HashGNN Profundizando en el nuevo algoritmo de incrustación de nodos de Neo4j GDS
HashGNN Nuevo algoritmo de incrustación de nodos en Neo4j GDS
En este artículo, exploraremos junto con un pequeño ejemplo cómo HashGNN transforma los nodos del grafo en un espacio de incrustación.
Si prefieres ver un video sobre esto, puedes hacerlo aquí.
HashGNN (#GNN) es una técnica de incrustación de nodos, que emplea conceptos de Redes Neuronales de Propagación de Mensajes (MPNN) para capturar la proximidad de alto orden y las propiedades de los nodos. Acelera significativamente el cálculo en comparación con las Redes Neuronales tradicionales utilizando una técnica de aproximación llamada MinHashing. Por lo tanto, es un enfoque basado en hash e introduce un compromiso entre eficiencia y precisión. En este artículo, entenderemos qué significa todo eso y exploraremos a través de un pequeño ejemplo cómo funciona el algoritmo.
Incrustaciones de Nodos: Los nodos con contextos similares deberían estar cerca en el espacio de incrustación
Muchos casos de uso de aprendizaje automático en grafos, como la predicción de enlaces y la clasificación de nodos, requieren el cálculo de similitudes entre nodos. En un contexto de grafo, estas similitudes son más expresivas cuando capturan (i) el vecindario (es decir, la estructura del grafo) y (ii) las propiedades del nodo a incrustar. Los algoritmos de incrustación de nodos proyectan los nodos en un espacio de incrustación de baja dimensionalidad, es decir, asignan a cada nodo un vector numérico. Estos vectores, las incrustaciones, se pueden utilizar para análisis predictivos numéricos adicionales (por ejemplo, algoritmos de aprendizaje automático). Los algoritmos de incrustación optimizan la métrica: Los nodos con un contexto de grafo (vecindario) y/o propiedades similares deben ser mapeados cerca en el espacio de incrustación. Los algoritmos de incrustación de grafos generalmente emplean dos pasos fundamentales: (i) Definir un mecanismo para muestrear el contexto de los nodos (caminata aleatoria en node2vec, matriz de transición en k-fold en FastRP) y (ii) posteriormente reducir la dimensionalidad preservando las distancias entre pares (SGD en node2vec, proyecciones aleatorias en FastRP).
HashGNN: Evitar el entrenamiento de una Red Neuronal
La clave de HashGNN es que no requiere entrenar una Red Neuronal basada en una función de pérdida, como tendríamos que hacer en una Red Neuronal de Propagación de Mensajes tradicional. Como los algoritmos de incrustación de nodos optimizan para “nodos similares deben estar cerca en el espacio de incrustación”, la evaluación de la pérdida implica calcular la similitud real de un par de nodos. Esto se utiliza como retroalimentación para el entrenamiento, para determinar qué tan precisas son las predicciones y ajustar los pesos en consecuencia. A menudo, se utiliza la similitud del coseno como medida de similitud.
- Más allá del VIF Análisis de la Colinealidad para Mitigación del Sesgo y Precisión Predictiva
- Ajuste fino de un modelo Llama-2 7B para la generación de código en Python
- Una Guía Completa para MLOps
HashGNN evita el entrenamiento del modelo y en realidad no emplea una Red Neuronal en absoluto. En lugar de entrenar matrices de pesos y definir una función de pérdida, utiliza un esquema de hash aleatorio, que asigna vectores de nodos a la misma firma con la probabilidad de su similitud, lo que significa que podemos incrustar nodos sin la necesidad de comparar nodos directamente entre sí (es decir, no es necesario calcular una similitud del coseno). Esta técnica de hash se conoce como MinHashing y se definió originalmente para aproximar la similitud de dos conjuntos sin compararlos. Como los conjuntos se codifican como vectores binarios, HashGNN requiere una representación de nodos binarios. Para comprender cómo se pueden incrustar nodos de un grafo general, se requieren varias técnicas. Echemos un vistazo.
MinHashing
Antes que nada, hablemos de MinHashing. MinHashing es una técnica de hash sensible a la localidad para aproximar la similitud de Jaccard de dos conjuntos. La similitud de Jaccard mide la superposición (intersección) de dos conjuntos dividiendo el tamaño de la intersección por el número de elementos únicos presentes (unión) en los dos conjuntos. Se define en conjuntos, que se codifican como vectores binarios: A cada elemento en el universo (el conjunto de todos los elementos) se le asigna un índice de fila único. Si un conjunto en particular contiene un elemento, esto se representa como el valor 1 en la fila respectiva del vector del conjunto. El algoritmo de MinHashing hace hash de forma independiente el vector binario de cada conjunto y utiliza K funciones de hash para generar una firma de K dimensiones para él. La explicación intuitiva de MinHashing es seleccionar aleatoriamente un elemento distinto de cero K veces, eligiendo aquel con el valor de hash más pequeño. Esto dará como resultado el vector de firma para el conjunto de entrada. Lo interesante es que si hacemos esto para dos conjuntos sin compararlos, se hashearán a la misma firma con la probabilidad de su similitud de Jaccard (si K es lo suficientemente grande). En otras palabras: La probabilidad converge hacia la similitud de Jaccard.
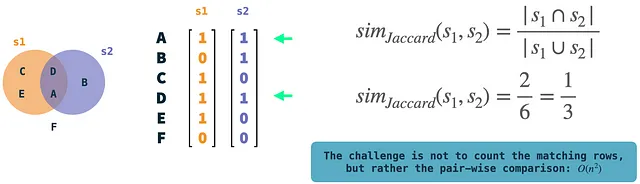
En la ilustración: los conjuntos de ejemplo s1 y s2 se representan como vectores binarios. Podemos calcular fácilmente la similitud de Jaccard comparando los dos y contando las filas donde ambos vectores tienen un 1. Estas son operaciones bastante simples, pero la complejidad radica en la comparación par a par de vectores si tenemos muchos vectores.
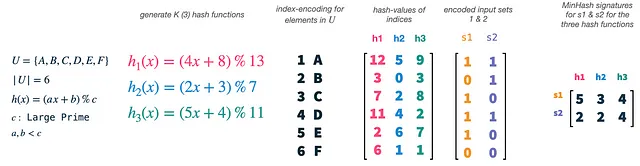
Nuestro universo U tiene un tamaño de 6 y elegimos K (el número de funciones hash) como 3. Podemos generar fácilmente nuevas funciones hash utilizando una fórmula simple y límites para a, b y c. Ahora, lo que realmente hacemos es hacer hash de los índices de nuestros vectores (1-6), cada uno relacionado con un solo elemento de nuestro universo, con cada una de nuestras funciones hash. Esto nos dará 3 permutaciones aleatorias de los índices y, por lo tanto, de los elementos en nuestro universo. Posteriormente, podemos tomar nuestros vectores de conjunto s1 y s2 y usarlos como máscaras en nuestras características permutadas. Para cada permutación y vector de conjunto, seleccionamos el índice del valor de hash más pequeño, que está presente en el conjunto. Esto nos dará dos vectores tridimensionales, uno para cada conjunto, que se llama la firma MinHash del conjunto.
MinHashing simplemente selecciona características aleatorias de los conjuntos de entrada, y necesitamos las funciones hash solo como un medio para reproducir esta aleatoriedad de manera igual en todos los conjuntos de entrada. Tenemos que usar el mismo conjunto de funciones hash en todos los vectores, para que los valores de firma de dos conjuntos de entrada colisionen si ambos tienen el elemento seleccionado presente. Los valores de firma colisionarán con la probabilidad de las similitudes de Jaccard de los conjuntos.
WLKNN (Red Neuronal de Kernel Weisfeiler-Lehman)
HashGNN utiliza un esquema de paso de mensajes como se define en las Redes Neuronales de Kernel Weisfeiler-Lehman (WLKNN) para capturar la estructura de grafo de alto orden y las propiedades de los nodos. Define la estrategia de muestreo de contexto mencionada anteriormente para HashGNN. El WLK se ejecuta en T iteraciones. En cada iteración, genera un nuevo vector de nodo para cada nodo combinando el vector actual del nodo con los vectores de todos los vecinos directamente conectados. Por lo tanto, se considera que pasa mensajes (vectores de nodo) a lo largo de las aristas a los nodos vecinos.
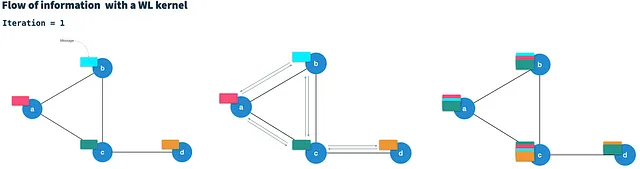
Después de T iteraciones, cada nodo contiene información de los nodos a una distancia de T saltos (de alto orden). El cálculo del nuevo vector de nodo en la iteración t básicamente agrega todos los mensajes de vecinos (de la iteración t-1) en un solo mensaje de vecino y luego lo combina con el vector de nodo de la iteración anterior. Además, el WLKNN utiliza tres redes neuronales (matrices de pesos y función de activación); (i) para el vector de vecinos agregados, (ii) para el vector de nodo y (iii) para la combinación de ambos. Es una característica notable del WLK que el cálculo en la iteración t depende únicamente del resultado de la iteración t-1. Por lo tanto, se puede considerar una cadena de Markov.
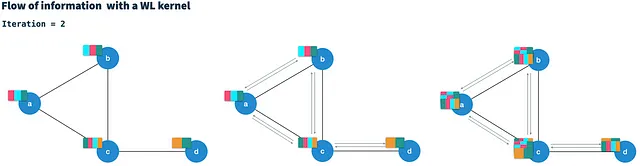
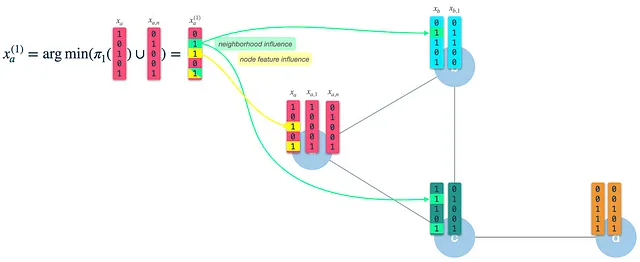
HashGNN ejemplificado
Exploraremos cómo HashGNN combina los dos enfoques para incrustar de manera eficiente los vectores de gráficos en vectores de incrustación. Al igual que WLKNN, el algoritmo HashGNN se ejecuta en T iteraciones, calculando un nuevo vector de nodo para cada nodo mediante la agregación de los vectores de vecinos y su propio vector de nodo de la iteración anterior. Sin embargo, en lugar de entrenar tres matrices de pesos, utiliza tres esquemas de hash para hash de sensibilidad local. Cada uno de los esquemas de hash consta de K funciones de hash construidas aleatoriamente para extraer K características aleatorias de un vector binario.
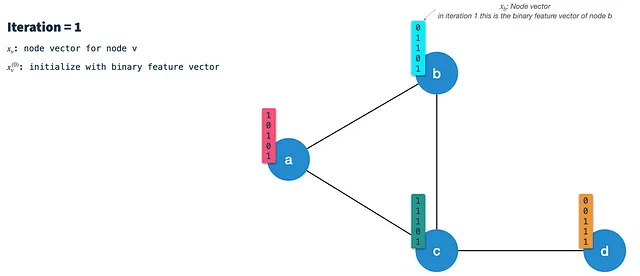
En cada iteración realizamos los siguientes pasos:
Paso 1: Calcular el vector de firma del nodo: Min-hash (seleccionar aleatoriamente K características) el vector de nodo de la iteración anterior usando el esquema de hash 3. En la primera iteración, los nodos se inicializan con sus vectores de características binarias (hablaremos sobre cómo binarizar los nodos más adelante). El vector de firma (o mensaje) resultante es el que se pasa a lo largo de los bordes a todos los vecinos. Por lo tanto, tenemos que hacer esto para todos los nodos primero en cada iteración.
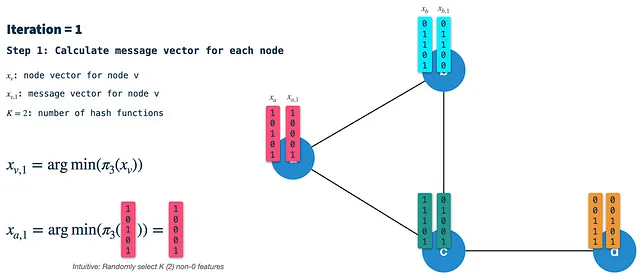
Paso 2: Construir el vector de vecinos: En cada nodo, recibiremos los vectores de firma de todos los vecinos directamente conectados y los agregaremos en un solo vector binario. Posteriormente, utilizamos el esquema de hash 2 para seleccionar K características aleatorias del vector de vecinos agregado y llamamos a este resultado el vector de vecinos.
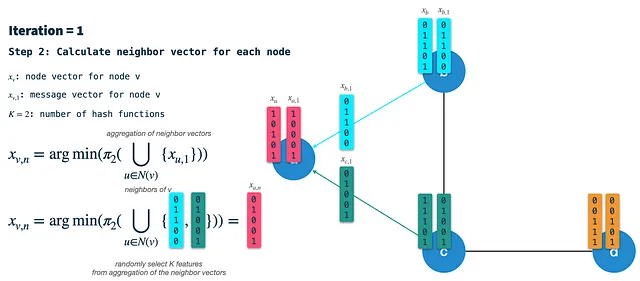
Paso 3: Combinar el vector de nodo y el vector de vecinos en un nuevo vector de nodo: Finalmente, utilizamos el esquema de hash 1 para seleccionar aleatoriamente K características del vector de nodo de la iteración anterior y combinamos el resultado con el vector de vecinos. El vector resultante es el nuevo vector de nodo que es el punto de partida para la siguiente iteración. Tenga en cuenta que esto no es lo mismo que en el paso 1: Allí, aplicamos el esquema de hash 3 al vector de nodo para construir el vector de mensaje/firma.
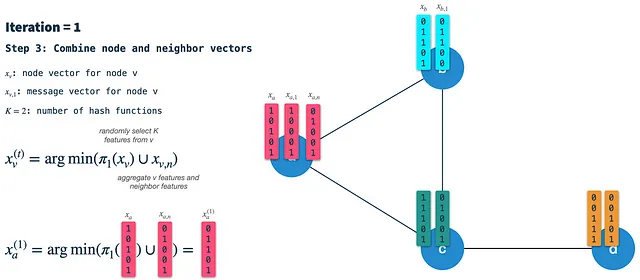
Como podemos ver, el vector de nodo resultante (nuevo) tiene influencia de sus propias características de nodo (3 y 5), así como de las características de sus vecinos (2 y 5). Después de la iteración 1, el vector de nodo capturará información de los vecinos con una distancia de 1 salto. Sin embargo, al usar esto como entrada para la iteración 2, ya estará influenciado por las características a 2 saltos de distancia.
Generalizaciones de Neo4j GDS
HashGNN fue implementado por la biblioteca Neo4j GDS (Graph Data Science) y agrega algunas generalizaciones útiles al algoritmo.
Un paso auxiliar importante en GDS es la binarización de características. MinHashing y, por lo tanto, HashGNN requieren vectores binarios como entrada. Neo4j ofrece un paso de preparación adicional para transformar vectores de nodo de valores reales en vectores de características binarias. Utilizan una técnica llamada redondeo de hiperplano. El algoritmo funciona de la siguiente manera:
Paso 1: Definir características del nodo: Definir las propiedades del nodo (de valores reales) que se utilizarán como características del nodo. Esto se hace utilizando el parámetro featureProperties. Llamaremos a esto el vector de entrada del nodo f.
Paso 2: Construir clasificadores binarios aleatorios: Definir un hiperplano para cada dimensión objetivo. El número de dimensiones resultantes se controla mediante el parámetro dimensions. Un hiperplano es un plano de alta dimensionalidad y, siempre que resida en el origen, puede describirse únicamente por su vector normal n. El vector n es ortogonal a la superficie del plano y, por lo tanto, describe su orientación. En nuestro caso, el vector n debe tener la misma dimensionalidad que los vectores de entrada de nodo (dim(f) = dim(n)). Para construir un hiperplano, simplemente extraemos dim(f) veces de una distribución gaussiana.
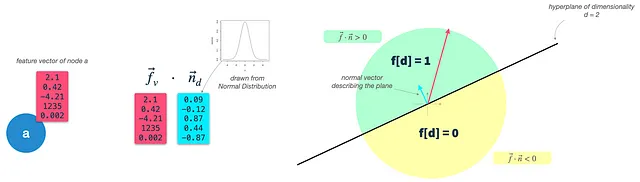
Paso 3: Clasificar vectores de nodo: Calcular el producto escalar del vector de entrada del nodo y cada vector de hiperplano, lo que produce el ángulo entre el hiperplano y el vector de entrada. Utilizando un parámetro threshold, podemos decidir si el vector de entrada está por encima (1) o por debajo (0) del hiperplano y asignar el valor respectivo al vector de características binarias resultante. Esto es exactamente lo que también sucede en una clasificación binaria, con la única diferencia de que no optimizamos iterativamente nuestro hiperplano, sino que utilizamos clasificadores gaussiano aleatorios.
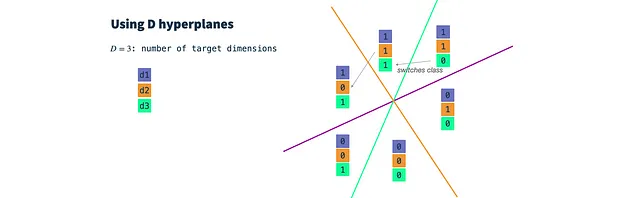
En esencia, dibujamos un clasificador gaussiano aleatorio para cada dimensión objetivo y establecemos un parámetro de umbral. Luego, clasificamos nuestros vectores de entrada para cada dimensión objetivo y obtenemos un vector binario de d dimensiones que utilizamos como entrada para HashGNN.
Conclusión
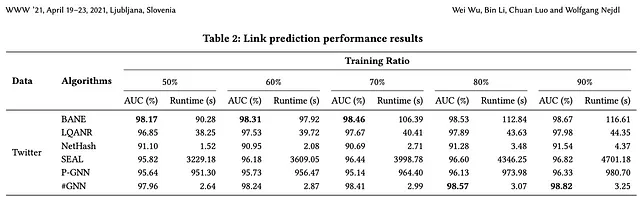
HashGNN utiliza hashing sensible a la localidad para incrustar vectores de nodo en un espacio de incrustación. Al utilizar esta técnica, evita el entrenamiento iterativo computacionalmente intensivo de una Red Neuronal (u otra optimización), así como las comparaciones directas de nodos. Los autores del artículo informan de un tiempo de ejecución de 2 a 4 órdenes de magnitud más rápido que los algoritmos basados en aprendizaje como SEAL y P-GNN, mientras produce resultados altamente comparables (en algunos casos, incluso mejores) en cuanto a precisión.
HashGNN está implementado en Neo4j GDS (Graph Data Science Library) y, por lo tanto, se puede utilizar directamente en tu grafo de Neo4j. En el próximo artículo, entraré en detalles prácticos sobre cómo utilizarlo y qué tener en cuenta.
Gracias por pasar y nos vemos la próxima vez. 🚀
Referencias
- Artículo original: Hashing-Accelerated Graph Neural Networks for Link Prediction
- Documentación de Neo4j GDS: HashGNN
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Tendencias principales de IA en marketing para observar en 2023
- Mejores Servidores Proxy 2023
- Clave maestra para la separación de fuentes de audio Presentamos AudioSep para separar cualquier cosa que describas
- 5 Cosas que Necesitas Saber al Construir Aplicaciones de Aprendizaje Automático
- Investigadores de la Universidad de Boston lanzan la familia Platypus de LLMs afinados para lograr un refinamiento económico, rápido y potente de los LLMs base.
- IBM y NASA se unen para crear Earth Science GPT Descifrando los misterios de nuestro planeta
- Reconocimiento del lenguaje hablado en Mozilla Common Voice Transformaciones de audio.





