META’s Hiera reduce la complejidad para aumentar la precisión.
Hiera de META reduces complexity to increase accuracy.
| INTELIGENCIA ARTIFICIAL | VISIÓN POR COMPUTADORA | VITs |
La simplicidad permite que la IA alcance un rendimiento increíble y una velocidad sorprendente
Las redes convolucionales han dominado el campo de la visión por computadora durante más de veinte años. Con la llegada de los transformers, se creía que serían abandonados. ¿Por qué muchos profesionales usan modelos basados en convolución para proyectos?
Este artículo intenta responder a estas preguntas:
- ¿Qué son los Vision Transformers?
- ¿Cuáles son sus limitaciones?
- ¿Podemos intentar superarlas?
- ¿Por qué y cómo parece que META Hiera tiene éxito?
Transformador de visión: ¿Cuántas palabras vale una imagen?

En los últimos años, los transformers de visión han dominado los benchmarks de visión, pero exactamente ¿qué son?
Hasta hace unos años, las redes neuronales convolucionales eran el estándar en tareas de visión. Sin embargo, en 2017, se lanzó el transformer y revolucionó el mundo del procesamiento del lenguaje natural. En el artículo “Attention is all you need”, los autores demuestran que un modelo construido solo con auto-atención es capaz de un rendimiento muy superior a los RNN y LSTMs. Entonces, uno se pregunta: ¿es posible aplicar un transformer a imágenes?
- La Inteligencia Artificial ayuda a mostrar cómo fluyen los líquidos del cerebro.
- Descubriendo los efectos perjudiciales de la IA en la comunidad trans
- ¡Di una vez! Repetir palabras no ayuda a la IA.
Los modelos híbridos donde se incluía la integración de la auto-atención se habían intentado antes del 2020. En cualquier caso, estos modelos no podían escalar bien. La idea era encontrar una forma en la que el transformer pudiera usarse de forma nativa con imágenes.
En el 2020, los autores de Google decidieron que la mejor forma era dividir las imágenes en diferentes parches y luego tener una incrustación de la secuencia. De esta forma, las imágenes se tratan básicamente como si fueran tokens (palabras) del modelo.
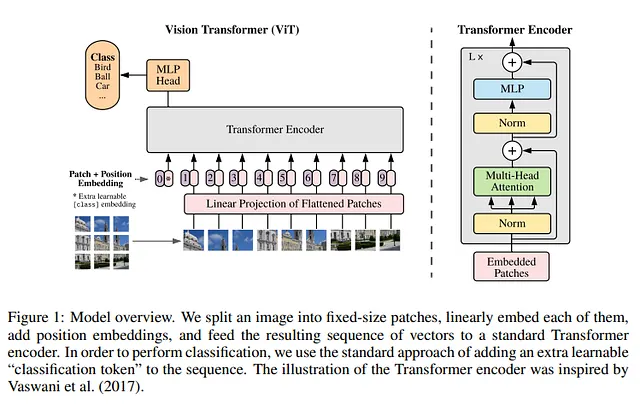
En poco tiempo, el dominio de las CNN en la visión por computadora está siendo socavado. Los transformers de visión demuestran ser superiores en benchmarks (como ImageNet) donde las CNN habían dominado hasta ahora.
De hecho, proporcionando suficiente información, los Vision Transformers (ViTs) muestran que son superiores a las CNN. También se muestra que aunque hay varias diferencias, también hay varias similitudes:
- ambos ViTs y las CNN construyen una representación compleja y progresiva.
- Sin embargo, los ViTs son más capaces de explotar la información presente en el fondo y parecen ser más robustos.
Un viaje visual en lo que los Vision-Transformers ven
Cómo ven el mundo algunos de los modelos más grandes
pub.towardsai.net
Además, una ventaja adicional es la capacidad de escalar del transformer. Esta ha sido una ventaja competitiva de los ViTs que los ha convertido en una opción popular.
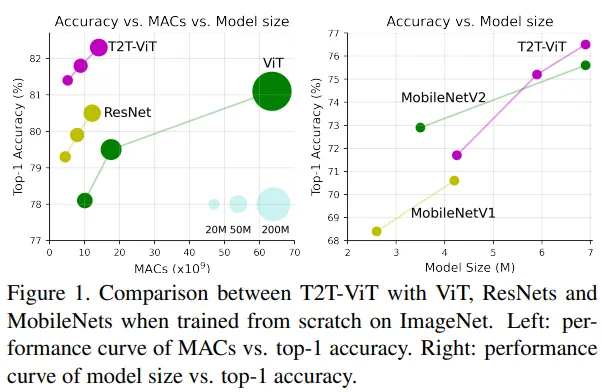
De hecho, a lo largo de los años hemos visto CNNs con millones de parámetros y ViTs alcanzando billones de parámetros. El año pasado, Google demostró cómo se puede escalar los ViTs hasta 20 B de parámetros y probablemente en el futuro veremos modelos aún más grandes.
¿Por qué tenemos modelos de lenguaje enormes y transformadores de visión pequeños?
Google ViT-22 allana el camino para nuevos transformadores grandes y para revolucionar la visión por computadora
towardsdatascience.com
El límite del transformador de visión
Adaptar nativamente el transformador aún tiene un costo: los ViTs utilizan sus parámetros de manera ineficiente. Esto se debe a que utilizan la misma resolución espacial y el mismo número de canales en la red.
Las CNNs tenían precisamente dos aspectos que determinaron sus fortunas iniciales (ambos inspirados en la corteza humana):
- Reducción en la resolución espacial al subir en la jerarquía de capas.
- Aumento en el número de diferentes “canales”, y cada uno de estos canales se vuelve más y más especializado.
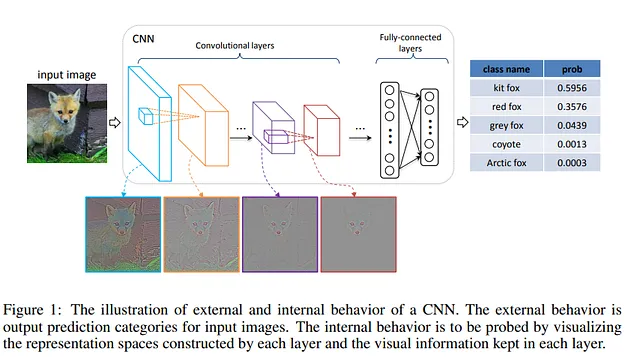
El transformador, por otro lado, tiene una estructura diferente: una secuencia de bloques de auto-atención donde ocurren dos operaciones principales que le permiten generalizar bien:
- la operación de atención que se utiliza para modelar las relaciones entre elementos.
- Una capa completamente conectada que en su lugar modela la relación entre elementos.
De hecho, esto se notó antes y se debe a que el transformador fue diseñado para palabras y no para imágenes. Después de todo, el texto e imágenes son dos modos diferentes. Una de las diferencias es que las palabras no varían en escala mientras que las imágenes sí. Esto es conflictivo cuando tienes que prestar atención a elementos que cambian a escala en la detección de objetos.
Además, la resolución de los píxeles en una imagen es mayor que la resolución de las palabras en un pasaje de texto. Dado que la atención tiene un costo cuadrático, utilizar imágenes de alta resolución tiene un alto costo computacional con un transformador.
Estudios anteriores han intentado resolver este problema con el uso de mapas de características jerárquicas. Por ejemplo, el Swin Transformer construye una representación jerárquica comenzando con pequeños parches y luego fusionando gradualmente los diversos parches vecinos.
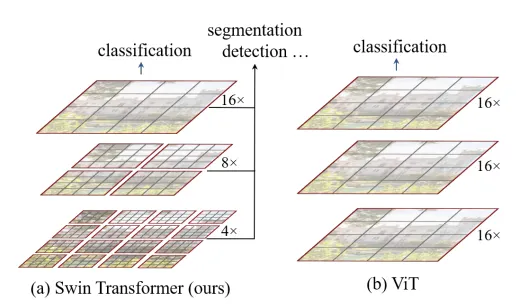
Otros estudios han intentado implementar múltiples canales en ViTs. Por ejemplo, los MVIT han intentado crear canales iniciales que se centran en información visual simple de bajo nivel mientras que los canales más profundos se centran en características complejas de alto nivel como en las CNNs.

Sin embargo, esto no resolvió completamente el problema. Con el tiempo, se han propuesto modelos cada vez más complejos y módulos especializados que han mejorado el rendimiento hasta cierto punto pero han hecho que los ViTs sean bastante lentos en el entrenamiento.
¿Podemos resolver estas limitaciones del transformador sin necesidad de soluciones complejas?
Cómo aprender la relación espacial

Las ViTs han surgido como modelo para la visión por computadora, sin embargo, se han necesitado modificaciones cada vez más complejas para adaptarlas.
¿Podemos resolver estas limitaciones de los transformadores sin necesidad de soluciones complejas?
En los últimos años, se han realizado esfuerzos para simplificar los modelos y acelerar su velocidad. Una forma comúnmente utilizada es la introducción de la dispersión. En el caso de la visión por computadora, un modelo que ha tenido mucho éxito ha sido el de los autoencoder enmascarados (MAE).
En ese caso, después de dividir en parches, se enmascaran una cantidad de parches. Luego, el decodificador tiene que reconstruir a partir de los parches enmascarados. El codificador ViT luego trabaja solo en el 25 por ciento de los parches. De esta manera, se pueden entrenar codificadores amplios con una fracción de la computación y la memoria.
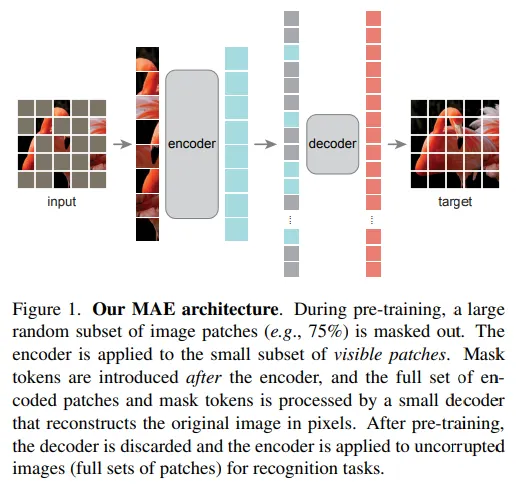
Se ha demostrado que este método es capaz de enseñar razonamiento espacial, logrando resultados comparables, si no superiores, a Swin y Mvit (que, sin embargo, son mucho más complejos computacionalmente).
Por otro lado, si bien el régimen de dispersión obtenido logra eficiencia en el entrenamiento, una de las grandes ventajas de las CNN es el enfoque jerárquico. Pero esto es conflictivo con la dispersión.
De hecho, se ha probado antes pero sin mucho éxito:
- El modelo obtenido era demasiado lento (MaskFeat o SimMIM).
- Las modificaciones realizadas hicieron que el modelo fuera innecesariamente complejo y sin ganancias en precisión (UM-MAE o MCMAE).
¿Es posible diseñar un modelo espaciado y jerárquico pero eficiente?
Un nuevo trabajo de META se ha alejado del entrenamiento MAE y otros trucos para construir un ViT que sea eficiente y preciso sin la necesidad de todas esas estructuras complejas que se han utilizado en el pasado.
Hiera: Un transformador de visión jerárquico sin campanas ni silbidos
Los transformadores de visión jerárquicos modernos han agregado varios componentes específicos de visión en la búsqueda de la supervisión…
arxiv.org
Hiera: ViT jerárquico, espaciado y eficiente
El modelo
La idea básica es que para entrenar una ViT jerárquica con alta precisión en tareas visuales, no es necesario utilizar toda una serie de elementos que la hacen lenta y compleja. Según los autores, se puede aprender sesgo espacial del modelo utilizando el entrenamiento de los autoencoder enmascarados.
En el MAE, se eliminan los parches, por lo que en un modelo jerárquico, tiene problemas para reconstruir la rejilla 2D (y las relaciones espaciales). Los autores resuelven esto para que el kernel no pueda superponerse entre las unidades de máscara (durante el agrupamiento, no hay superposición con las unidades enmascaradas).

Los autores partieron de un modelo jerárquico existente de ViT, MViTv2, y decidieron reutilizarlo utilizando el entrenamiento MAE. El modelo está compuesto por varios bloques ViT, pero como se puede ver en la estructura, en algún momento hay una reducción de tamaño que se logra mediante el uso de la atención de agrupamiento.
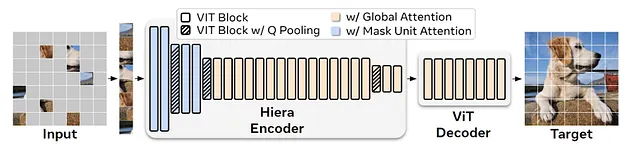
Durante la atención de agrupamiento, las características se agregan localmente utilizando una convolución 3×3 y luego se calcula la autoatención (esto es para reducir el tamaño de K y V y así reducir la computación computacional). Este mecanismo puede volverse costoso cuando se utiliza video. Por lo tanto, los autores lo reemplazaron con la Atención de Unidad de Máscara.
En otras palabras, en Hiera durante el agrupamiento, el kernel se desplaza para que las partes enmascaradas no terminen en el agrupamiento. Por lo tanto, hay una especie de atención local para cada grupo de tokens (del tamaño de la máscara).

Luego, MViTv2 había introducido una serie completa de accesorios que aumentaron la complejidad, aunque los autores los consideraron no esenciales y los eliminaron:
- Incrustaciones de posición relativa. La incrustación de posición se agrega a la atención en cada bloque.
- Capas de agrupación máxima, que habrían requerido un relleno para su uso en Hiera.
- Residuo de atención, donde hay una conexión residual entre Q (consulta) y la salida para aprender mejor la atención de agrupamiento. Los autores han reducido el número de capas para que ya no sea necesario.
Los autores muestran que el impacto de estos cambios conduce singularmente a una mejora del rendimiento tanto en precisión (acc.) como en velocidad (imágenes por segundo).
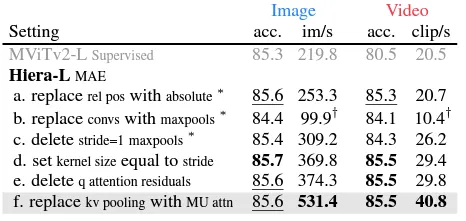
En general, simplificar el modelo hace que Hiera no solo sea mucho más rápido (tanto para imágenes como para video), sino también más preciso (que tanto su contraparte MViTv2 como otros modelos).
Hiera es 2,4 veces más rápido en imágenes y 5,1 veces más rápido en video que el MViTv2 con el que comenzamos y es realmente más preciso debido a MAE (fuente)
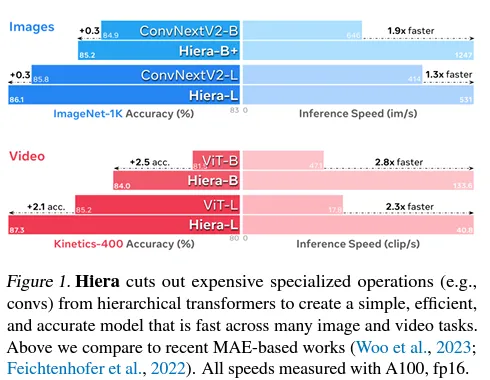
Los autores señalan que el modelo no solo es más rápido en inferencia, sino que el entrenamiento también es mucho más rápido.

Resultados
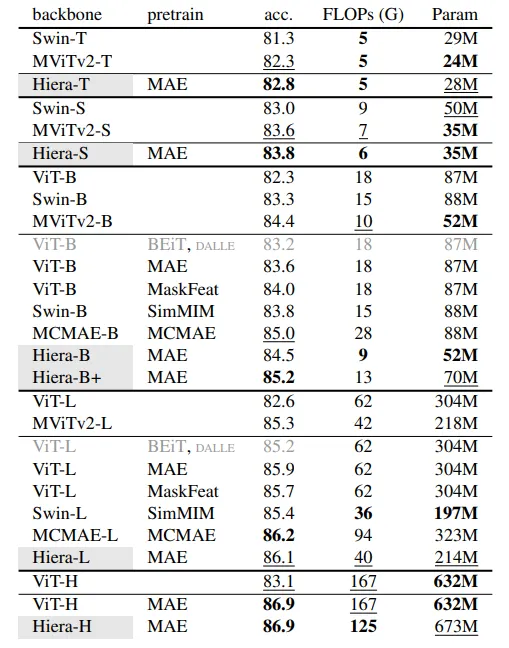
Los autores muestran cómo efectivamente el modelo básico con un número limitado de parámetros logra buenos resultados en Imagenet 1K (uno de los conjuntos de datos más importantes de clasificación de imágenes).
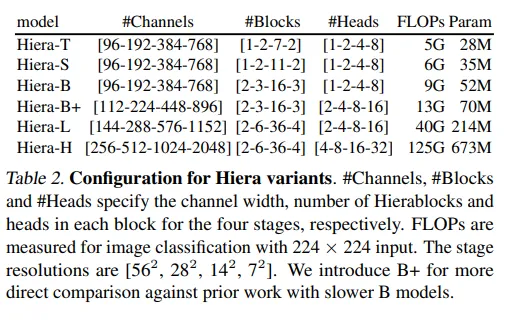
El segundo punto es que normalmente en los regímenes de parámetros bajos, los modelos basados en convolución dominaron. Aquí, el modelo más pequeño muestra muy buenos resultados. Para los autores, esto confirma sus intuiciones de que se puede aprender un sesgo espacial durante el entrenamiento y, por lo tanto, hacer que ViTs sea competitivo con la red convolucional incluso para modelos pequeños.
La fortuna de los modelos grandes de CNN fue usarlos para el aprendizaje por transferencia. Tanto los modelos basados en ResNet como en VGG se han entrenado en Imagenet y luego la comunidad los ha adaptado para muchas tareas. Por lo tanto, los autores prueban Hiera por su capacidad de aprendizaje por transferencia utilizando dos conjuntos de datos: iNaturalists y Places.
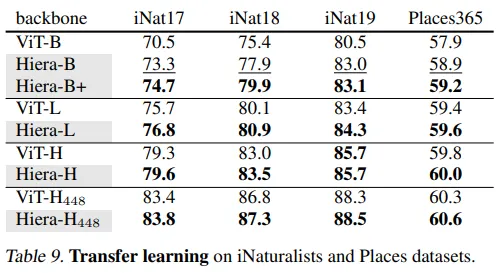
Los autores ajustan el modelo en los dos conjuntos de datos y muestran que su modelo es superior a los ViTs anteriores. Esto demuestra que su modelo también podría usarse para otros conjuntos de datos.
Además, los autores utilizan otro conjunto de datos popular, COCO. Mientras que iNaturalists y Places eran conjuntos de datos para la clasificación de imágenes, COCO es uno de los conjuntos de datos más utilizados para la segmentación de imágenes y la detección de objetos (dos tareas populares en informática). Nuevamente, el modelo muestra un fuerte comportamiento de escalado (un aumento en el rendimiento a medida que aumentan los parámetros). Además, el modelo es más rápido tanto durante el entrenamiento como en la inferencia.
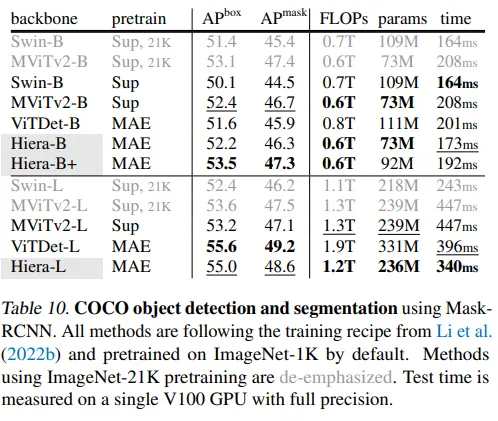
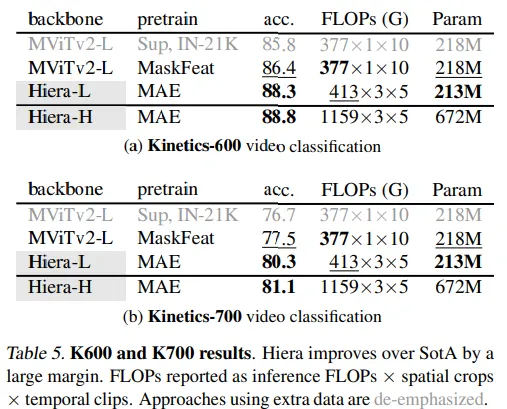
Además, el modelo ha sido probado en video. Específicamente en dos conjuntos de datos de clasificación de video. Hiera muestra que funciona mejor con menos parámetros. El modelo también es más rápido en inferencia. Los autores demuestran que el modelo logra el estado del arte para este tipo de tarea.
Los autores demuestran que el modelo también se puede utilizar en otras tareas de video, como la detección de acciones.
Pensamientos finales
En este trabajo, creamos un transformador de visión jerárquico simple tomando uno existente y eliminando todas sus campanas y silbatos mientras suministramos al modelo un sesgo espacial a través del preentrenamiento MAE. (fuente)
Los autores mostraron cómo muchos de los elementos que se han agregado para mejorar el rendimiento del transformador no solo son innecesarios, sino que aumentan la complejidad del modelo, lo que lo hace más lento.
En su lugar, los autores mostraron que el uso de MAE y una estructura jerárquica puede resultar en un ViT que es más rápido y preciso tanto para imágenes como para video.
Este trabajo es importante porque para muchas tareas, la comunidad todavía utiliza modelos basados en convolución. Los ViT son modelos muy grandes y tienen un alto costo computacional. Entonces, a menudo, las personas prefieren usar modelos basados en ResNet y VGG. Los ViT que son más precisos, pero especialmente más rápidos en la inferencia, podrían ser revolucionarios.
En segundo lugar, destaca una tendencia vista en otros lugares: aprovechar la dispersión para el entrenamiento. Lo que tiene la ventaja de reducir los parámetros y acelerar el entrenamiento y la inferencia. En general, la idea de la dispersión también se está viendo en otros campos de la inteligencia artificial y es un campo de investigación activo.
Si te ha parecido interesante:
Puedes buscar mis otros artículos, también puedes subscribirte para recibir notificaciones cuando publique artículos, puedes convertirte en miembro de Zepes para acceder a todas sus historias (enlaces de afiliado de la plataforma por la cual obtengo pequeñas ganancias sin costo para ti) y también puedes conectarte o contactarme en LinkedIn.
Aquí está el enlace a mi repositorio de GitHub, donde planeo recopilar código y muchos recursos relacionados con el aprendizaje automático, la inteligencia artificial y más.
GitHub — SalvatoreRa/tutorial: Tutoriales sobre aprendizaje automático, inteligencia artificial, ciencia de datos…
Tutoriales sobre aprendizaje automático, inteligencia artificial, ciencia de datos con explicación matemática y código reutilizable (en python…
github.com
O tal vez estés interesado en uno de mis artículos recientes:
El juego de la imitación: Dominando la brecha entre modelos de código abierto y propietarios
¿Pueden los modelos de imitación alcanzar el rendimiento de los modelos propietarios como ChatGPT?
levelup.gitconnected.com
La escalabilidad no lo es todo: Cómo los modelos más grandes fallan más duro
¿Los modelos de lenguaje grande realmente entienden los lenguajes de programación?
salvatore-raieli.medium.com
META’S LIMA: La forma de Maria Kondo para el entrenamiento de LLMs
Datos menos y ordenados para crear un modelo capaz de competir con ChatGPT
levelup.gitconnected.com
¿Es divertida la inteligencia artificial? Tal vez, un poco
Por qué la IA sigue luchando con el humor y por qué es un paso importante
levelup.gitconnected.com
Referencias
Aquí está la lista de las principales referencias que consulté para escribir este artículo, solo se cita el primer nombre de un artículo.
- Chaitanya Ryali et al, 2023, Hiera: Un transformador de visión jerárquico sin adornos, enlace
- Peng Gao et al, 2022, MCMAE: Encuentro de convolución enmascarado con autoencoders enmascarados, enlace
- Xiang Li et al, 2022, Máscara uniforme: permitiendo la preformación de MAE para transformadores de visión en pirámide con localidad, enlace
- Zhenda Xie et al, 2022, SimMIM: Un marco simple para el modelado de imágenes enmascaradas, enlace
- Ze Liu et al, 2021, Swin Transformer: Transformador de visión jerárquico utilizando ventanas desplazadas, enlace
- Haoqi Fan et al, 2021, Transformadores de visión multiescala, enlace
- Kaiming He et al, 2021, Los autoencoders enmascarados son aprendices de visión escalables, enlace
- Chen Wei et al, 2021, Predicción de características enmascaradas para la preformación visual de auto-supervisión, enlace
- Alexey Dosovitskiy et al, 2020, Una imagen vale 16×16 palabras: Transformadores para el reconocimiento de imágenes a gran escala, enlace
- Ashish Vaswani et al, 2017, La atención es todo lo que necesitas, enlace
- Kaiming He et al, 2015, Aprendizaje residual profundo para el reconocimiento de imágenes, enlace
- Wei Yu et al, 2014, Visualización y comparación de redes neuronales convolucionales, enlace
- Karen Simonyan et al, 2014, Redes convolucionales muy profundas para el reconocimiento de imágenes a gran escala, enlace
- ¿Por qué tenemos modelos de lenguaje enormes y transformadores de visión pequeños?, TDS, enlace
- Un viaje visual en lo que los transformadores de visión ven, TowardsAI, enlace
- Transformador de visión, paperswithcode, enlace
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Creando Operaciones de Aprendizaje Automático para Empresas
- La Guía Esencial de Análisis Exploratorio de Datos para un Científico de Datos.
- Predicción del éxito de un programa de recompensas en Starbucks.
- Regresión Lineal y Descenso del Gradiente
- Boto3 vs AWS Wrangler Simplificando Operaciones en S3 con Python
- Samsung adopta la IA y los grandes datos, revoluciona el proceso de fabricación de chips.
- Modelo SARIMA para la predicción de tasas de cambio de divisas.





