Las complejidades de la implementación de la resolución de entidades
Implementación de la resolución de entidades' complejidades
Ejemplo práctico de algunos desafíos típicos al trabajar en la coincidencia de datos

La resolución de entidades es el proceso de determinar si dos o más registros en un conjunto de datos se refieren a la misma entidad del mundo real, a menudo una persona o una empresa. A primera vista, la resolución de entidades puede parecer una tarea relativamente simple: por ejemplo, dadas dos imágenes de una persona, incluso un niño pequeño podría determinar si muestra a la misma persona o no con una precisión bastante alta. Y lo mismo ocurre con las computadoras: comparar dos registros que contienen atributos como nombres, direcciones, correos electrónicos, etc., puede hacerse fácilmente. Sin embargo, cuanto más se profundiza en ese tema, más desafiante se vuelve: se deben evaluar varios algoritmos de coincidencia, manejar millones o miles de millones de registros implica una complejidad cuadrática, sin mencionar los casos de uso en tiempo real y eliminación de datos.
Coincidencia difusa de texto
Comencemos comparando dos registros del famoso artista Vincent Van Gogh, ¿o era Van Gough?

Hay algunos errores en el segundo registro (además de haber nacido un siglo después y una dirección de correo electrónico): el nombre está mal escrito, se mezcló la fecha de nacimiento, falta el código postal y la dirección de correo electrónico es ligeramente diferente.
- La IA generativa impulsa una nueva era en la industria automotriz, desde el diseño y la ingeniería hasta la producción y las ventas
- Visual Effects Multiplier Wylie Co. apuesta todo por el rendimiento de GPU para obtener ganancias de 24 veces
- Superando los límites del análisis de datos con SQL en S4 HANA y Domo Una perspectiva de Aprendizaje Automático
Entonces, ¿cómo podemos comparar esos valores? Si, digamos, los nombres fueran iguales, entonces una simple comparación de cadenas de esos valores sería suficiente. Como este no es el caso, necesitamos una coincidencia difusa más avanzada. Hay muchos algoritmos diferentes disponibles para la coincidencia difusa basada en texto y se pueden separar aproximadamente en tres grupos. Los algoritmos fonéticos se centran en qué tan similar se pronuncia un texto. Los algoritmos más famosos son Soundex y Metaphone, que se utilizan principalmente para textos en inglés, pero también existen variaciones de estos para otros idiomas, como el Kölner Phonetik (fonética de Colonia) para el alemán. Los algoritmos de distancia de texto suelen definir cuántos caracteres de un texto deben cambiar para alcanzar el otro texto. La distancia de Levenshtein y la distancia de Hamming son dos algoritmos conocidos en ese grupo. Los algoritmos de similitud, como la similitud del coseno o el índice de Jaccard, calculan la similitud estructural de los textos y a menudo representan la similitud como un porcentaje.
Para este artículo, utilizaremos un enfoque muy simple, utilizando solo una distancia de Levenshtein en el nombre e igualdad en la ciudad. Este ejemplo y todos los ejemplos siguientes utilizarán golang como lenguaje de programación y utilizarán bibliotecas existentes cuando sea posible. Convertir esto a python, java o cualquier otro lenguaje debería ser trivial. Además, solo realizará la coincidencia en el atributo del nombre. Agregar más atributos o incluso hacerlo configurable no es el propósito de este artículo.
package mainimport ( "fmt" "github.com/hbollon/go-edlib")type Record struct { ID int Name string City string}func matches(a, b Record) bool { distance := edlib.LevenshteinDistance(a.Name, b.Name) return distance <= 3 && a.City == b.City}func main() { a := Record{ Name: "Vincent Van Gogh", City: "París", } b := Record{ Name: "Vince Van Gough", City: "París", } if matches(a, b) { fmt.Printf("%s y %s probablemente sean la misma persona\n", a.Name, b.Name) } else { fmt.Printf("%s y %s probablemente no sean la misma persona\n", a.Name, b.Name) }}Prueba en el Go Playground: https://go.dev/play/p/IJtanpXEdyu
La distancia de Levenshtein entre los dos nombres es exactamente 3. Esto se debe a que hay tres caracteres adicionales (“en” en el primer nombre y “u” en el apellido). Ten en cuenta que esto funciona con esta entrada específica. Sin embargo, está lejos de ser perfecto. Por ejemplo, los nombres “Joe Smith” y “Amy Smith” también tienen una distancia de Levenshtein de tres, pero obviamente no son la misma persona. Combinar un algoritmo de distancia con un algoritmo fonético podría resolver el problema, pero eso está fuera del alcance de este artículo.
Cuando se utiliza un enfoque basado en reglas en lugar de un enfoque basado en ML, elegir los algoritmos adecuados que produzcan los mejores resultados para su caso de uso es el aspecto más crucial para el éxito de su negocio. Aquí es donde debería pasar la mayor parte de su tiempo. Desafortunadamente, como descubriremos ahora, hay muchas otras cosas que lo distraerán de optimizar esas reglas si decide desarrollar usted mismo un motor de resolución de entidades.
Resolución de entidades ingenua
Ahora que sabemos cómo comparar dos registros, necesitamos encontrar todos los registros que coincidan entre sí. El enfoque más sencillo es simplemente comparar cada registro con todos los demás registros. Para este ejemplo, trabajamos con nombres y ciudades elegidos al azar. Para los nombres, forzamos hasta tres errores (reemplazamos cualquier carácter con x).
var firstNames = [...]string{"Wade", "Dave", "Seth", "Ivan", "Riley", "Gilbert", "Jorge", "Dan", "Brian", "Roberto", "Daisy", "Deborah", "Isabel", "Stella", "Debra", "Berverly", "Vera", "Angela", "Lucy", "Lauren"}
var lastNames = [...]string{"Smith", "Jones", "Williams", "Brown", "Taylor"}
func randomName() string {
fn := firstNames[rand.Intn(len(firstNames))]
ln := lastNames[rand.Intn(len(lastNames))]
name := []byte(fmt.Sprintf("%s %s", fn, ln))
errors := rand.Intn(4)
for i := 0; i < errors; i++ {
name[rand.Intn(len(name))] = 'x'
}
return string(name)
}
var cities = [...]string{"Paris", "Berlin", "Nueva York", "Ámsterdam", "Shanghái", "San Francisco", "Sídney", "Ciudad del Cabo", "Brasilia", "El Cairo"}
func randomCity() string {
return cities[rand.Intn(len(cities))]
}
func loadRecords(n int) []Record {
records := make([]Record, n)
for i := 0; i < n; i++ {
records[i] = Record{
ID: i,
Name: randomName(),
City: randomCity(),
}
}
return records
}
func compare(records []Record) (comparisons, matchCount int) {
for _, a := range records {
for _, b := range records {
if a == b {
continue // no comparar con sí mismo
}
comparisons++
if matches(a, b) {
fmt.Printf("%s y %s probablemente son la misma persona\n", a.Name, b.Name)
matchCount++
}
}
}
return comparisons, matchCount
}
func main() {
records := loadRecords(100)
comparisons, matchCount := compare(records)
fmt.Printf("se realizaron %d comparaciones y se encontraron %d coincidencias\n", comparisons, matchCount)
}Prueba en Go Playground: https://go.dev/play/p/ky80W_hk4S3
Deberías ver una salida similar a esto (es posible que debas ejecutarlo varias veces si no obtienes ninguna coincidencia para los datos aleatorios):
Daisy Williams y Dave Williams probablemente son la misma persona
Deborax Browx y Debra Brown probablemente son la misma persona
Riley Brown y RxxeyxBrown probablemente son la misma persona
Dan Willxams y Dave Williams probablemente son la misma persona
se realizaron 9900 comparaciones y se encontraron 16 coincidenciasSi tienes suerte, también obtendrás coincidencias incorrectas como “Daisy” y “Dave”. Esto se debe a que estamos utilizando una distancia de Levenshtein de tres, que es demasiado alta como único algoritmo difuso en nombres cortos. Siéntete libre de mejorarlo por tu cuenta.
En cuanto al rendimiento, la parte realmente problemática son las 9,900 comparaciones necesarias para obtener el resultado, porque duplicar la cantidad de datos de entrada aproximadamente cuadruplicará la cantidad de comparaciones necesarias. Se necesitan 39,800 comparaciones para 200 registros. Para la pequeña cantidad de solo 100,000 registros, eso significaría que se necesitan casi 10 mil millones de comparaciones. No importa cuán grande sea tu sistema, llegará un punto en el que el sistema no podrá terminar esto en un tiempo aceptable a medida que la cantidad de datos aumente.
Una optimización rápida pero casi inútil es no comparar cada combinación dos veces. No debería importar si comparamos A con B o B con A. Sin embargo, esto solo reduciría la cantidad de comparaciones necesarias a la mitad, lo cual es despreciable debido al crecimiento cuadrático.
Reducción de complejidad mediante el bloqueo
Si observamos las reglas que creamos, nos damos cuenta fácilmente de que nunca tendremos una coincidencia si las ciudades son diferentes. Todas esas comparaciones son completamente inútiles y deben evitarse. Colocar registros que se sospecha que son similares en un mismo grupo y otros que no lo son en otro, se llama bloqueo en la resolución de entidades. Como queremos usar la ciudad como nuestra clave de bloqueo, la implementación es bastante simple.
func bloquear(registros []Registro) map[string][]Registro { bloques := map[string][]Registro{} for _, registro := range registros { bloques[registro.Ciudad] = append(bloques[registro.Ciudad], registro) } return bloques}func main() { registros := cargarRegistros(100) bloques := bloquear(registros) comparaciones := 0 cantidadCoincidencias := 0 for _, registrosBloque := range bloques { c, m := comparar(registrosBloque) comparaciones += c cantidadCoincidencias += m } fmt.Printf("realizadas %d comparaciones y encontradas %d coincidencias\n", comparaciones, cantidadCoincidencias)}Prueba en el Go Playground: https://go.dev/play/p/1z_j0nhX-tU
El resultado será el mismo, pero ahora solo tenemos aproximadamente una décima parte de las comparaciones que teníamos anteriormente, porque tenemos diez ciudades diferentes. En una aplicación real, este efecto sería mucho más grande debido a la varianza mucho mayor de las ciudades. Además, cada bloque se puede procesar de forma independiente de los demás, por ejemplo, en paralelo en el mismo servidor o en servidores diferentes.
Encontrar la clave de bloqueo adecuada puede ser un desafío en sí mismo. El uso de un atributo como la ciudad podría resultar en distribuciones desiguales y, por lo tanto, en casos en los que un bloque enorme (por ejemplo, una ciudad grande) tarda mucho más que todos los demás bloques. O la ciudad contiene un pequeño error ortográfico y ya no se considera una coincidencia válida. El uso de múltiples atributos y/o el uso de claves fonéticas o de q-gramas como clave de bloqueo puede resolver estos problemas, pero aumenta la complejidad del software.
De coincidencias a entidad
Hasta ahora, todo lo que podemos decir acerca de nuestros registros es si dos de ellos coinciden o no. Para casos de uso muy básicos, esto podría ser suficiente. Sin embargo, en la mayoría de los casos, quieres saber todas las coincidencias que pertenecen a la misma entidad. Esto puede ir desde patrones simples en forma de estrella donde A coincide con B, C y D, hasta patrones en forma de cadena donde A coincide con B, B coincide con C y C coincide con D, hasta patrones muy complejos en forma de grafo. Esta llamada vinculación de registros transitiva se puede implementar fácilmente utilizando un algoritmo de componente conectado siempre y cuando todos los datos quepan en memoria en un solo servidor. Nuevamente, en una aplicación del mundo real, esto es mucho más desafiante.
func comparar(registros []Registro) (comparaciones int, aristas [][2]int) { for _, a := range registros { for _, b := range registros { if a == b { continue // no comparar consigo mismo } comparaciones++ if coincide(a, b) { aristas = append(aristas, [2]int{a.ID, b.ID}) } } } return comparaciones, aristas}func componentesConectados(aristas [][2]int) [][]int { componentes := map[int][]int{} siguienteIdx := 0 idx := map[int]int{} for _, arista := range aristas { a := arista[0] b := arista[1] idxA, okA := idx[a] idxB, okB := idx[b] switch { case okA && okB && idxA == idxB: // en el mismo componente continue case okA && okB && idxA != idxB: // fusionar dos componentes componentes[siguienteIdx] = append(componentes[idxA], componentes[idxB]...) delete(componentes, idxA) delete(componentes, idxB) for _, x := range componentes[siguienteIdx] { idx[x] = siguienteIdx } siguienteIdx++ case okA && !okB: // agregar b al componente de a idx[b] = idxA componentes[idxA] = append(componentes[idxA], b) case okB && !okA: // agregar a al componente de b idx[a] = idxB componentes[idxB] = append(componentes[idxB], a) default: // crear nuevo componente con a y b idx[a] = siguienteIdx idx[b] = siguienteIdx componentes[siguienteIdx] = []int{a, b} siguienteIdx++ } } cc := make([][]int, len(componentes)) i := 0 for k := range componentes { cc[i] = componentes[k] i++ } return cc}func main() { registros := cargarRegistros(100) bloques := bloquear(registros) comparaciones := 0 aristas := [][2]int{} for _, registrosBloque := range bloques { c, e := comparar(registrosBloque) comparaciones += c aristas = append(aristas, e...) } cc := componentesConectados(aristas) fmt.Printf("realizadas %d comparaciones y encontradas %d coincidencias y %d entidades\n", comparaciones, len(aristas), len(cc)) for _, componente := range cc { nombres := make([]string, len(componente)) for i, id := range componente { nombres[i] = registros[id].Nombre } fmt.Printf("encontrada la siguiente entidad: %s de %s\n", strings.Join(nombres, ", "), registros[componente[0]].Ciudad) }}Prueba en el Playground de Go: https://go.dev/play/p/vP3tzlzJ2LN
La función de componentes conectados itera sobre todas las aristas y crea un nuevo componente, agrega el nuevo id al componente existente o fusiona dos componentes en uno solo. El resultado se ve así:
se hicieron 1052 comparaciones y se encontraron 6 coincidencias y 2 entidadesse encontró la siguiente entidad: Ivan Smxth, Ixan Smith, Ivax Smitx de El Cairose encontró la siguiente entidad: Brxan Williams, Brian Williams de Ciudad del CaboMantener esas aristas nos proporciona algunas ventajas. Podemos usarlas para que la entidad resultante sea comprensible y explicativa, idealmente incluso con una interfaz de usuario agradable que muestre cómo están conectados los registros de una entidad. O cuando se trabaja con un sistema de resolución de entidades en tiempo real, podemos usar las aristas para dividir una entidad a medida que se eliminan datos. O se pueden usar al construir una red neuronal de grafos (GNN), lo que lleva a mejores resultados de ML en lugar de sólo los registros por sí solos.
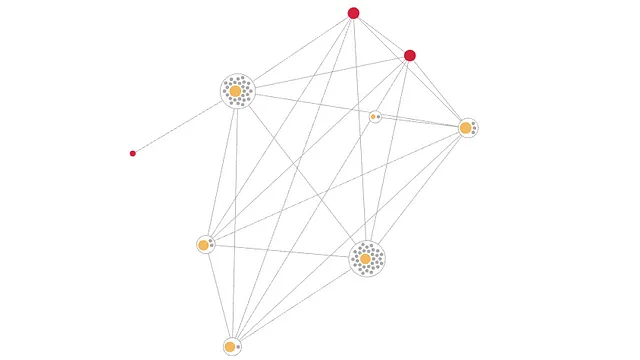
Un problema que puede surgir de las aristas es cuando hay muchos registros muy similares. Si, por ejemplo, A coincide con B y B coincide con C, entonces C también podría coincidir con A dependiendo de las reglas utilizadas. Si D, E, F y así sucesivamente también coinciden con los registros existentes, entonces volvemos al problema del crecimiento cuadrático, lo que resulta en tantas aristas que se vuelven inmanejables.
¿Recuerdas cómo construimos los bloques de bloqueo? ¡Sorpresa! Para datos muy similares, que terminan en pocos bloques enormes, el rendimiento del cálculo vuelve a caer drásticamente, incluso si siguió el consejo anterior de crear bloques a partir de múltiples atributos.
Un ejemplo típico de estos duplicados no idénticos es alguien que realiza pedidos regularmente en la misma tienda, pero con acceso de invitado (lo siento, no hay un buen identificador de cliente). Es posible que esa persona utilice casi siempre la misma dirección de entrega y que sea capaz de escribir correctamente su propio nombre en su mayoría. Por lo tanto, esos registros deben tratarse de manera especial para garantizar un rendimiento estable del sistema, pero eso es un tema aparte.
Antes de que te sientas demasiado cómodo con tus conocimientos adquiridos y quieras comenzar a implementar tu propia solución, déjame aplastar rápidamente tus sueños. Aún no hemos hablado de los desafíos de hacer todo esto en tiempo real. Incluso si piensas que no necesitarás una entidad siempre actualizada (el beneficio obvio), un enfoque en tiempo real ofrece un valor adicional: no necesitas hacer los mismos cálculos una y otra vez, sino solo para los datos nuevos. Por otro lado, es mucho más complejo de implementar. ¿Quieres hacer bloqueo? Compara los nuevos registros con todos los registros del(os) bloque(s) al que pertenece, pero eso puede llevar un tiempo y podría considerarse más bien como un lote incremental. Además, hasta que finalmente termine, ya hay toneladas de nuevos registros esperando para ser procesados. ¿Quieres calcular las entidades utilizando componentes conectados? Claro, mantén todo el grafo en memoria y simplemente agrega las nuevas aristas. Pero no olvides hacer un seguimiento de las dos entidades que acaban de fusionarse debido al nuevo registro.
Entonces, todavía estás dispuesto a implementar esto por tu cuenta. Y tomaste la (en ese caso) sabia decisión de no almacenar aristas y no admitir tiempo real. Así que ejecutaste con éxito tu primer trabajo de resolución de entidades en lote con todos tus datos. Tomó un tiempo, pero solo lo harás una vez al mes, así que está bien. Pero probablemente justo en ese momento ves a tu oficial de protección de datos corriendo hacia ti y diciéndote que elimines a esa persona de tus datos debido a una queja de GDPR. Así que ejecutas todo el trabajo en lote nuevamente para una sola entidad eliminada, ¡genial!
Conclusión
La resolución de entidades puede parecer al principio bastante simple, pero contiene muchos desafíos técnicos significativos. Algunos de ellos se pueden simplificar y/o ignorar, pero otros deben resolverse para obtener un buen rendimiento.
Publicado originalmente en https://tilores.io.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Top 50 Herramientas de Escritura de IA para Probar (Agosto 2023)
- Presentando el plan de estudios del Bootcamp ODSC West comienza ahora
- Construye aplicaciones de IA generativa listas para producción para la búsqueda empresarial utilizando tuberías de Haystack y Amazon SageMaker JumpStart con LLMs
- Investigadores exploran las mejores prácticas para hablar con los niños sobre la privacidad en línea
- Los hackers exploran formas de abusar de la IA en una importante prueba de seguridad
- 15 Mejores Inicios de ChatGPT para la Gestión del Tiempo
- Dominando las pruebas A/B Un ejemplo de negocio del mundo real [Parte 1]






