Cómo construir una plataforma de análisis semi-estructurado en tiempo real en Snowflake
'How to build a real-time semi-structured analysis platform on Snowflake'
Construir un datalake para datos semi-estructurados o json siempre ha sido un desafío. Imagina si los documentos json se transmiten o fluyen continuamente desde proveedores de atención médica, entonces necesitamos una arquitectura moderna y robusta que pueda manejar un volumen tan alto. Al mismo tiempo, la capa de análisis también debe ser…

Introducción
Snowflake es un SaaS, es decir, un software como servicio que es ideal para ejecutar análisis en grandes volúmenes de datos. La plataforma es extremadamente fácil de usar y es adecuada para usuarios empresariales, equipos de análisis, etc., para obtener valor de los conjuntos de datos cada vez mayores. Este artículo describirá los componentes de la creación de una plataforma de análisis semi-estructurado en tiempo real en Snowflake para datos de atención médica. También repasaremos algunas consideraciones clave durante esta fase.
Contexto
Existen muchos formatos de datos diferentes que la industria de la atención médica en su conjunto admite, pero consideraremos uno de los últimos formatos semi-estructurados, es decir, FHIR (Fast Healthcare Interoperability Resources), para construir nuestra plataforma de análisis. Este formato generalmente contiene toda la información centrada en el paciente incrustada en 1 documento JSON. Este formato contiene una gran cantidad de información, como todos los encuentros hospitalarios, resultados de laboratorio, etc. El equipo de análisis, al proporcionar un lago de datos consultable, puede extraer información valiosa, como cuántos pacientes fueron diagnosticados con cáncer, etc. Supongamos que todos estos archivos JSON se cargan en AWS S3 (u otro almacenamiento en la nube pública) cada 15 minutos a través de diferentes servicios de AWS o puntos finales de API.
- ¿Es la Ciencia de Datos una buena carrera?
- ¿Cómo cambiar de carrera de analista de datos a científico de datos?
- Narración de historias con gráficos
Diseño Arquitectónico
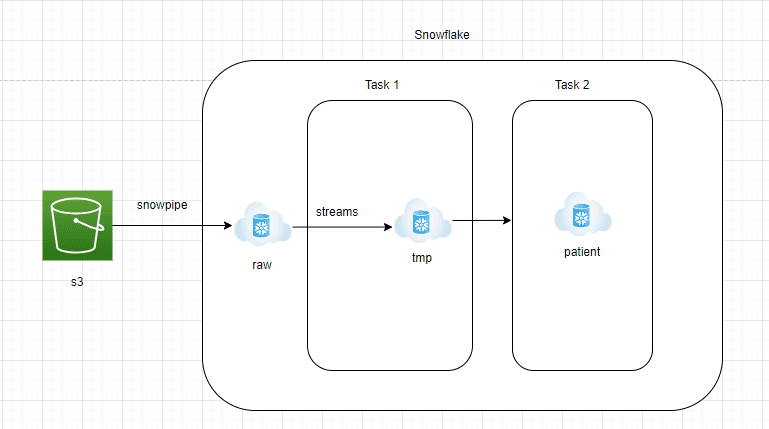
Componentes Arquitectónicos
AWS S3 a la zona RAW de Snowflake:
- Los datos deben ser transmitidos continuamente desde AWS S3 a la zona RAW de Snowflake.
- Snowflake ofrece el servicio gestionado Snowpipe, que puede leer archivos JSON de S3 de forma continua.
- Se debe crear una tabla con una columna variante en la zona RAW de Snowflake para almacenar los datos JSON en su formato nativo.
Zona RAW de Snowflake a Streams:
- Streams es un servicio de captura de cambios gestionado que será capaz de capturar todos los nuevos documentos JSON entrantes en la zona RAW de Snowflake
- Las Streams estarían apuntando a la tabla de la zona RAW de Snowflake y deberían configurarse con append=true
- Las Streams son como cualquier otra tabla y se pueden consultar fácilmente.
Tarea 1 de Snowflake:
- La tarea de Snowflake es un objeto similar a un programador. Las consultas o procedimientos almacenados se pueden programar para que se ejecuten utilizando notaciones de trabajos cron
- En esta arquitectura, creamos la Tarea 1 para obtener los datos de las Streams e ingresarlos en una tabla de preparación. Esta capa se truncaría y volvería a cargar
- Esto se hace para asegurarse de que los nuevos documentos JSON se procesen cada 15 minutos
Tarea 2 de Snowflake:
- Esta capa convertirá el documento JSON sin procesar en tablas de informes que el equipo de análisis puede consultar fácilmente.
- Para convertir los documentos JSON en formato estructurado, se puede usar la función lateral flatten de Snowflake.
- Lateral flatten es una función fácil de usar que explota los elementos de matriz anidados y se puede extraer fácilmente utilizando la notación ‘:’.
Consideraciones Clave
- Se recomienda utilizar Snowpipe con algunos archivos grandes. El costo puede aumentar si los archivos pequeños en el almacenamiento externo no se agrupan
- En un entorno de producción, asegúrese de crear procesos automatizados para monitorear las Streams, ya que una vez que se vuelven obsoletas, no se puede recuperar datos de ellas
- El tamaño máximo permitido de un solo documento JSON comprimido que se puede cargar en Snowflake es de 16 MB. Si tiene documentos JSON grandes que exceden estos límites de tamaño, asegúrese de tener un proceso para dividirlos antes de ingresarlos en Snowflake
Conclusión
La gestión de datos semi-estructurados siempre es un desafío debido a la estructura anidada de los elementos incrustados dentro de los documentos JSON. Considere el aumento gradual y exponencial del volumen de datos entrantes antes de diseñar la capa de informes final. Este artículo tiene como objetivo demostrar lo fácil que es construir un canal de transmisión con datos semi-estructurados.
Milind Chaudhari es un experimentado ingeniero de datos/arquitecto de datos que tiene una década de experiencia laboral en la construcción de lagos/lakehouses de datos utilizando una variedad de herramientas convencionales y modernas. Es extremadamente apasionado por la arquitectura de transmisión de datos y también es revisor técnico en Packt y O’Reilly.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ¿Qué es los datos sintéticos?
- El enemigo invisible de la IA enfrentando el desafío de la materia oscura digital
- Convirtiendo viejos mapas en modelos digitales en 3D de vecindarios perdidos.
- Cómo convertirse en un científico de datos sin experiencia técnica consejos y estrategias
- Investigadores enseñan a una IA a escribir mejores leyendas de gráficos
- Usando GANs en TensorFlow para generar imágenes
- ¿Qué es la simulación de robótica?






