GPT-4 8 Modelos en Uno; El Secreto ha Sido Revelado
GPT-4 8 en 1; Secreto Revelado
El modelo GPT4 ha sido el modelo revolucionario hasta ahora, disponible para el público en general tanto de forma gratuita como a través de su portal comercial (para uso en versión beta pública). Ha funcionado maravillas en el encendido de nuevas ideas de proyectos y casos de uso para muchos emprendedores, pero el secreto sobre el número de parámetros y el modelo estaba matando a todos los entusiastas que apostaban por el primer modelo de 1 billón de parámetros hasta las afirmaciones de 100 billones de parámetros.
El gato está fuera de la bolsa
Bueno, el gato está fuera de la bolsa (más o menos). El 20 de junio, George Hotz, fundador de la startup de conducción autónoma Comma.ai, filtró que GPT-4 no es un solo modelo denso monolítico (como GPT-3 y GPT-3.5), sino una mezcla de 8 modelos de 220 billones de parámetros.
- El informe de ganancias de NVIDIA revela dominio en la revolución de la IA
- Investigadores de Microsoft y la Universidad Bautista de Hong Kong presentan WizardCoder Un Code Evol-Instruct Fine-Tuned Code LLM.
- Microsoft presenta Python en Excel uniendo habilidades analíticas con familiaridad para mejorar la comprensión de los datos.
Más tarde ese día, Soumith Chintala, cofundador de PyTorch en Meta, confirmó la filtración.
Justo el día anterior, Mikhail Parakhin, líder de IA de Microsoft Bing, también insinuó esto.
GPT 4: No es un monolito
¿Qué significan todos los tweets? GPT-4 no es un solo modelo grande, sino una unión/ensamble de 8 modelos más pequeños que comparten la experiencia. Se rumorea que cada uno de estos modelos tiene 220 billones de parámetros.

La metodología se llama paradigmas de modelo de mezcla de expertos (enlace abajo). Es una metodología bien conocida también llamada hidra de modelo. Me recuerda a la mitología india, iré con Ravana.
Tómalo con un grano de sal ya que no es una noticia oficial, pero miembros significativamente importantes de la comunidad de IA han hablado/insinuado esto. Microsoft aún no ha confirmado ninguno de estos.
¿Qué es el paradigma de mezcla de expertos?
Ahora que hemos hablado sobre la mezcla de expertos, profundicemos un poco en qué es eso. La Mezcla de Expertos es una técnica de aprendizaje de conjunto desarrollada específicamente para redes neuronales. Difiere un poco de la técnica de conjunto general de la modelización de aprendizaje automático convencional (esa forma es una forma generalizada). Así que puedes considerar que la Mezcla de Expertos en LLMs es un caso especial para los métodos de conjunto.
En resumen, en este método, una tarea se divide en subtareas y se utilizan expertos para cada subtarea para resolver los modelos. Es una forma de enfoque de dividir y conquistar al crear árboles de decisión. Uno también podría considerarlo como aprendizaje automático en la parte superior de los modelos expertos para cada tarea separada.
Se puede entrenar un modelo más pequeño y mejor para cada sub-tarea o tipo de problema. Un meta-modelo aprende a usar qué modelo es mejor para predecir una tarea en particular. El meta-aprendiz/modelo actúa como un policía de tráfico. Las sub-tareas pueden o no pueden tener superposición, lo que significa que se pueden combinar las salidas para obtener la salida final.
Para las descripciones de conceptos de MOE a Pooling, todos los créditos al gran blog de Jason Brownlee (https://machinelearningmastery.com/mixture-of-experts/). Si te gusta lo que lees a continuación, por favor suscríbete al blog de Jason y compra uno o dos libros para apoyar su increíble trabajo.
Mixture of experts, MoE o ME para abreviar, es una técnica de aprendizaje de conjunto que implementa la idea de entrenar expertos en sub-tareas de un problema de modelado predictivo.
En la comunidad de redes neuronales, varios investigadores han examinado la metodología de descomposición. […] Metodología de mezcla de expertos (ME) que descompone el espacio de entrada, de modo que cada experto examina una parte diferente del espacio. […] Una red de control es responsable de combinar los diferentes expertos.
— Página 73, Clasificación de patrones utilizando métodos de conjunto, 2010.
Hay cuatro elementos en el enfoque, son:
- División de una tarea en sub-tareas.
- Desarrollar un experto para cada sub-tarea.
- Usar un modelo de control para decidir qué experto usar.
- Combinar las predicciones y la salida del modelo de control para hacer una predicción.
La figura a continuación, tomada de la página 94 del libro de 2012 “Métodos de Conjunto”, proporciona una descripción general útil de los elementos arquitectónicos del método.
¿Cómo funcionan los 8 modelos más pequeños en GPT4?
¡El secreto del “Modelo de Expertos” está revelado, entendamos por qué GPT4 es tan bueno!
ithinkbot.com
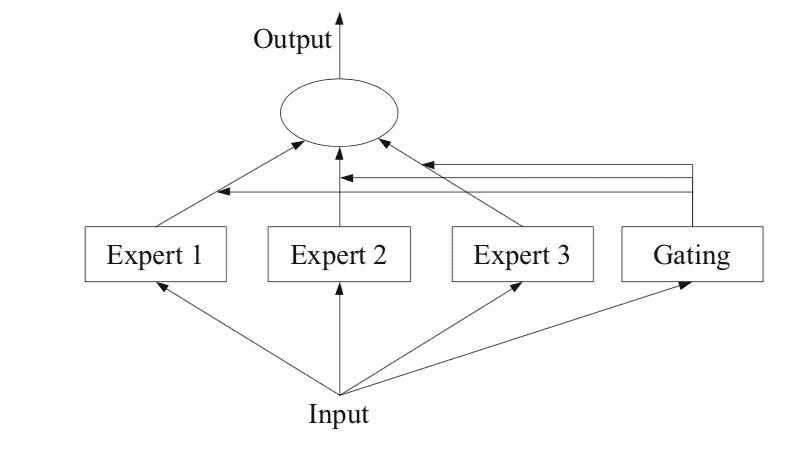
Subtareas
El primer paso es dividir el problema de modelado predictivo en subtareas. Esto a menudo implica el uso de conocimientos especializados. Por ejemplo, una imagen podría dividirse en elementos separados como fondo, primer plano, objetos, colores, líneas, y así sucesivamente.
… ME funciona con una estrategia de división y conquista donde una tarea compleja se divide en varias subtareas más simples y pequeñas, y se entrenan expertos individuales para diferentes subtareas.
— Página 94, Métodos de Conjunto, 2012.
Para aquellos problemas donde la división de la tarea en subtareas no es obvia, se podría utilizar un enfoque más simple y genérico. Por ejemplo, uno podría imaginar un enfoque que divide el espacio de características de entrada por grupos de columnas o separa ejemplos en el espacio de características basado en medidas de distancia, valores atípicos y valores normales para una distribución estándar, y mucho más.
… en ME, un problema clave es cómo encontrar la división natural de la tarea y luego derivar la solución general a partir de sub-soluciones.
— Página 94, Métodos de Conjunto, 2012.
Modelos de Expertos
A continuación, se diseña un experto para cada subtarea.
El enfoque de mezcla de expertos fue desarrollado y explorado inicialmente en el campo de las redes neuronales artificiales, por lo que tradicionalmente, los propios expertos son modelos de redes neuronales utilizados para predecir un valor numérico en el caso de regresión o una etiqueta de clase en el caso de clasificación.
Debería quedar claro que podemos “conectar” cualquier modelo al experto. Por ejemplo, podemos usar redes neuronales para representar tanto las funciones de compuertas como los expertos. El resultado se conoce como una red de densidad mixta.
— Página 344, Aprendizaje Automático: Una Perspectiva Probabilista, 2012.
Los expertos reciben cada uno el mismo patrón de entrada (fila) y hacen una predicción.
Modelo de Compuerta
Se utiliza un modelo para interpretar las predicciones realizadas por cada experto y ayudar a decidir en qué experto confiar para una entrada dada. Esto se llama modelo de compuerta, o red de compuertas, dado que tradicionalmente es un modelo de red neuronal.
La red de compuertas toma como entrada el patrón de entrada que se proporcionó a los modelos de expertos y produce la contribución que cada experto debe tener en la realización de una predicción para la entrada.
… los pesos determinados por la red de compuertas se asignan dinámicamente según la entrada dada, ya que el ME aprende efectivamente qué parte del espacio de características es aprendida por cada miembro del conjunto
— Página 16, Aprendizaje Automático de Conjunto, 2012.
La red de compuertas es clave para el enfoque y, efectivamente, el modelo aprende a elegir el subconjunto de tareas para una entrada dada y, a su vez, el experto en el que confiar para realizar una predicción sólida.
La mezcla de expertos también se puede ver como un algoritmo de selección de clasificadores, donde los clasificadores individuales se entrenan para convertirse en expertos en alguna parte del espacio de características.
— Página 16, Aprendizaje Automático de Conjunto, 2012.
Cuando se utilizan modelos de redes neuronales, la red de compuertas y los expertos se entrenan juntos de manera que la red de compuertas aprende cuándo confiar en cada experto para hacer una predicción. Este procedimiento de entrenamiento se implementaba tradicionalmente utilizando la maximización de expectativas (EM). La red de compuertas puede tener una salida softmax que proporciona una puntuación de confianza similar a una probabilidad para cada experto.
En general, el procedimiento de entrenamiento intenta lograr dos objetivos: para los expertos dados, encontrar la función de compuerta óptima; para una función de compuerta dada, entrenar a los expertos en la distribución especificada por la función de compuerta.
— Página 95, Métodos de Conjunto, 2012.
Método de Agrupación
Finalmente, la mezcla de modelos expertos debe hacer una predicción, y esto se logra mediante un mecanismo de agrupación o agregación. Esto podría ser tan simple como seleccionar el experto con la mayor salida o confianza proporcionada por la red de puertas.
Alternativamente, se podría realizar una predicción de suma ponderada que combina explícitamente las predicciones realizadas por cada experto y la confianza estimada por la red de puertas. Es posible imaginar otros enfoques para hacer un uso efectivo de las predicciones y la salida de la red de puertas.
El sistema de agrupación/combinación puede elegir un solo clasificador con el peso más alto, o calcular una suma ponderada de las salidas del clasificador para cada clase y elegir la clase que recibe la suma ponderada más alta.
— Página 16, Aprendizaje Automático en Conjunto, 2012.
Enrutamiento de Interruptores
También deberíamos discutir brevemente cómo difiere el enfoque de enrutamiento de interruptores del documento MoE (Modelo de Expertos). Lo menciono porque parece que Microsoft ha utilizado un enrutamiento de interruptores en lugar de un Modelo de Expertos para ahorrar algo de complejidad computacional, pero estaré encantado de ser refutado. Cuando hay más de un modelo de experto, estos pueden tener un gradiente no trivial para la función de enrutamiento (cuál modelo usar en cada caso). Este límite de decisión está controlado por la capa de interruptores.
Los beneficios de la capa de interruptores son tres.
- Se reduce el cálculo de enrutamiento si el token se dirige únicamente a un solo modelo experto.
- El tamaño del lote (capacidad del experto) se puede reducir al menos a la mitad, ya que un solo token se dirige a un solo modelo.
- Se simplifica la implementación del enrutamiento y se reducen las comunicaciones.
La superposición del mismo token en más de 1 modelo experto se denomina factor de capacidad. A continuación se muestra una representación conceptual de cómo funciona el enrutamiento con diferentes factores de capacidad de expertos.
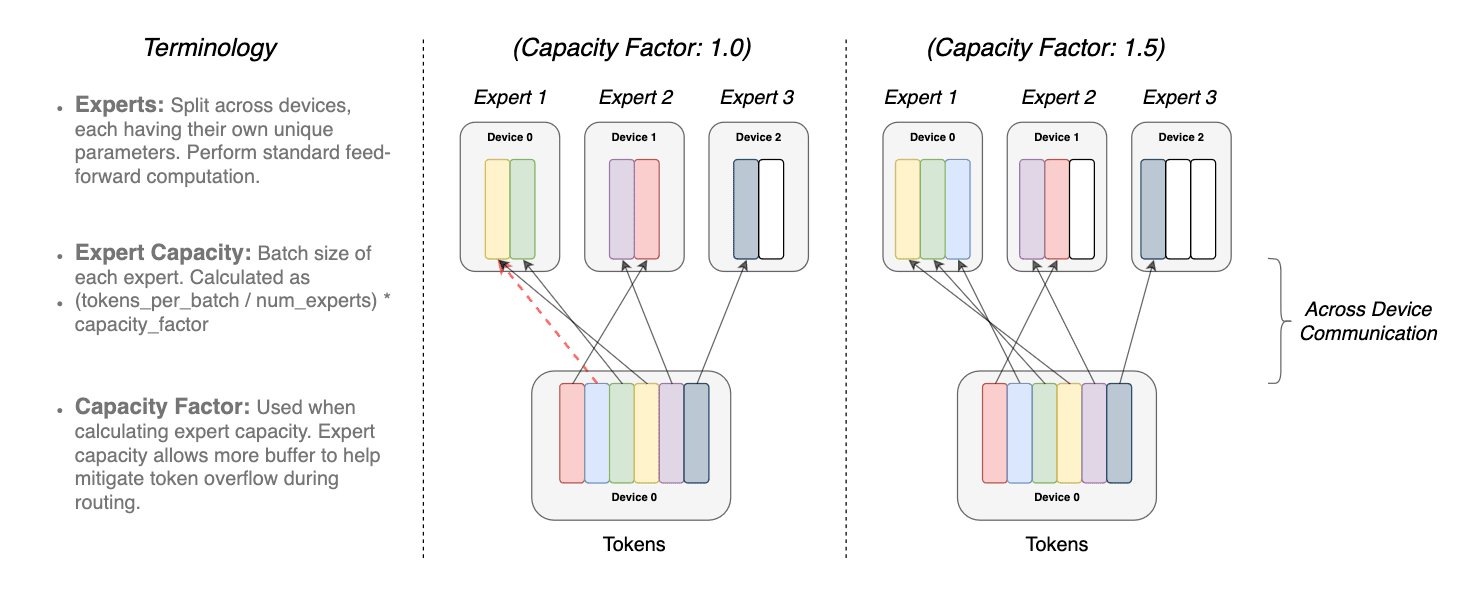
de los tokens modulados por el factor de capacidad. Cada token se dirige al experto
con la probabilidad de enrutamiento más alta, pero cada experto tiene un tamaño de lote fijo de
(tokens totales / número de expertos) × factor de capacidad. Si los tokens se distribuyen de manera desigual,
entonces ciertos expertos se desbordarán (indicado por líneas rojas punteadas), lo que resultará
en que estos tokens no sean procesados por esta capa. Un factor de capacidad más grande alivia
este problema de desbordamiento pero también aumenta los costos de cálculo y comunicación
(representado por espacios en blanco/vacíos acolchados). (fuente https://arxiv.org/pdf/2101.03961.pdf)
En comparación con el MoE, los hallazgos del documento MoE y Switch sugieren que:
- Los transformadores de interruptores superan a los modelos densos cuidadosamente ajustados y a los transformadores MoE en términos de velocidad y calidad.
- Los transformadores de interruptores tienen una huella de cálculo más pequeña que los MoE.
- Los transformadores de interruptores tienen un mejor rendimiento en factores de capacidad más bajos (1-1.25).

Pensamientos finales
Hay dos advertencias, primero, todo esto es solo rumores, y segundo, mi comprensión de estos conceptos es bastante débil, así que insto a los lectores a tomarlo con mucha precaución.
Pero, ¿qué logró Microsoft al mantener esta arquitectura oculta? Bueno, crearon expectación y suspenso en torno a ella. Esto podría haberles ayudado a elaborar mejor sus narrativas. Mantuvieron la innovación para ellos mismos y evitaron que otros los alcanzaran antes. Toda la idea probablemente fue un plan de juego habitual de Microsoft para frustrar la competencia mientras invierten 10 mil millones en una empresa.
El rendimiento de GPT-4 es excelente, pero no fue un diseño innovador o revolucionario. Fue una implementación increíblemente inteligente de los métodos desarrollados por ingenieros e investigadores, respaldada por una implementación empresarial/capitalista. OpenAI no ha negado ni ha aceptado estas afirmaciones (https://thealgorithmicbridge.substack.com/p/gpt-4s-secret-has-been-revealed), lo que me hace pensar que esta arquitectura para GPT-4 es muy probablemente la realidad (¡lo cual es genial!). ¡Simplemente no es genial! Todos queremos saber y aprender.
Un gran crédito va para Alberto Romero por sacar a la luz esta noticia e investigar más a fondo contactando a OpenAI (quienes no respondieron según la última actualización). Vi su artículo en Linkedin, pero también ha sido publicado en VoAGI.
Dr. Mandar Karhade, MD. PhD. Director Senior de Analítica Avanzada y Estrategia de Datos en Avalere Health. Mandar es un Médico Científico experimentado que trabaja en la implementación de vanguardia de la IA en las Ciencias de la Vida y la Industria de Cuidado de la Salud durante más de 10 años. Mandar también forma parte de AFDO/RAPS, ayudando a regular la implementación de la IA en el ámbito de la Salud.
Original. Repostead con permiso.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Conoce a SeamlessM4T el nuevo modelo base de Meta AI para la traducción de voz
- Cómo el cómputo en la nube mejora los flujos de trabajo de la ciencia de datos
- Aplicaciones de Python | Aprovechando la Multiprocesamiento para Velocidad y Eficiencia
- Investigadores del MIT desarrollaron una técnica de Inteligencia Artificial (IA) que permite a un robot desarrollar planes complejos para manipular un objeto utilizando toda su mano
- Papel de los Contratos de Datos en la Canalización de Datos
- Cómo solucionar problemas en scripts de Python con el módulo de registro
- El modelo base de CLIP






