Inmersión profunda en el modo de copia por escritura de pandas Parte I
Inmersión en copia por escritura de pandas I
Explicando cómo funciona Copy-on-Write internamente

Introducción
Se lanzó pandas 2.0 a principios de abril y trajo muchas mejoras al nuevo modo de Copia por Escritura (Copy-on-Write, CoW). Se espera que esta característica se convierta en la opción predeterminada en pandas 3.0, que está programado para abril de 2024 en este momento. No hay planes para un modo heredado o no CoW.
Esta serie de publicaciones explicará cómo funciona Copy-on-Write internamente para ayudar a los usuarios a comprender lo que está sucediendo, mostrar cómo usarlo de manera efectiva e ilustrar cómo adaptar su código. Esto incluirá ejemplos sobre cómo aprovechar el mecanismo para obtener el rendimiento más eficiente y también mostrará un par de anti-patrones que resultarán en cuellos de botella innecesarios. Escribí una breve introducción a Copy-on-Write hace un par de meses.
Escribí una breve publicación que explica la estructura de datos de pandas, lo cual te ayudará a comprender algunos términos que son necesarios para CoW.
Soy parte del equipo principal de pandas y he estado muy involucrado en la implementación y mejora de CoW hasta ahora. Soy un ingeniero de código abierto en Coiled, donde trabajo en Dask, incluida la mejora de la integración con pandas y asegurándome de que Dask sea compatible con CoW.
- LLMs afinados para la predicción de sentimientos – Cómo analizar y evaluar
- AI Prowess Utilizando Docker para la implementación y escalabilidad eficiente de aplicaciones de Aprendizaje Automático
- 7 Estúpidas Razones por las que la Gente no está Utilizando la IA
Cómo cambia el comportamiento de pandas Copy-on-Write
Muchos de ustedes probablemente están familiarizados con las siguientes advertencias en pandas:
import pandas as pddf = pd.DataFrame({"student_id": [1, 2, 3], "grade": ["A", "C", "D"]})Seleccionemos la columna de calificaciones y sobrescribamos la primera fila con "E".
grades = df["grade"]grades.iloc[0] = "E"df student_id grade0 1 E1 2 C2 3 DDesafortunadamente, esto también actualizó df y no solo grades, lo que puede introducir errores difíciles de encontrar. CoW no permitirá este comportamiento y asegura que solo se actualice df. También vemos una advertencia falsa positiva SettingWithCopyWarning que no nos ayuda aquí.
Veamos un ejemplo de ChainedIndexing que no está haciendo nada:
df[df["student_id"] > 2]["grades"] = "F"df student_id grade0 1 A1 2 C2 3 DNuevamente recibimos una advertencia SettingWithCopyWarning, pero nada sucede en este ejemplo a df. Todas estas advertencias se reducen a las reglas de copia y vista en NumPy, que es lo que pandas utiliza internamente. Los usuarios de pandas deben conocer estas reglas y cómo se aplican a los DataFrames de pandas para comprender por qué patrones de código similares producen resultados diferentes.
CoW resuelve todas estas inconsistencias. Los usuarios solo pueden actualizar un objeto a la vez cuando CoW está habilitado, por ejemplo, df no cambiaría en nuestro primer ejemplo, ya que solo se actualiza grades en ese momento y el segundo ejemplo genera un ChainedAssignmentError en lugar de no hacer nada. En general, no será posible actualizar dos objetos a la vez, es decir, cada objeto se comportará como una copia del objeto anterior.
Hay muchos más de estos casos, pero revisarlos todos no está dentro del alcance de este documento.
Cómo funciona
Veamos Copy-on-Write con más detalle y destaquemos algunos hechos que es bueno saber. Esta es la parte principal de esta publicación y es bastante técnica.
Copy-on-Write promete que todos los DataFrame o Series derivados de otro en cualquier forma siempre se comportarán como una copia. Esto significa que no es posible modificar más de un objeto con una sola operación, por ejemplo, nuestro primer ejemplo anterior solo modificaría grades.
Un enfoque muy defensivo para garantizar esto sería copiar el DataFrame y sus datos en cada operación, lo que evitaría las vistas en pandas por completo. Esto garantizaría la semántica de CoW pero también incurriría en una enorme penalización de rendimiento, por lo que esta no era una opción viable.
Ahora nos sumergiremos en el mecanismo que asegura que no se actualicen dos objetos con una sola operación y que nuestros datos no se copien innecesariamente. La segunda parte es lo que hace interesante la implementación.
Tenemos que saber exactamente cuándo desencadenar una copia para evitar copias que no sean absolutamente necesarias. Las copias potenciales solo son necesarias si intentamos mutar los valores de un objeto pandas sin copiar sus datos. Tenemos que desencadenar una copia si los datos de este objeto se comparten con otro objeto pandas. Esto significa que tenemos que llevar un registro de si un array NumPy es referenciado por dos DataFrames (en general, tenemos que ser conscientes de si un array NumPy es referenciado por dos objetos pandas, pero usaré el término DataFrame por simplicidad).
df = pd.DataFrame({"student_id": [1, 2, 3], "grade": [1, 2, 3]})df2 = df[:]Esta declaración crea un DataFrame df y una vista de este DataFrame df2. Vista significa que ambos DataFrames están respaldados por el mismo array NumPy subyacente. Cuando lo miramos con CoW, df tiene que ser consciente de que df2 también referencia su array NumPy. Sin embargo, esto no es suficiente. df2 también tiene que ser consciente de que df referencia su array NumPy. Si ambos objetos son conscientes de que hay otro DataFrame que referencia el mismo array NumPy, podemos desencadenar una copia en caso de que uno de ellos sea modificado, por ejemplo:
df.iloc[0, 0] = 100Aquí se modifica df inplace. df sabe que hay otro objeto que referencia los mismos datos, por ejemplo, desencadena una copia. No sabe qué objeto referencia los mismos datos, solo sabe que hay otro objeto ahí fuera.
Echemos un vistazo a cómo podemos lograr esto. Creamos una clase interna BlockValuesRefs que se utiliza para almacenar esta información, apunta a todos los DataFrames que hacen referencia a un determinado array NumPy.
Existen tres tipos diferentes de operaciones que pueden crear un DataFrame:
- Se crea un DataFrame a partir de datos externos, por ejemplo, a través de
pd.DataFrame(...)o mediante cualquier método de I/O. - Se crea un nuevo DataFrame mediante una operación de pandas que desencadena una copia de los datos originales, por ejemplo,
dropnacrea una copia en casi todos los casos. - Se crea un nuevo DataFrame mediante una operación de pandas que no desencadena una copia de los datos originales, por ejemplo,
df2 = df.reset_index().
Los dos primeros casos son simples. Cuando se crea el DataFrame, los arrays NumPy que lo respaldan están conectados a un nuevo objeto BlockValuesRefs. Estos arrays solo son referenciados por el nuevo objeto, por lo que no tenemos que llevar un registro de ningún otro objeto. El objeto crea una weakref que apunta al Block que envuelve el array NumPy y almacena esta referencia internamente. El concepto de Blocks se explica aquí.
Una weakref crea una referencia a cualquier objeto de Python. No mantiene vivo este objeto cuando normalmente quedaría fuera de alcance.
import weakrefclass Dummy: def __init__(self, a): self.a = aIn[1]: obj = Dummy(1)In[2]: ref = weakref.ref(obj)In[3]: ref()Out[3]: <__main__.Dummy object at 0x108187d60>In[4]: obj = Dummy(2)Este ejemplo crea un objeto Dummy y una referencia débil a este objeto. Después, asignamos otro objeto a la misma variable, por ejemplo, el objeto inicial queda fuera de alcance y se recoge como basura. La referencia débil no interfiere en este proceso. Si resuelves la referencia débil, apuntará a
Noneen lugar del objeto original.
In[5]: ref()Out[5]: NoneEsto asegura que no mantengamos vivos arrays que de otra manera serían recolectados como basura.
Echemos un vistazo a cómo se organizan estos objetos:
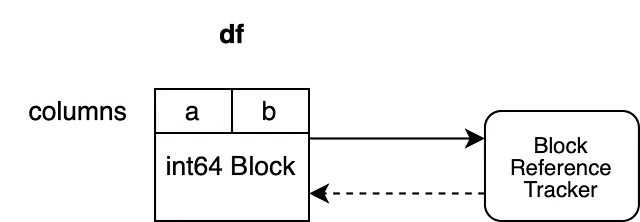
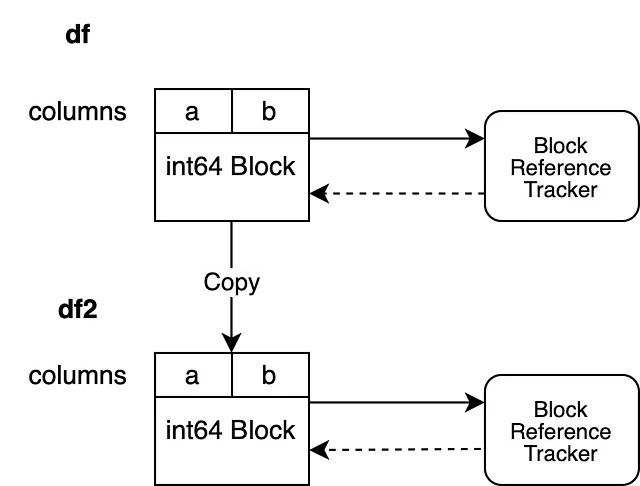
Nuestro ejemplo tiene dos columnas "a" y "b" que ambas tienen dtype "int64". Están respaldadas por un Bloque que contiene los datos para ambas columnas. El Bloque mantiene una referencia fuerte al objeto de seguimiento de referencia, asegurando que se mantenga vivo mientras el Bloque no sea recolectado como basura. El objeto de seguimiento de referencia mantiene una referencia débil al Bloque. Esto permite al objeto hacer un seguimiento del ciclo de vida de este bloque pero no evita la recolección de basura. El objeto de seguimiento de referencia no mantiene una referencia débil a ningún otro Bloque aún.
Estos son los escenarios más fáciles. Sabemos que ningún otro objeto de pandas comparte el mismo array NumPy, por lo que simplemente podemos instanciar un nuevo objeto de seguimiento de referencia.
El tercer caso es más complicado. El nuevo objeto ve los mismos datos que el objeto original. Esto significa que ambos objetos apuntan a la misma memoria. Nuestra operación creará un nuevo Bloque que referencia el mismo array NumPy, esto se llama una copia superficial. Ahora tenemos que registrar este nuevo Bloque en nuestro mecanismo de seguimiento de referencia. Registraremos nuestro nuevo Bloque con el objeto de seguimiento de referencia que está conectado al objeto antiguo.
df2 = df.reset_index(drop=True)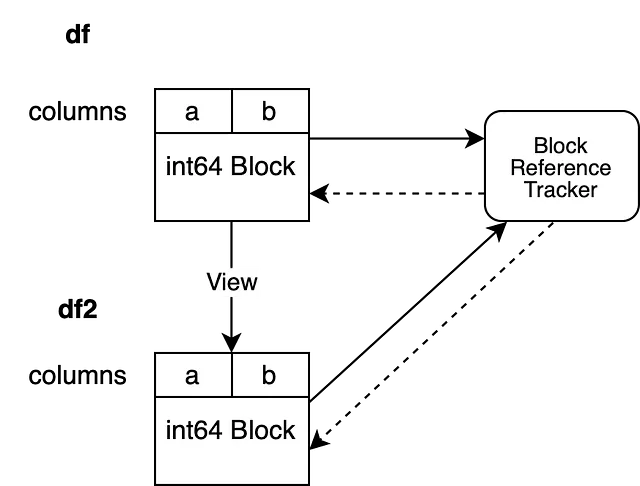
Nuestro BlockValuesRefs ahora apunta al Bloque que respalda el df inicial y al Bloque recién creado que respalda a df2. Esto asegura que siempre estemos conscientes de todos los DataFrames que apuntan a la misma memoria.
Ahora podemos preguntarle al objeto de seguimiento de referencia cuántos Bloques que apuntan al mismo array NumPy están vivos. El objeto de seguimiento de referencia evalúa las referencias débiles y nos dice que más de un objeto referencia los mismos datos. Esto nos permite activar una copia internamente si uno de ellos se modifica en su lugar.
df2.iloc[0, 0] = 100El Bloque en df2 se copia mediante una copia profunda, creando un nuevo Bloque que tiene sus propios datos y objeto de seguimiento de referencia. El bloque original que respaldaba a df2 ahora puede ser recolectado como basura, lo que asegura que los arrays que respaldan a df y df2 no compartan ninguna memoria.
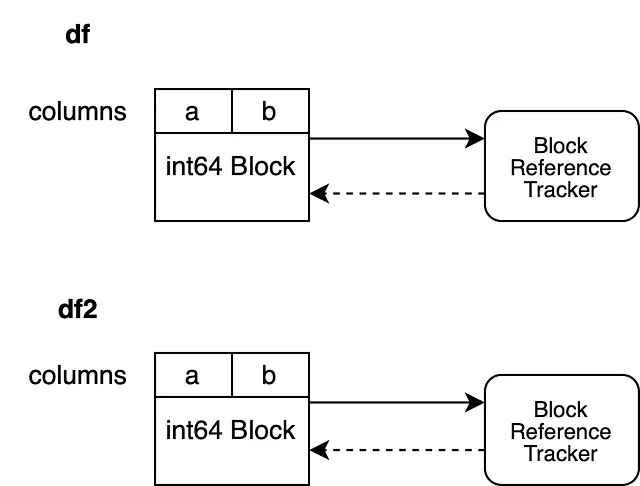
Echemos un vistazo a un escenario diferente.
df = None
df2.iloc[0, 0] = 100df es invalidado antes de modificar df2. En consecuencia, la referencia débil de nuestro objeto de seguimiento de referencia, que apunta al Bloque que respaldaba a df, se evalúa como None. Esto nos permite modificar df2 sin activar una copia.
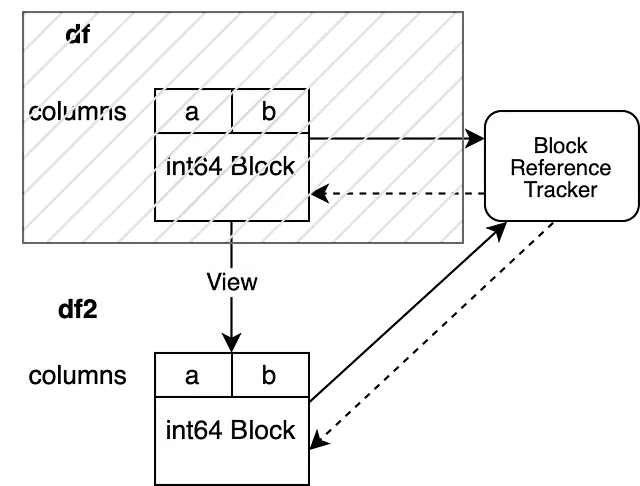
Nuestro objeto de seguimiento de referencia apunta solo a un DataFrame, lo que nos permite realizar la operación inplace sin activar una copia.
reset_index arriba crea una vista. El mecanismo es un poco más simple si tenemos una operación que activa una copia internamente.
df2 = df.copy()Esto instantáneamente instancia un nuevo objeto de seguimiento de referencia para nuestro DataFrame df2.
Conclusión
Hemos investigado cómo funciona el mecanismo de seguimiento de Copia en Escritura (Copy-on-Write) y cuándo se activa una copia. El mecanismo pospone las copias en pandas tanto como sea posible, lo cual es bastante diferente al comportamiento sin CoW. El mecanismo de seguimiento de referencias mantiene un registro de todos los DataFrames que comparten memoria, lo que permite un comportamiento más consistente en pandas.
La próxima parte de esta serie explicará técnicas que se utilizan para hacer que este mecanismo sea más eficiente.
Gracias por leer. No dudes en comunicarte para compartir tus pensamientos y comentarios sobre Copy-on-Write.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Genera publicidad creativa utilizando inteligencia artificial generativa implementada en Amazon SageMaker
- Los ajustes de privacidad de Zoom avivan el temor de que sus llamadas se utilicen para entrenar a la IA
- Se ha confirmado que LK-99 no es un superconductor a temperatura ambiente
- Explorando la interacción entre la Inteligencia Artificial y la Inteligencia Humana
- AI Time Journal presenta el eBook Tendencias de IA en SEO 2023 Ideas de expertos sobre el futuro del SEO.
- El salto de KPMG hacia el futuro de la IA generativa
- De Experimentos 🧪 a Despliegue 🚀 MLflow 101 | Parte 01





