes de que se complete la computación). Además, para posibilitar la optimización de gráficos, las matrices de JAX son inmutables (los conceptos similares con la evaluación perezosa y la optimización de gráficos se aplican a Apache Spark). La función pmap() se puede utilizar para paralelizar cálculos en varias GPU/TPU.
- Vectorización Automática: La vectorización automática para paralelizar operaciones se puede realizar utilizando la función vmap(). Durante la vectorización, se transforma un algoritmo que opera con un solo valor en un conjunto de valores.
- Diferenciación Automática: La función grad() se puede utilizar para calcular automáticamente el gradiente (derivada) de funciones. En particular, la Diferenciación Automática de JAX permite el desarrollo de programas diferenciales de propósito general fuera del ámbito del Aprendizaje Profundo. Lo que hace posible diferenciar a través de la recursión, las ramas, los bucles, realizar diferenciación de orden superior (por ejemplo, Jacobianos y Hessians) y utilizar tanto la diferenciación de modo directo como la de modo inverso.
Por lo tanto, JAX nos proporciona todas las bases necesarias para construir modelos avanzados de Aprendizaje Profundo, pero no proporciona utilidades de alto nivel listas para usar para algunas de las operaciones de Aprendizaje Profundo más comunes (por ejemplo, funciones de pérdida/activación, capas, etc.). Por ejemplo, los parámetros del modelo aprendidos durante el entrenamiento de ML se pueden almacenar en una estructura Pytree en JAX. Teniendo en cuenta todas las ventajas proporcionadas por JAX, se han construido frameworks orientados al DL que se basan en él, como Haiku (utilizado por DeepMind) y Flax (utilizado por Google Brain).
- Selección activa de políticas sin conexión.
- Un agente generalista
- Comportamiento emergente de trueque en el aprendizaje por refuerzo de múltiples agentes
Demostración
Como parte de este artículo, vamos a ver cómo resolver un problema de clasificación simple usando JAX y el conjunto de datos de clasificación de precios de teléfonos móviles de Kaggle [1] para predecir en qué rango de precios estará un teléfono. Todo el código utilizado a lo largo de este artículo (¡y más!) está disponible en mis cuentas de GitHub y Kaggle.
En primer lugar, debemos asegurarnos de tener JAX instalado en nuestro entorno.
pip install jaxEn este punto, estamos listos para importar las bibliotecas y conjuntos de datos necesarios (Figura 1). Para simplificar nuestro análisis, en lugar de usar todas las clases en nuestra etiqueta, filtramos los datos para usar solo 2 clases y reducir el número de características.
import pandas as pdimport jax.numpy as jnpfrom jax import gradfrom sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import classification_reportimport matplotlib.pyplot as pltdf = pd.read_csv('/kaggle/input/mobile-price-classification/train.csv')df = df.iloc[:, 10:]df = df.loc[df['price_range'] <= 1]df.head()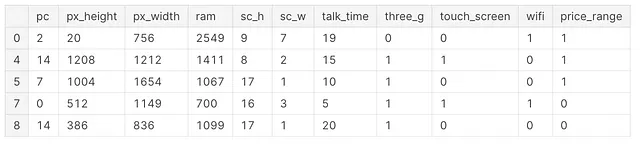
Una vez limpiado el conjunto de datos, ahora podemos dividirlo en subconjuntos de entrenamiento y prueba y estandarizar las características de entrada para asegurarnos de que todas se encuentren dentro del mismo rango. En este punto, los datos de entrada también se convierten en arreglos JAX.
X = df.iloc[:, :-1]y = df.iloc[:, -1]X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, stratify=y)X_train, X_test, y_train, Y_test = jnp.array(X_train), jnp.array(X_test), \ jnp.array(y_train), jnp.array(y_test)scaler = StandardScaler()scaler.fit(X_train)X_train = scaler.transform(X_train)X_test = scaler.transform(X_test)Para predecir el rango de precios de los teléfonos, vamos a crear un modelo de Regresión Logística desde cero. Para hacerlo, primero necesitamos crear un par de funciones auxiliares (una para crear la función de activación Sigmoidal y otra para la función de pérdida binaria).
def activation(r): return 1 / (1 + jnp.exp(-r))def loss(c, w, X, y, lmbd=0.1): p = activation(jnp.dot(X, w) + c) loss = jnp.sum(y * jnp.log(p) + (1 - y) * jnp.log(1 - p)) / y.size reg = 0.5 * lmbd * (jnp.dot(w, w) + c * c) return - loss + reg Estamos listos para crear nuestro bucle de entrenamiento y graficar los resultados (Figura 2).
n_iter, eta = 100, 1e-1w = 1.0e-5 * jnp.ones(X.shape[1])c = 1.0history = [float(loss(c, w, X_train, y_train))]for i in range(n_iter): c_current = c c -= eta * grad(loss, argnums=0)(c_current, w, X_train, y_train) w -= eta * grad(loss, argnums=1)(c_current, w, X_train, y_train) history.append(float(loss(c, w, X_train, y_train)))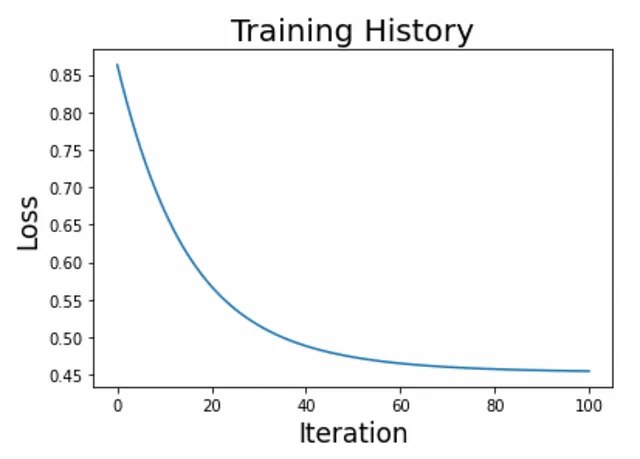
Una vez satisfechos con los resultados, podemos probar el modelo con nuestro conjunto de prueba (Figura 3).
y_pred = jnp.array(activation(jnp.dot(X_test, w) + c))y_pred = jnp.where(y_pred > 0.5, 1, 0) print(classification_report(y_test, y_pred))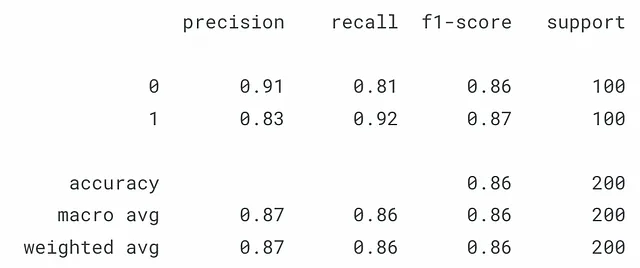
Conclusión
Como se demuestra en este breve ejemplo, JAX tiene una API muy intuitiva que sigue de cerca las convenciones de Numpy y al mismo tiempo permite usar el mismo código para el uso de CPU/GPU/TPU. Utilizando estos bloques de construcción, es posible crear modelos de Aprendizaje Profundo altamente personalizables y optimizados para un rendimiento óptimo.
Contactos
Si desea mantenerse actualizado con mis últimos artículos y proyectos, sígame en VoAGI y suscríbase a mi lista de correo. Estos son algunos de mis detalles de contacto:
- Sitio web personal
- Perfil de VoAGI
- GitHub
- Kaggle
Bibliografía
[1] “Clasificación de precios de teléfonos móviles” (ABHISHEK SHARMA). Accedido en: https://thecleverprogrammer.com/2021/03/05/clasificacion-de-precios-de-telefonos-moviles-con-aprendizaje-automatico/ (Licencia MIT: https://github.com/alifrmf/Análisis-de-Clasificación-y-Predicción-de-Precios-de-Teléfonos-Móviles)
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Aprendizaje de física intuitiva en un modelo de aprendizaje profundo inspirado en la psicología del desarrollo
- El ciclo virtuoso de la investigación en IA
- De control de motor a inteligencia encarnada
- En conversación con la IA construyendo mejores modelos de lenguaje
- Mi viaje desde ser pasante de DeepMind hasta mentor
- Maximizando el impacto de nuestros avances
- Cómo nuestros principios ayudaron a definir el lanzamiento de AlphaFold






