Una Guía Completa para MLOps
Guía completa MLOps

Introducción
Los modelos de ML han crecido significativamente en los últimos años y las empresas dependen cada vez más de ellos para automatizar y optimizar sus operaciones. Sin embargo, gestionar los modelos de ML puede ser desafiante, especialmente a medida que los modelos se vuelven más complejos y requieren más recursos para entrenar y desplegar. Esto ha llevado a la aparición de MLOps como una forma de estandarizar y agilizar el flujo de trabajo de ML. MLOps enfatiza la necesidad de integración continua y despliegue continuo (CI/CD) en el flujo de trabajo de ML, asegurando que los modelos se actualicen en tiempo real para reflejar los cambios en los datos o algoritmos de ML. Esta infraestructura es valiosa en áreas donde la precisión, la reproducibilidad y la confiabilidad son críticas, como la salud, las finanzas y los autos autónomos. Al implementar MLOps, las organizaciones pueden asegurarse de que sus modelos de ML se actualicen y sean precisos de manera continua, lo que ayuda a impulsar la innovación, reducir costos y mejorar la eficiencia.
- Tendencias principales de IA en marketing para observar en 2023
- Mejores Servidores Proxy 2023
- Clave maestra para la separación de fuentes de audio Presentamos AudioSep para separar cualquier cosa que describas
¿Qué es MLOps?
MLOps es una metodología que combina prácticas de ML y DevOps para agilizar el desarrollo, despliegue y mantenimiento de modelos de ML. MLOps comparte varias características clave con DevOps, que incluyen:
- CI/CD: MLOps enfatiza la necesidad de un ciclo continuo de actualizaciones de código, datos y modelos en los flujos de trabajo de ML. Este enfoque requiere automatizar tanto como sea posible para garantizar resultados consistentes y confiables.
- Automatización: Al igual que DevOps, MLOps destaca la importancia de la automatización en todo el ciclo de vida de ML. Automatizar pasos críticos en el flujo de trabajo de ML, como el procesamiento de datos, el entrenamiento de modelos y el despliegue, resulta en un flujo de trabajo más eficiente y confiable.
- Colaboración y Transparencia: MLOps fomenta una cultura colaborativa y transparente de conocimiento compartido y experiencia entre los equipos que desarrollan y despliegan modelos de ML. Esto ayuda a garantizar un proceso eficiente, ya que las expectativas de entrega serán más estandarizadas.
- Infraestructura como Código (IaC): DevOps y MLOps emplean un enfoque de “infraestructura como código”, en el que la infraestructura se trata como código y se gestiona a través de sistemas de control de versiones. Este enfoque permite a los equipos gestionar los cambios de infraestructura de manera más eficiente y reproducible.
- Pruebas y Monitoreo: MLOps y DevOps enfatizan la importancia de las pruebas y el monitoreo para garantizar resultados consistentes y confiables. En MLOps, esto implica probar y monitorear la precisión y el rendimiento de los modelos de ML a lo largo del tiempo.
- Flexibilidad y Agilidad: DevOps y MLOps enfatizan la flexibilidad y agilidad en respuesta a las cambiantes necesidades y requisitos comerciales. Esto significa poder implementar y iterar rápidamente en modelos de ML para mantenerse al día con las demandas comerciales en evolución.
En resumen, ML tiene mucha variabilidad en su comportamiento, dado que los modelos son esencialmente una caja negra utilizada para generar alguna predicción. Si bien DevOps y MLOps comparten muchas similitudes, MLOps requiere un conjunto de herramientas y prácticas más especializadas para abordar los desafíos únicos planteados por los flujos de trabajo de ML impulsados por datos y computacionalmente intensivos. Los flujos de trabajo de ML a menudo requieren una amplia gama de habilidades técnicas que van más allá del desarrollo de software tradicional, y pueden involucrar componentes de infraestructura especializados, como aceleradores, GPUs y clústeres, para gestionar las demandas computacionales del entrenamiento y despliegue de modelos de ML. Sin embargo, adoptar las mejores prácticas de DevOps y aplicarlas en todo el flujo de trabajo de ML reducirá significativamente los tiempos del proyecto y proporcionará la estructura que ML necesita para ser efectivo en producción.
Importancia y Beneficios de MLOps en los Negocios Modernos
ML ha revolucionado la forma en que las empresas analizan datos, toman decisiones y optimizan operaciones. Permite a las organizaciones crear modelos potentes basados en datos que revelan patrones, tendencias e ideas, lo que lleva a una toma de decisiones más informada y una automatización más efectiva. Sin embargo, desplegar y gestionar modelos de ML de manera efectiva puede ser desafiante, y ahí es donde entra en juego MLOps. MLOps es cada vez más importante para los negocios modernos porque ofrece una serie de beneficios, que incluyen:
- Tiempo de Desarrollo más Rápido: MLOps permite a las organizaciones acelerar el ciclo de vida de desarrollo de modelos de ML, reduciendo el tiempo de llegada al mercado y permitiendo a las empresas responder rápidamente a las demandas cambiantes del mercado. Además, MLOps puede ayudar a automatizar muchas tareas en la recopilación de datos, el entrenamiento de modelos y el despliegue, liberando recursos y acelerando el proceso general.
- Mejor Rendimiento del Modelo: Con MLOps, las empresas pueden monitorear y mejorar continuamente el rendimiento de sus modelos de ML. MLOps facilita mecanismos de prueba automatizados para modelos de ML, que detectan problemas relacionados con la precisión del modelo, el cambio del modelo y la calidad de los datos. Las organizaciones pueden mejorar el rendimiento y la precisión general de sus modelos de ML al abordar estos problemas de manera temprana, lo que se traduce en mejores resultados comerciales.
- Despliegues más Confiables: MLOps permite a las empresas desplegar modelos de ML de manera más confiable y consistente en diferentes entornos de producción. Al automatizar el proceso de despliegue, MLOps reduce el riesgo de errores de despliegue e inconsistencias entre diferentes entornos al ejecutarse en producción.
- Reducción de Costos y Mejora de la Eficiencia: Implementar MLOps puede ayudar a las organizaciones a reducir costos y mejorar la eficiencia general. Al automatizar muchas tareas involucradas en el procesamiento de datos, el entrenamiento de modelos y el despliegue, las organizaciones pueden reducir la necesidad de intervención manual, lo que resulta en un flujo de trabajo más eficiente y rentable.
En resumen, MLOps es esencial para las empresas modernas que buscan aprovechar el poder transformador de la IA para impulsar la innovación, mantenerse por delante de la competencia y mejorar los resultados empresariales. Al permitir un desarrollo más rápido, un mejor rendimiento del modelo, implementaciones más confiables y una mayor eficiencia, MLOps es fundamental para desbloquear todo el potencial de la IA en la inteligencia empresarial y la estrategia. Utilizar herramientas de MLOps también permitirá a los miembros del equipo centrarse en asuntos más importantes y a las empresas ahorrar en la necesidad de contar con grandes equipos dedicados para mantener flujos de trabajo redundantes.
El ciclo de vida de MLOps
Ya sea que esté creando su propia infraestructura de MLOps o seleccionando entre varias plataformas de MLOps disponibles en línea, asegurarse de que su infraestructura abarque las cuatro características mencionadas a continuación es fundamental para el éxito. Al seleccionar herramientas de MLOps que aborden estos aspectos vitales, creará un ciclo continuo desde los científicos de datos hasta los ingenieros de implementación para desplegar modelos rápidamente sin sacrificar la calidad.
Integración continua (CI)
La integración continua (CI) implica probar y validar constantemente los cambios realizados en el código y los datos para asegurarse de que cumplan con un conjunto de estándares definidos. En MLOps, la CI integra nuevos datos y actualizaciones de modelos de IA y código de soporte. La CI ayuda a los equipos a detectar problemas temprano en el proceso de desarrollo, lo que les permite colaborar de manera más efectiva y mantener modelos de IA de alta calidad. Ejemplos de prácticas de CI en MLOps incluyen:
– Verificaciones automáticas de validación de datos para garantizar la integridad y calidad de los datos.
– Control de versiones del modelo para rastrear cambios en la arquitectura y los hiperparámetros del modelo.
– Pruebas unitarias automáticas del código del modelo para detectar problemas antes de que el código se fusione en el repositorio de producción.
Implementación continua (CD)
La implementación continua (CD) es la liberación automatizada de actualizaciones de software en entornos de producción, como modelos de IA o aplicaciones. En MLOps, la CD se enfoca en garantizar que la implementación de los modelos de IA sea fluida, confiable y consistente. La CD reduce el riesgo de errores durante la implementación y facilita el mantenimiento y la actualización de los modelos de IA en respuesta a los cambios en los requisitos empresariales. Ejemplos de prácticas de CD en MLOps incluyen:
– Tubería de IA automatizada con herramientas de implementación continua como Jenkins o CircleCI para integrar y probar actualizaciones del modelo, y luego implementarlos en producción.
– Contenerización de modelos de IA utilizando tecnologías como Docker para lograr un entorno de implementación consistente, reduciendo posibles problemas de implementación.
– Implementación de implementaciones escalonadas o implementaciones azul-verde para minimizar el tiempo de inactividad y permitir una fácil reversión de actualizaciones problemáticas.
Entrenamiento continuo (CT)
El entrenamiento continuo (CT) implica actualizar los modelos de IA a medida que se disponga de nuevos datos o a medida que los datos existentes cambien con el tiempo. Este aspecto esencial de MLOps garantiza que los modelos de IA sigan siendo precisos y efectivos al considerar los últimos datos y prevenir la deriva del modelo. Entrenar regularmente modelos con nuevos datos ayuda a mantener un rendimiento óptimo y lograr mejores resultados empresariales. Ejemplos de prácticas de CT en MLOps incluyen:
– Establecer políticas (por ejemplo, umbrales de precisión) que desencadenen el reentrenamiento del modelo para mantener una precisión actualizada.
– Utilizar estrategias de aprendizaje activo para priorizar la recolección de nuevos datos valiosos para el entrenamiento.
– Emplear métodos de conjunto para combinar múltiples modelos entrenados en diferentes subconjuntos de datos, lo que permite una mejora continua del modelo y su adaptación a los cambios en los patrones de datos.
Monitoreo continuo (CM)
El monitoreo continuo (CM) implica analizar constantemente el rendimiento de los modelos de IA en entornos de producción para identificar posibles problemas, verificar que los modelos cumplan con los estándares definidos y mantener la efectividad general del modelo. Los profesionales de MLOps utilizan el CM para detectar problemas como la deriva del modelo o la degradación del rendimiento, que pueden comprometer la precisión y confiabilidad de las predicciones. Al monitorear regularmente el rendimiento de sus modelos, las organizaciones pueden abordar de manera proactiva cualquier problema, asegurando que sus modelos de IA sigan siendo efectivos y generen los resultados deseados. Ejemplos de prácticas de CM en MLOps incluyen:
– Seguimiento de indicadores clave de rendimiento (KPI) de los modelos en producción, como precisión, recuperación u otras métricas específicas del dominio.
– Implementación de paneles de control de monitoreo del rendimiento del modelo para visualizar en tiempo real el estado del modelo.
– Aplicación de técnicas de detección de anomalías para identificar y manejar la deriva conceptual, asegurando que el modelo pueda adaptarse a los cambios en los patrones de datos y mantener su precisión con el tiempo.
¿Cómo beneficia MLOps al ciclo de vida de la IA?
Administrar e implementar modelos de aprendizaje automático puede ser consumidor de tiempo y desafiante, principalmente debido a la complejidad de los flujos de trabajo de aprendizaje automático, la variabilidad de los datos, la necesidad de experimentación iterativa y la monitorización y actualización continua de los modelos implementados. Cuando el ciclo de vida del aprendizaje automático no se optimiza adecuadamente con MLOps, las organizaciones enfrentan problemas como resultados inconsistentes debido a la variabilidad de la calidad de los datos, implementación más lenta a medida que los procesos manuales se convierten en cuellos de botella, y dificultad para mantener y actualizar los modelos lo suficientemente rápido como para reaccionar a las condiciones comerciales cambiantes. MLOps aporta eficiencia, automatización y mejores prácticas que facilitan cada etapa del ciclo de vida del aprendizaje automático.
Consideremos un escenario en el que un equipo de ciencia de datos sin prácticas de MLOps dedicadas está desarrollando un modelo de aprendizaje automático para la previsión de ventas. En este escenario, el equipo puede enfrentar los siguientes desafíos:
- Las tareas de preprocesamiento y limpieza de datos consumen mucho tiempo debido a la falta de prácticas estandarizadas o herramientas automatizadas de validación de datos.
- Dificultad para reproducir y rastrear experimentos debido a una versión inadecuada de la arquitectura del modelo, hiperparámetros y conjuntos de datos.
- Los procesos de implementación manuales e ineficientes provocan retrasos en la liberación de modelos en producción y aumentan el riesgo de errores en entornos de producción.
- Las implementaciones manuales también pueden generar muchas fallas en la implementación automática de escalado en varios servidores en línea, lo que afecta la redundancia y el tiempo de actividad.
- Incapacidad para ajustar rápidamente los modelos implementados a los cambios en los patrones de datos, lo que potencialmente lleva a una degradación del rendimiento y deriva del modelo.
Existen cinco etapas en el ciclo de vida del aprendizaje automático, que se mejoran directamente con las herramientas de MLOps mencionadas a continuación.
Recopilación y preprocesamiento de datos
La primera etapa del ciclo de vida del aprendizaje automático implica la recopilación y preprocesamiento de datos. Las organizaciones pueden garantizar la calidad, consistencia y gestionabilidad de los datos mediante la implementación de mejores prácticas en esta etapa. La versión de datos, las comprobaciones automatizadas de validación de datos y la colaboración dentro del equipo conducen a una mayor precisión y efectividad de los modelos de aprendizaje automático. Ejemplos incluyen:
- Versión de datos para rastrear cambios en los conjuntos de datos utilizados para el modelado.
- Comprobaciones automatizadas de validación de datos para mantener la calidad e integridad de los datos.
- Herramientas de colaboración dentro del equipo para compartir y gestionar fuentes de datos de manera efectiva.
Desarrollo de modelos
MLOps ayuda a los equipos a seguir prácticas estandarizadas durante la etapa de desarrollo del modelo al seleccionar algoritmos, características y ajustar hiperparámetros. Esto reduce las ineficiencias y los esfuerzos duplicados, lo que mejora el rendimiento general del modelo. Implementar control de versiones, rastreo de experimentación automatizado y herramientas de colaboración agilizan significativamente esta etapa del ciclo de vida del aprendizaje automático. Ejemplos incluyen:
- Implementar control de versiones para la arquitectura del modelo y los hiperparámetros.
- Establecer un centro central para el seguimiento automatizado de experimentos para reducir la repetición de experimentos y fomentar comparaciones y discusiones fáciles.
- Herramientas de visualización y seguimiento de métricas para fomentar la colaboración y monitorear el rendimiento de los modelos durante el desarrollo.
Entrenamiento y validación del modelo
En la etapa de entrenamiento y validación, MLOps garantiza que las organizaciones utilicen procesos confiables para entrenar y evaluar sus modelos de aprendizaje automático. Las organizaciones pueden optimizar eficazmente la precisión de sus modelos aprovechando la automatización y las mejores prácticas en el entrenamiento. Las prácticas de MLOps incluyen validación cruzada, gestión de tuberías de entrenamiento e integración continua para probar y validar automáticamente las actualizaciones del modelo. Ejemplos incluyen:
- Técnicas de validación cruzada para una mejor evaluación del modelo.
- Gestión de tuberías y flujos de trabajo de entrenamiento para un proceso más eficiente y ágil.
- Flujos de trabajo de integración continua para probar y validar automáticamente las actualizaciones del modelo.
Implementación del modelo
La cuarta etapa es la implementación del modelo en entornos de producción. Las prácticas de MLOps en esta etapa ayudan a las organizaciones a implementar modelos de manera más confiable y consistente, reduciendo el riesgo de errores e inconsistencias durante la implementación. Técnicas como la contenerización utilizando Docker y las tuberías de implementación automatizadas permiten la integración perfecta de los modelos en entornos de producción, facilitando la capacidad de deshacer y monitorear. Ejemplos incluyen:
- Contenerización utilizando Docker para entornos de implementación consistentes.
- Tuberías de implementación automatizadas para manejar versiones del modelo sin intervención manual.
- Capacidad de deshacer y monitoreo para una identificación y solución rápida de problemas de implementación.
Monitoreo y mantenimiento del modelo
La quinta etapa implica el monitoreo y mantenimiento continuo de los modelos de aprendizaje automático en producción. Utilizar los principios de MLOps para esta etapa permite a las organizaciones evaluar y ajustar los modelos según sea necesario de manera consistente. El monitoreo regular ayuda a detectar problemas como la deriva del modelo o la degradación del rendimiento, que pueden comprometer la precisión y confiabilidad de las predicciones. Los indicadores clave de rendimiento, los paneles de rendimiento del modelo y los mecanismos de alerta garantizan que las organizaciones puedan abordar proactivamente cualquier problema y mantener la efectividad de sus modelos de aprendizaje automático. Ejemplos incluyen:
- Indicadores clave de rendimiento para hacer un seguimiento del rendimiento de los modelos en producción.
- Paneles de rendimiento del modelo para visualizar en tiempo real la salud del modelo.
- Mecanismos de alerta para notificar a los equipos de cambios repentinos o graduales en el rendimiento del modelo, permitiendo una rápida intervención y remedio.
Herramientas y Tecnologías de MLOps
Adoptar las herramientas y tecnologías adecuadas es crucial para implementar las prácticas de MLOps y gestionar con éxito los flujos de trabajo de ML de principio a fin. Muchas soluciones de MLOps ofrecen muchas características, desde la gestión de datos y el seguimiento de experimentos hasta la implementación y monitorización de modelos. De una herramienta de MLOps que promociona todo un flujo de trabajo del ciclo de vida de ML, se espera que estas características se implementen de alguna manera:
- Gestión del ciclo de vida de ML de principio a fin: Todas estas herramientas están diseñadas para admitir diversas etapas del ciclo de vida de ML, desde la preprocesamiento de datos y el entrenamiento de modelos hasta la implementación y monitorización.
- Seguimiento y versionado de experimentos: Estas herramientas proporcionan algún mecanismo para realizar un seguimiento de los experimentos, las versiones de modelos y las ejecuciones de canalización, lo que permite la reproducibilidad y la comparación de diferentes enfoques. Algunas herramientas pueden mostrar la reproducibilidad utilizando otras abstracciones, pero de todas formas tienen algún tipo de control de versiones.
- Implementación de modelos: Si bien los detalles difieren entre las herramientas, todas ofrecen alguna funcionalidad de implementación de modelos para ayudar a los usuarios a trasladar sus modelos a entornos de producción o proporcionar un punto de implementación rápida para probar con aplicaciones que soliciten inferencia de modelos.
- Integración con bibliotecas y marcos de trabajo de ML populares: Estas herramientas son compatibles con bibliotecas de ML populares como TensorFlow, PyTorch y Scikit-learn, lo que permite a los usuarios aprovechar sus herramientas y habilidades de ML existentes. Sin embargo, el nivel de soporte de cada marco de trabajo difiere en las herramientas.
- Escalabilidad: Cada plataforma proporciona formas de escalar flujos de trabajo, ya sea horizontal, vertical o ambos, lo que permite a los usuarios trabajar con grandes conjuntos de datos y entrenar modelos más complejos de manera eficiente.
- Extensibilidad y personalización: Estas herramientas ofrecen extensibilidad y personalización variables, lo que permite a los usuarios adaptar la plataforma a sus necesidades específicas e integrarla con otras herramientas o servicios según sea necesario.
- Colaboración y soporte multiusuario: Cada plataforma suele admitir la colaboración entre los miembros del equipo, lo que les permite compartir recursos, código, datos y resultados experimentales, fomentando un trabajo en equipo más efectivo y una comprensión compartida a lo largo del ciclo de vida de ML.
- Gestión de entorno y dependencias: La mayoría de estas herramientas incluyen funciones que abordan la gestión de entornos coherentes y reproducibles. Esto puede implicar la gestión de dependencias utilizando contenedores (por ejemplo, Docker) o entornos virtuales (por ejemplo, Conda) o proporcionando configuraciones preconfiguradas con bibliotecas y herramientas populares de ciencia de datos preinstaladas.
- Monitorización y alerta: Las herramientas de MLOps de principio a fin también podrían ofrecer alguna forma de monitorización de rendimiento, detección de anomalías o funcionalidad de alerta. Esto ayuda a los usuarios a mantener modelos de alto rendimiento, identificar posibles problemas y asegurar que sus soluciones de ML sigan siendo confiables y eficientes en producción.
Aunque hay una superposición considerable en las funcionalidades principales proporcionadas por estas herramientas, sus implementaciones únicas, métodos de ejecución y áreas de enfoque las distinguen. En otras palabras, juzgar una herramienta de MLOps a simple vista puede ser difícil al comparar sus ofertas en papel. Todas estas herramientas proporcionan una experiencia de flujo de trabajo diferente.
En las siguientes secciones, mostraremos algunas herramientas notables de MLOps diseñadas para proporcionar una experiencia completa de MLOps de principio a fin y destacaremos las diferencias en cómo abordan y ejecutan las características estándar de MLOps.
MLFlow
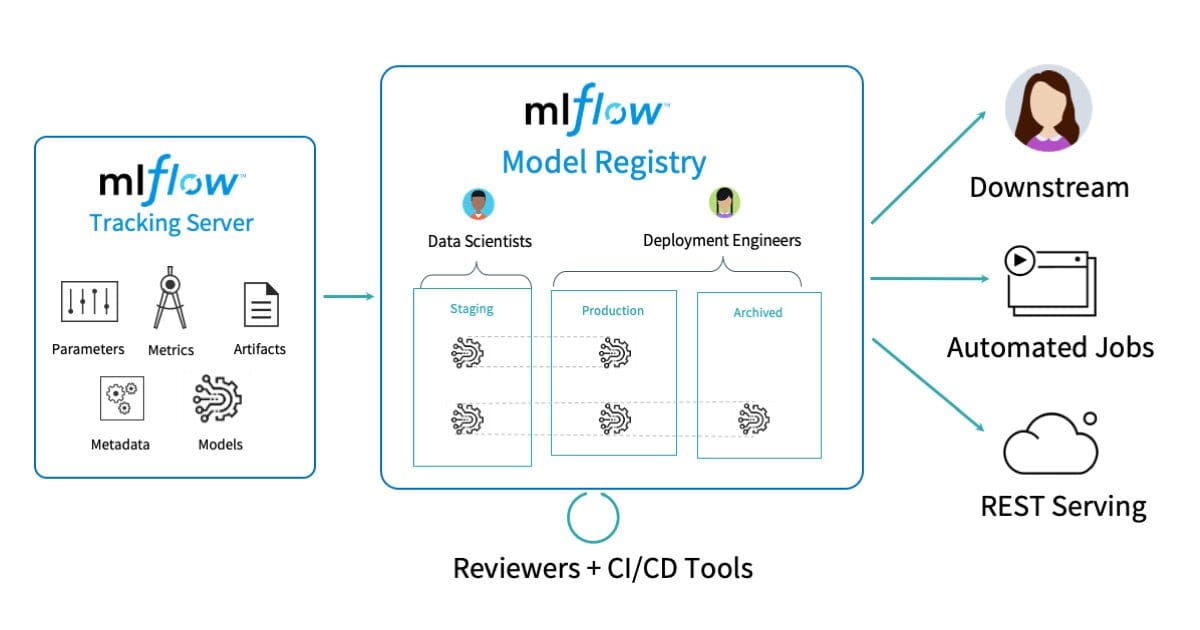
MLflow tiene características y características únicas que lo diferencian de otras herramientas de MLOps, lo que lo hace atractivo para usuarios con requisitos o preferencias específicas:
- Modularidad: Una de las ventajas más importantes de MLflow es su arquitectura modular. Consiste en componentes independientes (Tracking, Projects, Models y Registry) que se pueden utilizar por separado o en combinación, lo que permite a los usuarios adaptar la plataforma a sus necesidades precisas sin verse obligados a adoptar todos los componentes.
- Agnóstico del lenguaje: MLflow admite varios lenguajes de programación, incluidos Python, R y Java, lo que lo hace accesible a una amplia gama de usuarios con conjuntos de habilidades diversos. Esto beneficia principalmente a los equipos con miembros que prefieren diferentes lenguajes de programación para sus cargas de trabajo de ML.
- Integración con bibliotecas populares: MLflow está diseñado para funcionar con bibliotecas de ML populares como TensorFlow, PyTorch y Scikit-learn. Esta compatibilidad permite a los usuarios integrar MLflow sin problemas en sus flujos de trabajo existentes, aprovechando sus características de gestión sin adoptar un ecosistema completamente nuevo o cambiar sus herramientas actuales.
- Comunidad activa de código abierto: MLflow cuenta con una comunidad de código abierto vibrante que contribuye a su desarrollo y mantiene la plataforma actualizada con nuevas tendencias y requisitos en el espacio de MLOps. Este apoyo activo de la comunidad asegura que MLflow siga siendo una solución de gestión de ciclo de vida de ML de vanguardia y relevante.
Mientras que MLflow es una herramienta versátil y modular para gestionar varios aspectos del ciclo de vida de ML, tiene algunas limitaciones en comparación con otras plataformas de MLOps. Una área notable en la que MLflow se queda corto es su necesidad de una función de orquestación y ejecución de tuberías integrada y incorporada, como las proporcionadas por TFX o Kubeflow Pipelines. Si bien MLflow puede estructurar y gestionar los pasos de su tubería utilizando su seguimiento, proyectos y componentes de modelos, los usuarios pueden necesitar confiar en herramientas externas o secuencias de comandos personalizadas para coordinar flujos de trabajo complejos de principio a fin y automatizar la ejecución de tareas de la tubería. Como resultado, las organizaciones que buscan un soporte más simplificado y listo para usar para la orquestación de tuberías complejas pueden encontrar que las capacidades de MLflow necesitan mejorar y explorar plataformas o integraciones alternativas para abordar sus necesidades de gestión de tuberías.
Kubeflow

Mientras que Kubeflow es una plataforma completa de MLOps con una serie de componentes diseñados para cubrir varios aspectos del ciclo de vida de ML, tiene algunas limitaciones en comparación con otras herramientas de MLOps. Algunas de las áreas en las que Kubeflow puede quedarse corto incluyen:
- Mayor Curva de Aprendizaje: El fuerte acoplamiento de Kubeflow con Kubernetes puede resultar en una mayor curva de aprendizaje para los usuarios que necesitan familiarizarse más con los conceptos y herramientas de Kubernetes. Esto podría aumentar el tiempo requerido para incorporar nuevos usuarios y podría ser una barrera para la adopción de equipos sin experiencia en Kubernetes.
- Soporte Limitado de Lenguaje: Kubeflow fue desarrollado inicialmente con un enfoque principal en TensorFlow, y aunque ha ampliado el soporte para otros marcos de ML como PyTorch y MXNet, todavía tiene un sesgo más pronunciado hacia el ecosistema de TensorFlow. Las organizaciones que trabajan con otros lenguajes o marcos pueden requerir esfuerzos adicionales para adoptar e integrar Kubeflow en sus flujos de trabajo.
- Complejidad de Infraestructura: La dependencia de Kubeflow en Kubernetes puede introducir una complejidad adicional en la gestión de infraestructura para organizaciones sin una configuración de Kubernetes existente. Equipos más pequeños o proyectos que no requieren las capacidades completas de Kubernetes pueden encontrar que los requisitos de infraestructura de Kubeflow son una sobrecarga innecesaria.
- Menor Enfoque en el Seguimiento de Experimentos: Si bien Kubeflow ofrece funcionalidades de seguimiento de experimentos a través de su componente Kubeflow Pipelines, es posible que no sea tan extenso o fácil de usar como herramientas dedicadas de seguimiento de experimentos como MLflow o Weights & Biases, otra herramienta de MLOps de extremo a extremo con énfasis en herramientas de observabilidad de modelos en tiempo real. Los equipos con un fuerte enfoque en el seguimiento y comparación de experimentos pueden encontrar que este aspecto de Kubeflow necesita mejoras en comparación con otras plataformas de MLOps con características de seguimiento más avanzadas.
- Integración con Sistemas No-Kubernetes: El diseño nativo de Kubernetes de Kubeflow puede limitar sus capacidades de integración con otros sistemas basados en infraestructura no-Kubernetes o propietaria. En contraste, herramientas de MLOps más flexibles o agnósticas como MLflow pueden ofrecer opciones de integración más accesibles con diversas fuentes de datos y herramientas, independientemente de la infraestructura subyacente.
Kubeflow es una plataforma de MLOps diseñada como un envoltorio alrededor de Kubernetes, simplificando la implementación, escalado y gestión de cargas de trabajo de ML al convertirlas en cargas de trabajo nativas de Kubernetes. Esta estrecha relación con Kubernetes ofrece ventajas, como la orquestación eficiente de flujos de trabajo de ML complejos. Sin embargo, puede introducir complejidades para los usuarios que carecen de experiencia en Kubernetes, aquellos que utilizan una amplia gama de lenguajes o marcos, o las organizaciones con infraestructura no basada en Kubernetes. En general, la naturaleza centrada en Kubernetes de Kubeflow proporciona beneficios significativos para la implementación y orquestación, y las organizaciones deben tener en cuenta estos compromisos y factores de compatibilidad al evaluar Kubeflow para sus necesidades de MLOps.
Saturn Cloud
Saturn Cloud es una plataforma de MLOps que ofrece escalado sin complicaciones, infraestructura, colaboración e implementación rápida de modelos de ML, centrándose en la paralelización y aceleración de la GPU. Algunas ventajas clave y características robustas de Saturn Cloud incluyen:
- Enfoque en Aceleración de Recursos: Saturn Cloud enfatiza en proporcionar aceleración de GPU fácil de usar y una gestión de recursos flexible para cargas de trabajo de ML. Mientras que otras herramientas pueden admitir procesamiento basado en GPU, Saturn Cloud simplifica este proceso para eliminar la sobrecarga de gestión de infraestructura para que el científico de datos pueda usar esta aceleración.
- Dask y Computación Distribuida: Saturn Cloud tiene una integración estrecha con Dask, una biblioteca popular para computación en paralelo y distribuida en Python. Esta integración permite a los usuarios escalar sus cargas de trabajo fácilmente para utilizar el procesamiento paralelo en clústeres multinodos.
- Infraestructura y Entornos Preconstruidos Gestionados: Saturn Cloud va un paso más allá al proporcionar infraestructura y entornos preconstruidos gestionados, aliviando la carga de la configuración y el mantenimiento de la infraestructura para los usuarios.
- Gestión y Compartición Fácil de Recursos: Saturn Cloud simplifica la compartición de recursos como imágenes de Docker, secretos y carpetas compartidas al permitir a los usuarios definir la propiedad y los permisos de acceso a los activos. Estos activos pueden ser propiedad de un usuario individual, de un grupo (una colección de usuarios) o de toda la organización. La propiedad determina quién puede acceder y usar los recursos compartidos. Además, los usuarios pueden clonar fácilmente entornos completos para que otros ejecuten el mismo código en cualquier lugar.
- Infraestructura como Código: Saturn Cloud utiliza un formato JSON de receta, lo que permite a los usuarios definir y gestionar recursos con un enfoque centrado en el código. Esto fomenta la consistencia, la modularidad y el control de versiones, agilizando la configuración y gestión de los componentes de la infraestructura de la plataforma.
Saturn Cloud, aunque proporciona características y funcionalidades útiles para muchos casos de uso, puede tener algunas limitaciones en comparación con otras herramientas de MLOps. Aquí hay algunas áreas en las que Saturn Cloud podría tener limitaciones:
- Integración con lenguajes que no son Python: Saturn Cloud se enfoca principalmente en el ecosistema de Python, con un amplio soporte para bibliotecas y herramientas populares de Python. Sin embargo, cualquier lenguaje que se pueda ejecutar en un entorno Linux se puede ejecutar con la plataforma de Saturn Cloud.
- Seguimiento de experimentos listo para usar: Si bien Saturn Cloud facilita el registro y seguimiento de experimentos, su enfoque en la escalabilidad y la infraestructura es más extenso que sus capacidades de seguimiento de experimentos. Sin embargo, aquellos que buscan más personalización y funcionalidad en el seguimiento de experimentos en el flujo de trabajo de MLOps estarán satisfechos al saber que Saturn Cloud se puede integrar con plataformas que incluyen, pero no se limitan a, Comet, Weights & Biases, Verta y Neptune.
- Orquestación nativa de Kubernetes: Aunque Saturn Cloud ofrece escalabilidad e infraestructura administrada a través de Dask, carece de la orquestación nativa de Kubernetes que ofrecen herramientas como Kubeflow. Las organizaciones que están fuertemente invertidas en Kubernetes pueden preferir plataformas con una integración más profunda de Kubernetes.
TensorFlow Extended (TFX)

TensorFlow Extended (TFX) es una plataforma de extremo a extremo diseñada específicamente para usuarios de TensorFlow, que proporciona una solución integral y estrechamente integrada para gestionar flujos de trabajo de ML basados en TensorFlow. TFX destaca en áreas como:
- Integración con TensorFlow: La fortaleza más notable de TFX es su integración perfecta con el ecosistema de TensorFlow. Ofrece un conjunto completo de componentes adaptados para TensorFlow, lo que facilita a los usuarios que ya están invertidos en TensorFlow construir, probar, implementar y monitorear sus modelos de ML sin tener que cambiar a otras herramientas o frameworks.
- Preparación para la producción: TFX está diseñado teniendo en cuenta los entornos de producción, enfatizando la robustez, la escalabilidad y la capacidad de admitir cargas de trabajo de ML críticas para la misión. Se encarga de todo, desde la validación y el preprocesamiento de datos hasta la implementación y el monitoreo del modelo, asegurando que los modelos estén listos para la producción y puedan ofrecer un rendimiento confiable a gran escala.
- Flujos de trabajo de extremo a extremo: TFX proporciona componentes extensos para manejar varias etapas del ciclo de vida de ML. Con soporte para la ingestión de datos, la transformación, el entrenamiento del modelo, la validación y el servicio, TFX permite a los usuarios construir tuberías de extremo a extremo que garantizan la reproducibilidad y consistencia de sus flujos de trabajo.
- Extensibilidad: Los componentes de TFX son personalizables y permiten a los usuarios crear e integrar sus propios componentes si es necesario. Esta extensibilidad permite a las organizaciones adaptar TFX a sus requisitos específicos, incorporar sus herramientas preferidas o implementar soluciones personalizadas para desafíos únicos que puedan encontrar en sus flujos de trabajo de ML.
Sin embargo, vale la pena señalar que el enfoque principal de TFX en TensorFlow puede ser una limitación para las organizaciones que dependen de otros frameworks de ML o prefieren una solución más agnóstica del lenguaje. Si bien TFX ofrece una plataforma potente y completa para cargas de trabajo basadas en TensorFlow, los usuarios que trabajan con frameworks como PyTorch o Scikit-learn pueden considerar otras herramientas de MLOps que se adapten mejor a sus requisitos. La sólida integración de TensorFlow, la preparación para la producción y los componentes extensibles hacen de TFX una plataforma atractiva para organizaciones que están fuertemente invertidas en el ecosistema de TensorFlow. Las organizaciones pueden evaluar la compatibilidad de sus herramientas y frameworks actuales y decidir si las características de TFX se alinean bien con sus casos de uso y necesidades específicas en la gestión de sus flujos de trabajo de ML.
MetaFlow
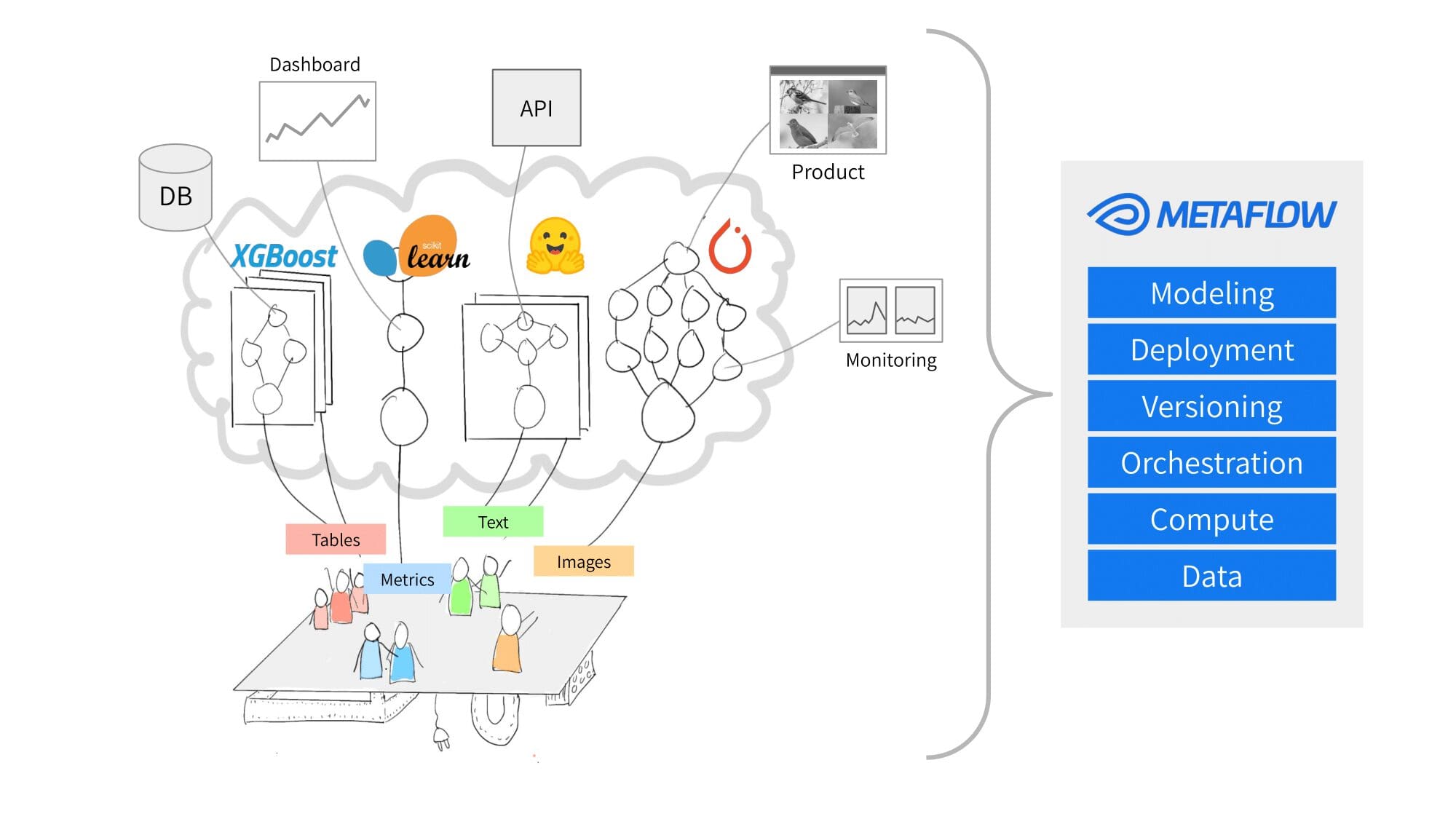
Metaflow es una plataforma de MLOps desarrollada por Netflix, diseñada para agilizar y simplificar proyectos complejos de ciencia de datos del mundo real. Metaflow destaca en varios aspectos debido a su enfoque en el manejo de proyectos complejos de ciencia de datos y la simplificación de flujos de trabajo de ML. Aquí hay algunas áreas en las que Metaflow sobresale:
- Gestión de flujos de trabajo: La principal fortaleza de Metaflow radica en la gestión efectiva de flujos de trabajo de ML complejos del mundo real. Los usuarios pueden diseñar, organizar y ejecutar pasos de procesamiento y entrenamiento de modelos intrincados con versionado incorporado, gestión de dependencias y un lenguaje específico del dominio basado en Python.
- Observabilidad: Metaflow proporciona funcionalidad para observar las entradas y salidas después de cada paso del pipeline, lo que facilita el seguimiento de los datos en varias etapas del pipeline.
- Escalabilidad: Metaflow escala fácilmente los flujos de trabajo desde entornos locales hasta la nube y tiene una integración estrecha con servicios de AWS como AWS Batch, S3 y Step Functions. Esto permite a los usuarios ejecutar e implementar sus cargas de trabajo a gran escala sin preocuparse por los recursos subyacentes.
- Gestión de datos incorporada: Metaflow proporciona herramientas para la gestión eficiente de datos y el versionado al realizar un seguimiento automático de los conjuntos de datos utilizados por los flujos de trabajo. Garantiza la consistencia de los datos en diferentes ejecuciones del pipeline y permite a los usuarios acceder a datos y artefactos históricos, lo que contribuye a la reproducibilidad y experimentación confiable.
- Tolerancia a fallos y resiliencia: Metaflow está diseñado para manejar los desafíos que surgen en proyectos de ML del mundo real, como fallas inesperadas, restricciones de recursos y cambios en los requisitos. Ofrece funciones como manejo automático de errores, mecanismos de reintento y la capacidad de reanudar pasos fallidos o detenidos, lo que garantiza que los flujos de trabajo se puedan ejecutar de manera confiable y eficiente en diversas situaciones.
- Integración con AWS: Como Netflix desarrolló Metaflow, se integra estrechamente con la infraestructura de Amazon Web Services (AWS). Esto facilita significativamente a los usuarios que ya están invertidos en el ecosistema de AWS aprovechar los recursos y servicios de AWS existentes en sus cargas de trabajo de ML gestionadas por Metaflow. Esta integración permite un almacenamiento de datos, recuperación, procesamiento y control de acceso sin problemas a los recursos de AWS, lo que agiliza aún más la gestión de flujos de trabajo de ML.
Aunque Metaflow tiene varias fortalezas, hay áreas en las que puede ser limitado o quedarse corto en comparación con otras herramientas de MLOps:
- Soporte Limitado para Deep Learning: Metaflow fue desarrollado inicialmente para enfocarse en flujos de trabajo típicos de ciencia de datos y métodos de aprendizaje automático tradicionales en lugar de deep learning. Esto podría hacerlo menos adecuado para equipos o proyectos que trabajen principalmente con frameworks de deep learning como TensorFlow o PyTorch.
- Seguimiento de Experimentos: Metaflow ofrece algunas funcionalidades de seguimiento de experimentos. Su enfoque en la gestión de flujos de trabajo y la simplicidad de la infraestructura podrían hacer que sus capacidades de seguimiento sean menos completas que las de plataformas dedicadas de seguimiento de experimentos como MLflow o Weights & Biases.
- Orquestación Nativa de Kubernetes: Metaflow es una plataforma versátil que puede implementarse en varias soluciones de backend, como AWS Batch y sistemas de orquestación de contenedores. Sin embargo, carece de la orquestación de pipelines nativa de Kubernetes que se encuentra en herramientas como Kubeflow, que permite ejecutar pipelines de aprendizaje automático completos como recursos de Kubernetes.
- Soporte de Lenguajes: Metaflow principalmente soporta Python, lo cual es ventajoso para la mayoría de los practicantes de ciencia de datos, pero podría ser una limitación para equipos que utilizan otros lenguajes de programación como R o Java en sus proyectos de aprendizaje automático.
ZenML
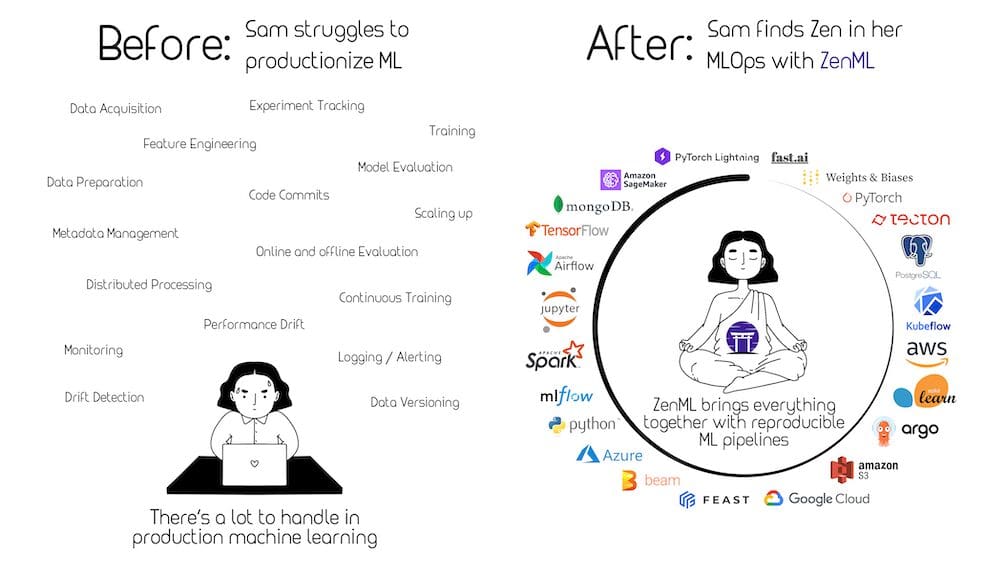
ZenML es un marco de trabajo de MLOps extensible y de código abierto diseñado para hacer que el aprendizaje automático sea reproducible, mantenible y escalable. ZenML está diseñado para ser un marco de trabajo de MLOps altamente extensible y adaptable. Su principal propuesta de valor es que te permite integrar y “pegar” fácilmente diversos componentes, bibliotecas y frameworks de aprendizaje automático para construir pipelines de extremo a extremo. El diseño modular de ZenML facilita que los científicos de datos e ingenieros puedan combinar diferentes frameworks y herramientas de aprendizaje automático para tareas específicas dentro del pipeline, reduciendo la complejidad de integrar diversas herramientas y frameworks.
Aquí hay algunas áreas en las que ZenML sobresale:
- Abstracción de Pipelines de Aprendizaje Automático: ZenML ofrece una forma limpia y pythonica de definir pipelines de aprendizaje automático utilizando abstracciones simples, lo que facilita la creación y gestión de diferentes etapas del ciclo de vida del aprendizaje automático, como la ingestión de datos, el preprocesamiento, el entrenamiento y la evaluación.
- Reproducibilidad: ZenML enfatiza fuertemente la reproducibilidad, asegurando que los componentes del pipeline sean versionados y rastreados a través de un sistema de metadatos preciso. Esto garantiza que los experimentos de aprendizaje automático se puedan replicar de manera consistente, evitando problemas relacionados con entornos inestables, datos o dependencias.
- Integración con Orquestadores de Backend: ZenML admite diferentes orquestadores de backend, como Apache Airflow, Kubeflow y otros. Esta flexibilidad permite a los usuarios elegir el backend que mejor se adapte a sus necesidades e infraestructura, ya sea gestionando pipelines en sus máquinas locales, Kubernetes o un entorno en la nube.
- Extensibilidad: ZenML ofrece una arquitectura altamente extensible que permite a los usuarios escribir lógica personalizada para diferentes pasos del pipeline e integrarse fácilmente con sus herramientas o bibliotecas preferidas. Esto permite a las organizaciones adaptar ZenML a sus requisitos y flujos de trabajo específicos.
- Versionado de Conjuntos de Datos: ZenML se centra en la gestión y versionado eficientes de datos, asegurando que los pipelines tengan acceso a las versiones correctas de datos y artefactos. Este sistema de gestión de datos incorporado permite a los usuarios mantener la consistencia de los datos en diferentes ejecuciones del pipeline y fomenta la transparencia en los flujos de trabajo de aprendizaje automático.
- Alta Integración con Frameworks de Aprendizaje Automático: ZenML se integra fácilmente con frameworks populares de aprendizaje automático, como TensorFlow, PyTorch y Scikit-learn. Su capacidad para trabajar con estas bibliotecas de aprendizaje automático permite a los practicantes aprovechar sus habilidades y herramientas existentes mientras utilizan la gestión de pipelines de ZenML.
En resumen, ZenML destaca al proporcionar una abstracción limpia de pipelines, fomentar la reproducibilidad, admitir varios orquestadores de backend, ofrecer extensibilidad, mantener un versionado eficiente de conjuntos de datos e integrarse con bibliotecas populares de aprendizaje automático. Su enfoque en estos aspectos hace que ZenML sea particularmente adecuado para organizaciones que buscan mejorar la mantenibilidad, reproducibilidad y escalabilidad de sus flujos de trabajo de aprendizaje automático sin cambiar demasiado su infraestructura.
¿Cuál es la Herramienta Correcta Para Mí?
Con tantas herramientas de MLOps disponibles, ¿cómo sabes cuál es la adecuada para ti y tu equipo? Al evaluar posibles soluciones de MLOps, entran en juego varios factores. Aquí hay algunos aspectos clave a considerar al elegir herramientas de MLOps adaptadas a las necesidades y objetivos específicos de tu organización:
- Tamaño de la Organización y Estructura del Equipo: Considera el tamaño de tus equipos de ciencia de datos e ingeniería, su nivel de experiencia y el grado de colaboración necesario. Grupos más grandes o estructuras jerárquicas más complejas pueden beneficiarse de herramientas con sólidas características de colaboración y comunicación.
- Complejidad y Diversidad de los Modelos de ML: Evalúa la variedad de algoritmos, arquitecturas de modelos y tecnologías utilizadas en tu organización. Algunas herramientas de MLOps se adaptan a frameworks o bibliotecas específicas, mientras que otras ofrecen un soporte más amplio y versátil.
- Nivel de Automatización y Escalabilidad: Determina el grado de automatización que necesitas para tareas como el preprocesamiento de datos, entrenamiento de modelos, implementación y monitoreo. Además, comprende la importancia de la escalabilidad en tu organización, ya que algunas herramientas de MLOps brindan un mejor soporte para ampliar los cálculos y manejar grandes cantidades de datos.
- Integración y Compatibilidad: Considera la compatibilidad de las herramientas de MLOps con tu infraestructura, pila tecnológica y flujos de trabajo existentes. Una integración fluida con tus sistemas actuales garantizará un proceso de adopción más sencillo y minimizará las interrupciones en los proyectos en curso.
- Personalización y Extensibilidad: Evalúa el nivel de personalización y extensibilidad necesario para tus flujos de trabajo de ML, ya que algunas herramientas ofrecen APIs más flexibles o arquitecturas de complementos que permiten crear componentes personalizados para satisfacer requisitos específicos.
- Costo y Licencia: Ten en cuenta las estructuras de precios y opciones de licencia de las herramientas de MLOps, asegurándote de que se ajusten al presupuesto y restricciones de recursos de tu organización.
- Seguridad y Cumplimiento: Evalúa cómo las herramientas de MLOps abordan la seguridad, privacidad de los datos y requisitos de cumplimiento. Esto es especialmente importante para organizaciones que operan en industrias reguladas o que manejan datos sensibles.
- Soporte y Comunidad: Considera la calidad de la documentación, el soporte de la comunidad y la disponibilidad de asistencia profesional cuando sea necesario. Las comunidades activas y el soporte receptivo pueden ser valiosos al enfrentar desafíos o buscar mejores prácticas.
Examinando cuidadosamente estos factores y alineándolos con las necesidades y objetivos de tu organización, puedes tomar decisiones informadas al seleccionar herramientas de MLOps que mejor respalden tus flujos de trabajo de ML y permitan una estrategia de MLOps exitosa.
Mejores Prácticas de MLOps
Establecer mejores prácticas en MLOps es crucial para las organizaciones que buscan desarrollar, implementar y mantener modelos de ML de alta calidad que generen valor e impacten positivamente los resultados comerciales. Al implementar las siguientes prácticas, las organizaciones pueden asegurarse de que sus proyectos de ML sean eficientes, colaborativos y sostenibles, al tiempo que minimizan el riesgo de posibles problemas derivados de datos inconsistentes, modelos desactualizados o desarrollo lento y propenso a errores:
- Garantizar la calidad y consistencia de los datos: Establecer pipelines de preprocesamiento robustos, utilizar herramientas para verificar automáticamente la calidad de los datos como Great Expectations o TensorFlow Data Validation, e implementar políticas de gobierno de datos que definan el almacenamiento, acceso y reglas de procesamiento de los datos. La falta de control de calidad de los datos puede llevar a resultados inexactos o sesgados en los modelos, lo que provoca una toma de decisiones deficiente y posibles pérdidas comerciales.
- Control de versiones para datos y modelos: Utilizar sistemas de control de versiones como Git o DVC para rastrear los cambios realizados en los datos y modelos, mejorando la colaboración y reduciendo la confusión entre los miembros del equipo. Por ejemplo, DVC puede gestionar diferentes versiones de conjuntos de datos y experimentos de modelos, permitiendo cambios, compartición y reproducción sencilla. Con el control de versiones, los equipos pueden gestionar múltiples iteraciones y reproducir resultados pasados para su análisis.
- Flujos de trabajo colaborativos y reproducibles: Fomentar la colaboración mediante la implementación de una documentación clara, procesos de revisión de código, gestión de datos estandarizada y herramientas y plataformas colaborativas como Jupyter Notebooks y Saturn Cloud. Apoyar a los miembros del equipo para que trabajen juntos de manera eficiente y efectiva ayuda a acelerar el desarrollo de modelos de alta calidad. Por otro lado, ignorar flujos de trabajo colaborativos y reproducibles resulta en un desarrollo más lento, un mayor riesgo de errores y una compartición de conocimientos obstaculizada.
- Pruebas y validación automatizadas: Adoptar una estrategia de pruebas rigurosa mediante la integración de técnicas de pruebas y validación automatizadas (por ejemplo, pruebas unitarias con Pytest, pruebas de integración) en tu pipeline de ML, aprovechando herramientas de integración continua como GitHub Actions o Jenkins para probar regularmente la funcionalidad del modelo. Las pruebas automatizadas ayudan a identificar y solucionar problemas antes de la implementación, asegurando un rendimiento del modelo de alta calidad y confiable en producción. Saltarse las pruebas automatizadas aumenta el riesgo de problemas no detectados, comprometiendo el rendimiento del modelo y, en última instancia, perjudicando los resultados comerciales.
- Sistemas de monitoreo y alerta: Utilizar herramientas como Amazon SageMaker Model Monitor, MLflow o soluciones personalizadas para rastrear métricas clave de rendimiento y configurar alertas para detectar posibles problemas de manera temprana. Por ejemplo, configurar alertas en MLflow cuando se detecte deriva en el modelo o se superen umbrales de rendimiento específicos. No implementar sistemas de monitoreo y alerta retrasa la detección de problemas como la deriva del modelo o la degradación del rendimiento, lo que resulta en decisiones subóptimas basadas en predicciones de modelos desactualizadas o inexactas, afectando negativamente el rendimiento comercial en general.
Al adherirse a estas mejores prácticas de MLOps, las organizaciones pueden desarrollar, implementar y mantener modelos de ML de manera eficiente, minimizando posibles problemas y maximizando la efectividad del modelo y el impacto general en el negocio.
La seguridad de los datos desempeña un papel vital en la implementación exitosa de MLOps. Las organizaciones deben tomar las precauciones necesarias para garantizar que sus datos y modelos permanezcan seguros y protegidos en cada etapa del ciclo de vida de ML. Las consideraciones críticas para garantizar la seguridad de los datos en MLOps incluyen:
– Robustez del modelo: Asegúrese de que sus modelos de ML puedan resistir ataques adversarios o funcionar de manera confiable en condiciones ruidosas o inesperadas. Por ejemplo, puede incorporar técnicas como el entrenamiento adversarial, que consiste en inyectar ejemplos adversarios en el proceso de entrenamiento para aumentar la resistencia del modelo contra ataques maliciosos. Evaluar regularmente la robustez del modelo ayuda a prevenir posibles explotaciones que podrían llevar a predicciones incorrectas o fallas del sistema.
– Privacidad y cumplimiento de datos: Para proteger los datos confidenciales, las organizaciones deben cumplir con las regulaciones relevantes de privacidad y cumplimiento de datos, como el Reglamento General de Protección de Datos (GDPR) o la Ley de Portabilidad y Responsabilidad del Seguro Médico (HIPAA). Esto puede implicar la implementación de políticas sólidas de gobierno de datos, anonimizar información sensible o utilizar técnicas como el enmascaramiento de datos o la pseudonimización.
– Seguridad e integridad del modelo: Garantizar la seguridad e integridad de los modelos de ML ayuda a protegerlos contra accesos no autorizados, manipulación o robo. Las organizaciones pueden implementar medidas como la encriptación de artefactos del modelo, almacenamiento seguro y firma del modelo para validar la autenticidad, minimizando así el riesgo de compromiso o manipulación por parte de terceros.
– Implementación segura y control de acceso: Al implementar modelos de ML en entornos de producción, las organizaciones deben seguir las mejores prácticas para una implementación rápida. Esto incluye identificar y solucionar posibles vulnerabilidades, implementar canales de comunicación seguros (por ejemplo, HTTPS o TLS) y aplicar mecanismos estrictos de control de acceso para restringir el acceso al modelo solo a usuarios autorizados. Las organizaciones pueden prevenir el acceso no autorizado y mantener la seguridad del modelo utilizando el control de acceso basado en roles y protocolos de autenticación como OAuth o SAML.
Involucrar a equipos de seguridad, como equipos de pruebas de seguridad (red teams), en el ciclo de MLOps también puede mejorar significativamente la seguridad general del sistema. Los equipos de pruebas de seguridad, por ejemplo, pueden simular ataques adversarios a modelos e infraestructura, ayudando a identificar vulnerabilidades y debilidades que de otra manera podrían pasar desapercibidas. Este enfoque de seguridad proactivo permite a las organizaciones abordar los problemas antes de que se conviertan en amenazas, garantizando el cumplimiento de las regulaciones y mejorando la confiabilidad y confiabilidad de sus soluciones de ML. Colaborar con equipos de seguridad dedicados durante el ciclo de MLOps fomenta una cultura de seguridad sólida que en última instancia contribuye al éxito de los proyectos de ML.
MLOps se ha implementado con éxito en diversas industrias, impulsando mejoras significativas en eficiencia, automatización y rendimiento general del negocio. A continuación, se presentan ejemplos del mundo real que muestran el potencial y la efectividad de MLOps en diferentes sectores:
– Salud con CareSource: CareSource es uno de los proveedores de Medicaid más grandes de Estados Unidos, enfocándose en la clasificación de embarazos de alto riesgo y colaborando con proveedores médicos para brindar atención obstétrica salvadora de vidas de manera proactiva. Sin embargo, se necesitaba resolver algunos problemas relacionados con los datos. Los datos de CareSource estaban aislados en diferentes sistemas y no siempre estaban actualizados, lo que dificultaba su acceso y análisis. En cuanto al entrenamiento del modelo, los datos no siempre estaban en un formato consistente, lo que dificultaba su limpieza y preparación para el análisis.
Para abordar estos desafíos, CareSource implementó un marco de MLOps que utiliza Databricks Feature Store, MLflow e Hyperopt para desarrollar, ajustar y rastrear modelos de ML para predecir el riesgo obstétrico. Luego utilizaron Stacks para ayudar a crear una plantilla lista para producción para la implementación y enviar resultados de predicción según un cronograma oportuno a los socios médicos.
La transición acelerada entre el desarrollo de ML y la implementación lista para producción permitió a CareSource impactar directamente la salud y la vida de los pacientes antes de que fuera demasiado tarde. Por ejemplo, CareSource identificó embarazos de alto riesgo antes, lo que llevó a mejores resultados para las madres y los bebés. También redujeron el costo de la atención al prevenir hospitalizaciones innecesarias.
– Finanzas con Moody’s Analytics: Moody’s Analytics, líder en modelado financiero, se encontró con desafíos como acceso limitado a herramientas e infraestructura, fricciones en el desarrollo y entrega de modelos y silos de conocimiento en equipos distribuidos. Desarrollaron y utilizaron modelos de ML para diversas aplicaciones, incluida la evaluación del riesgo crediticio y el análisis de estados financieros. En respuesta a estos desafíos, implementaron la plataforma de ciencia de datos Domino para agilizar su flujo de trabajo de principio a fin y permitir una colaboración eficiente entre los científicos de datos.
Al aprovechar Domino, Moody’s Analytics aceleró el desarrollo de modelos, redujo un proyecto de nueve meses a cuatro meses y mejoró significativamente sus capacidades de monitoreo de modelos. Esta transformación permitió a la empresa desarrollar y entregar de manera eficiente modelos personalizados de alta calidad para las necesidades de los clientes, como la evaluación de riesgos y el análisis financiero.
Entretenimiento con Netflix
Netflix utilizó Metaflow para agilizar el desarrollo, despliegue y gestión de cargas de trabajo de aprendizaje automático para diversas aplicaciones, como recomendaciones de contenido personalizado, optimización de experiencias de transmisión, pronóstico de demanda de contenido y análisis de sentimientos para el compromiso en las redes sociales. Al fomentar prácticas eficientes de MLOps y adaptar un marco centrado en el ser humano para sus flujos de trabajo internos, Netflix permitió a sus científicos de datos experimentar e iterar rápidamente, lo que condujo a una práctica de ciencia de datos más ágil y efectiva.
Según Ville Tuulos, un exgerente de infraestructura de aprendizaje automático en Netflix, la implementación de Metaflow redujo el tiempo promedio desde la idea del proyecto hasta la implementación de cuatro meses a solo una semana. Este flujo de trabajo acelerado resalta el impacto transformador de MLOps y la infraestructura de aprendizaje automático dedicada, lo que permite que los equipos de aprendizaje automático operen de manera más rápida y eficiente. Al integrar el aprendizaje automático en diversos aspectos de su negocio, Netflix muestra el valor y el potencial de las prácticas de MLOps para revolucionar industrias y mejorar las operaciones comerciales en general, brindando una ventaja sustancial a las empresas de ritmo acelerado.
Lecciones aprendidas de MLOps
Como hemos visto en los casos mencionados anteriormente, la implementación exitosa de MLOps demostró cómo las prácticas efectivas de MLOps pueden impulsar mejoras sustanciales en diferentes aspectos del negocio. Gracias a las lecciones aprendidas de experiencias del mundo real como esta, podemos obtener ideas clave sobre la importancia de MLOps para las organizaciones:
- Estandarización, APIs unificadas y abstracciones para simplificar el ciclo de vida del aprendizaje automático.
- Integración de múltiples herramientas de aprendizaje automático en un marco coherente único para agilizar los procesos y reducir la complejidad.
- Abordar problemas críticos como la reproducibilidad, la versión y el seguimiento de experimentos para mejorar la eficiencia y la colaboración.
- Desarrollar un marco centrado en el ser humano que se adapte a las necesidades específicas de los científicos de datos, reduciendo la fricción y fomentando la experimentación y la iteración rápidas.
- Monitorear modelos en producción y mantener bucles de retroalimentación adecuados para garantizar que los modelos sigan siendo relevantes, precisos y efectivos.
Las lecciones de Netflix y otras implementaciones de MLOps del mundo real pueden proporcionar ideas valiosas a las organizaciones que buscan mejorar sus propias capacidades de aprendizaje automático. Enfatizan la importancia de tener una estrategia bien pensada e invertir en prácticas robustas de MLOps para desarrollar, implementar y mantener modelos de aprendizaje automático de alta calidad que generen valor mientras se escalan y se adaptan a las necesidades comerciales en constante evolución.
Tendencias futuras y desafíos en MLOps
A medida que MLOps continúa evolucionando y madurando, las organizaciones deben estar al tanto de las tendencias emergentes y los desafíos que pueden enfrentar al implementar prácticas de MLOps. Algunas tendencias destacadas y posibles obstáculos incluyen:
- Edge Computing: El auge de la informática en el borde presenta oportunidades para que las organizaciones implementen modelos de aprendizaje automático en dispositivos periféricos, lo que permite una toma de decisiones más rápida y localizada, reduce la latencia y disminuye los costos de ancho de banda. La implementación de MLOps en entornos de informática en el borde requiere nuevas estrategias para el entrenamiento, despliegue y monitoreo de modelos, teniendo en cuenta los recursos limitados del dispositivo, la seguridad y las limitaciones de conectividad.
- Inteligencia Artificial Explicable: A medida que los sistemas de IA desempeñan un papel más importante en los procesos y la toma de decisiones diarios, las organizaciones deben asegurarse de que sus modelos de aprendizaje automático sean explicables, transparentes y imparciales. Esto requiere la integración de herramientas para la interpretabilidad del modelo, la visualización y técnicas para mitigar el sesgo. La incorporación de principios de IA explicables y responsables en las prácticas de MLOps ayuda a aumentar la confianza de las partes interesadas, cumplir con los requisitos regulatorios y mantener los estándares éticos.
- Monitoreo y alerta sofisticados: A medida que aumenta la complejidad y la escala de los modelos de aprendizaje automático, las organizaciones pueden requerir sistemas de monitoreo y alerta más avanzados para mantener un rendimiento adecuado. La detección de anomalías, la retroalimentación en tiempo real y los umbrales de alerta adaptativos son algunas de las técnicas que pueden ayudar a identificar y diagnosticar rápidamente problemas como cambios en el modelo, degradación del rendimiento o problemas de calidad de datos. La integración de estas técnicas avanzadas de monitoreo y alerta en las prácticas de MLOps puede garantizar que las organizaciones puedan abordar proactivamente los problemas a medida que surjan y mantener niveles consistentemente altos de precisión y confiabilidad en sus modelos de aprendizaje automático.
- Aprendizaje Federado: Este enfoque permite entrenar modelos de aprendizaje automático en fuentes de datos descentralizadas mientras se mantiene la privacidad de los datos. Las organizaciones pueden beneficiarse del aprendizaje federado mediante la implementación de prácticas de MLOps para el entrenamiento distribuido y la colaboración entre múltiples partes interesadas sin exponer datos sensibles.
- Procesos en colaboración con los seres humanos: Existe un creciente interés en incorporar la experiencia humana en muchas aplicaciones de aprendizaje automático, especialmente aquellas que involucran toma de decisiones subjetivas o contextos complejos que no pueden ser completamente codificados. La integración de procesos en colaboración con los seres humanos dentro de los flujos de trabajo de MLOps requiere herramientas de colaboración efectivas y estrategias para combinar de manera fluida la inteligencia humana y la inteligencia artificial.
- Aprendizaje automático cuántico: La computación cuántica es un campo emergente que muestra potencial para resolver problemas complejos y acelerar procesos de aprendizaje automático específicos. A medida que esta tecnología madura, los marcos y herramientas de MLOps pueden necesitar evolucionar para adaptarse a los modelos de aprendizaje automático basados en la computación cuántica y manejar nuevos desafíos en la gestión de datos, entrenamiento e implementación.
- Robustez y resiliencia: Garantizar la robustez y resiliencia de los modelos de aprendizaje automático frente a circunstancias adversas, como entradas ruidosas o ataques maliciosos, es una preocupación creciente. Las organizaciones deberán incorporar estrategias y técnicas para el aprendizaje automático robusto en sus prácticas de MLOps para garantizar la seguridad y estabilidad de sus modelos. Esto puede incluir entrenamiento adversarial, validación de entrada o implementación de sistemas de monitoreo para identificar y alertar cuando los modelos encuentren entradas o comportamientos inesperados.
Conclusión
En el mundo actual, implementar MLOps se ha vuelto crucial para las organizaciones que buscan aprovechar todo el potencial del aprendizaje automático (ML), optimizar los flujos de trabajo y mantener modelos de alto rendimiento a lo largo de su ciclo de vida. Este artículo ha explorado las prácticas y herramientas de MLOps, los casos de uso en diversas industrias, la importancia de la seguridad de los datos y las oportunidades y desafíos futuros a medida que el campo continúa evolucionando.
Para resumir, hemos discutido lo siguiente:
- Las etapas del ciclo de vida de MLOps.
- Herramientas populares de MLOps de código abierto que se pueden implementar en la infraestructura de su elección.
- Las mejores prácticas para implementaciones de MLOps.
- Casos de uso de MLOps en diferentes industrias y valiosas lecciones aprendidas de MLOps.
- Tendencias y desafíos futuros, como la informática perimetral, la inteligencia artificial explicativa y responsable, y los procesos de colaboración humana.
A medida que el panorama de MLOps sigue evolucionando, las organizaciones y los profesionales deben mantenerse actualizados con las prácticas, herramientas e investigaciones más recientes. Enfatizar el aprendizaje continuo y la adaptación permitirá a las empresas mantenerse a la vanguardia, perfeccionar sus estrategias de MLOps y abordar de manera efectiva las tendencias y desafíos emergentes.
La naturaleza dinámica del ML y el ritmo rápido de la tecnología significa que las organizaciones deben estar preparadas para iterar y evolucionar con sus soluciones de MLOps. Esto implica adoptar nuevas técnicas y herramientas, fomentar una cultura de aprendizaje colaborativo dentro del equipo, compartir conocimientos y buscar ideas de la comunidad más amplia de MLOps.
Las organizaciones que adopten las mejores prácticas de MLOps, mantengan un fuerte enfoque en la seguridad de los datos y la IA ética, y sean ágiles en respuesta a las tendencias emergentes estarán en una mejor posición para maximizar el valor de sus inversiones en ML. A medida que las empresas de diferentes industrias aprovechen el ML, MLOps será cada vez más vital para garantizar la implementación exitosa, responsable y sostenible de soluciones impulsadas por la IA. Al adoptar una estrategia sólida y a prueba de futuro de MLOps, las organizaciones pueden desbloquear el verdadero potencial del ML y generar un cambio transformador en sus respectivos campos. Honson Tran está comprometido con el mejoramiento de la tecnología para la humanidad. Es una persona extremadamente curiosa que ama todo lo relacionado con la tecnología. Desde el desarrollo front-end hasta la inteligencia artificial y la conducción autónoma, me encanta todo. El objetivo principal al final del día para él es aprender tanto como pueda con la esperanza de participar a nivel global en la discusión sobre hacia dónde nos lleva la IA. Tiene más de 10 años de experiencia en TI, 5 años de experiencia en programación y una fuerza energética constante para sugerir e implementar nuevas ideas. Está casado para siempre con su trabajo. Ser el hombre más rico del cementerio no le importa. Lo que importa es acostarse por la noche sabiendo que ha contribuido algo nuevo a la tecnología cada día.
Original. Repostado con permiso.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 5 Cosas que Necesitas Saber al Construir Aplicaciones de Aprendizaje Automático
- Investigadores de la Universidad de Boston lanzan la familia Platypus de LLMs afinados para lograr un refinamiento económico, rápido y potente de los LLMs base.
- IBM y NASA se unen para crear Earth Science GPT Descifrando los misterios de nuestro planeta
- Reconocimiento del lenguaje hablado en Mozilla Common Voice Transformaciones de audio.
- Conoce a PUG una nueva investigación de IA de Meta AI sobre conjuntos de datos fotorrealistas y semánticamente controlables utilizando Unreal Engine para una evaluación de modelos robusta
- Investigadores de Salesforce presentan XGen-Image-1 un modelo de difusión latente de texto a imagen entrenado para reutilizar varios componentes preentrenados.
- Investigadores de UC Santa Cruz proponen una nueva herramienta de prueba de asociación de texto a imagen que cuantifica los estereotipos implícitos entre conceptos y valencia y los presentes en las imágenes






