Transformaciones generativas de IA de Google
'Google's generative AI transformations'
ETL está a punto de ser transformado
¿De qué se trata esto?
Los grandes modelos de lenguaje (LLM) pueden extraer información y generar información, pero también pueden transformar la información, haciendo que la extracción, transformación y carga (ETL) sean un esfuerzo potencialmente diferente. Proporcionaré un ejemplo que ilustra estas ideas, que también debería mostrar cómo se pueden y se deben utilizar los LLM para muchas tareas relacionadas, incluida la transformación de texto no estructurado en texto estructurado.
Recientemente, Google hizo que su conjunto de ofertas de grandes modelos de lenguaje (LLM) esté disponible públicamente en versión preliminar y ha etiquetado una parte de la oferta como “Generative AI Studio”. En resumen, GenAI Studio dentro de la consola de Google Cloud Platform es una IU para los LLM de Google. Sin embargo, a diferencia de Google Bard (que es una aplicación comercial que utiliza un LLM), Google no mantiene datos por ninguna razón. Tenga en cuenta que Google también lanzó una API para muchas de las capacidades descritas aquí.
Usando GenAI Studio
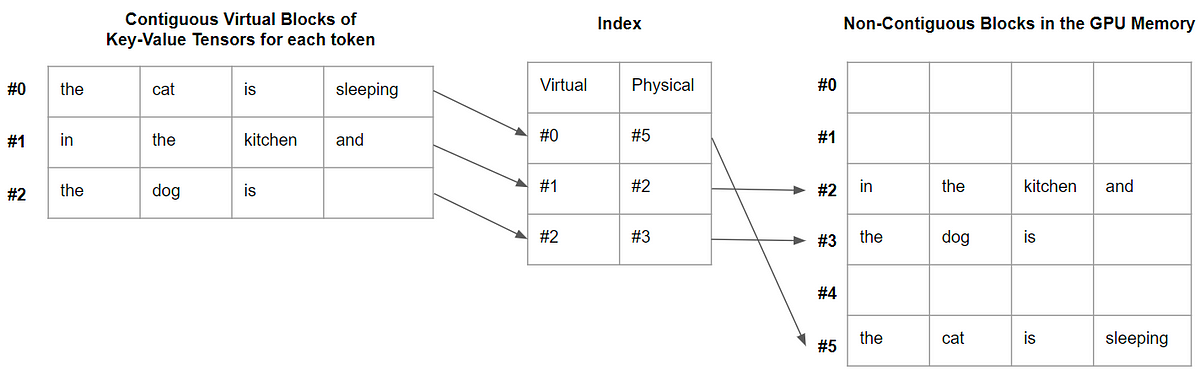
Entrar en GenAI Studio es bastante sencillo: desde la Consola de GCP, simplemente use la barra de navegación de la izquierda, coloque el cursor sobre Vertex AI y seleccione Resumen en GENERATIVE AI STUDIO.
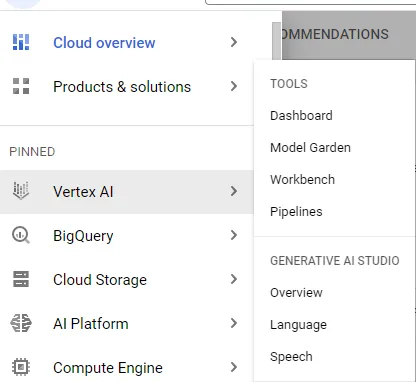
A finales de mayo de 2023, hay dos opciones: Lenguaje y Habla. (Pronto, se espera que Google también lance una categoría de Visión aquí). Cada opción contiene algunos estilos de indicación de muestra, que pueden ayudarlo a generar ideas y enfocar sus ideas existentes en indicaciones útiles. Pero más que eso, esta es una experiencia similar a Bard “segura” en el sentido de que Google no mantiene sus datos.
- Análisis de Big Data ¿Por qué es tan crucial para la inteligencia empresarial?
- ¡No olvides que Python es dinámico!
- 5 Mejores Prácticas para la Colaboración del Equipo de Ciencia de Datos.
Lenguaje
La página de inicio para Lenguaje, que es la única función utilizada para este ejemplo, tiene varias capacidades diferentes, mientras que también contiene una forma fácil de ajustar el modelo base (actualmente, la afinación solo se puede hacer en ciertas regiones).
Crear una indicación
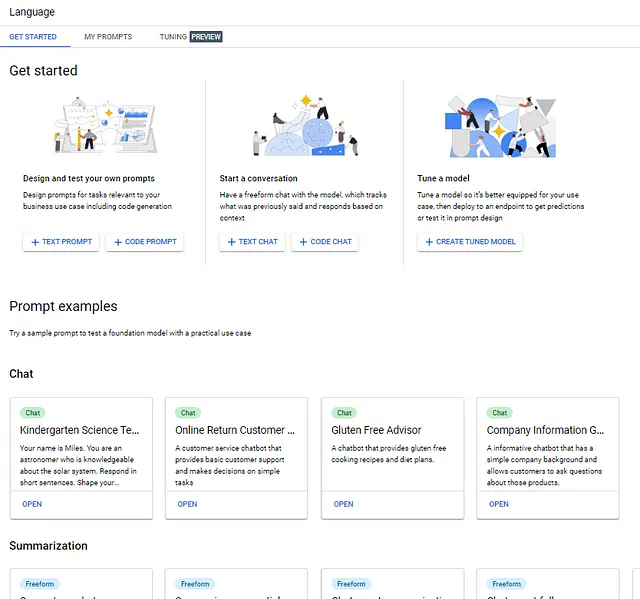
El área Comenzar es donde se crean rápidamente interacciones no guiadas con los modelos de Google (uno o más según el momento y el tipo de interacción).
Al seleccionar INDICACIÓN DE TEXTO, se invoca una IU similar a Bard con algunas diferencias importantes (además de la privacidad de los datos):
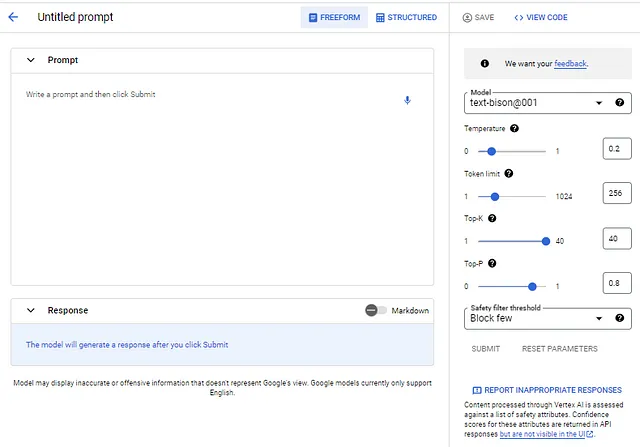
- El LLM subyacente se puede cambiar. Actualmente, el modelo de bison001 es el único disponible, pero otros aparecerán con el tiempo.
- Los parámetros del modelo se pueden cambiar. Google proporciona explicaciones para cada parámetro utilizando los signos de interrogación junto a cada uno.
- Se puede ajustar el filtro para bloquear respuestas inseguras (las opciones incluyen “Bloquear algunas”, “Bloquear algunas” y “Bloquear la mayoría”).
- Las respuestas inapropiadas se pueden informar fácilmente.
Además de las diferencias obvias con Bard, el uso de los modelos de esta manera también carece de algunos de los “complementos” de Bard, como eventos actuales. Por ejemplo, si se ingresa una indicación que pregunta sobre el clima de ayer en Chicago, este modelo no dará la respuesta correcta, pero Bard sí lo hará.
La sección de texto grande es donde se ingresa una indicación.
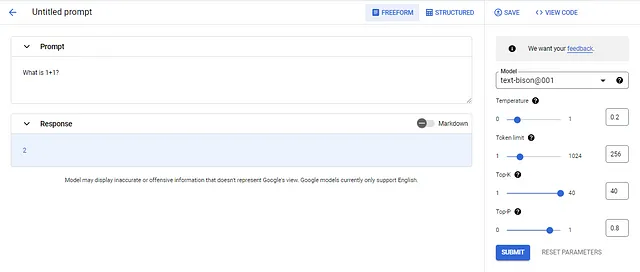
Se crea un prompt ingresando el texto en la sección Prompt, ajustando parámetros (opcionalmente), y luego seleccionando el botón SUBMIT. En este ejemplo, el prompt es “¿Qué es 1+1?” utilizando el modelo de texto-bison001 y los valores de parámetros predeterminados. Se puede observar que el modelo simplemente devuelve el número 2, lo que es un buen ejemplo del efecto que tiene la Temperatura en las respuestas. Repetir este prompt (presionando SUBMIT varias veces) produce “2” la mayoría de las veces, pero aleatoriamente se da una respuesta diferente. Al cambiar la Temperatura a 1.0, se obtiene “La respuesta es 2. 1+1=2 es una de las ecuaciones matemáticas más básicas que todos aprenden en la escuela primaria. Es la base para todo lo demás que se aprende en matemáticas más adelante.” Esto sucede porque la Temperatura ajusta la selección probabilística de tokens, cuanto más bajo es el valor, menos variable (es decir, más determinista) son las respuestas. Si el valor se establece en 0 en este ejemplo, el modelo siempre devolverá “2”. Bastante impresionante y muy parecido a Bard pero mejor. También se pueden guardar prompts y ver el código del prompt. A continuación se muestra el código para “¿Qué es 1+1?”
import vertexaifrom vertexai.preview.language_models import TextGenerationModeldef predict_large_language_model_sample( project_id: str, model_name: str, temperature: float, max_decode_steps: int, top_p: float, top_k: int, content: str, location: str = "us-central1", tuned_model_name: str = "", ) : """Predict using a Large Language Model.""" vertexai.init(project=project_id, location=location) model = TextGenerationModel.from_pretrained(model_name) if tuned_model_name: model = model.get_tuned_model(tuned_model_name) response = model.predict( content, temperature=temperature, max_output_tokens=max_decode_steps, top_k=top_k, top_p=top_p,) print(f"Response from Model: {response.text}")predict_large_language_model_sample( "mythic-guild-339223", "text-bison@001", 0, 256, 0.8, 40, '''¿Qué es 1+1?''', "us-central1")El código generado contiene el prompt, pero es fácil ver que la función predict_large_language_model_sample es de propósito general y se puede utilizar para cualquier prompt de texto.
¡Vamos a la ETL ya!
En mi trabajo diario, paso mucho tiempo descubriendo cómo extraer información de texto (incluyendo documentos). Los LLMs pueden hacer esto de manera sorprendentemente fácil y precisa, y al hacerlo también pueden cambiar los datos. Un ejemplo ilustra este potencial.
Supongamos, para el caso de este ejemplo, que se recibe el siguiente mensaje de correo electrónico por parte de una ficticia ACME Incorporated:
Comprador: Galveston WidgetsEstimado Purchasing,¿Puede por favor enviarme los siguientes artículos y proporcionarme una factura por ellos?Artículo NúmeroWidget 11 22Widget 22 4Widget 67 1Widget 99 44Gracias.Arthur GalvestonAgente de compras(312)448-4492También supongamos que los objetivos del sistema son extraer datos específicos del correo electrónico, aplicar precios (y subtotales) para cada artículo ingresado y generar un total general.
¡Si piensas que un LLM no puede hacer todo eso, piénsalo de nuevo!
Existe un estilo de prompt llamado extractive Q&A que se adapta muy bien a algunas situaciones (quizás todas las situaciones si se aplica ajustando el modelo versus simplemente la ingeniería de prompts). La idea es simple:
- Proporcionar un Antecedente, que es el texto original.
- Proporcionar un Q (para Pregunta), que debería ser algo extractivo, como “Extraer toda la información como JSON”.
- Opcionalmente, proporcionar una A (para Respuesta) que tenga la salida deseada.
Si no se proporciona una A, se aplica la ingeniería sin disparo (y esto funciona mejor de lo que esperaba). También se pueden proporcionar disparos únicos o múltiples, hasta cierto punto. Existe un límite en el tamaño de un prompt, lo que restringe la cantidad de muestras que se pueden proporcionar.
En resumen, un extracto de pregunta y respuesta tiene la siguiente forma:
Antecedentes: [el texto]P: [la pregunta extractiva]R: [nada, o un ejemplo de salida deseada]En el ejemplo, el correo electrónico es el texto y “Extraer toda la información como JSON” es la pregunta extractiva. Si no se proporciona nada como R:, el LLM intentará hacer la extracción (cero disparo). (JSON significa JavaScript Object Notation. Es un formato de intercambio de datos ligero.)
Aquí está la salida de cero disparo:
Antecedentes: Comprador: Galveston WidgetsEstimado comprador, ¿podría enviarme los siguientes artículos y proporcionarme una factura para ellos?Artículo NúmeroWidget 11 22Widget 22 4Widget 67 1Widget 99 44Gracias.Arthur GalvestonAgente de compras(312)448-4492P: Extraer toda la información como JSONR:No es necesario poner en negrita Antecedentes:, P: y R:, lo hice por claridad.
En la interfaz de usuario, dejé la sugerencia como FORMA LIBRE e ingresé la sugerencia anterior en el área de Sugerencia. Luego, configuré la Temperatura en 0 (quiero la misma respuesta para la misma entrada cada vez) y aumenté el límite de Tokens a 512 para permitir una respuesta más larga.
Así es como se ve la sugerencia y respuesta de cero disparo:
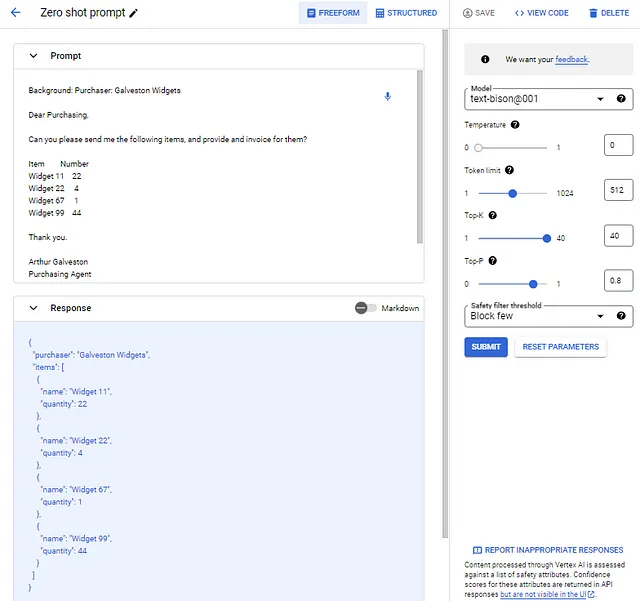
La función “Extraer” funciona e incluso hace un buen trabajo al colocar los elementos de línea en una lista dentro del JSON. Pero eso no es lo suficientemente bueno. Asumamos que mis requisitos son tener etiquetas específicas para los datos, y también supongamos que quiero capturar al agente de compras y su teléfono. Finalmente, supongamos que quiero subtotales de los elementos de línea y un gran total (esta suposición requiere que exista un precio de línea de artículo).
Mi salida ideal, que es tanto una “E”xtracto como una “T”ransformación, se ve así:
{"nombre_empresa": "Galveston Widgets","artículos" : [ {"nombre_artículo": "Widget 11", "cantidad": "22", "precio_unitario": "$1.50", "subtotal": "$33.00"}, {"nombre_artículo": "Widget 22", "cantidad": "4", "precio_unitario": "$50.00", "subtotal": "$200.00"}, {"nombre_artículo": "Widget 67", "cantidad": "1", "precio_unitario": "$3.50", "subtotal": "$3.50"}, {"nombre_artículo": "Widget 99", "cantidad": "44", "precio_unitario": "$1.00", "subtotal": "$44.00"}],"gran_total": "$280.50","agente_de_compras": "Arthur Galveston","teléfono_del_agente_de_compras": "(312)448-4492"}Para esta sugerencia, cambio la interfaz de usuario de FORMA LIBRE a ESTRUCTURADO, lo que facilita la disposición de los datos. Con esta interfaz de usuario, puedo establecer un Contexto para el LLM (lo que puede tener un efecto sorprendente en las respuestas del modelo). Luego, proporciono un Ejemplo, tanto el texto de entrada como el texto de salida, y luego una entrada de Prueba.
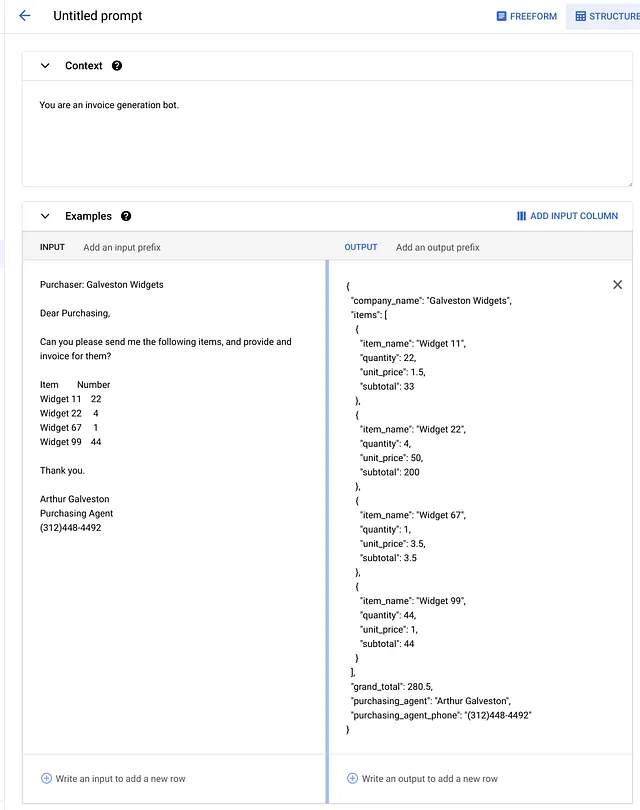
Los parámetros son los mismos para ESTRUCTURADO y FORMA LIBRE. Aquí está el Contexto y Ejemplo (tanto la entrada como la salida) para el ejemplo de ETL de la factura.
Agregué un correo electrónico de prueba, con datos totalmente diferentes (los mismos widgets, sin embargo). Aquí está todo, mostrado en la interfaz de usuario. Luego seleccioné ENVIAR, que completó el JSON de prueba, que está en el panel inferior derecho de la imagen.
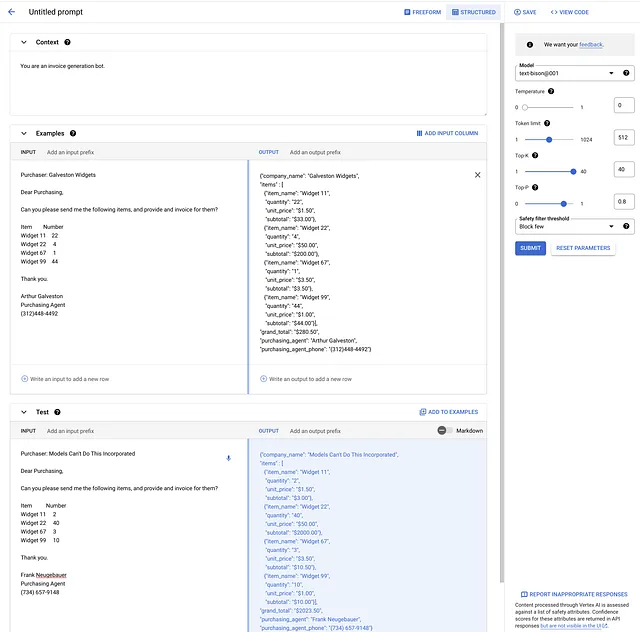
Eso ahí es magia vudú. Sí, las matemáticas están completamente correctas.
¿Qué pasa con la “L”?
En este punto, he mostrado la extracción y transformación, es hora de la parte de carga. Esa parte es en realidad muy simple, con cero esfuerzo (si se hace con la API, son dos llamadas: una para E+T, y otra para L).
Proporcioné el JSON del último paso como Antecedente y cambié P: a “Convertir el JSON a una declaración de inserción SQL”. Aquí está el resultado, que deduce una tabla de facturas y una tabla de elementos de factura. (Puede ajustar ese SQL con la pregunta y/o un ejemplo de SQL).
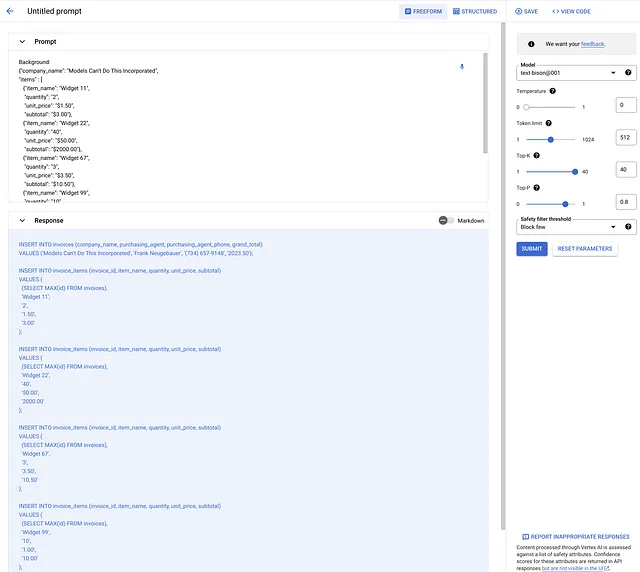
Lo que esto significa
Este ejemplo demuestra una capacidad LLM bastante asombrosa, que bien podría cambiar la naturaleza del trabajo ETL. No tengo ninguna duda de que hay límites en lo que los LLM pueden hacer en este espacio, pero todavía no sé cuáles son esos límites. Trabajar con el modelo en sus problemas es fundamental para comprender qué se puede, qué no se puede y qué debe hacerse con los LLM.
El futuro parece brillante, y GenAI Studio puede hacer que empieces muy rápidamente. Recuerda, la interfaz de usuario te proporciona algún código simple de copiar y pegar para que puedas usar la API en lugar de la interfaz de usuario, lo que se requiere para las aplicaciones reales que hacen este tipo de trabajo.
Esto también significa que el martillo todavía no hace casas. Con esto quiero decir que el modelo no descubrió este ejemplo de ETL. El LLM es el “martillo” muy elaborado – yo era el carpintero, como tú.
Descargo de responsabilidad
Este artículo es la opinión y perspectiva del autor y no refleja la de su empleador. (Por si acaso Google está observando.)
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Visualización del efecto de la multicolinealidad en el modelo de regresión múltiple.
- Pandas potenciado Encriptando archivos de Excel escritos desde DataFrames
- Control Sintético ¿Y si pudiéramos simular realidades alternativas?
- Investigadores crean una herramienta para simular con precisión sistemas complejos.
- Estudio Los modelos de IA no logran reproducir los juicios humanos sobre violaciones de reglas.
- Celebrando el impacto de IDSS
- Herramientas de Análisis de Datos que Necesitas Conocer en 2023