GPT vs BERT ¿Cuál es mejor?
GPT vs BERT ¿Cuál es mejor?
Comparación de dos modelos de lenguaje grandes: Enfoque y ejemplo

La creciente popularidad de la inteligencia artificial generativa también ha llevado a un aumento en el número de grandes modelos de lenguaje. En esta historia, haré una comparación entre dos de ellos: GPT y BERT. GPT (Transformador Generativo Pre-entrenado) es desarrollado por OpenAI y se basa en una arquitectura solo de decodificador. Por otro lado, BERT (Representaciones Bidireccionales de Codificadores a partir de Transformadores) es desarrollado por Google y es un modelo pre-entrenado solo de codificador.
Ambos son técnicamente diferentes, pero tienen un objetivo similar: realizar tareas de procesamiento de lenguaje natural. Muchos artículos los comparan desde un punto de vista técnico. Sin embargo, en esta historia, los compararé en función de la calidad de su objetivo, que es el procesamiento de lenguaje natural.
Enfoque de comparación
¿Cómo comparar dos arquitecturas técnicas completamente diferentes? GPT es una arquitectura solo de decodificador y BERT es una arquitectura solo de codificador. Por lo tanto, una comparación técnica de una arquitectura solo de decodificador versus una arquitectura solo de codificador es como comparar un Ferrari versus un Lamborghini: ambos son geniales pero con tecnología completamente diferente bajo el chasis.
Sin embargo, podemos hacer una comparación basada en la calidad de una tarea común de procesamiento de lenguaje natural que ambos pueden hacer, que es la generación de incrustaciones. Las incrustaciones son representaciones vectoriales de un texto. Las incrustaciones forman la base de cualquier tarea de procesamiento de lenguaje natural. Entonces, si podemos comparar la calidad de las incrustaciones, puede ayudarnos a juzgar la calidad de las tareas de procesamiento de lenguaje natural, ya que las incrustaciones son fundamentales para el procesamiento de lenguaje natural por arquitectura de transformador.
- Inmersión teórica profunda en la Regresión Lineal
- Conoce BITE Un Nuevo Método Que Reconstruye la Forma y Poses 3D de un Perro a Partir de una Imagen, Incluso con Poses Desafiantes como Sentado y Acostado.
- Conoce Paella Un Nuevo Modelo de IA Similar a Difusión que Puede Generar Imágenes de Alta Calidad Mucho Más Rápido que Usando Difusión Estable.
A continuación, se muestra el enfoque de comparación que tomaré.
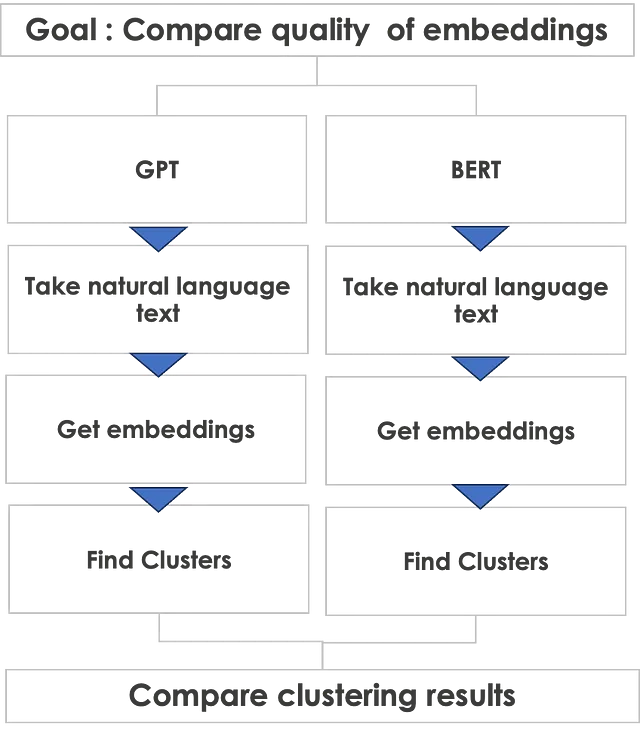
Comencemos con GPT
Hice una tirada de moneda y ¡GPT ganó la tirada! Así que comencemos con GPT primero. Tomaré texto del conjunto de datos de reseñas de alimentos finos de Amazon. Las reseñas son una buena manera de probar ambos modelos, ya que las reseñas se expresan en lenguaje natural y son muy espontáneas. Incluyen el sentimiento de los clientes y pueden contener todo tipo de idiomas: ¡buenos, malos, feos! Además, pueden tener muchas palabras mal escritas, emojis y jerga comúnmente utilizada.
A continuación se muestra un ejemplo del texto de la reseña.

Para obtener las incrustaciones del texto utilizando GPT, necesitamos hacer una llamada API a OpenAI. El resultado es una incrustación o vector de tamaño de 1540 para cada texto. Aquí hay un ejemplo de datos que incluye las incrustaciones.

El siguiente paso es la agrupación y visualización. Se puede usar KMeans para agrupar el vector de incrustación y usar TSNE para reducir las 1540 dimensiones a 2 dimensiones. A continuación, se muestran los resultados después de la agrupación y la reducción de dimensionalidad.
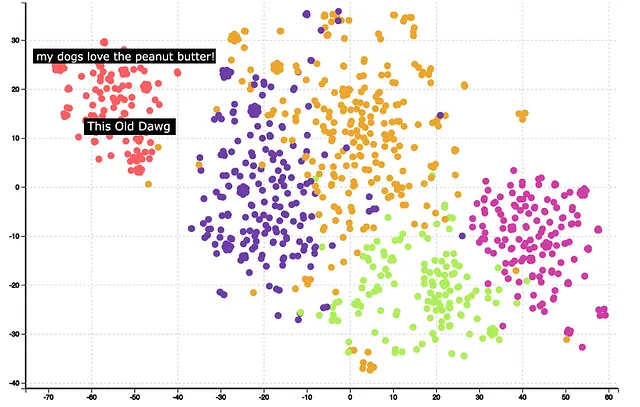
Se puede observar que los clusters están muy bien formados. Pasar el cursor sobre algunos de los clusters puede ayudar a entender el significado de los clusters. Por ejemplo, el cluster rojo está relacionado con la comida para perros. Un análisis adicional también muestra que los embeddings GPT han identificado correctamente que las palabras ‘Dog’ y ‘Dawg’ son similares y las ha colocado en el mismo cluster.
En general, los embeddings GPT dan buenos resultados como indica la calidad del clustering.
Ahora le toca a BERT
¿Puede BERT hacerlo mejor? Vamos a averiguarlo. Hay múltiples versiones del modelo BERT como bert-base-case, bert-base-uncased, etc. Esencialmente tienen diferentes tamaños de vector de embedding. Aquí está el resultado basado en Bert base que tiene un tamaño de embedding de 768.
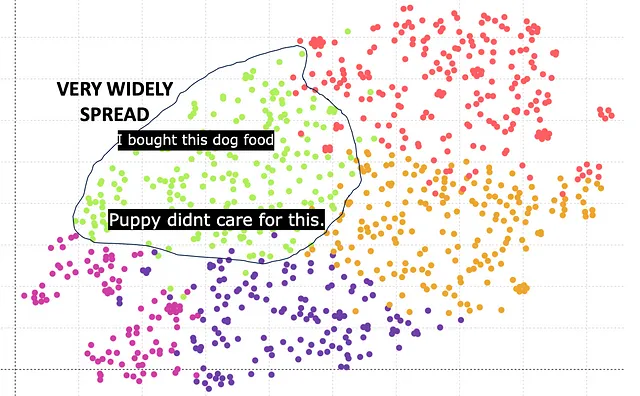
El cluster verde corresponde a la comida para perros. Sin embargo, se puede observar que los clusters están muy dispersos y no muy compactos en comparación con GPT. La razón principal es que la longitud del vector de embedding de 768 es inferior en comparación con la longitud del vector de embedding de 1540 de GPT.
Afortunadamente, BERT también ofrece un tamaño de embedding superior de 1024. Aquí están los resultados.
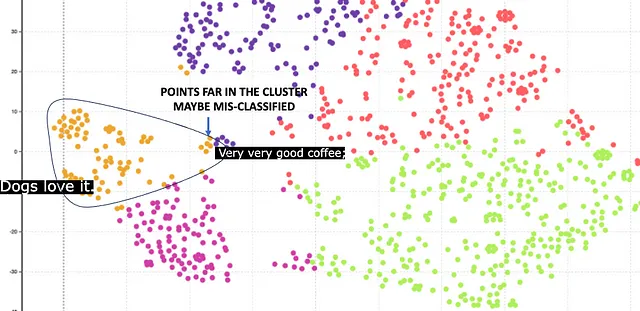
Aquí el cluster naranja corresponde a la comida para perros. El cluster es relativamente compacto, lo que es un resultado mejor en comparación con el embedding de 768. Sin embargo, hay algunos puntos que están lejos del centro. Estos puntos están clasificados incorrectamente. Por ejemplo, hay una reseña sobre café, pero se ha clasificado incorrectamente como comida para perros porque tiene la palabra ‘Dog’ en ella.
Conclusión
Claramente, GPT hace un mejor trabajo y proporciona embeddings de mayor calidad en comparación con BERT. Sin embargo, no me gustaría dar todo el crédito a GPT ya que hay otros aspectos en la comparación. Aquí hay una tabla resumen

GPT gana a BERT por la calidad del embedding proporcionada por el mayor tamaño de embedding. Sin embargo, GPT requiere una API de pago, mientras que BERT es gratuito. Además, el modelo BERT es de código abierto y no es una caja negra, por lo que se puede hacer un análisis adicional para entenderlo mejor. Los modelos GPT de OpenAI son cajas negras.
En conclusión, recomendaría usar BERT para textos complejos de Zepes como páginas web o libros que tengan un texto curado. GPT se puede utilizar para textos muy complejos como reseñas de clientes que están completamente en lenguaje natural y no están curados.
Implementación técnica
Aquí hay un fragmento de código de Python que implementa el proceso descrito en la historia. Para ilustrar, he dado un ejemplo de GPT. El de BERT es similar.
##Importar paquetesimportar openaiimportar pandas como pdimportar reimportar contextlibimportar ioimportar tiktokenfrom openai.embeddings_utils import get_embeddingfrom sklearn.cluster import KMeansfrom sklearn.manifold import TSNE##Leer datosfile_name = 'path_to_file'df = pd.read_csv(file_name)##Establecer parámetrosembedding_model = "text-embedding-ada-002"embedding_encoding = "cl100k_base" # este es el encoding para text-embedding-ada-002max_tokens = 8000 # el máximo para text-embedding-ada-002 es 8191top_n = 1000encoding = tiktoken.get_encoding(embedding_encoding)col_embedding = 'embedding'n_tsne=2n_iter = 1000##Obtiene el embedding de OpenAIdef get_embedding(text, model): openai.api_key = "YOUR_OPENAPI_KEY" text = text.replace("\n", " ") return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']col_txt = 'Reseña'df["n_tokens"] = df[col_txt].apply(lambda x: len(encoding.encode(x)))df = df[df.n_tokens <= max_tokens].tail(top_n)df = df[df.n_tokens > 0].reset_index(drop=True) ##Eliminar si no hay tokens, por ejemplo líneas en blanco.df[col_embedding] = df[col_txt].apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))matrix = np.array(df[col_embedding].to_list())##Hacer clusteringkmeans_model = KMeans(n_clusters=n_clusters,random_state=0)kmeans = kmeans_model.fit(matrix)kmeans_clusters = kmeans.predict(matrix)#TSNEtsne_model = TSNE(n_components=n_tsne, verbose=0, random_state=42, n_iter=n_iter,init='random')tsne_out = tsne_model.fit_transform(matrix)Cita del conjunto de datos
El conjunto de datos está disponible aquí con licencia CC0 Dominio público. Tanto el uso comercial como el no comercial está permitido .
Reseñas de alimentos de Amazon Fine
Analice ~500,000 reseñas de alimentos de Amazon
www.kaggle.com
Por favor, suscríbase para mantenerse informado cada vez que publique una nueva historia.
Reciba un correo electrónico cada vez que Pranay Dave publique.
Reciba un correo electrónico cada vez que Pranay Dave publique. Al registrarse, creará una cuenta de Zepes si aún no la tiene…
pranay-dave9.medium.com
También puede unirse a Zepes con mi enlace de referencia
Únase a Zepes con mi enlace de referencia – Pranay Dave
Como miembro de Zepes, una parte de su tarifa de membresía va a los escritores que lee y obtiene acceso completo a cada historia…
pranay-dave9.medium.com
Recursos adicionales
Sitio web
Puede visitar mi sitio web para realizar análisis sin codificación. https://experiencedatascience.com
Canal de Youtube
Por favor visite mi canal de YouTube para aprender casos de uso de ciencia de datos y AI utilizando demostraciones
Ciencia de datos demostrada
Aprenda ciencia de datos a través de demostraciones. Cualquiera que sea su profesión, siéntese, relájese y disfrute de los videos. Mi nombre es…
www.youtube.com
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Usando ChatGPT para Debugging Eficiente
- Científicos mejoran la detección de delirio utilizando Inteligencia Artificial y electroencefalogramas de respuesta rápida.
- Cómo Light & Wonder construyó una solución de mantenimiento predictivo para máquinas de juego en AWS.
- Revolucionando el descubrimiento de medicamentos modelo de aprendizaje automático identifica compuestos potenciales antienvejecimiento y allana el camino para futuros tratamientos de enfermedades complejas.
- De Sonido a Vista Conoce AudioToken para la Síntesis de Audio a Imagen.
- Red Cat y Athena AI crean drones militares inteligentes con visión nocturna.
- Todo lo que necesitas saber para construir tu primera aplicación de LLM





