Introducción a las bases de datos en la ciencia de datos
Introducción a bases de datos en ciencia de datos

La ciencia de datos implica extraer valor y conocimientos de grandes volúmenes de datos para impulsar decisiones empresariales. También implica construir modelos predictivos utilizando datos históricos. Las bases de datos facilitan el almacenamiento, gestión, recuperación y análisis efectivos de estos grandes volúmenes de datos.
Por lo tanto, como científico de datos, debes entender los fundamentos de las bases de datos. Porque permiten el almacenamiento y la gestión de conjuntos de datos grandes y complejos, lo que permite una exploración eficiente de datos, modelado y obtención de conocimientos. Vamos a explorar esto con más detalle en este artículo.
Comenzaremos discutiendo las habilidades esenciales de bases de datos para la ciencia de datos, incluyendo SQL para la recuperación de datos, diseño de bases de datos, optimización y mucho más. Luego revisaremos los principales tipos de bases de datos, sus ventajas y casos de uso.
- ¿Cómo construir LLMs para código?
- AR y AI El papel de la IA en la Realidad Aumentada
- Conoce a MetaGPT El asistente de IA impulsado por ChatGPT que convierte texto en aplicaciones web.
Habilidades esenciales de bases de datos para la ciencia de datos
Las habilidades de bases de datos son esenciales para los científicos de datos, ya que proporcionan la base para una gestión, análisis e interpretación efectivos de los datos.
Aquí hay un desglose de las habilidades clave de bases de datos que los científicos de datos deben entender:
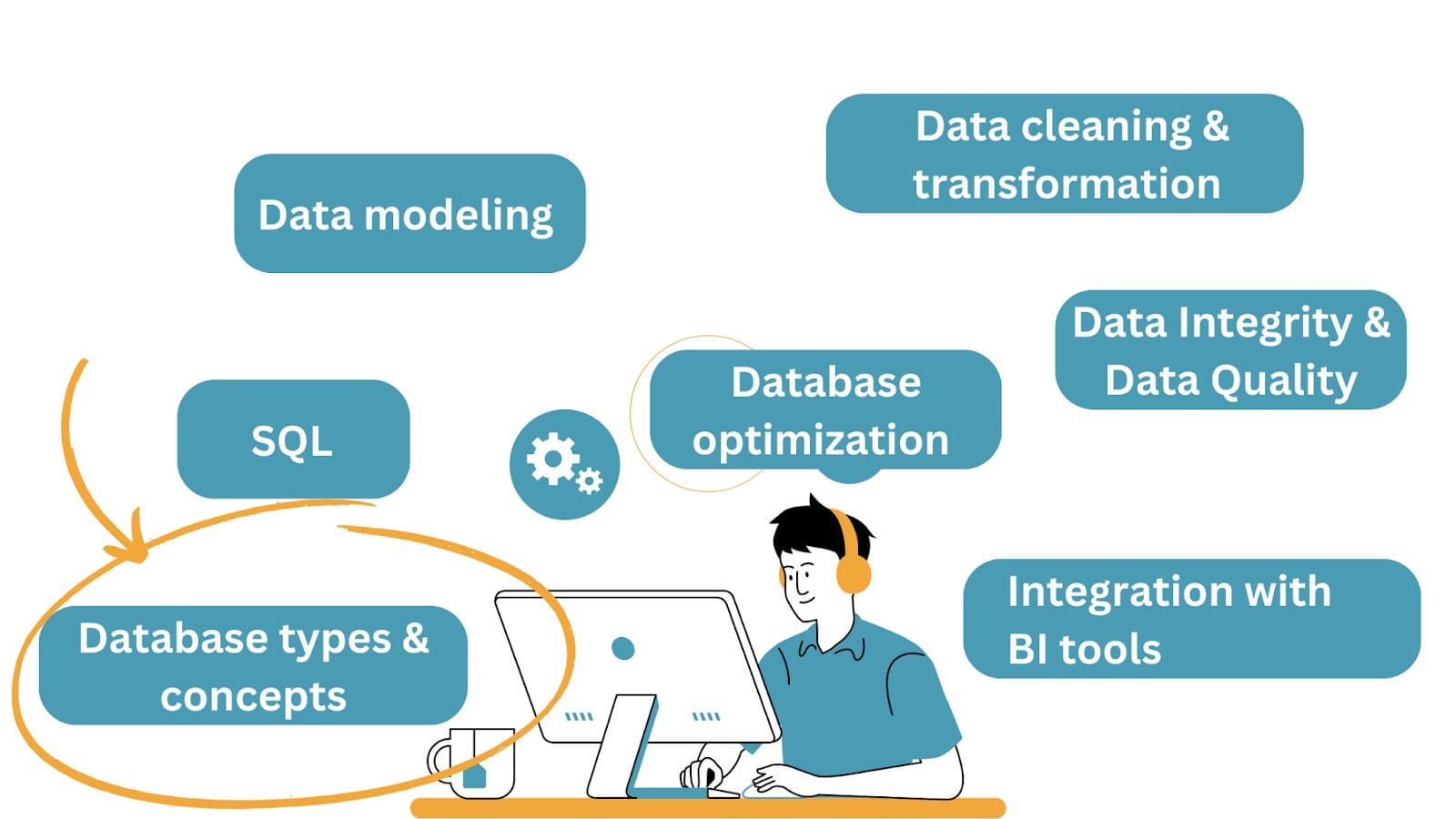
Aunque hemos tratado de categorizar los conceptos y habilidades de bases de datos en diferentes grupos, van juntos. Y a menudo necesitarás conocerlos o aprenderlos en el camino al trabajar en proyectos.
Ahora veamos cada uno de los anteriores.
1. Tipos y conceptos de bases de datos
Como científico de datos, debes tener un buen entendimiento de los diferentes tipos de bases de datos, como bases de datos relacionales y NoSQL, y sus respectivos casos de uso.
2. SQL (Lenguaje de consulta estructurado) para la recuperación de datos
La competencia en SQL, lograda a través de la práctica, es imprescindible para cualquier rol en el ámbito de los datos. Debes ser capaz de escribir y optimizar consultas SQL para recuperar, filtrar, agregar y unir datos de las bases de datos.
También es útil entender los planes de ejecución de consultas y ser capaz de identificar y resolver cuellos de botella de rendimiento.
3. Modelado de datos y diseño de bases de datos
Además de consultar tablas de bases de datos, debes entender los conceptos básicos de modelado de datos y diseño de bases de datos, incluyendo diagramas entidad-relación (ER), diseño de esquemas y restricciones de validación de datos.
También debes ser capaz de diseñar esquemas de bases de datos que soporten consultas eficientes y almacenamiento de datos para fines analíticos.
4. Limpieza y transformación de datos
Como científico de datos, tendrás que preprocesar y transformar datos en bruto en un formato adecuado para el análisis. Las bases de datos pueden soportar tareas de limpieza, transformación e integración de datos.
Por lo tanto, debes saber cómo extraer datos de diversas fuentes, transformarlos en un formato adecuado y cargarlos en bases de datos para su análisis. Es importante estar familiarizado con herramientas ETL, lenguajes de script (Python, R) y técnicas de transformación de datos.
5. Optimización de bases de datos
Debes estar al tanto de técnicas para optimizar el rendimiento de las bases de datos, como la creación de índices, la desnormalización y el uso de mecanismos de caché.
Para optimizar el rendimiento de las bases de datos, se utilizan índices para acelerar la recuperación de datos. La indexación adecuada mejora los tiempos de respuesta de las consultas al permitir que el motor de la base de datos localice rápidamente los datos requeridos.
6. Integridad y verificación de calidad de datos
La integridad de los datos se mantiene a través de restricciones que definen reglas para la entrada de datos. Restricciones como únicas, no nulas y de verificación aseguran la precisión y confiabilidad de los datos.
Las transacciones se utilizan para garantizar la consistencia de los datos, asegurando que múltiples operaciones se traten como una unidad única y atómica.
7. Integración con herramientas y lenguajes
Las bases de datos pueden integrarse con herramientas populares de análisis y visualización, lo que permite a los científicos de datos analizar y presentar sus hallazgos de manera efectiva. Por lo tanto, debes saber cómo conectarte e interactuar con bases de datos utilizando lenguajes de programación como Python, y realizar análisis de datos.
Es necesario tener familiaridad con herramientas como pandas de Python, R y bibliotecas de visualización.
En resumen: entender varios tipos de bases de datos, SQL, modelado de datos, procesos ETL, optimización de rendimiento, integridad de datos e integración con lenguajes de programación son componentes clave del conjunto de habilidades de un científico de datos.
En el resto de esta guía introductoria, nos centraremos en conceptos fundamentales de bases de datos y tipos.
Fundamentos de las bases de datos relacionales
Las bases de datos relacionales son un tipo de sistema de gestión de bases de datos (DBMS) que organizan y almacenan datos de manera estructurada utilizando tablas con filas y columnas. Algunos RDBMS populares incluyen PostgreSQL, MySQL, Microsoft SQL Server y Oracle.
Sumergámonos en algunos conceptos clave de bases de datos relacionales utilizando ejemplos.
Tablas de bases de datos relacionales
En una base de datos relacional, cada tabla representa una entidad específica y las relaciones entre las tablas se establecen mediante claves.
Para entender cómo se organiza la información en las tablas de bases de datos relacionales, es útil comenzar con las entidades y los atributos.
Frecuentemente, querrás almacenar información sobre objetos: estudiantes, clientes, órdenes, productos, entre otros. Estos objetos son entidades y tienen atributos.
Tomemos el ejemplo de una entidad simple, un objeto “Estudiante” con tres atributos: Nombre, Apellido y Calificación. Al almacenar los datos, la entidad se convierte en una tabla de base de datos y los atributos son los nombres de las columnas o campos. Y cada fila es una instancia de una entidad.
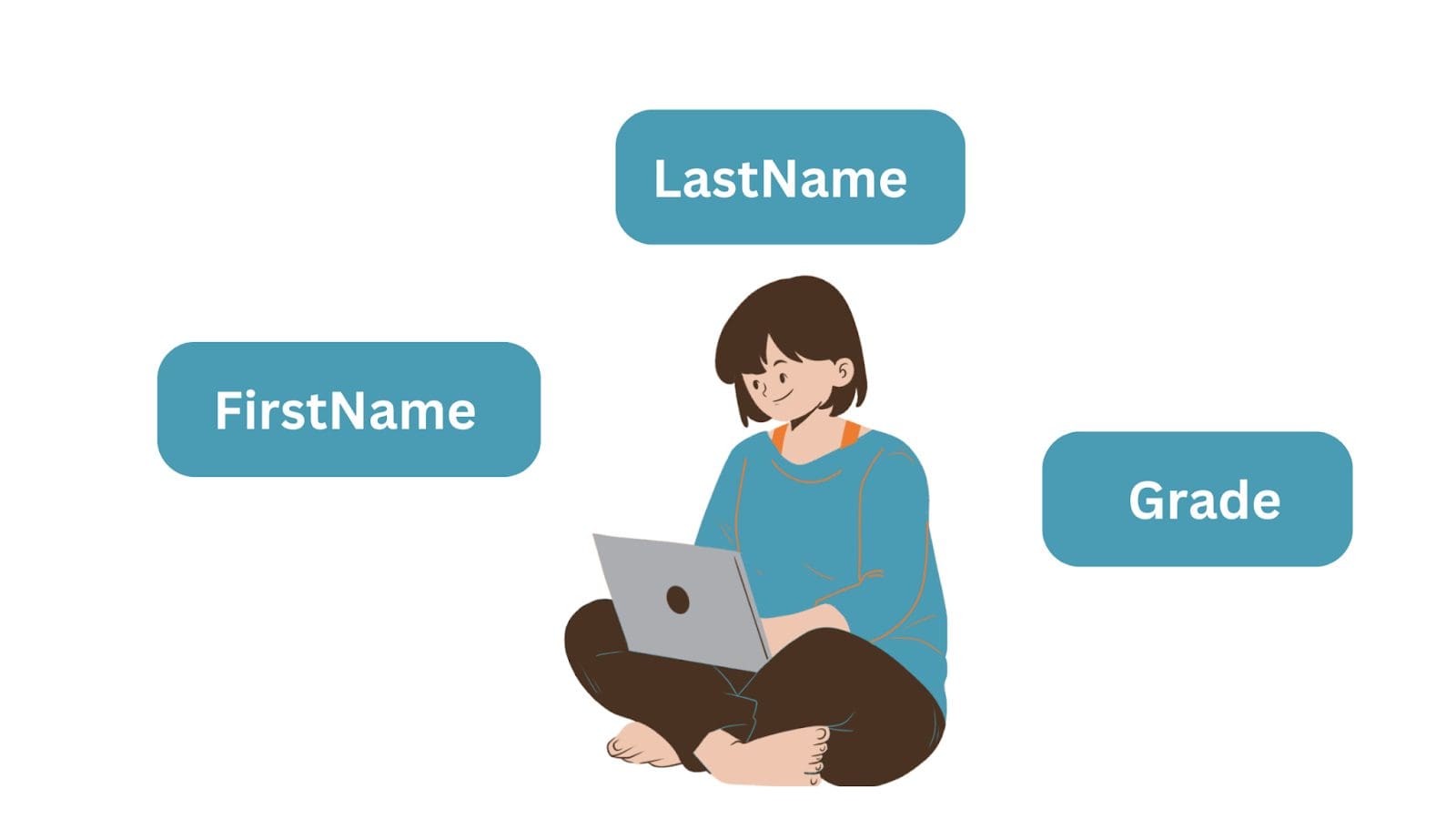
Las tablas en una base de datos relacional consisten en filas y columnas:
- Las filas también se conocen como registros o tuplas, y
- Las columnas se denominan atributos o campos.
Aquí tienes un ejemplo de una tabla simple de “Estudiantes”:
| ID del estudiante | Nombre | Apellido | Calificación |
| 1 | Jane | Smith | A+ |
| 2 | Emily | Brown | A |
| 3 | Jake | Williams | B+ |
En este ejemplo, cada fila representa un estudiante y cada columna representa una pieza de información sobre el estudiante.
Entendiendo las claves
Las claves se utilizan para identificar de manera única las filas dentro de una tabla. Los dos tipos importantes de claves incluyen:
- Clave primaria: una clave primaria identifica de manera única cada fila en una tabla. Garantiza la integridad de los datos y proporciona una forma de hacer referencia a registros específicos. En la tabla “Estudiantes”, “ID del estudiante” podría ser la clave primaria.
- Clave foránea: una clave foránea establece una relación entre tablas. Se refiere a la clave primaria de otra tabla y se utiliza para vincular datos relacionados. Por ejemplo, si tenemos otra tabla llamada “Cursos”, la columna “ID del estudiante” en la tabla “Cursos” podría ser una clave foránea que hace referencia al “ID del estudiante” en la tabla “Estudiantes”.
Relaciones
Las bases de datos relacionales te permiten establecer relaciones entre tablas. Aquí están las relaciones más importantes y comúnmente presentes:
- Relación Uno a Uno: Bajo una relación uno a uno, cada registro en una tabla está relacionado con uno, y solo uno, registro en otra tabla en la base de datos. Por ejemplo, una tabla “DetallesEstudiante” con información adicional sobre cada estudiante puede tener una relación uno a uno con la tabla “Estudiantes”.
- Relación Uno a Muchos: Un registro en la primera tabla está relacionado con múltiples registros en la segunda tabla. Por ejemplo, una tabla “Cursos” podría tener una relación uno a muchos con la tabla “Estudiantes”, donde cada curso está asociado con múltiples estudiantes.
- Relación Muchos a Muchos: Múltiples registros en ambas tablas están relacionados entre sí. Para representar esto, se utiliza una tabla intermedia, a menudo llamada tabla de enlace o de unión. Por ejemplo, una tabla “EstudiantesCursos” podría establecer una relación muchos a muchos entre estudiantes y cursos.
Normalización
La normalización (discutida a menudo en técnicas de optimización de bases de datos) es el proceso de organizar los datos de manera que se minimice la redundancia de datos y se mejore la integridad de los datos. Implica descomponer tablas grandes en tablas más pequeñas y relacionadas. Cada tabla debe representar una entidad o concepto único para evitar duplicar datos.
Por ejemplo, si consideramos la tabla “Estudiantes” y una tabla hipotética “Direcciones”, la normalización podría implicar crear una tabla separada “Direcciones” con su propia clave primaria y vincularla a la tabla “Estudiantes” utilizando una clave externa.
Ventajas y Limitaciones de las Bases de Datos Relacionales
Aquí hay algunas ventajas de las bases de datos relacionales:
- Las bases de datos relacionales proporcionan una forma estructurada y organizada de almacenar datos, lo que facilita definir relaciones entre diferentes tipos de datos.
- Además, admiten las propiedades ACID (Atomicidad, Consistencia, Aislamiento, Durabilidad) para transacciones, asegurando que los datos se mantengan consistentes.
Por otro lado, tienen las siguientes limitaciones:
- Las bases de datos relacionales presentan desafíos con la escalabilidad horizontal, lo que dificulta manejar grandes cantidades de datos y altas cargas de tráfico.
- También requieren un esquema rígido, lo que dificulta adaptarse a cambios en la estructura de datos sin modificar el esquema.
- Las bases de datos relacionales están diseñadas para datos estructurados con relaciones bien definidas. Pueden no ser adecuadas para almacenar datos no estructurados o semi-estructurados como documentos, imágenes y contenido multimedia.
Explorando Bases de Datos NoSQL
Las bases de datos NoSQL no almacenan datos en tablas en el formato familiar de filas y columnas (son no relacionales). El término “NoSQL” significa “no solo SQL”, lo que indica que estas bases de datos difieren del modelo relacional tradicional.
Las principales ventajas de las bases de datos NoSQL son su escalabilidad y flexibilidad. Estas bases de datos están diseñadas para manejar grandes volúmenes de datos no estructurados o semi-estructurados y proporcionar soluciones más flexibles y escalables en comparación con las bases de datos relacionales tradicionales.
Las bases de datos NoSQL engloban una variedad de tipos de bases de datos que difieren en sus modelos de datos, mecanismos de almacenamiento y lenguajes de consulta. Algunas categorías comunes de bases de datos NoSQL incluyen:
- Almacenes de clave-valor
- Bases de datos de documentos
- Bases de datos de columnas familiares
- Bases de datos de grafos
Ahora, repasemos cada una de las categorías de bases de datos NoSQL, explorando sus características, casos de uso, ejemplos, ventajas y limitaciones.
Almacenes de Clave-Valor
Los almacenes de clave-valor almacenan datos como simples pares de claves y valores. Están optimizados para operaciones de lectura y escritura de alta velocidad. Son adecuados para aplicaciones como almacenamiento en caché, gestión de sesiones y análisis en tiempo real.
Estas bases de datos, sin embargo, tienen capacidades de consulta limitadas más allá de la recuperación basada en claves. Por lo tanto, no son adecuadas para relaciones complejas.
Amazon DynamoDB y Redis son almacenes de clave-valor populares.
Bases de Datos de Documentos
Las bases de datos de documentos almacenan datos en formatos de documentos como JSON y BSON. Cada documento puede tener estructuras variables, lo que permite datos anidados y complejos. Su esquema flexible permite manejar fácilmente datos semi-estructurados, admitiendo modelos de datos en evolución y relaciones jerárquicas.
Estos son especialmente adecuados para la gestión de contenido, plataformas de comercio electrónico, catálogos, perfiles de usuarios y aplicaciones con estructuras de datos cambiantes. Las bases de datos de documentos pueden no ser tan eficientes para uniones complejas o consultas complejas que involucren múltiples documentos.
MongoDB y Couchbase son bases de datos de documentos populares.
Column-Family Stores (Almacenes de Columna Ancha)
Los almacenes de familia de columnas, también conocidos como bases de datos columnares o bases de datos orientadas a columnas, son un tipo de base de datos NoSQL que organiza y almacena datos de manera columnar en lugar de la forma tradicional orientada a filas de las bases de datos relacionales.
Los almacenes de familia de columnas son adecuados para cargas de trabajo analíticas que implican ejecutar consultas complejas en conjuntos de datos grandes. Las agregaciones, filtrado y transformaciones de datos se realizan con mayor eficiencia en bases de datos de familia de columnas. Son útiles para administrar grandes cantidades de datos semi-estructurados o dispersos.
Apache Cassandra, ScyllaDB y HBase son algunos almacenes de familia de columnas.
Bases de Datos de Grafos
Las bases de datos de grafos modelan datos y relaciones en nodos y aristas, respectivamente, para representar relaciones complejas. Estas bases de datos admiten el manejo eficiente de relaciones complejas y lenguajes de consulta de gráficos potentes.
Como puedes imaginar, estas bases de datos son adecuadas para redes sociales, motores de recomendación, grafos de conocimiento y, en general, datos con relaciones intrincadas.
Algunos ejemplos de bases de datos de grafos populares son Neo4j y Amazon Neptune.
Existen muchos tipos de bases de datos NoSQL. Entonces, ¿cómo decidimos cuál usar? Bueno. La respuesta es: depende.
Cada categoría de base de datos NoSQL ofrece características y beneficios únicos, lo que las hace adecuadas para casos de uso específicos. Es importante elegir la base de datos NoSQL adecuada teniendo en cuenta los patrones de acceso, los requisitos de escalabilidad y las consideraciones de rendimiento.
En resumen: las bases de datos NoSQL ofrecen ventajas en términos de flexibilidad, escalabilidad y rendimiento, lo que las hace adecuadas para una amplia gama de aplicaciones, incluyendo big data, análisis en tiempo real y aplicaciones web dinámicas. Sin embargo, tienen compensaciones en términos de consistencia de datos.
Ventajas y Limitaciones de las Bases de Datos NoSQL
A continuación se muestran algunas ventajas de las bases de datos NoSQL:
- Las bases de datos NoSQL están diseñadas para la escalabilidad horizontal, lo que les permite manejar grandes cantidades de datos y tráfico.
- Estas bases de datos permiten esquemas flexibles y dinámicos. Tienen modelos de datos flexibles para acomodar varios tipos y estructuras de datos, lo que las hace adecuadas para datos no estructurados o semi-estructurados.
- Muchas bases de datos NoSQL están diseñadas para operar en entornos distribuidos y tolerantes a fallos, proporcionando alta disponibilidad incluso en presencia de fallas de hardware o interrupciones de red.
- Pueden manejar datos no estructurados o semi-estructurados, lo que las hace adecuadas para aplicaciones que tratan con diversos tipos de datos.
Algunas limitaciones incluyen:
- Las bases de datos NoSQL priorizan la escalabilidad y el rendimiento sobre el cumplimiento estricto de ACID. Esto puede resultar en consistencia eventual y puede no ser adecuado para aplicaciones que requieren una fuerte consistencia de datos.
- Debido a que las bases de datos NoSQL vienen en diferentes variantes con diferentes APIs y modelos de datos, la falta de estandarización puede dificultar el cambio entre bases de datos o integrarlas de manera transparente.
Es importante tener en cuenta que las bases de datos NoSQL no son una solución única para todos los casos. La elección entre una base de datos NoSQL y una base de datos relacional depende de las necesidades específicas de tu aplicación, incluyendo el volumen de datos, los patrones de consulta y los requisitos de escalabilidad, entre otros.
Bases de Datos Relacionales vs. Bases de Datos NoSQL
Resumamos las diferencias que hemos discutido hasta ahora:
| Característica | Bases de Datos Relacionales | Bases de Datos NoSQL |
| Modelo de Datos | Estructura tabular (tablas) | Diversos modelos de datos (documentos, pares clave-valor, grafos, columnas, etc.) |
| Consistencia de Datos | Consistencia fuerte | Consistencia eventual |
| Esquema | Esquema bien definido | Flexible o sin esquema |
| Relaciones de Datos | Admite relaciones complejas | Varía según el tipo (relaciones limitadas o explícitas) |
| Lenguaje de Consulta | Consultas basadas en SQL | Lenguaje de consulta específico o APIs |
| Flexibilidad | No tan flexible para datos no estructurados | Adecuado para diversos tipos de datos, incluyendo |
| Casos de Uso | Datos bien estructurados, transacciones complejas | Aplicaciones a gran escala, alto rendimiento, en tiempo real |
Una nota sobre las bases de datos de series de tiempo
Como científico de datos, también trabajarás con datos de series de tiempo. Las bases de datos de series de tiempo también son bases de datos no relacionales, pero tienen un caso de uso más específico.
Necesitan soportar el almacenamiento, gestión y consulta de puntos de datos con marca de tiempo, es decir, puntos de datos que se registran a lo largo del tiempo, como lecturas de sensores y precios de acciones. Ofrecen características especializadas para almacenar, consultar y analizar patrones de datos basados en el tiempo.
Algunos ejemplos de bases de datos de series de tiempo incluyen InfluxDB, QuestDB y TimescaleDB.
Conclusión
En esta guía, repasamos las bases de datos relacionales y NoSQL. También vale la pena señalar que puedes explorar algunas bases de datos más allá de los tipos populares relacionales y NoSQL. Las bases de datos NewSQL, como CockroachDB, ofrecen los beneficios tradicionales de las bases de datos SQL al tiempo que proporcionan la escalabilidad y el rendimiento de las bases de datos NoSQL.
También puedes usar una base de datos en memoria que almacena y gestiona datos principalmente en la memoria principal (RAM) de una computadora, a diferencia de las bases de datos tradicionales que almacenan datos en disco. Este enfoque ofrece beneficios significativos en rendimiento debido a las operaciones de lectura y escritura mucho más rápidas que se pueden realizar en la memoria en comparación con el almacenamiento en disco. Bala Priya C es una desarrolladora y redactora técnica de India. Le gusta trabajar en la intersección de las matemáticas, la programación, la ciencia de datos y la creación de contenido. Sus áreas de interés y experiencia incluyen DevOps, ciencia de datos y procesamiento de lenguaje natural. Le gusta leer, escribir, programar y tomar café. Actualmente, está trabajando en aprender y compartir sus conocimientos con la comunidad de desarrolladores mediante la creación de tutoriales, guías prácticas, artículos de opinión y más.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Emocionante lanzamiento Anunciando cursos gratuitos de GenAI Nano
- Programación Orientada a Objetos (POO) en Python – para principiantes (Parte 1)
- Aprovechando los datos geoespaciales en Python con GeoPandas
- Generación eficiente y controlable para SDXL con adaptadores T2I
- Cómo crear el Chatbot LLaMa 2 con Gradio y Hugging Face en Free Colab.
- Esta investigación de IA revoluciona el diseño del modulador Mach-Zehnder de silicio a través del aprendizaje profundo y algoritmos evolutivos
- Tiempo 100 IA ¿Los más influyentes?






