Mejorando la inferencia de PyTorch en CPU desde la cuantificación posterior al entrenamiento hasta el multihilo.
Improving PyTorch inference on CPU from post-training quantization to multithreading.
Los Planos de Kaggle
Cómo reducir el tiempo de inferencia en CPU con una selección inteligente de modelos, cuantización post-entrenamiento con ONNX Runtime o OpenVINO y multithreading con ThreadPoolExecutor

Bienvenidos a otra edición de “Los Planos de Kaggle”, donde analizaremos las soluciones ganadoras de las competiciones de Kaggle para obtener lecciones que podamos aplicar a nuestros propios proyectos de ciencia de datos.
Esta edición revisará las técnicas y enfoques de la competición “BirdCLEF 2023”, que finalizó en mayo de 2023.
Declaración del problema: inferencia de aprendizaje profundo bajo limitaciones de tiempo y computación
Las competiciones BirdCLEF son una serie de competiciones recurrentes anualmente en Kaggle. El objetivo principal de una competición BirdCLEF suele ser identificar una especie de ave específica por su sonido. A los competidores se les dan archivos de audio cortos de llamadas de aves individuales y luego deben predecir si una ave específica estaba presente en una grabación más larga.
- Transformaciones generativas de IA de Google
- Análisis de Big Data ¿Por qué es tan crucial para la inteligencia empresarial?
- ¡No olvides que Python es dinámico!
En una edición anterior de “Los Planos de Kaggle”, ya revisamos los enfoques ganadores para la clasificación de audio con Aprendizaje Profundo de la competición “BirdCLEF 2022” del año pasado.
Un aspecto novedoso de la competición “BirdCLEF 2023” fue la limitación de tiempo y las restricciones computacionales: Los competidores debían predecir aproximadamente 200 grabaciones de 10 minutos de duración en una Notebook CPU en 2 horas .
BirdCLEF 2023
Identificar llamadas de aves en paisajes sonoros
www.kaggle.com
Ahora, es posible que se pregunte por qué alguien querría hacer inferencia en un modelo de aprendizaje profundo en una CPU en lugar de en una GPU. Este es un problema práctico común [4], ya que a menudo el personal (especialmente en conservación pero también en otras industrias) tiene limitaciones presupuestarias y, por lo tanto, solo tiene acceso a recursos informáticos limitados. Además, poder hacer predicciones rápidamente es útil.
Como cubrir cómo abordar la clasificación de audio con Aprendizaje Profundo sería repetitivo para la edición anterior de “Los Planos de Kaggle” sobre la competición “BirdCLEF 2022”, nos centraremos en el aspecto novedoso de cómo acelerar la inferencia de modelos de Aprendizaje Profundo en CPU en este artículo.
Si está interesado en los enfoques ganadores para la clasificación de audio con Aprendizaje Profundo, consulte la edición anterior:
Clasificación de audio con Aprendizaje Profundo en Python
Afinación de modelos de imagen para abordar el cambio de dominio y el desequilibrio de clases con PyTorch y torchaudio en datos de audio
towardsdatascience.com
Abordando la inferencia de Aprendizaje Profundo en CPU
El problema principal al tener que hacer inferencia en CPU en un tiempo limitado es que no puedes crear grandes conjuntos de modelos poderosos y diversos para exprimir ese último porcentaje de rendimiento. Dependiendo del modelo utilizado, algunos competidores incluso tuvieron dificultades para cumplir con los requisitos de tiempo limitado con un solo modelo.
Sin embargo, es común que un conjunto de modelos más débiles generalmente funcione mejor que un solo modelo potente. En los informes de la competencia, los competidores exitosos compartieron algunos trucos sobre cómo aceleraron la inferencia en CPU para poder reunir varios modelos.
Este artículo cubre los siguientes trucos que se compartieron en los informes:
- Selección de modelos
- Cuantización post-entrenamiento
- Multithreading
Selección de modelos
El tamaño del modelo impacta fuertemente en el tiempo de inferencia. Como regla general: cuanto más grande sea el modelo, mayor será el tiempo de inferencia.
Como regla general: cuanto más grande sea el modelo, mayor será el tiempo de inferencia.
Por lo tanto, al seleccionar las espinas dorsales para los modelos en sus conjuntos, los competidores tuvieron que evaluar qué modelos resultaron en el mejor equilibrio entre rendimiento y tiempo de inferencia.
Mientras que NFNet (eca_nfnet_l0) [3, 5, 7, 9, 10, 11, 13, 14, 16] y EfficientNet no cambiaron como las espinas dorsales populares entre la competencia del año pasado y la de este año, pudimos ver que en la competencia de este año, los competidores prefirieron versiones más pequeñas de EfficientNet.
Mientras que en la competencia BirdCLEF 2022, tf_efficientnet_b0_ns [8, 11], tf_efficientnet_b3_ns [8], tf_efficientnetv2_s_in21k [11, 16] y tf_efficientnetv2_m_in21k [13] fueron populares, este año se prefirieron las versiones más pequeñas tf_efficientnet_b0_ns [1, 5, 6, 7, 10] y tf_efficientnetv2_s_in21k [1, 6, 15].
A continuación, puede ver una comparación de los tamaños de los modelos en términos del número de parámetros para una selección de modelos populares en la serie de competencias BirdCLEF.
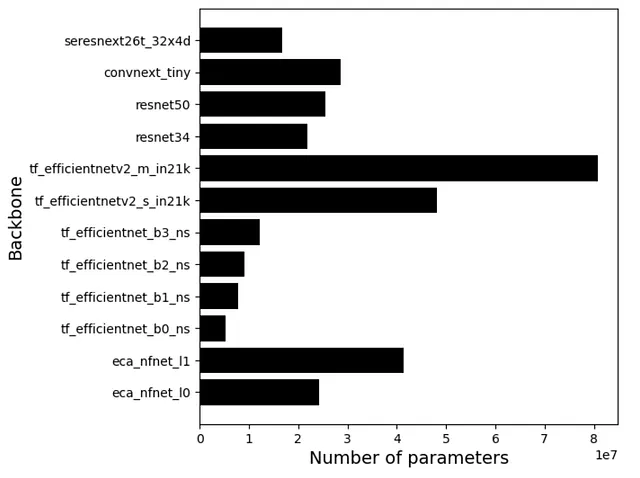
Como resultado, pudimos ver que los competidores exitosos aprovecharon una combinación de un modelo más grande (eca_nfnet_l0) con modelos más pequeños (por ejemplo, tf_efficientnet_b0_ns).
Cuantización posterior al entrenamiento
Otro truco para acelerar la inferencia en la CPU es aplicar cuantización al modelo después del entrenamiento: la cuantización posterior al entrenamiento reduce la precisión de los pesos y activaciones del modelo desde la precisión de punto flotante (32 bits) a una representación de ancho de bits más bajo (por ejemplo, 8 bits).
Esta técnica transforma el modelo en una representación más amigable para el hardware y, por lo tanto, mejora la latencia. Sin embargo, debido a la pérdida de precisión de la representación de peso y activación, también puede llevar a una ligera pérdida de rendimiento.
La cuantización va de la mano con el hardware. Por ejemplo, un cuaderno Kaggle tiene 4 CPU (Intel(R) Xeon(R) CPU @ 2.20GHz con arquitectura x86_64). Estas CPUs de Intel con arquitectura x86 prefieren que los tipos de datos cuantizados sean INT8.
Sugerencia: Para mostrar información sobre la arquitectura de la CPU, ejecute el comando lscpu y luego consulte la página web del fabricante para ver qué tipos de datos de entrada cuantizados prefiere esa CPU específica.
Para una explicación detallada de la cuantización posterior al entrenamiento y una comparación de ONNX Runtime y OpenVINO, recomiendo este artículo:
OpenVINO vs ONNX para Transformers en producción
Transformers ha revolucionado NLP, convirtiéndolo en la primera opción para aplicaciones como la traducción automática, la semántica…
blog.ml6.eu
Esta sección analizará específicamente dos técnicas populares de cuantización posterior al entrenamiento:
- ONNX Runtime
- OpenVINO
ONNX Runtime
Un enfoque popular para acelerar la inferencia en la CPU fue convertir los modelos finales a formato ONNX (Open Neural Network Exchange) [2, 7, 9, 10, 14, 15].
A continuación, se muestran los pasos relevantes para cuantizar y acelerar la inferencia en la CPU con ONNX Runtime:
Preparación: Instalar ONNX Runtime
pip install onnxruntimePaso 1: Convertir el modelo de PyTorch a ONNX
import torchimport torchvision# Defina su modelo aquímodelo = ...# Entrenar el modelo aquí...# Definir la entrada ficticiadummy_input = torch.randn(1, N_CHANNELS, IMG_WIDTH, IMG_HEIGHT, device="cuda")# Exportar el modelo de PyTorch al formato ONNXtorch.onnx.export(model, dummy_input, "model.onnx")Paso 2: Hacer predicciones con una sesión de ONNX Runtime
import onnxruntime as rt# Definir X_test con forma (BATCH_SIZE, N_CHANNELS, IMG_WIDTH, IMG_HEIGHT)X_test = ...# Definir sesión ONNX Runtimesess = rt.InferenceSession("model.onnx")# Hacer prediccióny_pred = sess.run([], {'input' : X_test})[0]OpenVINO
El enfoque igual de popular para acelerar la inferencia en CPU fue usar OpenVINO (Optimización de Redes Neuronales e Inferencia Visual Abierta) [5, 6, 12] como se muestra en este Cuaderno de Kaggle:
openvino es todo lo que necesitas
Explora y ejecuta código de aprendizaje automático con Cuadernos de Kaggle | Usando datos de múltiples fuentes de datos
www.kaggle.com
Los pasos relevantes para cuantizar y acelerar un modelo de aprendizaje profundo con OpenVINO se muestran a continuación:
Preparación: Instalar OpenVINO
!pip install openvino-dev[onnx]Paso 1: Convertir modelo de PyTorch a ONNX (ver Paso 1 de ONNX Runtime)
Paso 2: Convertir modelo ONNX a OpenVINO
mo --input_model model.onnxEsto producirá un archivo XML y un archivo BIN, de los cuales usaremos el archivo XML en el siguiente paso.
Paso 3: Cuantizar a INT8 usando OpenVINO
import openvino.runtime as ovcore = ov.Core()openvino_model = core.read_model(model='model.xml')compiled_model = core.compile_model(openvino_model, device_name="CPU")Paso 4: Hacer predicciones con una solicitud de inferencia de OpenVINO
# Definir X_test con forma (BATCH_SIZE, N_CHANNELS, IMG_WIDTH, IMG_HEIGHT)X_test = ...# Crear solicitud de inferenciainfer_request = compiled_model.create_infer_request()# Hacer prediccióny_pred = infer_request.infer(inputs=[X_test, 2])Comparación: ONNX vs. OpenVINO vs. Alternativas
Tanto ONNX como OpenVINO son marcos optimizados para implementar modelos en CPUs. Se dice que los tiempos de inferencia de una red neuronal cuantizada con ONNX y OpenVINO son comparables [12].
Algunos competidores usaron PyTorch JIT [3] o TorchScript [1] como alternativas para acelerar la inferencia en CPU. Sin embargo, otros competidores compartieron que ONNX fue considerablemente más rápido que TorchScript [10].
Multihilo con ThreadPoolExecutor
Otro enfoque popular para acelerar la inferencia en CPU fue usar multihilo con ThreadPoolExecutor [2, 3, 9, 15] además de la cuantificación posterior al entrenamiento, como se muestra en este Cuaderno de Kaggle:
Inferencia de modelo eb0_SED más rápida
Explora y ejecuta código de aprendizaje automático con Cuadernos de Kaggle | Usando datos de múltiples fuentes de datos
www.kaggle.com
Esto permitió a los competidores ejecutar múltiples inferencias al mismo tiempo.
En el siguiente ejemplo de ThreadPoolExecutor de la competencia, tenemos una lista de archivos de audio para inferir.
audios = ['audio_1.ogg', 'audio_2.ogg', # ..., 'audio_n.ogg',]A continuación, debe definir una función de inferencia que tome un archivo de audio como entrada y devuelva las predicciones.
def predict(audio_path): # Definir cualquier preprocesamiento del archivo de audio aquí ... # Hacer predicciones ... return predictionsCon la lista de audios (por ejemplo, audios) y la función de inferencia (por ejemplo, predict()), ahora puede usar ThreadPoolExecutor para ejecutar múltiples inferencias al mismo tiempo (en paralelo) en lugar de secuencialmente, lo que le dará un buen impulso en el tiempo de inferencia.
import concurrent.futures
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
dicts = list(executor.map(predict, audios))
Resumen
Hay muchas lecciones más por aprender al revisar los recursos de aprendizaje que los Kagglers han creado durante el curso de la competencia “BirdCLEF 2023”. También hay muchas soluciones diferentes para este tipo de declaración de problemas.
En este artículo, nos enfocamos en el enfoque general que fue popular entre muchos competidores:
- Selección del modelo: seleccione el tamaño del modelo de acuerdo con el mejor equilibrio entre rendimiento y tiempo de inferencia. Además, aproveche modelos más grandes y más pequeños en su conjunto.
- Cuantificación posterior al entrenamiento: la cuantificación posterior al entrenamiento puede llevar a tiempos de inferencia más rápidos debido a que los tipos de datos de los pesos del modelo y las activaciones se optimizan para el hardware. Sin embargo, esto puede llevar a una ligera pérdida de rendimiento del modelo.
- Multithreading: ejecute múltiples inferencias en paralelo en lugar de secuencialmente. Esto le dará un impulso en el tiempo de inferencia.
Si está interesado en cómo abordar la clasificación de audio con Deep Learning, que fue el aspecto principal de esta competencia, consulte el informe de la competencia BirdCLEF 2022:
Clasificación de audio con Deep Learning en Python
Ajuste fino de modelos de imagen para abordar el cambio de dominio y el desequilibrio de clases con PyTorch y torchaudio en datos de audio
towardsdatascience.com
¿Disfrutaste esta historia?
Suscríbete gratis para recibir una notificación cuando publique una nueva historia.
¿Quieres leer más de 3 historias gratuitas al mes? — Conviértete en miembro de Zepes por 5$/mes. Puedes apoyarme usando mi enlace de referencia cuando te registres. Recibiré una comisión sin costo adicional para ti.
Únete a Zepes con mi enlace de referencia — Leonie Monigatti
Lee todas las historias de Leonie Monigatti (y miles de otros escritores en Zepes). Tu tarifa de membresía directamente…
Zepes.com
¡Encuéntrame en LinkedIn, Twitter y Kaggle!
Referencias
Referencias de imagen
Si no se indica lo contrario, todas las imágenes son creadas por el autor.
Literatura web
[1] adsr (2023). Solución del tercer lugar: SED con atención en las bandas de frecuencia Mel en Discusiones de Kaggle (accedido el 1 de junio de 2023)
[2] anonamename (2023). Solución del sexto lugar: incrustación BirdNET + CNN en Discusiones de Kaggle (accedido el 1 de junio de 2023)
[3] atfujita (2023). Solución del cuarto lugar: la destilación de conocimiento es todo lo que necesita en Discusiones de Kaggle (accedido el 1 de junio de 2023)
[4] beluga (2023). Restricciones de inferencia – Notebook de CPU <= 120 minutos (accedido el 27 de marzo de 2023).
[5] Harshit Sheoran (2023). Solución del noveno lugar: conjunto de 7 modelos CNN en Discusiones de Kaggle (accedido el 1 de junio de 2023)
[6] HONG LIHANG (2023). Solución del segundo lugar: SED + CNN con un conjunto de 7 modelos en Discusiones de Kaggle (accedido el 1 de junio de 2023)
[7] HyeongChan Kim (2023). Solución del puesto 24 – preentrenamiento y modelo único (conjunto de 5 pliegues con ONNX) en Discusiones de Kaggle (accedido el 1 de junio de 2023)
[8] LeonShangguan (2022). Soluciones de [Público #1 Privado #2] + [Privado #7 / 8 (potencial)]. El anfitrión gana en Discusiones de Kaggle (accedido el 13 de marzo de 2023)
[9] LeonShangguan (2023). Solución en décimo lugar en Discusiones de Kaggle (accedido el 1 de junio de 2023)
[10] moritake04 (2023). Solución en vigésimo lugar: conjunto de SED + CNN utilizando onnx en Discusiones de Kaggle (accedido el 1 de junio de 2023)
[11] slime (2022). Solución en tercer lugar en Discusiones de Kaggle (accedido el 13 de marzo de 2023)
[12] storm (2023). Solución en el séptimo lugar: la ampliación ‘sumix’ hizo todo el trabajo en Discusiones de Kaggle (accedido el 1 de junio de 2023)
[13] Volodymyr (2022). Modelos de la solución en primer lugar (no solo BirdNet) en Discusiones de Kaggle (accedido el 13 de marzo de 2023)
[14] Volodymyr (2023). Solución en primer lugar: Los datos correctos es todo lo que necesitas en Discusiones de Kaggle (accedido el 1 de junio de 2023)
[15] Yevhenii Maslov (2023). Solución en quinto lugar en Discusiones de Kaggle (accedido el 1 de junio de 2023)
[16] yokuyama (2022). Solución en quinto lugar en Discusiones de Kaggle (accedido el 13 de marzo de 2023)
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 5 Mejores Prácticas para la Colaboración del Equipo de Ciencia de Datos.
- Visualización del efecto de la multicolinealidad en el modelo de regresión múltiple.
- Pandas potenciado Encriptando archivos de Excel escritos desde DataFrames
- Control Sintético ¿Y si pudiéramos simular realidades alternativas?
- Investigadores crean una herramienta para simular con precisión sistemas complejos.
- Estudio Los modelos de IA no logran reproducir los juicios humanos sobre violaciones de reglas.
- Celebrando el impacto de IDSS