Aprendizaje de Diferencia Temporal y la importancia de la exploración Una guía ilustrada
Guía ilustrada Aprendizaje de Diferencia Temporal y exploración
Comparando métodos de RL libres de modelo y basados en modelo en un mundo de rejilla dinámica
Recientemente, los algoritmos de aprendizaje por refuerzo (RL) han recibido mucha atención al resolver problemas de investigación como el plegado de proteínas, alcanzar un nivel sobrehumano en carreras de drones, o incluso integrar retroalimentación humana en tus chatbots favoritos.
De hecho, RL ofrece soluciones útiles para una variedad de problemas de toma de decisiones secuenciales. Los métodos de aprendizaje de diferencia temporal (TD learning) son un subconjunto popular de algoritmos de RL. Los métodos de TD learning combina aspectos clave de los métodos de Monte Carlo y Programación Dinámica para acelerar el aprendizaje sin requerir un modelo perfecto de la dinámica del entorno.
En este artículo, compararemos diferentes tipos de algoritmos de TD en un Mundo de Rejilla personalizado. El diseño del experimento destacará la importancia de la exploración continua, así como las características individuales de los algoritmos probados: Q-learning, Dyna-Q y Dyna-Q+.
El esquema de este post contiene:
- 5 Mejores Certificaciones de Ciencia de Datos en Estados Unidos
- Investigación en Stanford presenta PointOdyssey un conjunto de datos sintético a gran escala para el seguimiento de puntos a largo plazo
- Google DeepMind presenta una nueva herramienta de IA que clasifica los efectos de 71 millones de mutaciones ‘missense
- Descripción del entorno
- Aprendizaje de Diferencia Temporal (TD)
- Métodos de TD libres de modelo (Q-learning) y métodos de TD basados en modelo (Dyna-Q y Dyna-Q+)
- Parámetros
- Comparaciones de rendimiento
- Conclusión
El código completo que permite reproducir los resultados y los gráficos está disponible aquí: https://github.com/RPegoud/Temporal-Difference-learning
El Entorno
El entorno que utilizaremos en este experimento es un mundo de rejilla con las siguientes características:
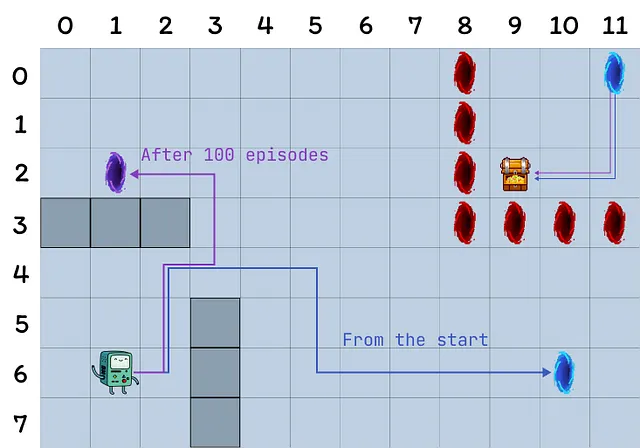
- La rejilla tiene 12 por 8 celdas.
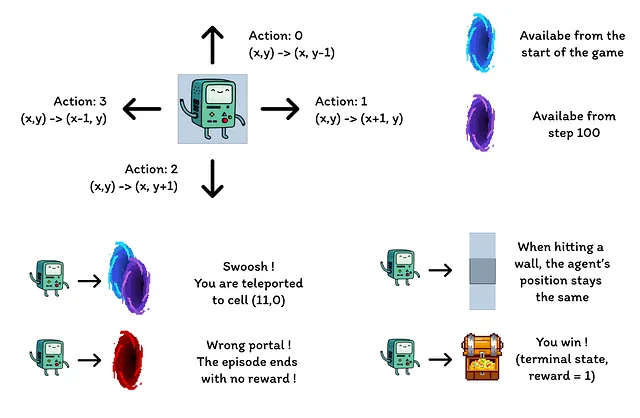
- El agente comienza en la esquina inferior izquierda de la rejilla, el objetivo es llegar al tesoro ubicado en la esquina superior derecha (un estado terminal con una recompensa de 1).
- Los portales azules están conectados, pasar a través del portal ubicado en la celda (10, 6) conduce a la celda (11, 0). El agente no puede volver a tomar el portal después de la primera transición.
- El portal morado solo aparece después de 100 episodios pero permite que el agente llegue más rápido al tesoro. Esto fomenta la exploración continua del entorno.
- Los portales rojos son trampas (estados terminales con una recompensa de 0) y terminan el episodio.
- Chocar contra una pared hace que el agente permanezca en el mismo estado.
Este experimento tiene como objetivo comparar el comportamiento de los agentes de Q-learning, Dyna-Q y Dyna-Q+ en un entorno cambiante. De hecho, después de 100 episodios, la política óptima está destinada a cambiar y el número óptimo de pasos durante un episodio exitoso disminuirá de 17 a 12.
Introducción al Aprendizaje de Diferencia Temporal:
El Aprendizaje de Diferencia Temporal es una combinación de los métodos de Monte Carlo (MC) y Programación Dinámica (DP):
- Al igual que los métodos MC, los métodos TD pueden aprender de la experiencia sin requerir un modelo de la dinámica del entorno.
- Al igual que los métodos DP, los métodos TD actualizan estimaciones después de cada paso basándose en otras estimaciones aprendidas sin esperar el resultado (esto se llama bootstrapping).
Una particularidad de los métodos TD es que actualizan su estimación de valor en cada paso, a diferencia de los métodos MC que esperan hasta el final de un episodio.
De hecho, ambos métodos tienen diferentes objetivos de actualización. Los métodos MC tienen como objetivo actualizar el retorno Gt, que solo está disponible al final de un episodio. En cambio, los métodos TD tienen como objetivo:
Donde V es una estimación de la verdadera función de valor Vπ.
Por lo tanto, los métodos TD combinan el muestreo de MC (utilizando una estimación del valor verdadero) y el bootstrapping de DP (actualizando V basado en estimaciones que se basan en más estimaciones).
La versión más simple del aprendizaje de diferencia temporal se llama TD(0) o TD de un paso, una implementación práctica de TD(0) se vería así:
![Pseudo-código para el algoritmo TD(0), reproducido de Reinforcement Learning, an introduction [4]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*YxhtNxDc985zRjMd7wPKJg.png)
Cuando se transiciona de un estado S a un nuevo estado S’, el algoritmo TD(0) calculará un valor respaldado y actualizará V(S) en consecuencia. Este valor respaldado se llama error TD, la diferencia entre la función de valor óptima V_star y nuestra estimación actual V(S):
En conclusión, los métodos TD presentan varias ventajas:
- No requieren un modelo perfecto de la dinámica del entorno p
- Se implementan de manera en línea, actualizando el objetivo después de cada paso de tiempo
- TD(0) se garantiza que convergerá para cualquier política fija π si α (la tasa de aprendizaje o tamaño del paso) sigue las condiciones de aproximación estocástica (para más detalles, consulte la página 55 “Seguimiento de un Problema No Estacionario” de [4])
Detalles de la implementación:
Las siguientes secciones exploran las principales características y el rendimiento de varios algoritmos TD en el mundo de la cuadrícula.
Se usaron los mismos parámetros para todos los modelos, por simplicidad:
- Epsilon (ε) = 0.1: probabilidad de seleccionar una acción aleatoria en las políticas ε-greedy
- Gamma (γ)= 0.9: factor de descuento aplicado a las recompensas futuras o estimaciones de valor
- Alpha (α) = 0.25: tasa de aprendizaje que restringe las actualizaciones del valor Q
- Pasos de planificación = 100: para Dyna-Q y Dyna-Q+, el número de pasos de planificación ejecutados para cada interacción directa
- Kappa (κ)= 0.001: para Dyna-Q+, el peso de las recompensas de bonificación aplicadas durante los pasos de planificación
Los rendimientos de cada algoritmo se presentan primero para una sola ejecución de 400 episodios (secciones: Aprendizaje Q, Dyna-Q, y Dyna-Q+) y luego se promedian en 100 ejecuciones de 250 episodios en la sección “Resumen y comparación de algoritmos“.
Q-learning
El primer algoritmo que implementamos aquí es el famoso Q-learning (Watkins, 1989):
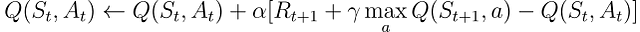
Q-learning se llama un algoritmo fuera de política ya que su objetivo es aproximar la función de valor óptimo directamente, en lugar de la función de valor de π, la política seguida por el agente.
En la práctica, Q-learning aún se basa en una política, a menudo referida como la “política de comportamiento”, para seleccionar qué pares de estado-acción se visitan y actualizan. Sin embargo, Q-learning está fuera de política porque actualiza sus valores Q en función de la mejor estimación de las recompensas futuras, independientemente de si las acciones seleccionadas siguen la política actual π.
En comparación con el pseudo-código de aprendizaje TD anterior, hay tres diferencias principales:
- Necesitamos inicializar la función Q para todos los estados y acciones, y Q(terminal) debería ser 0
- Las acciones se eligen a partir de una política basada en los valores Q (por ejemplo, la política ε-greedy con respecto a los valores Q)
- La actualización se dirige a la función de valor de acción Q en lugar de la función de valor de estado V
![Pseudo-código para el algoritmo Q-learning, reproducido de Reinforcement Learning, an introduction [4]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*l5_4S_WDALtIROP2HOhJ0w.png)
Ahora que tenemos nuestro primer algoritmo listo para probar, podemos comenzar la fase de entrenamiento. Nuestro agente navegará por el Grid World utilizando su política ε-greedy, con respecto a los valores Q. Esta política selecciona la acción con el mayor valor Q con una probabilidad de (1 – ε) y elige una acción aleatoria con una probabilidad de ε. Después de cada acción, el agente actualizará sus estimaciones de valores Q.
Podemos visualizar la evolución del valor de acción máximo estimado Q(S, a) de cada celda del Grid World utilizando un mapa de calor. Aquí, el agente juega 400 episodios. Como solo hay una actualización por episodio, la evolución de los valores Q es bastante lenta y una gran parte de los estados permanecen sin mapear:
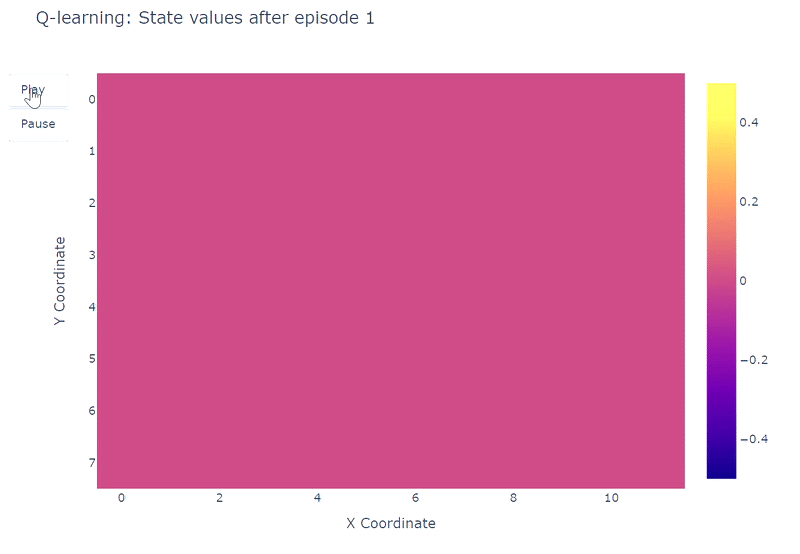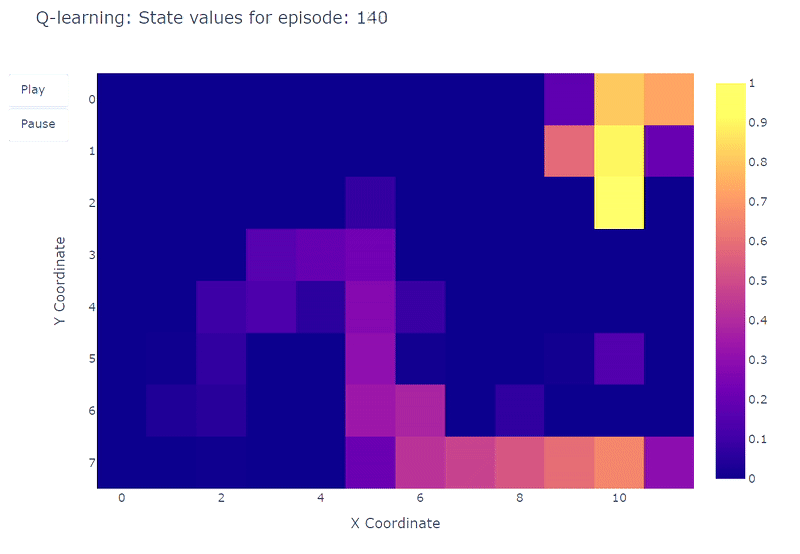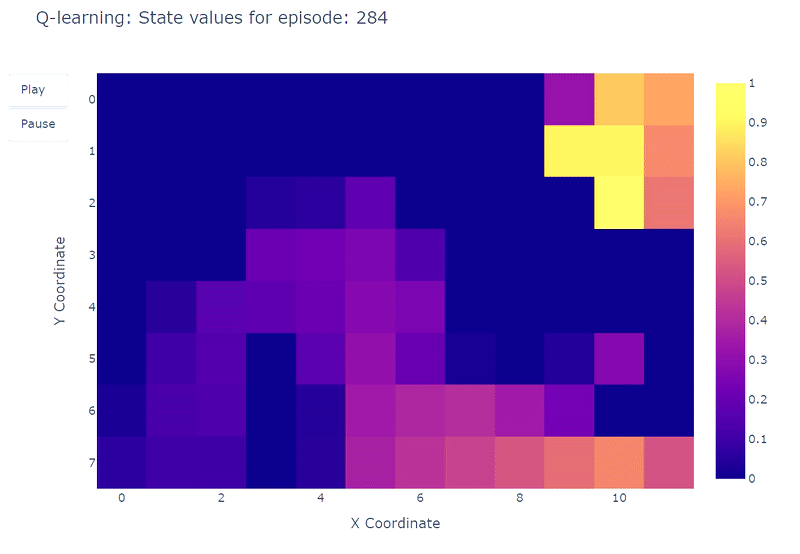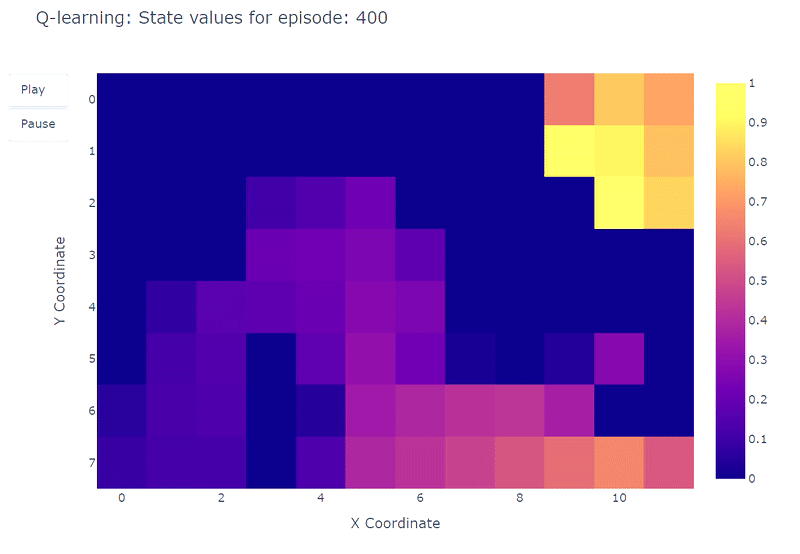
Al completar los 400 episodios, un análisis de las visitas totales a cada celda nos proporciona una estimación decente de la ruta promedio del agente. Como se muestra en el gráfico de la derecha a continuación, el agente parece haber convergido a una ruta subóptima, evitando la celda (4,4) y siguiendo consistentemente la pared inferior.
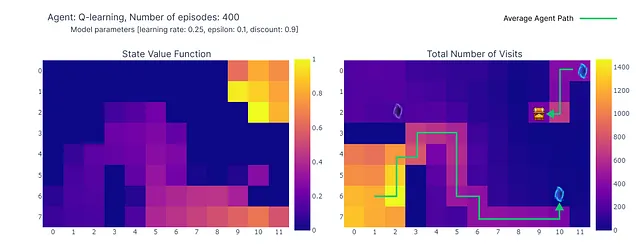
Como resultado de esta estrategia subóptima, el agente alcanza un mínimo de 21 pasos por episodio, siguiendo el camino delineado en el gráfico de “número de visitas totales”. Las variaciones en el recuento de pasos pueden atribuirse a la política ε-greedy, que introduce una probabilidad del 10% de acciones aleatorias. Dada esta política, seguir la pared inferior es una estrategia decente para limitar las posibles interrupciones causadas por acciones aleatorias.
En conclusión, el agente de Q-learning convergió a una estrategia subóptima como se mencionó anteriormente. Además, una parte del entorno permanece inexplorada por la función Q, lo que impide que el agente encuentre el nuevo camino óptimo cuando aparece el portal morado después del episodio 100.
Estas limitaciones de rendimiento se pueden atribuir al número relativamente bajo de pasos de entrenamiento (400), lo que limita las posibilidades de interacción con el entorno y la exploración inducida por la política ε-greedy.
La planificación, un componente esencial de los métodos de aprendizaje por refuerzo basados en modelos, es particularmente útil para mejorar la eficiencia de muestra y la estimación de los valores de acción. Dyna-Q y Dyna-Q+ son buenos ejemplos de algoritmos TD que incorporan pasos de planificación.
Dyna-Q
El algoritmo Dyna-Q (Q-learning dinámico) es una combinación de aprendizaje por refuerzo basado en modelos y aprendizaje TD.
Los algoritmos de aprendizaje por refuerzo basados en modelos se basan en un modelo del entorno para incorporar la planificación como su forma principal de actualizar las estimaciones de valor. En contraste, los algoritmos libres de modelo se basan en el aprendizaje directo.
“Un modelo del entorno es cualquier cosa que un agente pueda usar para predecir cómo responderá el entorno a sus acciones” – Aprendizaje por refuerzo: una introducción.
En el ámbito de este artículo, el modelo se puede ver como una aproximación de la dinámica de transición p(s’, r|s, a). Aquí, p devuelve un único par siguiente de estado y recompensa dado el par estado-acción actual.
En entornos donde p es estocástico, distinguimos entre modelos de distribución y modelos de muestra, el primero devuelve una distribución de los siguientes estados y acciones, mientras que el último devuelve un solo par, muestreado de la distribución estimada.
Los modelos son especialmente útiles para simular episodios y, por lo tanto, entrenar al agente reemplazando las interacciones del mundo real con pasos de planificación, es decir, interacciones con el entorno simulado.
Los agentes que implementan el algoritmo Dyna-Q son parte de la clase de agentes de planificación, agentes que combina el aprendizaje directo por refuerzo y el aprendizaje de modelos. Utilizan interacciones directas con el entorno para actualizar su función de valor (como en Q-learning) y también para aprender un modelo del entorno. Después de cada interacción directa, también pueden realizar pasos de planificación para actualizar su función de valor utilizando interacciones simuladas.
Un ejemplo rápido de ajedrez
Imagina jugar una buena partida de ajedrez. Después de jugar cada movimiento, la reacción de tu oponente te permite evaluar la calidad de tu movimiento. Esto es similar a recibir una recompensa positiva o negativa, que te permite “actualizar” tu estrategia. Si tu movimiento lleva a un error grave, probablemente no lo repetirías, siempre que se presente la misma configuración del tablero. Hasta ahora, esto es comparable al aprendizaje directo por refuerzo.
Ahora agreguemos planificación a la mezcla. Imagina que después de cada uno de tus movimientos, mientras el oponente está pensando, repasas mentalmente cada uno de tus movimientos anteriores para reevaluar su calidad. Es posible que encuentres debilidades que descuidaste a simple vista o descubras que ciertos movimientos eran mejores de lo que pensabas. Estos pensamientos también pueden permitirte actualizar tu estrategia. Esto es exactamente de lo que se trata la planificación, actualizar la función de valor sin interactuar con el entorno real, sino más bien con un modelo de dicho entorno.

Por lo tanto, Dyna-Q contiene algunos pasos adicionales en comparación con Q-learning:
Después de cada actualización directa de los valores Q, el modelo almacena el par estado-acción y la recompensa y el siguiente estado que se observaron. Este paso se llama entrenamiento del modelo.
- Después del entrenamiento del modelo, Dyna-Q realiza n pasos de planificación:
- Se selecciona al azar un par estado-acción del búfer del modelo (es decir, este par estado-acción se observó durante las interacciones directas)
- El modelo genera la recompensa y el siguiente estado simulados
- La función de valor se actualiza utilizando las observaciones simuladas (s, a, r, s’)
![Pseudo-código del algoritmo Dyna-Q, reproducido de Reinforcement Learning, an introduction [4]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*qWrFsoUOD4icvOuQpkvg_g.png)
Ahora replicamos el proceso de aprendizaje con el algoritmo Dyna-Q usando n=100. Esto significa que después de cada interacción directa con el entorno, utilizamos el modelo para realizar 100 pasos de planificación (es decir, actualizaciones).
El siguiente mapa de calor muestra la rápida convergencia del modelo Dyna-Q. De hecho, solo toma alrededor de 10 episodios para encontrar un camino óptimo. Esto se debe a que cada paso conduce a 101 actualizaciones de los valores Q (en lugar de 1 para el aprendizaje Q).
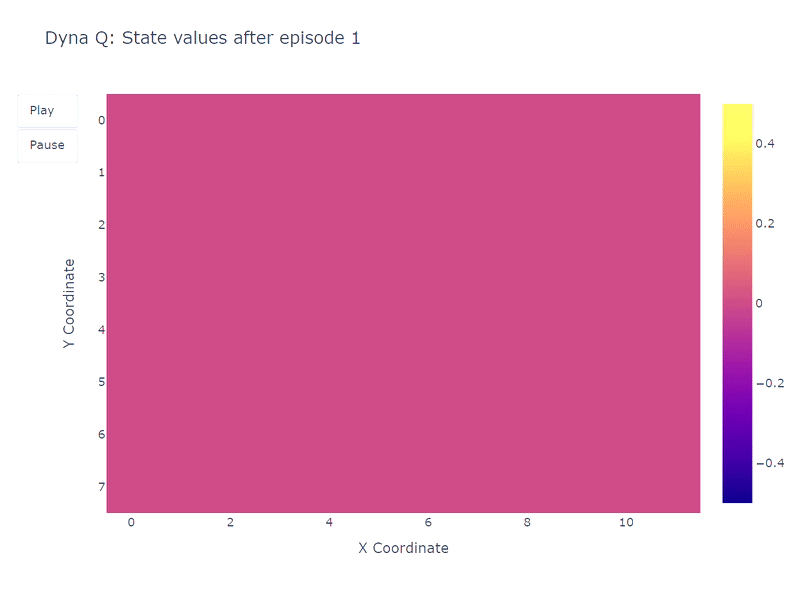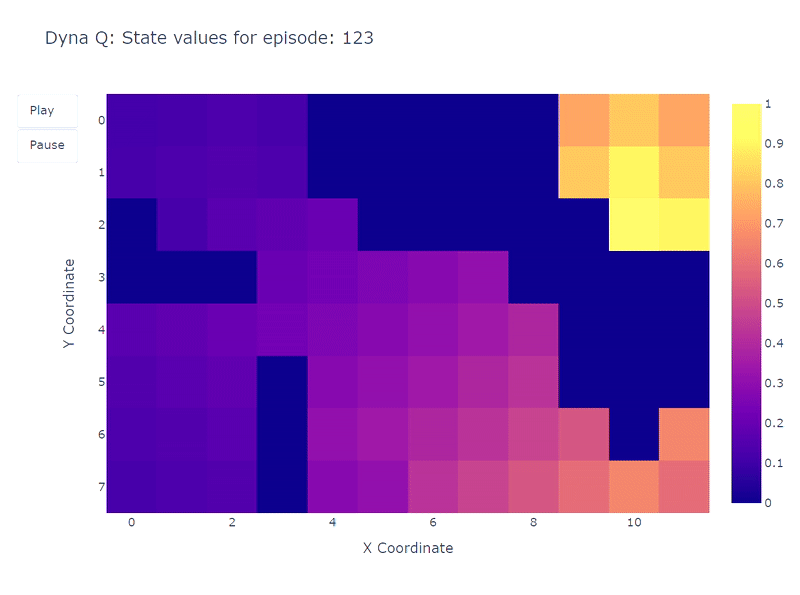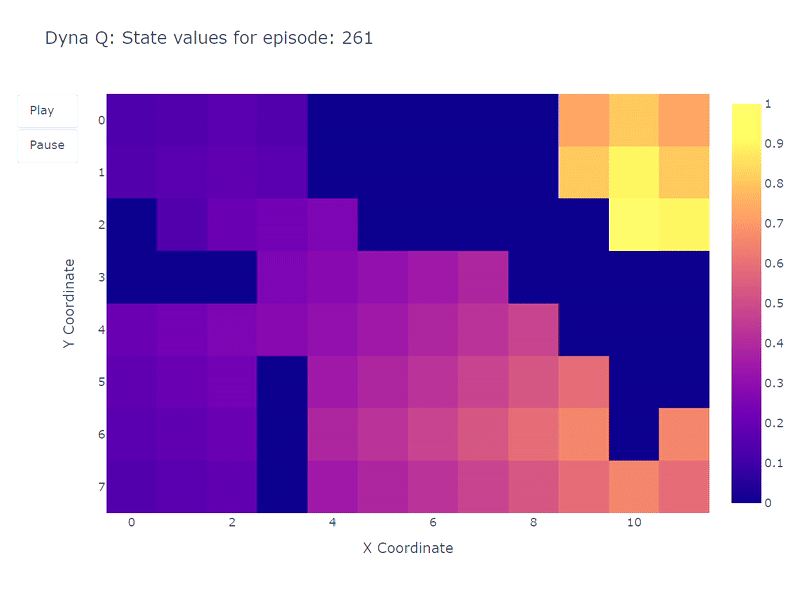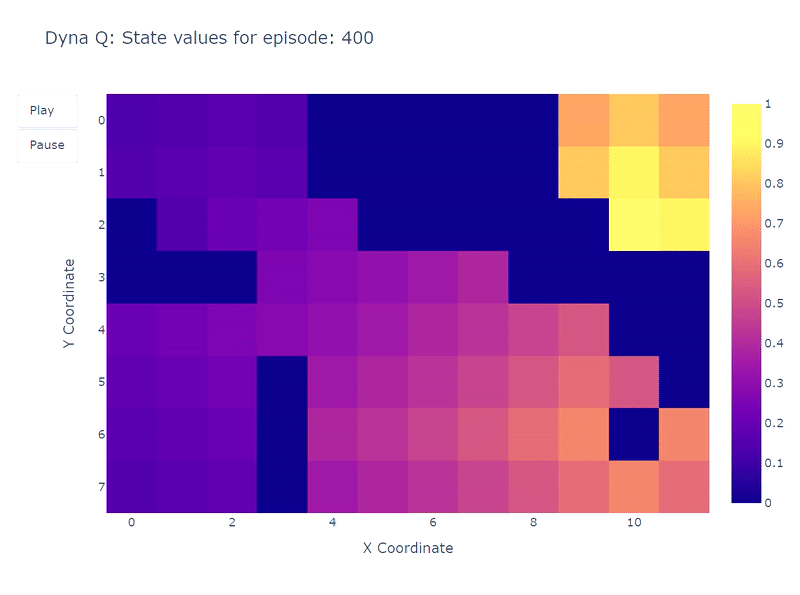
Otro beneficio de los pasos de planificación es una mejor estimación de los valores de acción en toda la cuadrícula. A medida que las actualizaciones indirectas apuntan a transiciones aleatorias almacenadas dentro del modelo, los estados que están lejos del objetivo también se actualizan.
En contraste, los valores de acción se propagan lentamente desde el objetivo en el aprendizaje Q, lo que lleva a un mapeo incompleto de la cuadrícula.
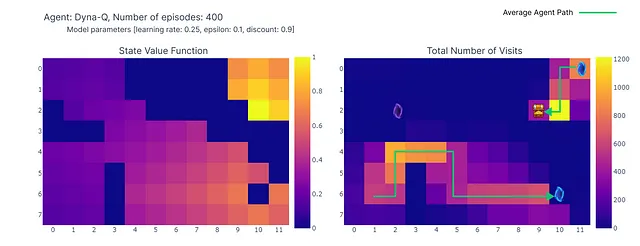
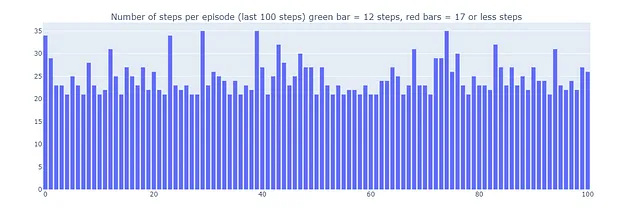
Usando Dyna-Q, encontramos un camino óptimo que permite la resolución del mundo en cuadrícula en 17 pasos, como se muestra en el gráfico a continuación con barras rojas. Se alcanzan regularmente rendimientos óptimos, a pesar de la interferencia ocasional de acciones ε-greedy con el fin de la exploración.
Finalmente, aunque Dyna-Q puede parecer más convincente que el aprendizaje Q debido a su incorporación de la planificación, es esencial recordar que la planificación introduce un compromiso entre costos computacionales y exploración del mundo real.
Dyna-Q+
Hasta ahora, ninguno de los algoritmos probados logró encontrar el camino óptimo que aparece después del paso 100 (el portal morado). De hecho, ambos algoritmos convergieron rápidamente hacia una solución óptima que se mantuvo fija hasta el final de la fase de entrenamiento. Esto resalta la necesidad de una exploración continua durante el entrenamiento.
Dyna-Q+ es en gran medida similar a Dyna-Q pero agrega un pequeño giro al algoritmo. De hecho, Dyna-Q+ realiza un seguimiento constante del número de pasos de tiempo transcurridos desde que se intentó cada par estado-acción en una interacción real con el entorno.
En particular, consideremos una transición que produce una recompensa r que no se ha intentado en τ pasos de tiempo. Dyna-Q+ realizaría una planificación como si la recompensa para esta transición fuera r + κ √τ, con κ suficientemente pequeño (0.001 en el experimento).
Este cambio en el diseño de la recompensa anima al agente a explorar continuamente el entorno. Supone que cuanto más tiempo haya pasado desde que se intentó un par estado-acción, mayores son las posibilidades de que la dinámica de este par haya cambiado o de que el modelo sea incorrecto.
![Pseudo-código del algoritmo Dyna-Q+, reproducido de Reinforcement Learning, an introduction [4]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*ULlUiD4-uyCdr5vi8MW-0Q.png)
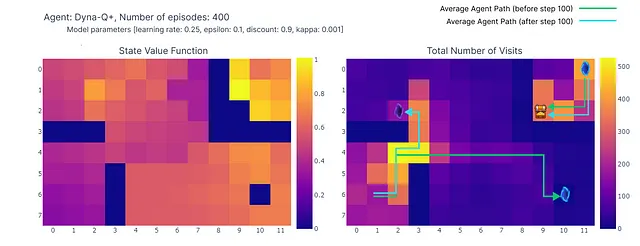
Tal como se muestra en el siguiente mapa de calor, Dyna-Q+ es mucho más activo con sus actualizaciones en comparación con los algoritmos anteriores. Antes del episodio 100, el agente explora toda la cuadrícula y encuentra el portal azul y la primera ruta óptima.
Los valores de acción para el resto de la cuadrícula disminuyen antes de aumentar lentamente nuevamente, ya que los pares de estados-acción en la esquina superior izquierda no se exploran durante algún tiempo.
Tan pronto como aparece el portal morado en el episodio 100, el agente encuentra el nuevo atajo y el valor de toda el área aumenta. Hasta la finalización de los 400 episodios, el agente actualizará continuamente el valor de acción de cada par estado-acción mientras mantiene una exploración ocasional de la cuadrícula.
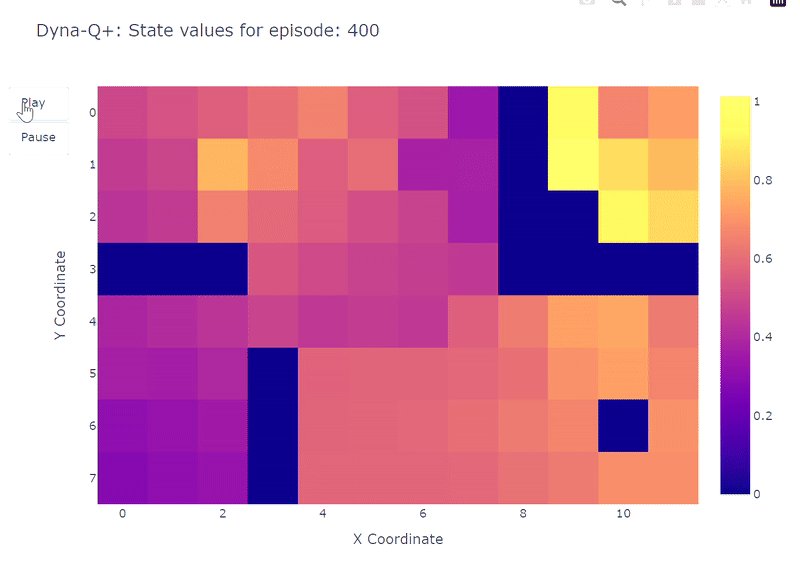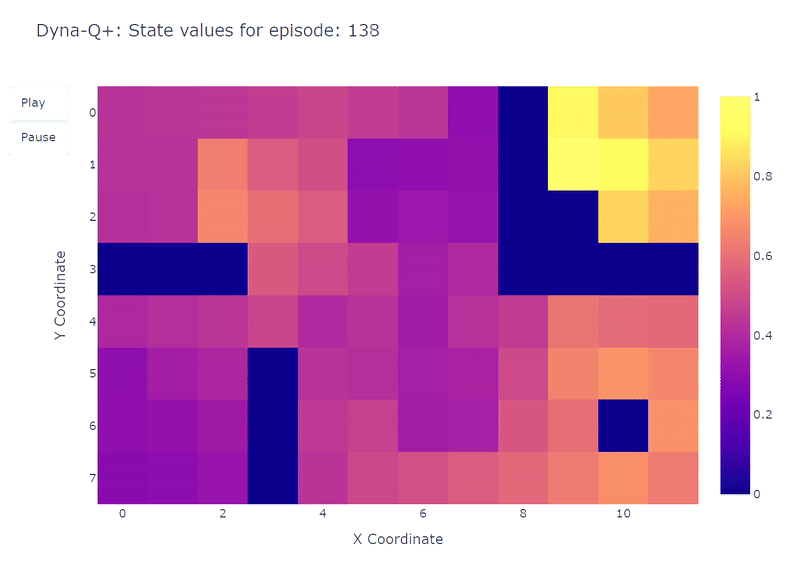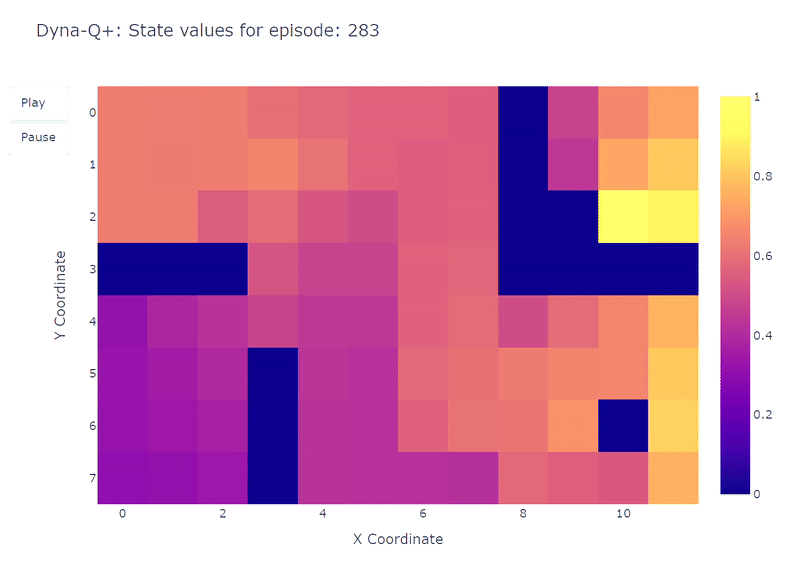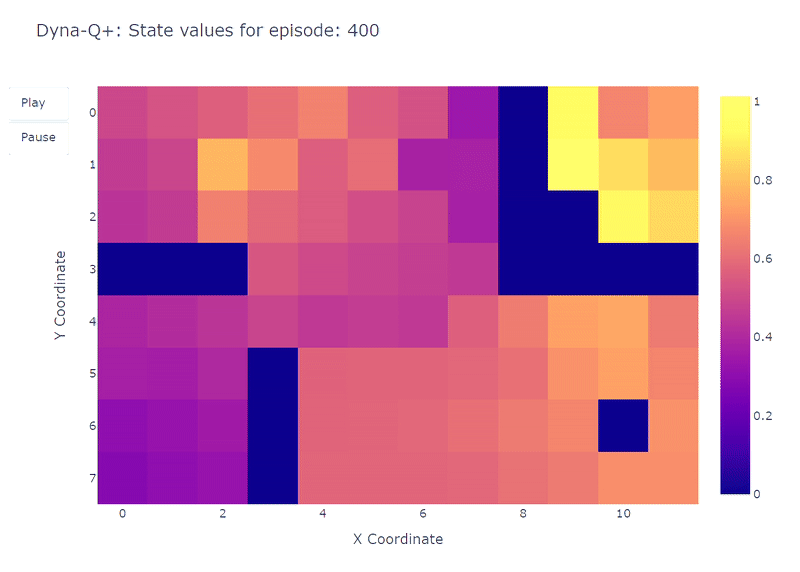
Gracias al bono agregado a las recompensas del modelo, finalmente obtenemos un mapeo completo de la función Q (cada estado o celda tiene un valor de acción).
Combinado con la exploración continua, el agente logra encontrar la nueva mejor ruta (es decir, la política óptima) a medida que aparece, mientras mantiene la solución anterior.
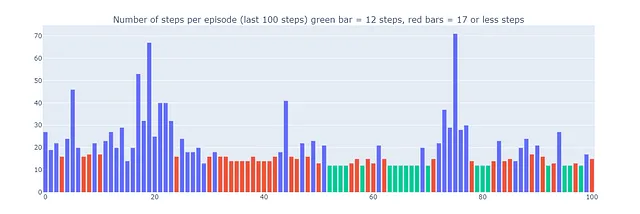
Sin embargo, el compromiso entre exploración y explotación en Dyna-Q+ tiene un costo. Cuando los pares estado-acción no han sido visitados durante un tiempo suficiente, el bono de exploración alienta al agente a revisitar esos estados, lo que puede disminuir temporalmente su rendimiento inmediato. Este comportamiento de exploración prioriza la actualización del modelo para mejorar la toma de decisiones a largo plazo.
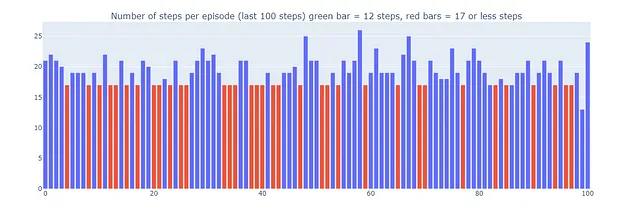
Esto explica por qué algunos episodios jugados por Dyna-Q+ pueden tener hasta 70 pasos de longitud, en comparación con un máximo de 35 y 25 pasos para Q-learning y Dyna-Q, respectivamente. Los episodios más largos en Dyna-Q+ reflejan la disposición del agente a invertir pasos adicionales en la exploración para recopilar más información sobre el entorno y refinar su modelo, incluso si eso resulta en reducciones de rendimiento a corto plazo.
En contraste, Dyna-Q+ regularmente logra un rendimiento óptimo (representado por las barras verdes en el gráfico a continuación) que los algoritmos anteriores no alcanzaron.
Resumen y Comparación de Algoritmos
Para comparar las diferencias clave entre los algoritmos, utilizamos dos métricas (ten en cuenta que los resultados dependen de los parámetros de entrada, que fueron idénticos entre todos los modelos por simplicidad):
- Número de pasos por episodio: esta métrica caracteriza la tasa de convergencia de los algoritmos hacia una solución óptima. También describe el comportamiento del algoritmo después de la convergencia, especialmente en términos de exploración.
- Recompensa acumulada promedio: el porcentaje de episodios que llevan a una recompensa positiva
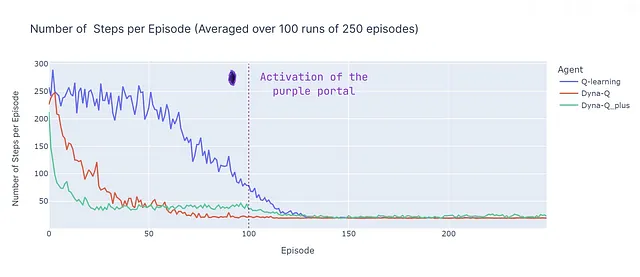
Al analizar el número de pasos por episodio (ver gráfico a continuación), se revelan varios aspectos de los métodos basados en modelos y sin modelos:
- Eficiencia basada en modelos: los algoritmos basados en modelos (Dyna-Q y Dyna-Q+) tienden a ser más eficientes en la utilización de muestras en este Grid World en particular (esta propiedad también se observa más generalmente en RL). Esto se debe a que pueden planificar con anticipación utilizando el modelo aprendido del entorno, lo que puede conducir a una convergencia más rápida hacia soluciones cercanas a óptimas u óptimas.
- Convergencia de Q-Learning: Q-learning, aunque eventualmente converge hacia una solución cercana a óptima, requiere más episodios (125) para hacerlo. Es importante destacar que Q-learning realiza solo 1 actualización por paso, lo cual contrasta con las múltiples actualizaciones realizadas por Dyna-Q y Dyna-Q+.
- Múltiples Actualizaciones: Dyna-Q y Dyna-Q+ ejecutan 101 actualizaciones por paso, lo que contribuye a su convergencia más rápida. Sin embargo, el costo computacional es el compromiso para esta eficiencia en el uso de muestras (ver la sección de tiempo de ejecución en la tabla a continuación).
- Entornos Complejos: En entornos más complejos o estocásticos, la ventaja de los métodos basados en modelos puede disminuir. Los modelos pueden introducir errores o inexactitudes, lo que puede llevar a políticas subóptimas. Por lo tanto, esta comparación debe verse como un resumen de las fortalezas y debilidades de diferentes enfoques en lugar de una comparación de rendimiento directa.
Ahora introducimos la recompensa acumulada promedio (ACR), que representa el porcentaje de episodios en los que el agente alcanza el objetivo (ya que la recompensa es 1 al alcanzar el objetivo y 0 al activar una trampa), el ACR se calcula simplemente mediante:
Con N el número de episodios (250) y K el número de ejecuciones independientes (100) y Rn,k la recompensa acumulada para el episodio n en la ejecución k.
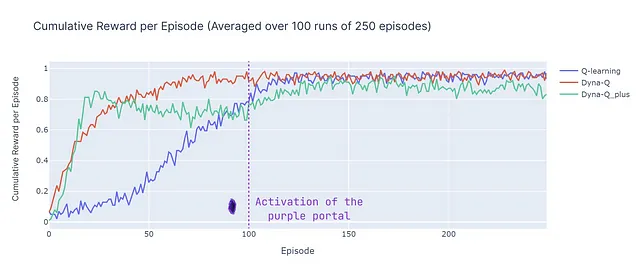
A continuación se muestra un desglose del rendimiento de todos los algoritmos:
- Dyna-Q converge rápidamente y logra el mayor retorno general, con un ACR del 87%. Esto significa que aprende eficientemente y alcanza el objetivo en una parte significativa de los episodios.
- Q-learning también alcanza un nivel similar de rendimiento, pero requiere más episodios para converger, lo que explica su ACR ligeramente inferior, del 70%.
- Dyna-Q+ encuentra rápidamente una buena política, alcanzando una recompensa acumulada de 0.8 después de solo 15 episodios. Sin embargo, la variabilidad y exploración inducidas por la recompensa adicional reducen el rendimiento hasta el paso 100. Después de 100 pasos, comienza a mejorar al descubrir el nuevo camino óptimo. Sin embargo, la exploración a corto plazo compromete su rendimiento, lo que resulta en un ACR del 79%, que es inferior a Dyna-Q pero superior a Q-learning.
Conclusión
En este artículo, presentamos los principios fundamentales del aprendizaje de Diferencia Temporal y aplicamos Q-learning, Dyna-Q y Dyna-Q+ a un mundo de rejilla personalizado. El diseño de este mundo de rejilla ayuda a enfatizar la importancia de la exploración continua como una forma de descubrir y explotar nuevas políticas óptimas en entornos cambiantes. Las diferencias de rendimiento (evaluadas utilizando el número de pasos por episodio y la recompensa acumulada) ilustran las fortalezas y debilidades de estos algoritmos.
En resumen, los métodos basados en modelos (Dyna-Q, Dyna-Q+) se benefician de una mayor eficiencia de muestra en comparación con los métodos basados en modelos (Q-learning), a costa de la eficiencia computacional. Sin embargo, en entornos estocásticos o más complejos, las inexactitudes en el modelo podrían obstaculizar el rendimiento y llevar a políticas subóptimas.

Referencias:
[1] Demis Hassabis, AlphaFold revela la estructura del universo de proteínas (2022), DeepMind
[2] Elia Kaufmann, Leonard Bauersfeld, Antonio Loquercio, Matthias Müller, Vladlen Koltun y Davide Scaramuzza, Carreras de drones a nivel de campeonato utilizando el aprendizaje por refuerzo profundo (2023), Nature
[3] Nathan Lambert, Louis Castricato, Leandro von Werra, Alex Havrilla, Ilustración del aprendizaje por refuerzo a partir de retroalimentación humana (RLHF), HuggingFace
[4] Sutton, R. S., y Barto, A. G. . Aprendizaje por refuerzo: una introducción (2018), Cambridge (Mass.): The MIT Press.
[5] Christopher J. C. H. Watkins y Peter Dayan, Q-learning (1992), Machine Learning, Springer Link
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 5 Proyectos Gratuitos de Ciencia de Datos con Soluciones
- Plan de estudios de Ciencia de Datos para autodidactas
- Desbloqueando la optimización de la batería Cómo el aprendizaje automático y la microscopía de rayos X a escala nanométrica podrían revolucionar las baterías de litio
- RELU vs. Softmax en Vision Transformers ¿Importa la longitud de la secuencia? Ideas de un artículo de investigación de Google DeepMind
- Branch and Bound – Introducción antes de codificar el algoritmo desde cero
- Lo más difícil de Pandas pivot_table, stack y unstack claramente explicados
- Robot Blando Camina al Inflarse Repetidamente