Cómo implementar el clustering jerárquico para campañas de marketing directo – con código Python
Implementación del clustering jerárquico para campañas de marketing directo - código Python.
Comprender los pormenores del clustering jerárquico y cómo se aplica al análisis de campañas de marketing en la industria bancaria.
Motivación
Imagina ser un científico de datos en una importante institución financiera y que tu tarea sea ayudar a tu equipo a categorizar a los clientes existentes en perfiles distintos: bajo, promedio, VoAGI y platinum para la aprobación de préstamos.
Pero aquí está el problema:
No existe una etiqueta histórica asociada a estos clientes, ¿entonces cómo proceder con la creación de estas categorías?
Aquí es donde el clustering puede ayudar, una técnica de aprendizaje automático no supervisado para agrupar datos sin etiquetar en categorías similares.
- Top 40+ Herramientas de IA Generativa (Septiembre 2023)
- Investigadores de la Universidad de Washington y AI2 presentan TIFA una métrica de evaluación automática que mide la fidelidad de una imagen generada por IA a través de VQA.
- Abriendo la caja negra
Existen múltiples técnicas de clustering, pero este tutorial se centrará más en el enfoque del clustering jerárquico.
Comienza proporcionando una visión general de lo que es el clustering jerárquico, antes de guiarte paso a paso en su implementación en Python utilizando la popular biblioteca Scipy.
¿Qué es el clustering jerárquico?
El clustering jerárquico es una técnica para agrupar datos en un árbol de clusters llamado dendrogramas, que representa la relación jerárquica entre los clusters subyacentes.
El algoritmo de clustering jerárquico se basa en medidas de distancia para formar clusters y generalmente implica los siguientes pasos principales:
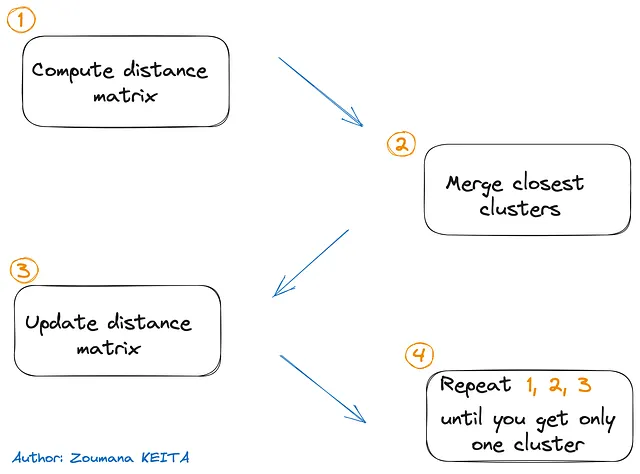
- Computar la matriz de distancias que contiene la distancia entre cada par de puntos de datos utilizando una métrica de distancia específica como la distancia euclidiana, distancia de Manhattan o similitud coseno
- Fusionar los dos clusters más cercanos en distancia
- Actualizar la matriz de distancias con respecto a los nuevos clusters
- Repetir los pasos 1, 2 y 3 hasta que se…
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Las 10 habilidades de IA más importantes para conseguir un trabajo en 2023
- Base de datos de vectores ¡Una guía para principiantes!
- 9 Mejores sitios web de IA (Tienes que probar antes de morir)
- Conoce DenseDiffusion una técnica de IA sin entrenamiento para abordar subtítulos densos y manipulación de diseño en la generación de texto a imagen
- Innovaciones autónomas en un mundo incierto
- Llevando la inteligencia artificial generativa en la búsqueda a más personas en todo el mundo
- Despliega un servicio de autorespuesta de preguntas con la solución QnABot en AWS, impulsado por Amazon Lex con Amazon Kendra y modelos de lenguaje amplios





