Acelera el aprendizaje automático de grafos con GraphStorm Una nueva forma de resolver problemas en grafos a escala empresarial.
GraphStorm acelera el aprendizaje automático en grafos y resuelve problemas a escala empresarial.
Nos complace anunciar la publicación de GraphStorm 0.1 de código abierto, un marco de aprendizaje automático (ML) empresarial de gráficos de bajo código para construir, entrenar y desplegar soluciones de ML de gráficos en gráficos de escala empresarial complejos en días en lugar de meses. Con GraphStorm, puede construir soluciones que tengan en cuenta directamente la estructura de las relaciones o interacciones entre miles de millones de entidades, que están inherentemente incrustadas en la mayoría de los datos del mundo real, que incluyen escenarios de detección de fraude, recomendaciones, detección de comunidades y problemas de búsqueda/recuperación.
Hasta ahora, ha sido notoriamente difícil construir, entrenar y desplegar soluciones de ML de gráficos para gráficos empresariales complejos que fácilmente tienen miles de millones de nodos, cientos de miles de millones de bordes y docenas de atributos. Solo piense en un gráfico que capture los productos de Amazon.com, los atributos del producto, los clientes y más. Con GraphStorm, lanzamos las herramientas que Amazon usa internamente para llevar soluciones de ML de gráficos a gran escala a la producción. GraphStorm no requiere que seas un experto en ML de gráficos y está disponible bajo la licencia Apache v2.0 en GitHub. Para obtener más información sobre GraphStorm, visite el repositorio de GitHub.
En esta publicación, proporcionamos una introducción a GraphStorm, su arquitectura y un caso de uso de ejemplo de cómo usarlo.
Presentando GraphStorm
Los algoritmos de gráficos y el ML de gráficos están emergiendo como soluciones de vanguardia para muchos problemas empresariales importantes, como predecir riesgos de transacciones, anticipar las preferencias de los clientes, detectar intrusiones, optimizar las cadenas de suministro, análisis de redes sociales y predicción de tráfico. Por ejemplo, Amazon GuardDuty, el servicio de detección de amenazas nativo de AWS, utiliza un gráfico con miles de millones de bordes para mejorar la cobertura y precisión de su inteligencia de amenazas. Esto permite a GuardDuty categorizar los dominios previamente invisibles como altamente propensos a ser maliciosos o benignos según su asociación con dominios maliciosos conocidos. Al utilizar las Redes Neuronales de Gráficos (GNN), GuardDuty es capaz de mejorar su capacidad para alertar a los clientes.
- ¡Última oportunidad! ¡Los talleres certificados de IA comienzan en 24 horas! ¡No te lo pierdas!
- Indicadores de iluminación en pleno vuelo.
- ¿Qué es Bubble.io? Construye una aplicación sin experiencia en programación.
Sin embargo, desarrollar, lanzar y operar soluciones de ML de gráficos lleva meses y requiere experiencia en ML de gráficos. Como primer paso, un científico de ML de gráficos tiene que construir un modelo de ML de gráficos para un caso de uso dado utilizando un marco como la Biblioteca de Grafos Profundos (DGL). Entrenar dichos modelos es un desafío debido al tamaño y complejidad de los gráficos en aplicaciones empresariales, que rutinariamente alcanzan miles de millones de nodos, cientos de miles de millones de bordes, diferentes tipos de nodos y bordes y cientos de atributos de nodos y bordes. Los gráficos empresariales pueden requerir terabytes de almacenamiento de memoria, lo que requiere que los científicos de ML de gráficos construyan tuberías de entrenamiento complejas. Finalmente, después de que se haya entrenado un modelo, deben ser implementados para la inferencia, lo que requiere tuberías de inferencia que son tan difíciles de construir como las tuberías de entrenamiento.
GraphStorm 0.1 es un marco empresarial de ML de gráficos de bajo código que permite a los practicantes de ML elegir fácilmente modelos de ML de gráficos predefinidos que han demostrado ser efectivos, ejecutar entrenamiento distribuido en gráficos con miles de millones de nodos y desplegar los modelos en producción. GraphStorm ofrece una colección de modelos de ML de gráficos integrados, como Redes Convolucionales de Gráficos Relacionales (RGCN), Redes de Atención de Gráficos Relacionales (RGAT) y Transformador de Gráficos Heterogéneos (HGT) para aplicaciones empresariales con gráficos heterogéneos, lo que permite a los ingenieros de ML con poca experiencia en ML de gráficos probar diferentes soluciones de modelos para su tarea y seleccionar rápidamente la correcta. Las tuberías de entrenamiento y de inferencia distribuidas de extremo a extremo, que se escalan a gráficos empresariales de miles de millones de escala, hacen que sea fácil entrenar, desplegar y ejecutar inferencias. Si eres nuevo en GraphStorm o en ML de gráficos en general, te beneficiarás de los modelos y tuberías predefinidos. Si eres un experto, tienes todas las opciones para ajustar la tubería de entrenamiento y la arquitectura del modelo para obtener el mejor rendimiento. GraphStorm se construye sobre el DGL, un marco ampliamente popular para desarrollar modelos GNN, y se encuentra disponible como código de fuente de código abierto bajo la licencia Apache v2.0.
“GraphStorm está diseñado para ayudar a los clientes a experimentar y operacionalizar los métodos de ML de gráficos para las aplicaciones de la industria y acelerar la adopción de ML de gráficos”, dice George Karypis, científico principal senior en la investigación de Amazon AI / ML. “Desde su lanzamiento dentro de Amazon, GraphStorm ha reducido el esfuerzo para construir soluciones basadas en ML de gráficos hasta en cinco veces”.
“GraphStorm permite a nuestro equipo entrenar la incrustación GNN de manera auto supervisada en un gráfico con 288 millones de nodos y 2 mil millones de bordes”, dice Haining Yu, científico aplicado principal en Amazon Measurement, Ad Tech y Data Science. “Las incrustaciones GNN pre-entrenadas muestran una mejora del 24% en una tarea de predicción de actividad de comprador sobre una línea de base basada en BERT; también supera el rendimiento de referencia en otras aplicaciones de anuncios”.
“Antes de GraphStorm, los clientes solo podían escalar verticalmente para manejar gráficos de 500 millones de bordes”, dice Brad Bebee, GM de Amazon Neptune y Amazon Timestream. “GraphStorm permite a los clientes escalar el entrenamiento del modelo GNN en gráficos masivos de Amazon Neptune con decenas de miles de millones de bordes”.
Arquitectura técnica de GraphStorm
La siguiente figura muestra la arquitectura técnica de GraphStorm.

GraphStorm se construye sobre PyTorch y puede ejecutarse en una sola GPU, varias GPUs y varias máquinas GPU. Consiste en tres capas (marcadas en los cuadros amarillos en la figura anterior):
- Capa inferior (Dist GraphEngine) – La capa inferior proporciona los componentes básicos para permitir el aprendizaje de machine learning distribuido, incluyendo grafos distribuidos, tensores distribuidos, embeddings distribuidos y samplers distribuidos. GraphStorm proporciona implementaciones eficientes de estos componentes para escalar el entrenamiento de machine learning de grafos de miles de millones de nodos.
- Capa intermedia (GS training/inference pipeline) – La capa intermedia proporciona entrenadores, evaluadores y predictores para simplificar el entrenamiento e inferencia de modelos tanto para modelos integrados como para modelos personalizados. Básicamente, mediante el uso de la API de esta capa, puede centrarse en el desarrollo del modelo sin preocuparse por cómo escalar el entrenamiento del modelo.
- Capa superior (GS general model zoo) – La capa superior es un modelo zoo con modelos GNN y no-GNN populares para diferentes tipos de grafos. A partir de esta escritura, proporciona RGCN, RGAT y HGT para grafos heterogéneos y BERTGNN para grafos textuales. En el futuro, agregaremos soporte para modelos de gráficos temporales como TGAT para gráficos temporales, así como TransE y DistMult para gráficos de conocimiento.
Cómo utilizar GraphStorm
Después de instalar GraphStorm, solo necesitas tres pasos para construir y entrenar modelos GML para tu aplicación.
Primero, preprocesas tus datos (potencialmente incluyendo tu propia ingeniería de características) y los transformas en un formato de tabla requerido por GraphStorm. Para cada tipo de nodo, defines una tabla que enumera todos los nodos de ese tipo y sus características, proporcionando un ID único para cada nodo. Para cada tipo de borde, de manera similar defines una tabla en la que cada fila contiene los IDs de nodo de origen y destino para un borde de ese tipo (para obtener más información, consulte el tutorial Use Your Own Data). Además, proporcionas un archivo JSON que describe la estructura general del gráfico.
Segundo, a través de la interfaz de línea de comandos (CLI), utilizas el componente construct_graph integrado de GraphStorm para un procesamiento de datos específico de GraphStorm, que permite un entrenamiento y una inferencia distribuidos eficientes.
Tercero, configuras el modelo y el entrenamiento en un archivo YAML (ejemplo) y, nuevamente usando la CLI, invocas uno de los cinco componentes integrados ( gs_node_classification, gs_node_regression, gs_edge_classification, gs_edge_regression, gs_link_prediction) como tuberías de entrenamiento para entrenar el modelo. Este paso da como resultado los artefactos del modelo entrenado. Para hacer inferencia, debes repetir los dos primeros pasos para transformar los datos de inferencia en un gráfico utilizando el mismo componente de GraphStorm (construct_graph) que antes.
Finalmente, puedes invocar uno de los cinco componentes integrados, el mismo que se usó para el entrenamiento del modelo, como una tubería de inferencia para generar embeddings o resultados de predicción.
El flujo general también se representa en la siguiente figura.
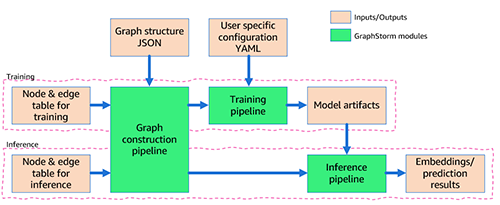
En la siguiente sección, proporcionamos un ejemplo de caso de uso.
Realizar predicciones sobre datos OAG en bruto
Para esta publicación, demostramos cómo GraphStorm puede permitir de manera fácil el entrenamiento e inferencia de machine learning de gráficos en un gran conjunto de datos en bruto. El Open Academic Graph (OAG) contiene cinco entidades (artículos, autores, lugares, afiliaciones y campos de estudio). El conjunto de datos en bruto se almacena en archivos JSON con más de 500 GB.
Nuestra tarea es construir un modelo para predecir el campo de estudio de un artículo. Para predecir el campo de estudio, puedes formularlo como una tarea de clasificación multietiqueta, pero es difícil usar la codificación one-hot para almacenar las etiquetas porque hay cientos de miles de campos. Por lo tanto, debes crear nodos de campo de estudio y formular este problema como una tarea de predicción de enlaces, prediciendo qué nodos de campo de estudio debe conectarse a un nodo de artículo.
Para modelar este conjunto de datos con un método gráfico, el primer paso es procesar el conjunto de datos y extraer entidades y relaciones. Puede extraer cinco tipos de relaciones de los archivos JSON para definir un gráfico, como se muestra en la siguiente figura. Puede utilizar el cuaderno Jupyter en el código de ejemplo de GraphStorm para procesar el conjunto de datos y generar cinco tablas de entidad para cada tipo de entidad y cinco tablas de relación para cada tipo de relación. El cuaderno Jupyter también genera incrustaciones BERT en las entidades con datos de texto, como los artículos.

Después de definir las entidades y relaciones entre las entidades, puede crear mag_bert.json, que define el esquema del gráfico, e invocar el pipeline de construcción de gráficos incorporado construct_graph en GraphStorm para construir el gráfico (ver el siguiente código). Aunque el pipeline de construcción de gráficos de GraphStorm se ejecuta en una sola máquina, admite el procesamiento multiproceso para procesar los nodos y las características de las relaciones en paralelo (--num_processes) y puede almacenar entidades y características de relaciones en memoria externa (--ext-mem-workspace) para escalar a conjuntos de datos grandes.
python3 -m graphstorm.gconstruct.construct_graph \
--num-processes 16 \
--output-dir /data/oagv2.1/mag_bert_constructed \
--graph-name mag --num-partitions 4 \
--skip-nonexist-edges \
--ext-mem-workspace /mnt/raid0/tmp_oag \
--ext-mem-feat-size 16 --conf-file mag_bert.jsonPara procesar un gráfico tan grande, necesita una instancia de CPU de gran memoria para construir el gráfico. Puede utilizar una instancia de Amazon Elastic Compute Cloud (Amazon EC2) r6id.32xlarge (128 vCPU y 1 TB de RAM) o r6a.48xlarge (192 vCPU y 1,5 TB de RAM) para construir el gráfico de OAG.
Después de construir un gráfico, puede utilizar gs_link_prediction para entrenar un modelo de predicción de enlaces en cuatro instancias g5.48xlarge. Cuando se utilizan los modelos incorporados, solo se invoca una línea de comando para iniciar el trabajo de entrenamiento distribuido. Ver el siguiente código:
python3 -m graphstorm.run.gs_link_prediction \
--num-trainers 8 \
--part-config /data/oagv2.1/mag_bert_constructed/mag.json \
--ip-config ip_list.txt \
--cf ml_lp.yaml \
--num-epochs 1 \
--save-model-path /data/mag_lp_modelDespués del entrenamiento del modelo, el artefacto del modelo se guarda en la carpeta /data/mag_lp_model.
Ahora puede ejecutar la inferencia de predicción de enlaces para generar incrustaciones GNN y evaluar el rendimiento del modelo. GraphStorm proporciona múltiples métricas de evaluación incorporadas para evaluar el rendimiento del modelo. Para problemas de predicción de enlaces, por ejemplo, GraphStorm genera automáticamente la métrica de rango reciproco medio (MRR). MRR es una métrica valiosa para evaluar modelos de predicción de enlaces de gráficos porque evalúa qué tan alto se clasifican los enlaces reales entre los enlaces predichos. Esto captura la calidad de las predicciones, asegurando que nuestro modelo priorice correctamente las conexiones verdaderas, que es nuestro objetivo aquí.
Puede ejecutar la inferencia con una línea de comando, como se muestra en el siguiente código. En este caso, el modelo alcanza un MRR de 0,31 en el conjunto de prueba del gráfico construido.
python3 -m graphstorm.run.gs_link_prediction \
--inference --num_trainers 8 \
--part-config /data/oagv2.1/mag_bert_constructed/mag.json \
--ip-config ip_list.txt \
--cf ml_lp.yaml \
--num-epochs 3 \
--save-embed-path /data/mag_lp_model/emb \
--restore-model-path /data/mag_lp_model/epoch-0/Tenga en cuenta que el pipeline de inferencia genera incrustaciones del modelo de predicción de enlaces. Para resolver el problema de encontrar el campo de estudio para cualquier artículo dado, simplemente realice una búsqueda de k-vecinos más cercanos en las incrustaciones.
Conclusión
GraphStorm es un nuevo marco de ML de gráficos que facilita la construcción, el entrenamiento y la implementación de modelos ML de gráficos en gráficos de la industria. Aborda algunos desafíos clave en ML de gráficos, incluida la escalabilidad y la facilidad de uso. Proporciona componentes incorporados para procesar gráficos de miles de millones de escala desde datos de entrada en bruto hasta el entrenamiento de modelos y la inferencia de modelos y ha permitido que varios equipos de Amazon entrenen modelos de ML de gráficos de última generación en diversas aplicaciones. Consulte nuestro repositorio de GitHub para obtener más información.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 7 Herramientas Sin Código Para Automatizar Tu Negocio
- Crea impresionantes códigos QR utilizando ControlNet AI.
- Link-credible Entra en el juego más rápido con la vinculación de cuentas de Steam, Epic Games Store y Ubisoft en GeForce NOW.
- Web LLM Trae los Chatbots de LLM al Navegador.
- 12 consejos y trucos de VSCode para el desarrollo en Python
- 4 Lecciones de carrera que me ayudaron a navegar en el difícil mercado laboral.
- ¿Qué tan difícil es ingresar a empresas FAANG?





