¡Hablemos de sesgos en el aprendizaje automático! Boletín de Ética y Sociedad #2
'¡Hablemos de sesgos en el aprendizaje automático! Boletín de Ética y Sociedad #2'
El sesgo en el aprendizaje automático es omnipresente y complejo; de hecho, es tan complejo que ninguna intervención técnica única es probable que aborde de manera significativa los problemas que genera. Los modelos de aprendizaje automático, como sistemas sociotécnicos, amplifican las tendencias sociales que pueden exacerbar las desigualdades y los sesgos perjudiciales de maneras que dependen del contexto de implementación y están en constante evolución.
Esto significa que desarrollar sistemas de aprendizaje automático con cuidado requiere vigilancia y responder a los comentarios de esos contextos de implementación, lo cual podemos facilitar compartiendo lecciones entre contextos y desarrollando herramientas para analizar los signos de sesgo en cada nivel del desarrollo del aprendizaje automático.
Esta publicación de blog de los habituales de Ética y Sociedad en @🤗 comparte algunas de las lecciones que hemos aprendido junto con las herramientas que hemos desarrollado para apoyarnos a nosotros mismos y a otros en los esfuerzos de nuestra comunidad para abordar mejor el sesgo en el aprendizaje automático. La primera parte es una reflexión más amplia sobre el sesgo y su contexto. Si ya lo has leído y vuelves específicamente por las herramientas, ¡siéntete libre de saltar a la sección de conjuntos de datos o modelos!
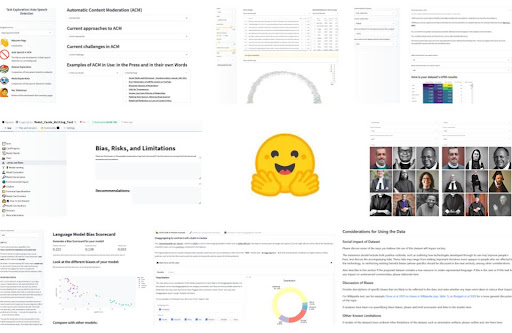 Selección de herramientas desarrolladas por miembros del equipo 🤗 para abordar el sesgo en el aprendizaje automático
Selección de herramientas desarrolladas por miembros del equipo 🤗 para abordar el sesgo en el aprendizaje automático
- Segmentación de imágenes sin entrenamiento previo con CLIPSeg
- Introducción al Aprendizaje de Máquina en Grafos
- ¿Qué hace útil a un agente de diálogo?
Tabla de contenidos:
- Sobre los sesgos en el aprendizaje automático
- Sesgo en máquinas: de los sistemas de aprendizaje automático a los riesgos
- Colocando el sesgo en contexto
- Herramientas y recomendaciones
- Abordar el sesgo en todo el desarrollo del aprendizaje automático
- Definición de tarea
- Curación de conjuntos de datos
- Entrenamiento del modelo
- Visión general de las herramientas de sesgo de 🤗
- Abordar el sesgo en todo el desarrollo del aprendizaje automático
Sesgo en máquinas: de los sistemas de aprendizaje automático a los riesgos personales y sociales
Los sistemas de aprendizaje automático nos permiten automatizar tareas complejas a una escala nunca antes vista, ya que se implementan en más sectores y casos de uso. Cuando la tecnología funciona en su mejor momento, puede ayudar a suavizar las interacciones entre las personas y los sistemas técnicos, eliminar la necesidad de trabajos altamente repetitivos o desbloquear nuevas formas de procesar información para respaldar la investigación.
Estos mismos sistemas también tienden a reproducir comportamientos discriminatorios y abusivos representados en sus datos de entrenamiento, especialmente cuando los datos codifican comportamientos humanos. La tecnología entonces tiene el potencial de empeorar significativamente estos problemas. La automatización y la implementación a gran escala pueden, de hecho:
- inmovilizar comportamientos en el tiempo y obstaculizar el progreso social para que se refleje en la tecnología,
- propagar comportamientos perjudiciales más allá del contexto de los datos de entrenamiento originales,
- amplificar las desigualdades al enfocarse demasiado en asociaciones estereotípicas al hacer predicciones,
- eliminar posibilidades de recurso al ocultar los sesgos dentro de sistemas “caja negra”.
Con el fin de comprender y abordar mejor estos riesgos, los investigadores y desarrolladores de aprendizaje automático han comenzado a estudiar el sesgo en máquinas o el sesgo algorítmico, mecanismos que podrían llevar a sistemas a, por ejemplo, codificar estereotipos o asociaciones negativas o tener desempeño dispar para diferentes grupos de población en su contexto de implementación.
Estos problemas son profundamente personales para muchos de nosotros, investigadores y desarrolladores de aprendizaje automático en Hugging Face y en la comunidad más amplia de aprendizaje automático. Hugging Face es una empresa internacional, muchos de nosotros existimos entre países y culturas. Es difícil expresar completamente nuestra sensación de urgencia cuando vemos que la tecnología en la que trabajamos se desarrolla sin suficiente preocupación por proteger a personas como nosotros; especialmente cuando estos sistemas llevan a arrestos discriminatorios injustos o a una angustia financiera indebida y se venden cada vez más a servicios de inmigración y aplicación de la ley en todo el mundo. De manera similar, ver nuestras identidades suprimidas rutinariamente en conjuntos de datos de entrenamiento o subrepresentadas en los resultados de sistemas de “IA generativa” conecta estas preocupaciones con nuestras experiencias diarias de vida de manera simultáneamente iluminadora y agotadora.
Si bien nuestras propias experiencias no se acercan a cubrir las innumerables formas en que la discriminación mediada por el aprendizaje automático puede perjudicar desproporcionadamente a las personas cuyas experiencias difieren de las nuestras, proporcionan un punto de entrada para considerar los compromisos inherentes a la tecnología. Trabajamos en estos sistemas porque creemos firmemente en el potencial del aprendizaje automático: creemos que puede brillar como una herramienta valiosa siempre que se desarrolle con cuidado y se cuente con la opinión de las personas en su contexto de implementación, en lugar de ser un remedio universal. En particular, permitir este cuidado requiere desarrollar una mejor comprensión de los mecanismos del sesgo en máquinas en todo el proceso de desarrollo del aprendizaje automático y desarrollar herramientas que apoyen a las personas con todos los niveles de conocimiento técnico de estos sistemas para participar en las conversaciones necesarias sobre cómo se distribuyen sus beneficios y perjuicios.
La presente publicación del blog de los colaboradores regulares de Hugging Face Ethics and Society proporciona una visión general de cómo hemos trabajado, estamos trabajando o recomendamos a los usuarios del ecosistema de bibliotecas de HF que trabajen para abordar el sesgo en las diversas etapas del proceso de desarrollo de ML, y las herramientas que desarrollamos para apoyar este proceso. Esperamos que lo encuentres como un recurso útil para orientar consideraciones concretas sobre el impacto social de tu trabajo y puedas aprovechar las herramientas mencionadas aquí para ayudar a mitigar estos problemas cuando surjan.
Poner el sesgo en contexto
El primer y quizás el concepto más importante a considerar cuando se trata de sesgo de las máquinas es el contexto. En su trabajo fundamental sobre sesgo en NLP, Su Lin Blodgett et al. señalan que: “[L]a mayoría de los [trabajos académicos sobre sesgo de las máquinas] no se comprometen críticamente con lo que constituye”sesgo” en primer lugar”, incluyendo la construcción de su trabajo sobre “supuestos no declarados sobre qué tipos de comportamientos del sistema son perjudiciales, de qué manera, para quién y por qué”.
Esto puede no ser una gran sorpresa dada la atención de la comunidad de investigación de ML en el valor de la “generalización” -la motivación más citada para el trabajo en el campo después del “rendimiento”. Sin embargo, si bien las herramientas de evaluación de sesgos que se aplican a una amplia gama de configuraciones son valiosas para permitir un análisis más amplio de las tendencias comunes en los comportamientos del modelo, su capacidad para dirigirse a los mecanismos que llevan a la discriminación en casos de uso concretos es inherentemente limitada. Utilizarlas para orientar decisiones específicas dentro del ciclo de desarrollo de ML generalmente requiere un paso adicional o dos para tener en cuenta el contexto de uso específico del sistema y las personas afectadas.
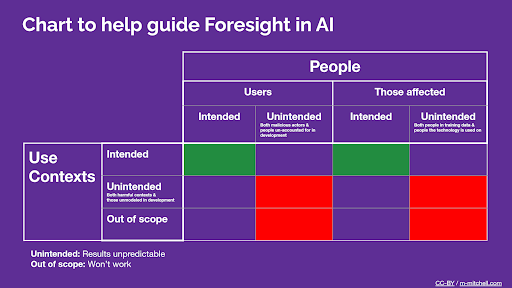 Extracto sobre consideraciones del contexto de uso y las personas de la Guía de la Tarjeta de Modelo
Extracto sobre consideraciones del contexto de uso y las personas de la Guía de la Tarjeta de Modelo
Ahora profundicemos en el problema de vincular los sesgos en los artefactos de ML autónomos/sin contexto con daños específicos. Puede ser útil pensar en los sesgos de las máquinas como factores de riesgo para daños basados en la discriminación. Tomemos como ejemplo un modelo de texto a imagen que sobre-representa los tonos de piel claros cuando se le solicita crear una imagen de una persona en un entorno profesional, pero produce tonos de piel más oscuros cuando las indicaciones mencionan la criminalidad. Estas tendencias serían lo que llamamos sesgos de las máquinas a nivel del modelo. Ahora pensemos en algunos sistemas que utilizan dicho modelo de texto a imagen:
- El modelo se integra en un servicio de creación de sitios web (por ejemplo, SquareSpace, Wix) para ayudar a los usuarios a generar fondos para sus páginas. El modelo desactiva explícitamente las imágenes de personas en el fondo generado.
- En este caso, el “factor de riesgo” del sesgo de la máquina no conduce a daños por discriminación porque el enfoque del sesgo (imágenes de personas) está ausente del caso de uso.
- No se requieren estrategias adicionales de mitigación de riesgos para los sesgos de las máquinas, aunque los desarrolladores deben estar al tanto de las discusiones en curso sobre la legalidad de integrar sistemas entrenados en datos raspados en sistemas comerciales.
- El modelo se integra en un sitio web de imágenes de stock para proporcionar a los usuarios imágenes sintéticas de personas (por ejemplo, en entornos profesionales) que pueden usar con menos preocupaciones de privacidad, por ejemplo, como ilustraciones para artículos de Wikipedia.
- En este caso, el sesgo de las máquinas actúa para afianzar y amplificar los sesgos sociales existentes. Refuerza estereotipos sobre las personas (“los CEOs son todos hombres blancos”) que luego retroalimentan sistemas sociales complejos donde un mayor sesgo conduce a una mayor discriminación de muchas maneras diferentes (como reforzar el sesgo implícito en el lugar de trabajo).
- Las estrategias de mitigación pueden incluir educar a los usuarios de imágenes de stock sobre estos sesgos, o el sitio web de imágenes de stock puede seleccionar imágenes generadas para proponer intencionalmente un conjunto de representaciones más diversas.
- El modelo se integra en un software de “artista de bocetos virtual” comercializado a departamentos de policía que lo utilizarán para generar imágenes de sospechosos basadas en testimonios verbales.
- En este caso, los sesgos de las máquinas causan directamente discriminación al dirigir sistemáticamente a los departamentos de policía a personas de piel más oscura, poniéndolas en mayor riesgo de daño, incluyendo lesiones físicas y encarcelamiento ilegal.
- En casos como este, puede no haber nivel de mitigación de sesgos que haga que el riesgo sea aceptable. En particular, un caso de uso como este estaría estrechamente relacionado con el reconocimiento facial en el contexto de la aplicación de la ley, donde problemas de sesgo similares han llevado a varias entidades comerciales y legislaturas a adoptar moratorias que suspenden o prohíben su uso en general.
Entonces, ¿quién es responsable de los sesgos de las máquinas en ML? Estos tres casos ilustran una de las razones por las cuales las discusiones sobre la responsabilidad de los desarrolladores de ML para abordar el sesgo pueden volverse tan complicadas: dependiendo de las decisiones tomadas en otros puntos del proceso de desarrollo del sistema de ML por otras personas, los sesgos en un conjunto de datos o modelo de ML pueden estar en cualquier lugar entre ser irrelevantes para las configuraciones de la aplicación y llevar directamente a graves daños. Sin embargo, en todos estos casos, los sesgos más fuertes en el modelo/conjunto de datos aumentan el riesgo de resultados negativos. La Unión Europea ha comenzado a desarrollar marcos que abordan este fenómeno en los esfuerzos regulatorios recientes: en resumen, una empresa que implementa un sistema de IA basado en un modelo mediblemente sesgado es responsable de los daños causados por el sistema.
Conceptualizar el sesgo como un factor de riesgo nos permite comprender mejor la responsabilidad compartida de los sesgos de las máquinas entre los desarrolladores en todas las etapas. El sesgo nunca puede eliminarse por completo, en parte porque las definiciones de los sesgos sociales y las dinámicas de poder que los vinculan a la discriminación varían ampliamente según los contextos sociales. Sin embargo:
- Cada etapa del proceso de desarrollo, desde la especificación de tareas, la curación de conjuntos de datos y el entrenamiento de modelos, hasta la integración del modelo y la implementación del sistema, puede tomar medidas para minimizar los aspectos del sesgo de las máquinas **que dependen directamente de sus elecciones** y decisiones técnicas, y
- La comunicación clara y el flujo de información entre las diversas etapas de desarrollo de ML pueden marcar la diferencia entre tomar decisiones que se basen unas sobre otras para atenuar el potencial negativo del sesgo (enfoque múltiple para la mitigación del sesgo, como en el escenario de implementación 1 anterior) versus tomar decisiones que aumenten este potencial negativo y aumenten el riesgo de daño (como en el escenario de implementación 3).
En la siguiente sección, revisaremos estas diversas etapas junto con algunas de las herramientas que pueden ayudarnos a abordar el sesgo de las máquinas en cada una de ellas.
Abordar el sesgo durante el ciclo de desarrollo de ML
¿Listos para algunos consejos prácticos? Aquí vamos 🤗
No hay una única forma de desarrollar sistemas de ML; qué pasos ocurren en qué orden depende de varios factores, incluido el entorno de desarrollo (universidad, gran empresa, startup, organización de base, etc.), la modalidad (texto, datos tabulares, imágenes, etc.) y la preeminencia o escasez de recursos de ML disponibles públicamente. Sin embargo, podemos identificar tres etapas comunes de particular interés para abordar el sesgo. Estas son la definición de tareas, la curación de datos y el entrenamiento de modelos. Veamos cómo puede diferir el manejo del sesgo en estas diversas etapas.
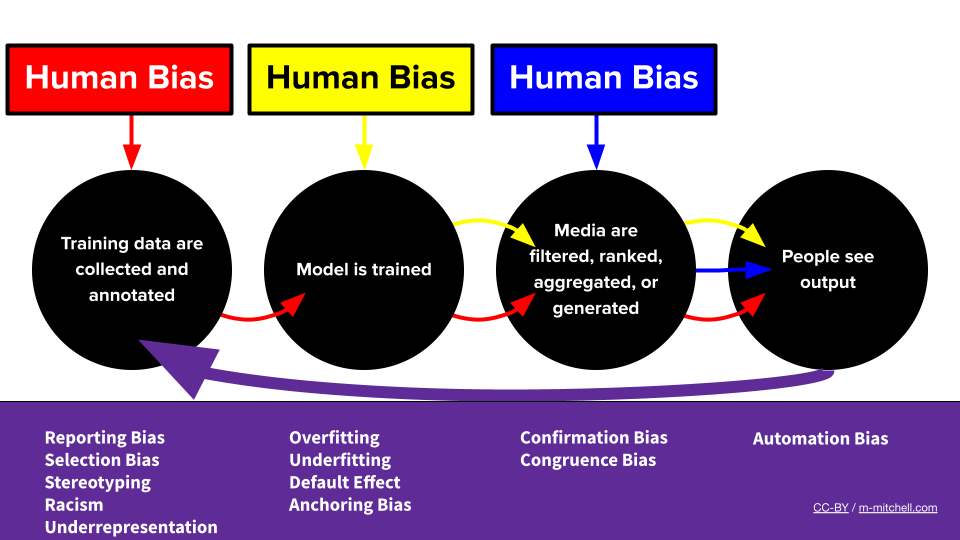 El pipeline de ML de sesgo por Meg
El pipeline de ML de sesgo por Meg
Estoy definiendo la tarea de mi sistema de ML, ¿cómo puedo abordar el sesgo?
Si y en qué medida el sesgo en el sistema afecta concretamente a las personas depende en última instancia de para qué se utiliza el sistema. Como tal, el primer lugar en el que los desarrolladores pueden trabajar para mitigar el sesgo es al decidir cómo se ajusta ML en su sistema, por ejemplo, al decidir qué objetivo de optimización utilizará.
Por ejemplo, volvamos a uno de los primeros casos ampliamente publicitados de un sistema de aprendizaje automático utilizado en producción para la recomendación algorítmica de contenido. De 2006 a 2009, Netflix llevó a cabo el Netflix Prize, una competencia con un premio en efectivo de 1 millón de dólares que desafió a equipos de todo el mundo a desarrollar sistemas de ML para predecir con precisión la calificación de un usuario para una nueva película en función de sus calificaciones anteriores. La presentación ganadora mejoró el RMSE (error cuadrático medio) de las predicciones en pares usuario-película no vistos en más del 10% en comparación con el algoritmo propio de Netflix, lo que significa que mejoró mucho en predecir cómo los usuarios calificarían una nueva película en función de su historial. Este enfoque abrió la puerta a gran parte de la recomendación de contenido algorítmico moderno al hacer que el papel de ML en modelar las preferencias de los usuarios en los sistemas de recomendación sea de conocimiento público.
Entonces, ¿qué tiene que ver esto con el sesgo? ¿No parece un buen servicio mostrar a las personas contenido que es probable que disfruten en una plataforma de contenido? Bueno, resulta que mostrar a las personas más ejemplos de lo que les ha gustado en el pasado termina reduciendo la diversidad de los medios que consumen . No solo hace que los usuarios estén menos satisfechos a largo plazo , sino que también significa que cualquier sesgo o estereotipo capturado por los modelos iniciales, como al modelar las preferencias de los usuarios afroamericanos o dinámicas que desfavorecen sistemáticamente a algunos artistas, es probable que se refuercen si el modelo se entrena aún más en interacciones de usuario mediadas por ML en curso. Esto refleja dos de los tipos de preocupaciones relacionadas con el sesgo que hemos mencionado anteriormente: el objetivo de entrenamiento actúa como un factor de riesgo para los daños relacionados con el sesgo, ya que hace que los sesgos preexistentes sean mucho más propensos a aparecer en las predicciones, y la formulación de la tarea tiene el efecto de afianzar y exacerbando los sesgos pasados.
Una estrategia prometedora de mitigación del sesgo en esta etapa ha sido reformular la tarea para modelar explícitamente tanto el compromiso como la diversidad al aplicar ML a la recomendación algorítmica de contenido. ¡Es probable que los usuarios obtengan más satisfacción a largo plazo y se reduzca el riesgo de exacerbar los sesgos mencionados anteriormente!
Este ejemplo sirve para ilustrar que el impacto de los sesgos de las máquinas en un producto respaldado por ML no depende solo de dónde decidamos aprovechar ML, sino también de cómo se integren las técnicas de ML en el sistema técnico más amplio y con qué objetivo. Cuando investigamos por primera vez cómo ML puede adaptarse a un producto o caso de uso en el que estamos interesados, recomendamos analizar los modos de falla del sistema desde la perspectiva del sesgo antes de sumergirse en los modelos o conjuntos de datos disponibles: ¿qué comportamientos de los sistemas existentes en el espacio serán particularmente perjudiciales o más propensos a ocurrir si el sesgo se ve exacerbado por las predicciones de ML?
Construimos una herramienta para guiar a los usuarios a través de estas preguntas en otro caso de gestión de contenido algorítmico: detección de discurso de odio en moderación automática de contenido. Encontramos, por ejemplo, que examinar noticias y artículos científicos que no se enfocaban particularmente en la parte de aprendizaje automático de la tecnología ya era una excelente manera de tener una idea de dónde ya existe sesgo. ¡Definitivamente echa un vistazo para ver un ejemplo de cómo los modelos y conjuntos de datos se ajustan al contexto de implementación y cómo pueden relacionarse con los daños relacionados con el sesgo conocidos!
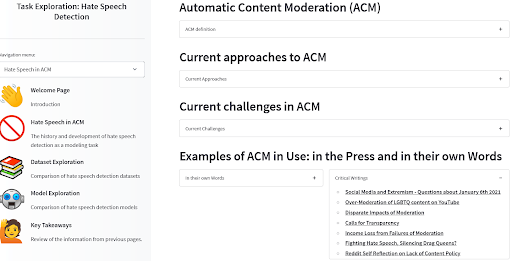 Herramienta de exploración de tareas ACM por Angie, Amandalynne y Yacine
Herramienta de exploración de tareas ACM por Angie, Amandalynne y Yacine
Definición de tarea: recomendaciones
Hay tantas formas en las que la definición y la implementación de la tarea de aprendizaje automático pueden afectar el riesgo de daños relacionados con el sesgo como aplicaciones para sistemas de aprendizaje automático. Como en los ejemplos anteriores, algunos pasos comunes que pueden ayudar a decidir si y cómo aplicar el aprendizaje automático de manera que se minimice el riesgo de sesgo relacionado incluyen:
- Investigar:
- Informes de sesgo en el campo previo a la implementación del aprendizaje automático
- Categorías demográficas en riesgo para su caso de uso específico
- Examinar:
- El impacto de su objetivo de optimización en la reafirmación de sesgos
- Objetivos alternativos que favorezcan la diversidad y tengan impactos positivos a largo plazo
Estoy seleccionando/unificando un conjunto de datos para mi sistema de aprendizaje automático, ¿cómo puedo abordar el sesgo?
Aunque los conjuntos de datos de entrenamiento no son la única fuente de sesgo en el ciclo de desarrollo de aprendizaje automático, desempeñan un papel importante. ¿Tu conjunto de datos asocia de manera desproporcionada biografías de mujeres con eventos de la vida, pero las de los hombres con logros? ¡Esos estereotipos probablemente se reflejarán en tu sistema de aprendizaje automático completo! ¿Tu conjunto de datos de reconocimiento de voz solo incluye acentos específicos? ¡No es una buena señal para la inclusividad de la tecnología que construyes en términos de desempeño dispar! Ya sea que estés seleccionando un conjunto de datos para aplicaciones de aprendizaje automático o eligiendo un conjunto de datos para entrenar un modelo de aprendizaje automático, descubrir, mitigar y comunicar en qué medida los datos exhiben estos fenómenos son pasos necesarios para reducir los riesgos relacionados con el sesgo.
Por lo general, puedes tener una buena idea de los sesgos probables en un conjunto de datos reflexionando sobre su origen, las personas representadas en los datos y el proceso de curación. Se han propuesto varios marcos para esta reflexión y documentación, como las Declaraciones de Datos para Procesamiento de Lenguaje Natural o las Hojas de Datos para Conjuntos de Datos. El Hugging Face Hub incluye una plantilla de Tarjeta de Conjunto de Datos y una guía inspirada en estos trabajos; la sección sobre consideraciones para usar los datos suele ser un buen lugar para buscar información sobre sesgos destacados si estás explorando conjuntos de datos, o para escribir un párrafo compartiendo tus conocimientos sobre el tema si estás compartiendo uno nuevo. Y si buscas más inspiración sobre qué incluir allí, echa un vistazo a estas secciones escritas por usuarios de Hub en la organización BigLAM para conjuntos de datos históricos de procedimientos legales, clasificación de imágenes y periódicos.
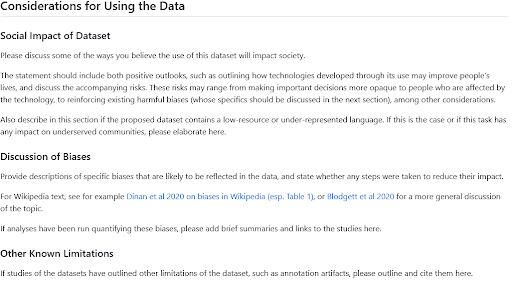 Guía de Tarjeta de Conjunto de Datos de HF para las secciones de Impacto Social y Sesgo
Guía de Tarjeta de Conjunto de Datos de HF para las secciones de Impacto Social y Sesgo
Aunque describir el origen y el contexto de un conjunto de datos siempre es un buen punto de partida para comprender los sesgos presentes, medir cuantitativamente fenómenos que codifican esos sesgos también puede ser de gran ayuda. Si estás eligiendo entre dos conjuntos de datos diferentes para una tarea determinada o eligiendo entre dos modelos de aprendizaje automático entrenados con conjuntos de datos diferentes, saber cuál representa mejor la composición demográfica de la base de usuarios de tu sistema de aprendizaje automático puede ayudarte a tomar una decisión informada para minimizar los riesgos relacionados con el sesgo. Si estás unificando un conjunto de datos de manera iterativa mediante la filtración de puntos de datos de una fuente o la selección de nuevas fuentes de datos para agregar, medir cómo estas elecciones afectan la diversidad y los sesgos presentes en el conjunto de datos general puede hacer que sea más seguro usarlo en general.
Recientemente hemos lanzado dos herramientas que puedes utilizar para medir tus datos desde una perspectiva informada sobre sesgo. La biblioteca disaggregators🤗 proporciona utilidades para cuantificar la composición de tu conjunto de datos, utilizando metadatos o aprovechando modelos para inferir propiedades de los puntos de datos. Esto puede ser particularmente útil para minimizar los riesgos de daños relacionados con la representación del sesgo o el desempeño dispar de los modelos entrenados. ¡Mira la demostración para ver cómo se aplica a los conjuntos de datos LAION, MedMCQA y The Stack!
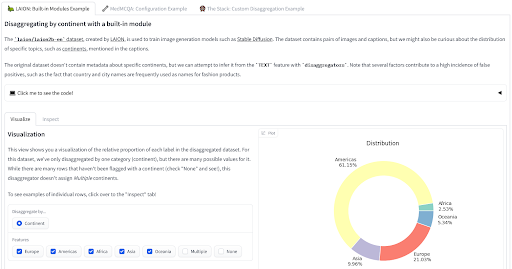 Herramienta de Desagregación por Nima
Herramienta de Desagregación por Nima
Una vez que tenga algunas estadísticas útiles sobre la composición de su conjunto de datos, también querrá analizar las asociaciones entre las características de sus elementos de datos, especialmente las asociaciones que puedan codificar estereotipos negativos o degradantes. La Herramienta de Mediciones de Datos que presentamos originalmente el año pasado le permite hacer esto mediante la observación de la Información Mutual Puntual Normalizada (nPMI) entre los términos en su conjunto de datos basado en texto; especialmente las asociaciones entre pronombres de género que pueden denotar estereotipos de género. ¡Ejecútelo usted mismo o pruébelo aquí en algunos conjuntos de datos precalculados!
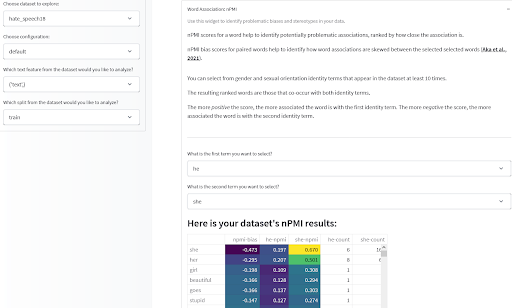 Herramienta de Mediciones de Datos por Meg, Sasha, Bibi y el equipo de Gradio
Herramienta de Mediciones de Datos por Meg, Sasha, Bibi y el equipo de Gradio
Selección/Curación de Conjuntos de Datos: recomendaciones
Estas herramientas no son soluciones completas por sí mismas, sino que están diseñadas para respaldar el examen crítico y la mejora de los conjuntos de datos desde varias perspectivas, incluida la perspectiva de sesgos y riesgos relacionados con sesgos. En general, le recomendamos que tenga en cuenta los siguientes pasos al utilizar estas y otras herramientas para mitigar los riesgos de sesgos en la etapa de curación/selección de conjuntos de datos:
- Identificar:
- Aspectos de la creación del conjunto de datos que pueden exacerbar sesgos específicos
- Categorías demográficas y variables sociales que son particularmente importantes para la tarea y el dominio del conjunto de datos
- Medir:
- La distribución demográfica en su conjunto de datos
- Estereotipos negativos preidentificados representados
- Documentar:
- Comparta lo que ha identificado y medido en su Tarjeta de Conjunto de Datos para que pueda beneficiar a otros usuarios, desarrolladores y personas afectadas de alguna manera
- Adaptar:
- Eligiendo el conjunto de datos menos propenso a causar daños relacionados con sesgos
- Mejorando iterativamente su conjunto de datos de formas que reduzcan los riesgos de sesgos
Estoy entrenando/seleccionando un modelo para mi sistema de ML, ¿cómo puedo abordar el sesgo?
Similar al paso de curación/selección de conjuntos de datos, documentar y medir fenómenos relacionados con sesgos en los modelos puede ayudar tanto a los desarrolladores de ML que seleccionan un modelo para usar tal cual o para ajustar finamente, como a los desarrolladores de ML que desean entrenar sus propios modelos. Para estos últimos, las medidas de fenómenos relacionados con sesgos en el modelo pueden ayudarles a aprender de lo que ha funcionado o no ha funcionado para otros modelos y servir como una señal para guiar sus propias decisiones de desarrollo.
Las tarjetas de modelo fueron propuestas originalmente por (Mitchell et al., 2019) y brindan un marco para la presentación de modelos que muestra información relevante sobre los riesgos de sesgos, incluyendo consideraciones éticas amplias, evaluación desagregada y recomendación de casos de uso. El Hugging Face Hub proporciona aún más herramientas para la documentación de modelos, con una guía de tarjetas de modelo en la documentación del Hub, y una aplicación que le permite crear fácilmente tarjetas de modelo detalladas para su nuevo modelo.
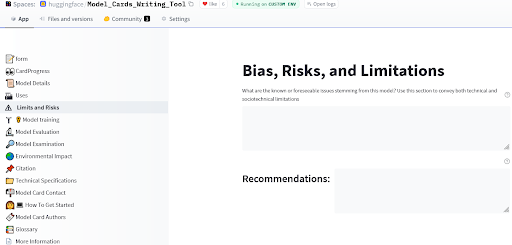 Herramienta de escritura de Tarjetas de Modelo por Ezi, Marissa y Meg
Herramienta de escritura de Tarjetas de Modelo por Ezi, Marissa y Meg
La documentación es un primer paso importante para compartir ideas generales sobre el comportamiento de un modelo, pero generalmente es estática y presenta la misma información a todos los usuarios. En muchos casos, especialmente para modelos generativos que pueden generar salidas para aproximar la distribución de sus datos de entrenamiento, podemos obtener una comprensión más contextual de los fenómenos relacionados con sesgos y estereotipos negativos al visualizar y contrastar las salidas del modelo. El acceso a las generaciones del modelo puede ayudar a los usuarios a plantear problemas interseccionales en el comportamiento del modelo correspondientes a su experiencia vivida, y evaluar hasta qué punto un modelo reproduce estereotipos de género para diferentes adjetivos. Para facilitar este proceso, hemos construido una herramienta que le permite comparar generaciones no solo en un conjunto de adjetivos y profesiones, ¡sino también entre diferentes modelos! Pruébelo para tener una idea de qué modelo puede tener menos riesgos de sesgos en su caso de uso.
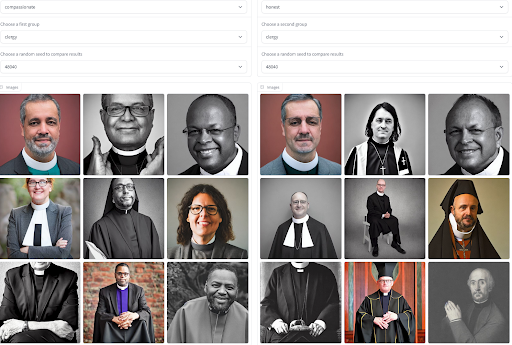 Visualización de Sesgos de Adjetivos y Ocupaciones en Generación de Imágenes por Sasha
Visualización de Sesgos de Adjetivos y Ocupaciones en Generación de Imágenes por Sasha
¡La visualización de las salidas del modelo no es solo para modelos generativos! Para modelos de clasificación, también queremos estar atentos a los daños relacionados con sesgos causados por el rendimiento desigual del modelo en diferentes grupos demográficos. Si sabe qué clases protegidas tienen más riesgo de discriminación y las tiene anotadas en un conjunto de evaluación, puede informar sobre el rendimiento desagregado en las diferentes categorías en la tarjeta de modelo, como se mencionó anteriormente, para que los usuarios puedan tomar decisiones informadas. Sin embargo, si está preocupado de no haber identificado todas las poblaciones en riesgo de daños relacionados con sesgos, o si no tiene acceso a ejemplos de prueba anotados para medir los sesgos que sospecha, ahí es donde resultan útiles las visualizaciones interactivas de dónde y cómo falla el modelo. Para ayudarlo con esto, la aplicación SEAL agrupa errores similares de su modelo y muestra algunas características comunes en cada grupo. Si desea ir más allá, incluso puede combinarlo con la biblioteca de desagregadores que presentamos en la sección de conjuntos de datos para encontrar grupos que sean indicativos de modos de falla relacionados con sesgos.
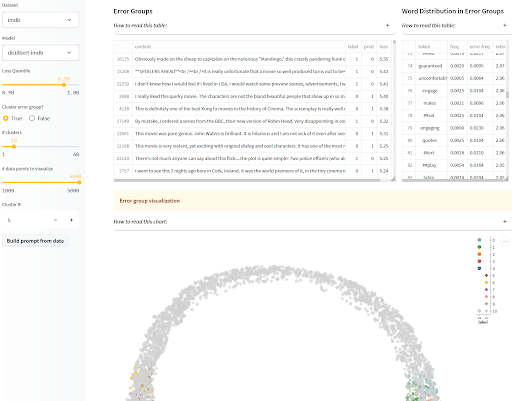 Análisis sistemático de errores y etiquetado (SEAL) por Nazneen
Análisis sistemático de errores y etiquetado (SEAL) por Nazneen
Finalmente, existen algunos puntos de referencia que pueden medir fenómenos relacionados con sesgos en los modelos. Para modelos de lenguaje, puntos de referencia como BOLD, HONEST o WinoBias proporcionan evaluaciones cuantitativas de comportamientos específicos que son indicativos de sesgos en los modelos. Si bien los puntos de referencia tienen sus limitaciones, proporcionan una visión limitada de algunos riesgos de sesgos preidentificados que pueden ayudar a describir cómo funcionan los modelos o a elegir entre diferentes modelos. ¡Puede encontrar estas evaluaciones precalculadas en una variedad de modelos de lenguaje comunes en este espacio de exploración para tener una primera idea de cómo se comparan!
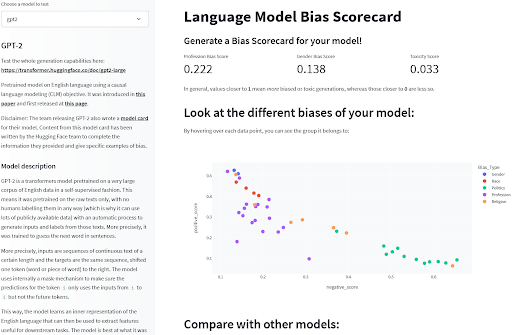 Detección de sesgos en modelos de lenguaje por Sasha
Detección de sesgos en modelos de lenguaje por Sasha
Incluso si tiene acceso a un punto de referencia para los modelos que está considerando, es posible que descubra que ejecutar evaluaciones de los modelos de lenguaje más grandes que está considerando puede ser prohibitivamente costoso o técnicamente imposible con sus propios recursos informáticos. La herramienta Evaluación en el Hub que lanzamos este año puede ayudar con eso: no solo ejecutará las evaluaciones por usted, sino que también ayudará a conectarlas con la documentación del modelo para que los resultados estén disponibles de una vez por todas, para que todos puedan ver, por ejemplo, que el tamaño aumenta mediblemente los riesgos de sesgos en modelos como OPT.
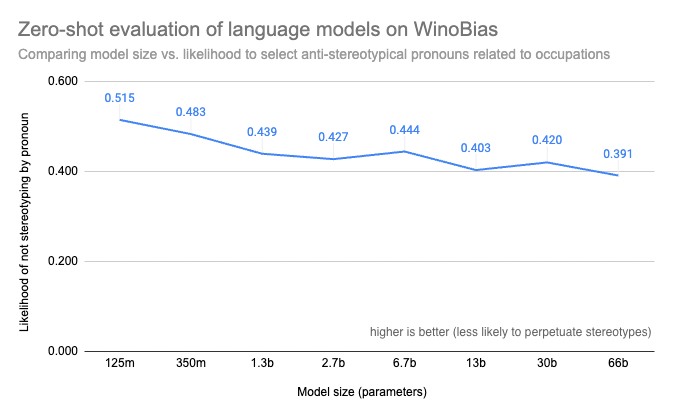 Puntuaciones WinoBias para modelos grandes calculadas con Evaluación en el Hub por Helen, Tristan, Abhishek, Lewis y Douwe
Puntuaciones WinoBias para modelos grandes calculadas con Evaluación en el Hub por Helen, Tristan, Abhishek, Lewis y Douwe
Selección/desarrollo de modelos: recomendaciones
Al igual que con los conjuntos de datos, diferentes herramientas de documentación y evaluación proporcionarán diferentes puntos de vista sobre los riesgos de sesgo en un modelo, todos los cuales tienen un papel importante en ayudar a los desarrolladores a elegir, desarrollar o comprender los sistemas de ML.
- Visualizar
- Modelo generativo: visualizar cómo las salidas del modelo pueden reflejar estereotipos
- Modelo de clasificación: visualizar los errores del modelo para identificar modos de falla que podrían conducir a un rendimiento dispar
- Evaluar
- Cuando sea posible, evaluar modelos en puntos de referencia relevantes
- Documentar
- Compartir lo que se ha aprendido de la visualización y evaluación cualitativa
- Informar el rendimiento desagregado de su modelo y los resultados en puntos de referencia de equidad aplicables
Conclusión y descripción general de las herramientas de análisis y documentación de sesgos de 🤗
A medida que aprendemos a aprovechar los sistemas de ML en más y más aplicaciones, obtener beneficios equitativos dependerá de nuestra capacidad para mitigar activamente los riesgos de daños relacionados con sesgos asociados con la tecnología. Si bien no hay una única respuesta a la pregunta de cómo se debe hacer esto de la mejor manera en cualquier entorno posible, podemos apoyarnos mutuamente en este esfuerzo compartiendo lecciones, herramientas y metodologías para mitigar y documentar esos riesgos. La presente publicación del blog describe algunas de las formas en que los miembros del equipo de Hugging Face han abordado esta cuestión de sesgo junto con las herramientas de apoyo, esperamos que les resulten útiles y los animamos a desarrollar y compartir las suyas propias.
Resumen de las herramientas vinculadas:
- Tareas:
- Explore nuestro directorio de tareas de ML para comprender qué enfoques técnicos y recursos están disponibles para elegir
- Utilice herramientas para explorar el ciclo de vida completo del desarrollo de tareas específicas
- Conjuntos de datos:
- Utilice y contribuya a las Tarjetas de Conjuntos de Datos para compartir ideas relevantes sobre sesgos en los conjuntos de datos.
- Utilice el Desagregador para buscar un posible rendimiento dispar
- Analice las medidas agregadas de su conjunto de datos, incluido el nPMI, para detectar posibles asociaciones estereotípicas
- Modelos:
- Utilice y contribuya a las Tarjetas de Modelo para compartir ideas relevantes sobre sesgos en los modelos.
- Utilice las Tarjetas de Modelo Interactivo para visualizar discrepancias de rendimiento
- Analice los errores sistemáticos del modelo y esté atento a los sesgos sociales conocidos
- Utilice Evaluar y Evaluación en el Hub para explorar sesgos en modelos de lenguaje, incluidos los modelos grandes
- Utilice un explorador de sesgos de texto a imagen para comparar sesgos en modelos de generación de imágenes
- Compare modelos de LM con la Tarjeta de Puntuación de Sesgo
¡Gracias por leer! 🤗
~ Yacine, en nombre de los habituales de Ética y Sociedad
Si desea citar esta publicación de blog, utilice lo siguiente:
@inproceedings{hf_ethics_soc_blog_2,
author = {Yacine Jernite y
Alexandra Sasha Luccioni y
Irene Solaiman y
Giada Pistilli y
Nathan Lambert y
Ezi Ozoani y
Brigitte Toussignant y
Margaret Mitchell},
title = {Boletín de Ética y Sociedad de Hugging Face 2: ¡Hablemos de Sesgos!},
booktitle = {Blog de Hugging Face},
year = {2022},
url = {https://doi.org/10.57967/hf/0214},
doi = {10.57967/hf/0214}
}We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Optimum+ONNX Runtime Entrenamiento más fácil y rápido para tus modelos de Hugging Face
- El estado de la Visión por Computadora en Hugging Face 🤗
- Presentando ⚔️ IA vs. IA ⚔️ un sistema de competencia de aprendizaje por refuerzo profundo para múltiples agentes
- Ajuste de Fine-Tuning Eficiente en Parámetros usando 🤗 PEFT
- Generación de texto a partir de imágenes sin entrenamiento previo con BLIP-2
- Hugging Face y AWS se asocian para hacer que la IA sea más accesible
- Swift 🧨Difusores – Difusión rápida y estable para Mac






