Inmersión profunda en las Unidades Recurrentes con Puertas (GRU) Entendiendo las Matemáticas detrás de las RNN
Inmersión profunda en las GRU Entendiendo las Matemáticas detrás de las RNN
La Unidad Recurrente con Puerta (GRU, por sus siglas en inglés) es una versión simplificada de la Memoria a Corto Plazo de Longitud Variable (LSTM, por sus siglas en inglés). Veamos cómo funciona en este artículo.
Este artículo explicará el funcionamiento de las unidades recurrentes con puerta (GRUs). Dado que las GRUs se pueden entender fácilmente si tenemos conocimiento previo de la Memoria a Corto Plazo de Longitud Variable (LSTMs), recomiendo encarecidamente aprender sobre las LSTMs de antemano. Puedes consultar mi artículo sobre LSTMs.
De las RNNs básicas a las LSTMs: Una guía práctica para la Memoria a Corto Plazo de Longitud Variable | por Shivamshinde | Ene, 2023 | VoAGI
Las unidades recurrentes con puerta, también conocidas como GRUs, son una versión simplificada de las unidades de Memoria a Corto Plazo de Longitud Variable (LSTM). Ambas se utilizan para que nuestra red neuronal recurrente retenga información útil durante más tiempo. Ambas son igualmente buenas. El rendimiento de ambas variará según el caso de uso. Para un caso de uso, las LSTMs pueden funcionar mejor y para otro caso las GRUs pueden funcionar mejor, tendremos que probar ambas y luego utilizar la que tenga un rendimiento más alto para nuestro entrenamiento de modelo real.
- Explorando NLP – Comenzando con NLP (Paso #1)
- Explorando el Procesamiento del Lenguaje Natural – Inicio de NLP (Paso #2)
- Explorando NLP – Iniciando NLP (Paso #3)
Sin embargo, hay algunas ventajas de utilizar GRUs en tu red.
- Como veremos en este artículo, las GRUs tienen dos puertas, lo que las hace más rápidas de entrenar. Esto es útil cuando tienes menos memoria y capacidad de procesamiento.
- También obtienen excelentes resultados en conjuntos de datos pequeños.
Ahora entendamos cómo funcionan las GRUs.
Observa el significado de los símbolos en los siguientes diagramas:

Significado de las variables en las siguientes ecuaciones
Wxz, Wxr, Wxg son las matrices de pesos de cada una de las tres puertas para su conexión con el vector de entrada x(t).
Whz, Whr, Whg son las matrices de pesos de cada una de las tres puertas para su conexión con el estado anterior h(t-1).
bz, br, bg son los términos de sesgo para cada una de las tres puertas.
Información básica sobre las GRUs
A nivel alto, las GRUs se pueden considerar como una versión mejorada de las unidades RNN simples con el mismo número de entradas y salidas. Sin embargo, la estructura interna de las GRUs es ligeramente diferente.
A diferencia de las LSTMs, las GRUs tienen solo un vector de estado. Se podría decir que los vectores de largo plazo y corto plazo se combinan en uno solo en el caso de las GRUs.
Las GRUs están compuestas por tres bloques. Ellos son:
- Bloque RNN básico, g(t)
- Una puerta que se encarga de olvidar información inútil y recordar la nueva información importante, z(t)
- Una puerta que determina qué parte del estado anterior se debe utilizar como entrada, r(t)
Las GRUs toman dos entradas. Ellos son:
- Estado anterior de la celda, h(t-1)
- Entrada de datos de entrenamiento, x(t)
La celda de la GRU produce dos términos de salida. Ellos son:
- Estado actual de la celda, h(t)
- Predicción para la celda actual, y(t)
Ahora, entendamos cómo se calcula cada una de las salidas utilizando las entradas.
Calculando el estado actual de la celda
Básicamente, el estado de la celda se encuentra mediante la suma de dos cantidades. La primera cantidad nos dice cuánto se debe olvidar del estado anterior. Y la segunda cantidad nos dice cuánto se debe recordar de la entrada de datos de entrenamiento.
Entendamos la primera cantidad.
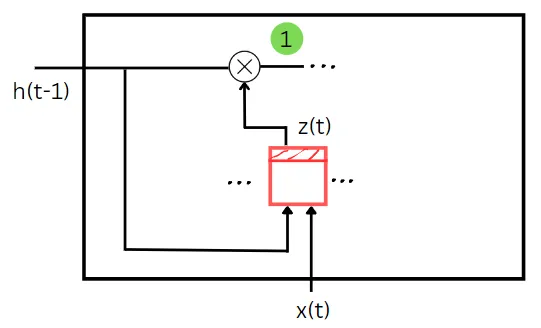
Como se puede ver en el diagrama anterior, z(t) toma el estado anterior y los datos de entrenamiento como entrada. Actúa como una compuerta de olvido aquí. El valor de la compuerta z(t) determina qué parte del estado anterior debe ser olvidada en este paso de tiempo. El estado anterior y la entrada de entrenamiento se multiplican por sus pesos correspondientes y se suma el sesgo a su suma. Después de aplicar una función sigmoide a esta suma, obtendremos el valor de z(t). La multiplicación elemento a elemento del estado anterior y el valor de z(t) nos da la primera cantidad que necesitamos para calcular el estado del paso de tiempo actual. La primera cantidad se muestra en color verde en el diagrama anterior.
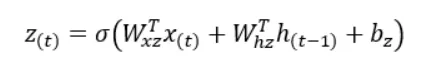
Entendamos la segunda cantidad.
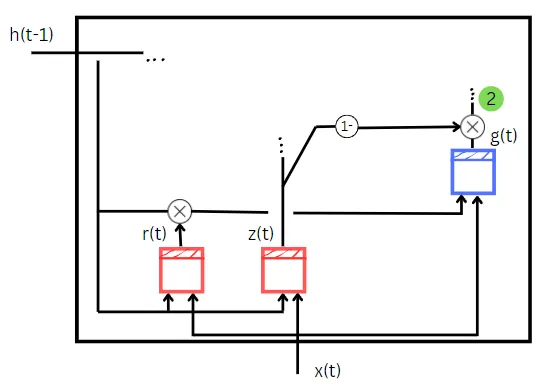
El valor de z(t) se calcula como se explicó en el cálculo de la primera cantidad. Pero aquí (1 – z(t)) actúa como una compuerta de entrada. La celda RNN básica g(t) toma dos entradas. Son
- Entrada de datos de entrenamiento, x(t)
- Multiplicación elemento a elemento de r(t) y el estado anterior, h(t-1)
El cálculo para encontrar r(t) es el mismo que el de z(t) excepto por los pesos y sesgos utilizados en el cálculo. El valor de r(t) nos dice qué parte del estado anterior debe ser dada como entrada a la celda RNN simple g(t).
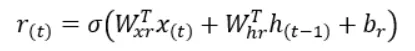
Ambas entradas de g(t) se multiplican por sus pesos correspondientes y luego se suma el término de sesgo a su suma. Luego, este valor de suma final se pasa a la función tangente hiperbólica, dándonos el valor de g(t).
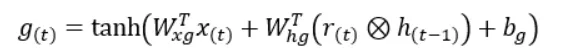
Ahora, la multiplicación elemento a elemento de g(t) con (1 – z(t)), también conocida como compuerta de entrada, nos dará la segunda cantidad requerida para calcular el estado del paso de tiempo actual. La segunda cantidad se muestra en color verde en el diagrama anterior.
Ahora que hemos encontrado ambas cantidades, su suma nos dará el estado del paso de tiempo actual.
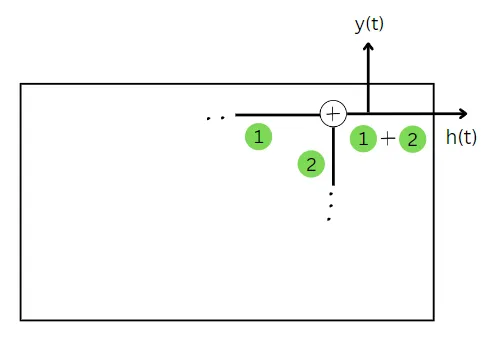
En las celdas GRU, el valor del estado actual es igual a la predicción. Por lo tanto, dado que ya hemos calculado el estado actual, también hemos calculado la predicción para el paso de tiempo actual.

Hasta ahora hemos visto las diferentes partes que componen el GRU completo para entenderlo mejor. Entonces, combinemos todas las partes que hemos visto hasta ahora.
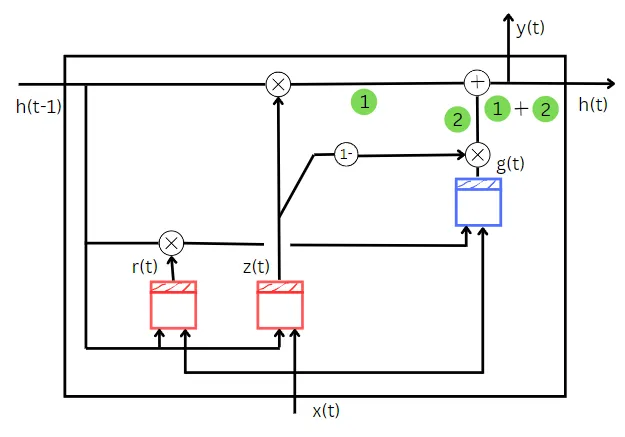
Este es el diagrama completo de la red GRU.
Espero que te guste el artículo. Los diagramas del artículo los he dibujado a mano. Espero que sean lo suficientemente intuitivos (y no demasiado desordenados) para entender claramente el GRU. Si tienes algún comentario sobre el artículo, por favor házmelo saber. Además, si te gustó el artículo, por favor aplaude.
Conéctate conmigo en
Sitio web
Escríbeme a [email protected]
¡Que tengas un excelente día!
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Guía completa de métricas de evaluación de clasificación
- ¿Qué tan aleatorios son los goles en el fútbol?
- Consulta tus DataFrames con potentes modelos de lenguaje grandes utilizando LangChain.
- Transformada de Fourier para series de tiempo Graficando números complejos
- 5 Programas de Certificación en IA en línea – Explora e Inscríbete
- Optimizando Conexiones Optimización Matemática dentro de Grafos
- Utilizando cámaras en los autobuses de transporte público para monitorear el tráfico






