La IA responsable en Google Research IA para el bien social
Google Research AI's responsible AI for social good
Publicado por Jimmy Tobin y Katrin Tomanek, Ingenieros de Software, Investigación de Google, IA para el Bien Social
El equipo de IA para el Bien Social de Google está compuesto por investigadores, ingenieros, voluntarios y otros con un enfoque compartido en el impacto social positivo. Nuestra misión es demostrar el beneficio social de la IA mediante la creación de valor en el mundo real, con proyectos que abarcan trabajos en salud pública, accesibilidad, respuesta a crisis, clima y energía, y naturaleza y sociedad. Creemos que la mejor manera de impulsar un cambio positivo en las comunidades desatendidas es asociarse con líderes de cambio y las organizaciones que sirven.
En esta publicación de blog, discutimos el trabajo realizado por el Proyecto Euphonia, un equipo dentro de IA para el Bien Social, que tiene como objetivo mejorar el reconocimiento automático del habla (ASR) para personas con trastornos del habla. Para las personas con habla típica, la tasa de error de palabra (WER) de un modelo ASR puede ser inferior al 10%. Pero para personas con patrones de habla desordenados, como tartamudeo, disartria y apraxia, la WER podría alcanzar el 50% o incluso el 90% dependiendo de la etiología y la gravedad. Para ayudar a abordar este problema, trabajamos con más de 1,000 participantes para recopilar más de 1,000 horas de muestras de habla desordenada y utilizamos los datos para demostrar que la personalización de ASR es una vía viable para reducir la brecha de rendimiento para usuarios con habla desordenada. Hemos demostrado que la personalización puede tener éxito con tan solo 3-4 minutos de entrenamiento de habla utilizando técnicas de congelación de capas.
Este trabajo llevó al desarrollo del Proyecto Relate para cualquier persona con habla atípica que podría beneficiarse de un modelo de habla personalizado. Construido en asociación con el equipo de Speech de Google, Project Relate permite a las personas que encuentran difícil ser entendidas por otras personas y tecnología entrenar sus propios modelos. Las personas pueden usar estos modelos personalizados para comunicarse de manera más efectiva y ganar más independencia. Para hacer que ASR sea más accesible y utilizable, describimos cómo ajustamos el Modelo de Habla Universal (USM) de Google para comprender mejor el habla desordenada sin necesidad de personalización, para su uso con tecnologías de asistente digital, aplicaciones de dictado y conversaciones.
- Investigadores de Deepmind publican TAPIR de código abierto un nuevo modelo de IA para rastrear cualquier punto (TAP) que sigue eficazmente un punto de consulta en una secuencia de video.
- La Administración de Biden selecciona al presidente de Google para el esfuerzo de investigación de chips.
- Diseñar coches eléctricos ahora es más rápido con la IA de Toyota.
Abordando los desafíos
Trabajando en estrecha colaboración con los usuarios de Project Relate, quedó claro que los modelos personalizados pueden ser muy útiles, pero para muchos usuarios, grabar docenas o cientos de ejemplos puede ser un desafío. Además, los modelos personalizados no siempre funcionaron bien en la conversación libre.
Para abordar estos desafíos, los esfuerzos de investigación de Euphonia se han centrado en el reconocimiento automático del habla independiente del hablante (SI-ASR) para que los modelos funcionen mejor de forma predeterminada para las personas con habla desordenada, sin necesidad de entrenamiento adicional.
Conjunto de datos de habla provocada para SI-ASR
El primer paso para construir un modelo SI-ASR sólido fue crear divisiones representativas del conjunto de datos. Creamos el conjunto de datos de habla provocada dividiendo el corpus de Euphonia en porciones de entrenamiento, validación y prueba, asegurándonos de que cada división abarcara una variedad de gravedad de deterioro del habla y etiología subyacente y que ningún hablante o frase apareciera en múltiples divisiones. La porción de entrenamiento consta de más de 950,000 enunciados de habla de más de 1,000 hablantes con habla desordenada. El conjunto de prueba contiene alrededor de 5,700 enunciados de más de 350 hablantes. Patólogos del habla y lenguaje revisaron manualmente todos los enunciados en el conjunto de prueba para verificar la precisión de la transcripción y la calidad del audio.
Conjunto de prueba de conversaciones reales
El habla no provocada o conversacional difiere del habla provocada en varios aspectos. En la conversación, las personas hablan más rápido y pronuncian menos. Repiten palabras, reparan palabras mal pronunciadas y usan un vocabulario más amplio que es específico y personal para ellos y su comunidad. Para mejorar un modelo para este caso de uso, creamos el conjunto de prueba de conversaciones reales para evaluar el rendimiento.
El conjunto de prueba de conversaciones reales se creó con la ayuda de probadores de confianza que se grabaron hablando durante conversaciones. El audio fue revisado, se eliminó cualquier información personal identificable (PII), y luego los patólogos del habla y lenguaje transcribieron los datos. El conjunto de prueba de conversaciones reales contiene más de 1,500 enunciados de 29 hablantes.
Adaptando USM al habla desordenada
Luego ajustamos USM en la porción de entrenamiento del conjunto de habla provocada de Euphonia para mejorar su rendimiento en el habla desordenada. En lugar de ajustar el modelo completo, nuestro ajuste se basó en adaptadores residuales, un enfoque de ajuste eficiente en parámetros que agrega capas de cuello de botella ajustables como residuos entre las capas transformadoras. Solo se ajustan estas capas, mientras que el resto de los pesos del modelo no se tocan. Hemos demostrado previamente que este enfoque funciona muy bien para adaptar modelos ASR al habla desordenada. Los adaptadores residuales se agregaron solo a las capas del codificador, y la dimensión de cuello de botella se estableció en 64.
Resultados
Para evaluar el USM adaptado, lo comparamos con modelos ASR antiguos utilizando los dos conjuntos de pruebas descritos anteriormente. Para cada prueba, comparamos el USM adaptado con el modelo pre-USM más adecuado para esa tarea: (1) Para el habla breve provocada, lo comparamos con el modelo ASR de producción de Google optimizado para ASR de forma breve; (2) para el habla prolongada de conversación real, lo comparamos con un modelo entrenado para ASR de forma larga. Las mejoras del USM sobre los modelos pre-USM pueden explicarse por el aumento relativo del tamaño del USM, de 120M a 2B de parámetros, y otras mejoras discutidas en la publicación del blog sobre el USM.
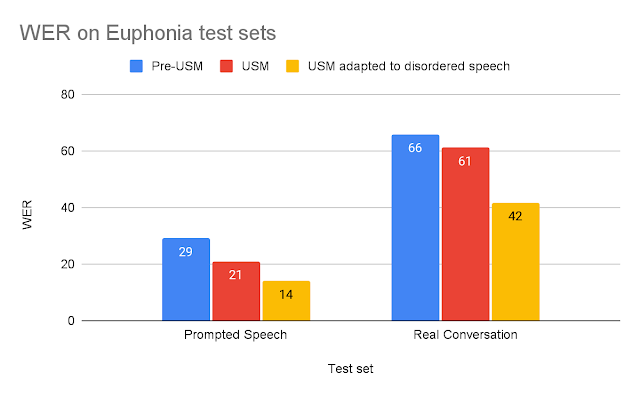 |
| Tasas de error de palabras del modelo (WER) para cada conjunto de pruebas (menor es mejor). |
Vemos que el USM adaptado con el habla desordenada supera significativamente a los otros modelos. El WER del USM adaptado en la Conversación Real es un 37% mejor que el modelo pre-USM, y en el conjunto de pruebas de Habla Provocada, el USM adaptado tiene un desempeño un 53% mejor.
Estos hallazgos sugieren que el USM adaptado es significativamente más utilizable para un usuario final con habla desordenada. Podemos demostrar esta mejora al mirar las transcripciones de las grabaciones del conjunto de pruebas de Conversación Real de un evaluador de confianza de Euphonia y Project Relate (ver abajo).
| Audio 1 | Verdad aterrizada | Modelo ASR pre-USM | USM adaptado | |||
| Ahora tengo un controlador adaptativo de Xbox en mi regazo. | ahora tengo mucho y ese consultor en mi boca | ahora tenía un controlador de xbox adaptador en mi lámpara. | ||||
| He estado hablando durante bastante tiempo. Veamos. | durante bastante tiempo ahora | He estado hablando durante bastante tiempo ahora. |
| Ejemplos de audio y transcripciones del habla de un evaluador de confianza del conjunto de pruebas de Conversación Real. |
Una comparación de las transcripciones del modelo pre-USM y el USM adaptado reveló algunas ventajas clave:
- El primer ejemplo muestra que el USM adaptado es mejor para reconocer patrones de habla desordenada. La línea de base pierde palabras clave como “XBox” y “controlador” que son importantes para que el oyente entienda lo que están tratando de decir.
- El segundo ejemplo es un buen ejemplo de cómo las eliminaciones son un problema principal con los modelos ASR que no están entrenados con habla desordenada. Aunque el modelo base transcribió una parte correctamente, gran parte del enunciado no fue transcrito, perdiendo el mensaje que el hablante quería transmitir.
Conclusión
Creemos que este trabajo es un paso importante hacia la accesibilidad de la reconocimiento de voz para personas con trastornos del habla. Continuamos trabajando en mejorar el rendimiento de nuestros modelos. Con los rápidos avances en ASR, nuestro objetivo es garantizar que las personas con trastornos del habla también se beneficien.
Agradecimientos
Los principales contribuyentes a este proyecto incluyen a Fadi Biadsy, Michael Brenner, Julie Cattiau, Richard Cave, Amy Chung-Yu Chou, Dotan Emanuel, Jordan Green, Rus Heywood, Pan-Pan Jiang, Anton Kast, Marilyn Ladewig, Bob MacDonald, Philip Nelson, Katie Seaver, Joel Shor, Jimmy Tobin, Katrin Tomanek y Subhashini Venugopalan. Agradecemos sinceramente el apoyo que el Proyecto Euphonia recibió de los miembros del equipo de investigación de USM, incluidos Yu Zhang, Wei Han, Nanxin Chen y muchos otros. Lo más importante, queríamos agradecer enormemente a los más de 2.200 participantes que grabaron muestras de voz y a los muchos grupos de defensa que nos ayudaron a conectarnos con estos participantes.
1 Se ha ajustado el volumen de audio para facilitar la escucha, pero los archivos originales serían más consistentes con los utilizados en el entrenamiento y tendrían pausas, silencios, volumen variable, etc. ↩︎
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Investigadores del Max Plank proponen MIME un modelo de IA generativo que toma capturas de movimiento humano en 3D y genera escenas en 3D plausibles que son consistentes con el movimiento.
- Investigadores de inteligencia artificial de Salesforce presentan OVIS sin máscaras un generador de máscaras de segmentación de instancia de vocabulario abierto.
- Cómo rejuvenecer usando IA Descubierto nuevo medicamento contra el envejecimiento.
- Investigadores de UC San Diego y Qualcomm lanzan Natural Program una herramienta poderosa para la verificación sin esfuerzo de cadenas de razonamiento rigurosas en lenguaje natural – Un cambio de juego en inteligencia artificial.
- Revolutionizando la Navegación Investigadores del MIT Presentan un Nuevo Enfoque de Aprendizaje Automático para la Estabilización y Evitación de Obstáculos en Vehículos Autónomos.
- NVIDIA Research gana el desafío de conducción autónoma y el premio a la innovación en CVPR.
- Generación de columnas en programación lineal y el problema de corte de stock.