Búsqueda de similitud, Parte 4 Hierarchical Navigable Small World (HNSW)
Hierarchical Navigable Small World (HNSW) for similarity search.
Descubre cómo construir grafos multicapa eficientes para aumentar la velocidad de búsqueda en volúmenes masivos de datos
La búsqueda de similitud es un problema en el que, dado una consulta, el objetivo es encontrar los documentos más similares a ella entre todos los documentos de la base de datos.
Introducción
En ciencia de datos, la búsqueda de similitud a menudo aparece en el dominio del procesamiento del lenguaje natural, en los motores de búsqueda o en los sistemas recomendadores donde se deben recuperar los documentos o elementos más relevantes para una consulta. Existe una gran variedad de diferentes formas de mejorar el rendimiento de la búsqueda en volúmenes masivos de datos.
Hierarchical Navigable Small World (HNSW) es un algoritmo de última generación utilizado para una búsqueda aproximada de vecinos más cercanos. Bajo el capó, HNSW construye estructuras de gráficos optimizados, lo que lo hace muy diferente de otros enfoques que se discutieron en partes anteriores de esta serie de artículos.
- Búsqueda de similitud, Parte 3 Mezclando el índice de archivo invertido y la cuantificación de productos.
- Inferencia Variacional Lo Básico
- Aprendiendo la Estimación de Poses Usando Nuevas Técnicas de Visión por Computadora
La idea principal de HNSW es construir un grafo de tal manera que se pueda recorrer un camino entre cualquier par de vértices en un número reducido de pasos.
Una analogía bien conocida sobre la famosa regla de los seis apretones de manos se relaciona con este método:
Todas las personas están a seis o menos conexiones sociales de distancia entre sí.
Antes de proceder a los trabajos internos de HNSW, discutamos primero las listas de salto y las pequeñas palabras navegables, estructuras de datos cruciales utilizadas dentro de la implementación de HNSW.
Listas de salto
La lista de salto es una estructura de datos probabilística que permite insertar y buscar elementos dentro de una lista ordenada en O (logn) en promedio. Se construye una lista de salto por varias capas de listas vinculadas. La capa inferior tiene la lista vinculada original con todos los elementos en ella. Al pasar a niveles superiores, aumenta el número de elementos saltados, disminuyendo así el número de conexiones.

El procedimiento de búsqueda de un valor determinado comienza desde el nivel más alto y compara su siguiente elemento con el valor. Si el valor es menor o igual al elemento, entonces el algoritmo procede a su siguiente elemento. De lo contrario, el procedimiento de búsqueda desciende al nivel inferior con más conexiones y repite el mismo proceso. Al final, el algoritmo desciende al nivel más bajo y encuentra el nodo deseado.
Según la información de Wikipedia, una lista de salto tiene el parámetro principal p que define la probabilidad de que un elemento aparezca en varias listas. Si un elemento aparece en la capa i, entonces la probabilidad de que aparezca en la capa i + 1 es igual a p (p generalmente se establece en 0.5 o 0.25). En promedio, cada elemento se presenta en 1 / (1 – p) listas.
Como podemos ver, este proceso es mucho más rápido que la búsqueda lineal normal en la lista vinculada. De hecho, HNSW hereda la misma idea pero en lugar de listas vinculadas, utiliza gráficos.
Pequeño mundo navegable
Pequeño mundo navegable es un grafo con complejidad de búsqueda T = O(logᵏn) polilogarítmica que utiliza un enrutamiento codicioso. Enrutamiento se refiere al proceso de iniciar el proceso de búsqueda desde vértices de bajo grado y terminar con vértices de alto grado. Dado que los vértices de bajo grado tienen muy pocas conexiones, el algoritmo puede moverse rápidamente entre ellos para navegar eficientemente hacia la región donde es probable que se encuentre el vecino más cercano. Luego, el algoritmo se acerca gradualmente y cambia a vértices de alto grado para encontrar el vecino más cercano entre los vértices en esa región.
El vértice a veces también se conoce como un nodo.
Búsqueda
En primer lugar, la búsqueda se realiza eligiendo un punto de entrada. Para determinar el siguiente vértice (o vértices) al que el algoritmo se mueve, calcula las distancias desde el vector de consulta a los vecinos del vértice actual y se mueve al más cercano. En algún momento, el algoritmo finaliza el procedimiento de búsqueda cuando no puede encontrar un nodo vecino que esté más cerca de la consulta que el propio nodo actual. Este nodo se devuelve como respuesta a la consulta.
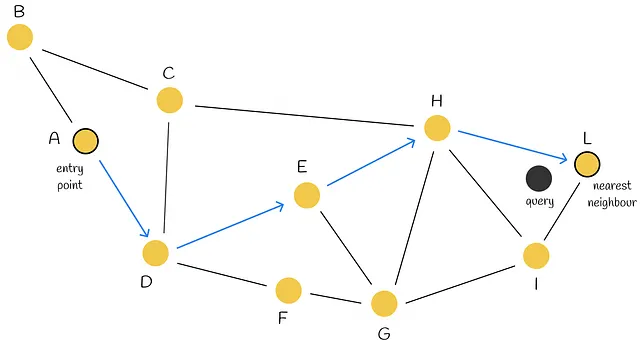
Esta estrategia voraz no garantiza que se encuentre el vecino más cercano exacto ya que el método utiliza solo información local en el paso actual para tomar decisiones. La detención temprana es uno de los problemas del algoritmo. Ocurre especialmente al comienzo del procedimiento de búsqueda cuando no hay nodos vecinos mejores que el actual. En su mayor parte, esto puede suceder cuando la región de inicio tiene demasiados vértices de bajo grado.
La precisión de la búsqueda se puede mejorar utilizando varios puntos de entrada.
Construcción
El grafo NSW se construye mezclando los puntos del conjunto de datos e insertándolos uno por uno en el grafo actual. Cuando se inserta un nuevo nodo, se vincula mediante aristas a los M vértices más cercanos a él.
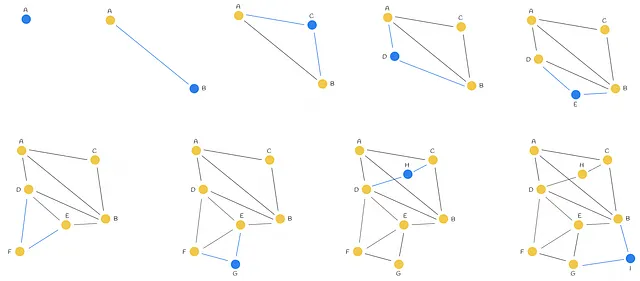
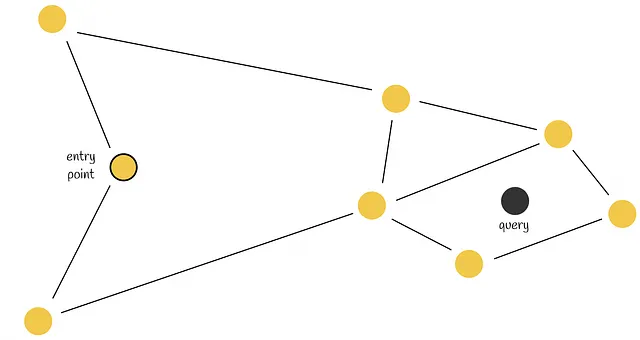
En la mayoría de los escenarios, es probable que se creen aristas de largo alcance en la fase inicial de la construcción del grafo. Estas desempeñan un papel importante en la navegación del grafo.
Los enlaces a los vecinos más cercanos de los elementos insertados al comienzo de la construcción se convierten luego en puentes entre los centros de red que mantienen la conectividad general del grafo y permiten la escala logarítmica del número de saltos durante el enrutamiento voraz. — Yu. A. Malkov, D. A. Yashunin
A partir del ejemplo en la figura anterior, podemos ver la importancia de la arista de largo alcance AB que se agregó al principio. Imagina una consulta que requiere el recorrido de un camino desde los nodos A y I, que están relativamente lejos. Tener la arista AB permite hacerlo rápidamente navegando directamente de un lado del grafo al otro.
A medida que aumenta el número de vértices en el grafo, aumenta la probabilidad de que las longitudes de las aristas recién conectadas a un nuevo nodo sean más pequeñas.
HNSW
HNSW se basa en los mismos principios que la lista de salto y el mundo pequeño navegable. Su estructura representa un grafo de varias capas con menos conexiones en las capas superiores y regiones más densas en las capas inferiores.
Búsqueda
La búsqueda comienza desde la capa más alta y procede a un nivel inferior cada vez que el vecino más cercano local es encontrado entre los nodos de la capa. En última instancia, el vecino más cercano encontrado en la capa más baja es la respuesta a la consulta.
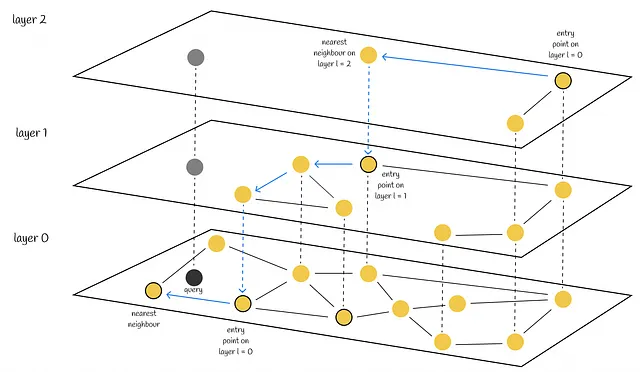
De manera similar a NSW, la calidad de búsqueda de HNSW puede ser mejorada mediante el uso de varios puntos de entrada. En lugar de encontrar solo un vecino más cercano en cada capa, se encuentran los efSearch (un hiperparámetro) vecinos más cercanos al vector de consulta y cada uno de estos vecinos se utiliza como punto de entrada en la siguiente capa.
Complejidad
Los autores del artículo original afirman que el número de operaciones necesarias para encontrar el vecino más cercano en cualquier capa está limitado por una constante. Teniendo en cuenta que el número de todas las capas en un grafo es logarítmico, obtenemos la complejidad total de búsqueda que es O(logn).
Construcción
Elección de la capa máxima
Los nodos en HNSW se insertan secuencialmente uno por uno. A cada nodo se le asigna aleatoriamente un entero l que indica la capa máxima en la que este nodo puede estar presente en el grafo. Por ejemplo, si l = 1, entonces el nodo solo se puede encontrar en las capas 0 y 1. Los autores seleccionan l aleatoriamente para cada nodo con una distribución de probabilidad exponencialmente decreciente normalizada por el multiplicador no nulo mL (mL = 0 da como resultado una sola capa en HNSW y una complejidad de búsqueda no optimizada). Normalmente, la mayoría de los valores de l deberían ser iguales a 0, por lo que la mayoría de los nodos solo están presentes en el nivel más bajo. Los valores más grandes de mL aumentan la probabilidad de que un nodo aparezca en capas superiores.

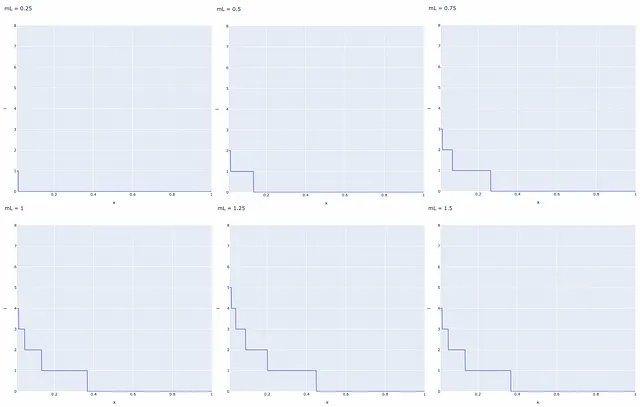
Para lograr la ventaja de rendimiento óptimo de la jerarquía controlable, la superposición entre vecinos en diferentes capas (es decir, el porcentaje de vecinos que también pertenecen a otras capas) debe ser pequeña. — Yu. A. Malkov, D. A. Yashunin.
Una de las formas de disminuir la superposición es disminuir mL. Pero es importante tener en cuenta que la reducción de mL también conduce en promedio a más recorridos durante una búsqueda codiciosa en cada capa. Es por eso que es esencial elegir un valor de mL que equilibre tanto la superposición como el número de recorridos.
Los autores del artículo proponen elegir el valor óptimo de mL que es igual a 1/ ln(M). Este valor corresponde al parámetro p = 1/M de la lista de salto siendo una superposición promedio de un solo elemento entre las capas.
Inserción
Después de que un nodo recibe el valor l, hay dos fases de su inserción:
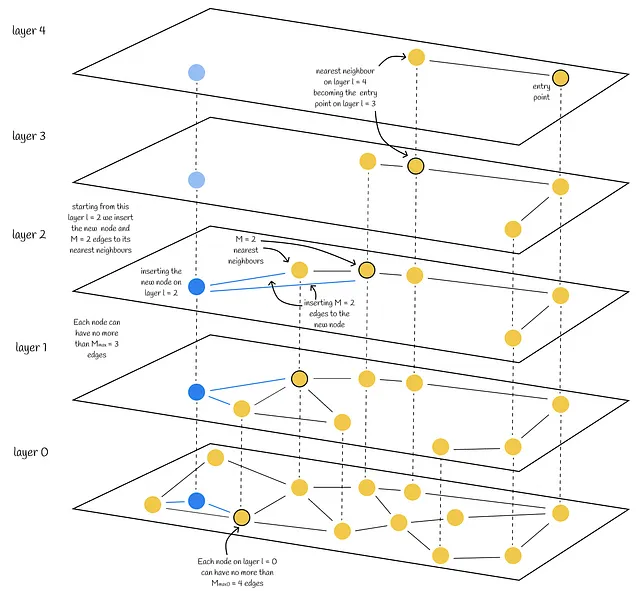
- El algoritmo comienza desde la capa superior y encuentra codiciosamente el nodo más cercano. El nodo encontrado se utiliza como punto de entrada en la siguiente capa y el proceso de búsqueda continúa. Una vez alcanzada la capa l, la inserción continúa con el segundo paso.
- A partir de la capa l, el algoritmo inserta el nuevo nodo en la capa actual. Luego actúa igual que antes en el paso 1, pero en lugar de encontrar solo un vecino más cercano, busca codiciosamente los efConstruction (hiperparámetro) vecinos más cercanos. Luego se eligen M de los vecinos efConstruction y se construyen bordes desde el nodo insertado hacia ellos. Después de eso, el algoritmo desciende a la siguiente capa y cada uno de los nodos efConstruction encontrados actúa como punto de entrada. El algoritmo termina después de que el nuevo nodo y sus bordes se insertan en la capa más baja 0.
Elección de valores para los parámetros de construcción
El artículo original proporciona varios conocimientos útiles sobre cómo elegir hiperparámetros:
- Según las simulaciones, los buenos valores para M se encuentran entre 5 y 48. Los valores más pequeños de M tienden a ser mejores para recuperaciones más bajas o datos de baja dimensión, mientras que los valores más altos de M son más adecuados para recuperaciones más altas o datos de alta dimensión.
- Valores más altos de efConstruction implican una búsqueda más profunda ya que se exploran más candidatos. Sin embargo, requiere más cálculos. Los autores recomiendan elegir un valor de efConstruction que resulte en una recuperación cercana a 0,95-1 durante el entrenamiento.
- Además, existe otro parámetro importante Mₘₐₓ – el número máximo de bordes que puede tener un vértice. Aparte de ello, existe el mismo parámetro Mₘₐₓ₀ pero por separado para la capa más baja. Se recomienda elegir un valor para Mₘₐₓ cercano a 2*M. Los valores mayores que 2*M pueden llevar a una degradación del rendimiento y un uso excesivo de memoria. Al mismo tiempo, Mₘₐₓ = M resulta en un rendimiento pobre en una recuperación alta.
Heurística de selección de candidatos
Se observó anteriormente que durante la inserción de un nodo, M de los candidatos de efConstruction se eligen para construir bordes hacia ellos. Discutamos posibles formas de elegir estos M nodos.
El enfoque ingenuo toma los M candidatos más cercanos. Sin embargo, no siempre es la elección óptima. A continuación, se muestra un ejemplo que lo demuestra.
Imaginemos un grafo con la estructura de la figura siguiente. Como se puede ver, hay tres regiones, dos de las cuales no están conectadas entre sí (a la izquierda y en la parte superior). Como resultado, llegar, por ejemplo, desde el punto A al punto B requiere un camino largo a través de otra región. Sería lógico conectar de alguna manera estas dos regiones para una mejor navegación.
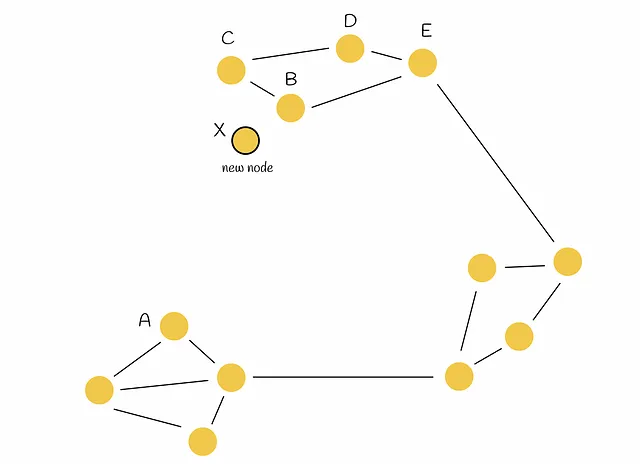
Luego se inserta un nodo X en el grafo y se necesitan conectar M = 2 vértices más.
En este caso, el enfoque ingenuo toma directamente los M = 2 vecinos más cercanos ( B y C ) y conecta X con ellos. Aunque X está conectado a sus verdaderos vecinos más cercanos, no resuelve el problema. Veamos el enfoque heurístico inventado por los autores.
La heurística considera no solo las distancias más cercanas entre los nodos, sino también la conectividad de diferentes regiones en el grafo.
La heurística elige el primer vecino más cercano ( B en nuestro caso) y conecta el nodo insertado ( X ) a él. Luego, el algoritmo toma secuencialmente otro vecino más cercano en orden ordenado ( C ) y construye un borde hacia él solo si su distancia al nuevo nodo ( X ) es mayor que cualquier distancia del vecino a todos los vértices ya conectados ( B ) al nuevo nodo ( X ). Después de eso, el algoritmo procede al siguiente vecino más cercano hasta que se construyen M bordes.
Volviendo al ejemplo, el procedimiento heurístico se ilustra en la figura siguiente. La heurística elige B como el vecino más cercano para X y construye el borde BX. Luego, el algoritmo elige C como el siguiente vecino más cercano. Sin embargo, esta vez BC < CX . Esto indica que agregar el borde CX al grafo no es óptimo porque ya existe el borde BX y los nodos B y C están muy cerca uno del otro. La misma analogía se aplica a los nodos D y E. Después de eso, el algoritmo examina el nodo A. Esta vez, satisface la condición ya que AC > AX. Como resultado, el nuevo borde AX y ambas regiones iniciales se conectan entre sí.

Complejidad
El proceso de inserción funciona de manera muy similar, en comparación con el procedimiento de búsqueda, sin ninguna diferencia significativa que pueda requerir un número no constante de operaciones. Por lo tanto, la inserción de un solo vértice impone un tiempo de O(logn). Para estimar la complejidad total, se debe considerar el número de todos los nodos insertados n en un conjunto de datos dado. En última instancia, la construcción de HNSW requiere un tiempo de O(n * logn).
Combinando HNSW con otros métodos
HNSW se puede utilizar junto con otros métodos de búsqueda de similitud para proporcionar un mejor rendimiento. Una de las formas más populares de hacerlo es combinarlo con un índice de archivo invertido y cuantificación de productos (IndexIVFPQ), que se describieron en otras partes de esta serie de artículos.
Búsqueda de similitud, parte 3: Mezcla de índice de archivo invertido y cuantificación de productos
En las dos primeras partes de esta serie, hemos discutido dos algoritmos fundamentales en la recuperación de información: invertido…
Zepes.com
Dentro de este paradigma, HNSW cumple el papel de un cuantizador grueso para IndexIVFPQ, lo que significa que será responsable de encontrar la partición de Voronoi más cercana, para que el alcance de la búsqueda se pueda reducir. Para hacerlo, se debe construir un índice HNSW en todos los centroides de Voronoi. Cuando se recibe una consulta, se utiliza HNSW para encontrar el centroide de Voronoi más cercano (en lugar de la búsqueda por fuerza bruta como antes, comparando las distancias con cada centroide). Después de eso, el vector de consulta se cuantifica dentro de una partición de Voronoi respectiva y se calculan las distancias mediante el uso de códigos PQ.
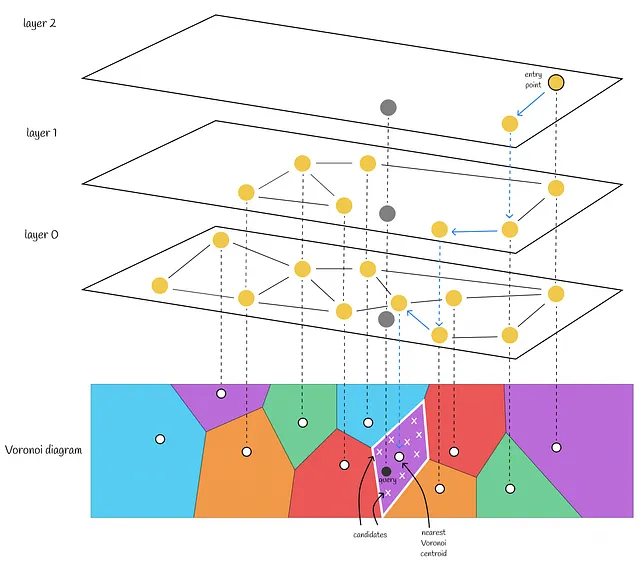
Cuando se usa solo un índice de archivo invertido, es mejor establecer el número de particiones de Voronoi no demasiado grande (256 o 1024, por ejemplo), porque se realiza una búsqueda por fuerza bruta para encontrar los centroides más cercanos. Al elegir un número pequeño de particiones de Voronoi, el número de candidatos dentro de cada partición se vuelve relativamente grande. Por lo tanto, el algoritmo identifica rápidamente el centroide más cercano para una consulta y la mayor parte de su tiempo de ejecución se concentra en encontrar el vecino más cercano dentro de una partición de Voronoi.
Sin embargo, la introducción de HNSW en el flujo de trabajo requiere un ajuste. Considere ejecutar HNSW solo en un pequeño número de centroides (256 o 1024): HNSW no aportaría ningún beneficio significativo porque, con un pequeño número de vectores, HNSW realiza relativamente lo mismo en términos de tiempo de ejecución que la búsqueda por fuerza bruta ingenua. Además, HNSW requeriría más memoria para almacenar la estructura del grafo.
Por eso, al fusionar HNSW e índice de archivo invertido, se recomienda establecer el número de centroides de Voronoi mucho más grande de lo habitual. Al hacerlo, el número de candidatos dentro de cada partición de Voronoi se vuelve mucho más pequeño.
Este cambio de paradigma da como resultado la siguiente configuración:
- HNSW identifica rápidamente los centroides de Voronoi más cercanos en tiempo logarítmico.
- Después de eso, se realiza una búsqueda exhaustiva dentro de las particiones de Voronoi respectivas. No debería haber ningún problema porque el número de candidatos potenciales es pequeño.
Implementación de Faiss
Faiss (Facebook AI Search Similarity) es una biblioteca de Python escrita en C++ utilizada para la búsqueda optimizada de similitud. Esta biblioteca presenta diferentes tipos de índices que son estructuras de datos utilizadas para almacenar eficientemente los datos y realizar consultas.
Basándonos en la información de la documentación de Faiss , veremos cómo se puede utilizar HNSW y fusionarlo junto con el índice de archivos invertidos y la cuantificación de productos.
IndexHNSWFlat
FAISS tiene una clase IndexHNSWFlat que implementa la estructura HNSW. Como de costumbre, el sufijo “Flat” indica que los vectores del conjunto de datos se almacenan completamente en el índice. El constructor acepta 2 parámetros:
- d : dimensionalidad de los datos.
- M : el número de aristas que deben agregarse a cada nuevo nodo durante la inserción.
Además, a través del campo hnsw, IndexHNSWFlat proporciona varios atributos y métodos útiles (que se pueden modificar):
- hnsw.efConstruction : número de vecinos más cercanos a explorar durante la construcción.
- hnsw.efSearch : número de vecinos más cercanos a explorar durante la búsqueda.
- hnsw.max_level : devuelve el nivel máximo.
- hnsw.entry_point : devuelve el punto de entrada.
- faiss.vector_to_array(index.hnsw.levels) : devuelve una lista de niveles máximos para cada vector
- hnsw.set_default_probas(M: int, level_mult: float) : permite establecer valores para M y mL, respectivamente. Por defecto, level_mult se establece en 1 / ln(M) .
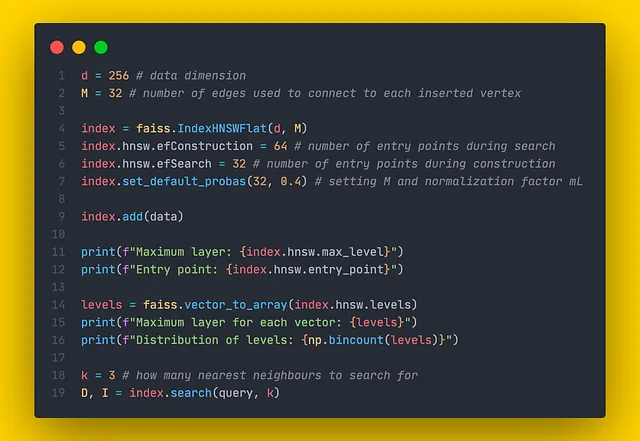
IndexHNSWFlat establece valores para Mₘₐₓ = M y Mₘₐₓ₀ = 2 * M.
IndexHNSWFlat + IndexIVFPQ
IndexHNSWFlat también puede combinarse con otros índices. Uno de los ejemplos es IndexIVFPQ descrito en la parte anterior. La creación de este índice compuesto procede en dos pasos:
- IndexHNSWFlat se inicializa como cuantificador grueso.
- El cuantificador se pasa como parámetro al constructor de IndexIVFPQ .
El entrenamiento y la adición se pueden realizar utilizando datos diferentes o los mismos datos.

Conclusión
En este artículo, hemos estudiado un algoritmo robusto que funciona especialmente bien para grandes vectores de conjunto de datos. Al utilizar representaciones de gráficos de múltiples capas y la heurística de selección de candidatos, su velocidad de búsqueda se escala eficientemente mientras mantiene una precisión de predicción decente. También vale la pena señalar que HNSW se puede usar en combinación con otros algoritmos de búsqueda de similitud, lo que lo hace muy flexible.
Recursos
- Seis grados de separación | Wikipedia
- Skip List | Wikipedia
- Búsqueda de vecinos más cercanos aproximada eficiente y robusta utilizando gráficos navegables pequeños del mundo jerárquico. Yu. A. Malkov, D. A. Yashunin
- Documentación de Faiss
- Repositorio de Faiss
- Resumen de índices de Faiss
Todas las imágenes, salvo indicación contraria, son del autor.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ¡Hola GPU, ¿qué hay de mi matriz?
- Dominando la Gestión de Configuración en Aprendizaje Automático con Hydra.
- Gestionando modelos de aprendizaje profundo fácilmente con configuraciones TOML
- Si el arte es cómo expresamos nuestra humanidad, ¿dónde encaja la IA?
- Detectando el Crecimiento del Cáncer Utilizando Inteligencia Artificial y Visión por Computadora.
- Flujos de trabajo CI/CD sin interrupciones con GitHub Actions en GCP sus herramientas para una eficaz MLOps.
- Problema del Gradiente Desvaneciente Causas, Consecuencias y Soluciones.






