Rastreador de Temas de GitHub | Web-Scraping con Python
GitHub Topic Tracker | Web Scraping with Python.

Web scraping es una técnica utilizada para extraer datos de sitios web. Nos permite recopilar información de páginas web y utilizarla para diversos fines, como análisis de datos, investigación o construcción de aplicaciones.
En este artículo, exploraremos un proyecto de Python llamado “GitHub Topics Scraper”, que aprovecha el web scraping para extraer información de la página de temas de GitHub y recuperar nombres y detalles de repositorios para cada tema.
Introducción
GitHub es una plataforma ampliamente popular para alojar y colaborar en repositorios de código. Ofrece una función llamada “temas” que permite a los usuarios categorizar repositorios en función de temas o temas específicos. El proyecto GitHub Topics Scraper automatiza el proceso de raspado de estos temas y la recuperación de información relevante del repositorio.
Visión general del proyecto
El raspador de temas de GitHub se implementa utilizando Python y utiliza las siguientes bibliotecas:
requests: utilizado para realizar solicitudes HTTP para recuperar el contenido HTML de las páginas web.BeautifulSoup: una biblioteca potente para analizar HTML y extraer datos de él.pandas: una biblioteca versátil para la manipulación y el análisis de datos, utilizada para organizar los datos raspados en un formato estructurado.
Sumergámonos en el código y entendamos cómo funciona cada componente del proyecto.
Script de Python
import requestsfrom bs4 import BeautifulSoupimport pandas as pdEl fragmento de código anterior importa tres bibliotecas:requests,BeautifulSoupypandas.
def topic_page_authentication(url): topics_url = url response = requests.get(topics_url) page_content = response.text doc = BeautifulSoup(page_content, 'html.parser') return docDefine una función llamadatopic_page_authenticationque toma una URL como argumento.
Aquí hay un desglose de lo que hace el código:
1. topics_url = url: Esta línea asigna la URL proporcionada a la variable topics_url. Esta URL representa la página web que queremos autenticar y recuperar su contenido.
2. response = requests.get(topics_url): Esta línea utiliza la funciónrequests.get()para enviar una solicitud HTTP GET atopics_urly almacena la respuesta en la variableresponse. Esta solicitud se utiliza para recuperar el contenido HTML de la página web.
3. page_content = response.text: Esta línea extrae el contenido HTML del objeto de respuesta y lo asigna a la variablepage_content. El atributoresponse.textrecupera el contenido de texto de la respuesta.
- 4.
doc = BeautifulSoup(page_content, 'html.parser') - Esta línea crea un objeto BeautifulSoup llamado
docanalizando elpage_contentusando el analizador'html.parser'. Esto nos permite navegar y extraer información de la estructura HTML de la página web.
5. return doc: Esta línea devuelve el objeto BeautifulSoupdocde la función. Esto significa que cuando se llama a la funcióntopic_page_authentication, devolverá el contenido HTML analizado como un objeto BeautifulSoup.
El propósito de esta función es autenticar y recuperar el contenido HTML de una página web especificada por la URL proporcionada. Utiliza la bibliotecarequestspara enviar una solicitud HTTP GET, recupera el contenido de la respuesta y luego lo analiza usando BeautifulSoup para crear un objeto navegable que representa la estructura HTML.
Tenga en cuenta que el fragmento de código proporcionado maneja los pasos iniciales de autenticación y análisis de la página web, pero no realiza tareas específicas de raspado o extracción de datos.
def topicSraper(doc): # Extract title title_class = 'f3 lh-condensed mb-0 mt-1 Link--primary' topic_title_tags = doc.find_all('p', {'class':title_class}) # Extract description description_class = 'f5 color-fg-muted mb-0 mt-1' topic_desc_tags = doc.find_all('p', {'class':description_class}) # Extract link link_class = 'no-underline flex-1 d-flex flex-column' topic_link_tags = doc.find_all('a',{'class':link_class}) #Extract all the topic names topic_titles = [] for tag in topic_title_tags: topic_titles.append(tag.text) #Extract the descrition text of the particular topic topic_description = [] for tag in topic_desc_tags: topic_description.append(tag.text.strip()) #Extract the urls of the particular topics topic_urls = [] base_url = "https://github.com" for tags in topic_link_tags: topic_urls.append(base_url + tags['href']) topics_dict = { 'Title':topic_titles, 'Description':topic_description, 'URL':topic_urls } topics_df = pd.DataFrame(topics_dict) return topics_dfDefine una función llamada topicScraper que toma un objeto BeautifulSoup ( doc ) como argumento.

Aquí se explica qué hace el código:
1. title_class = 'f3 lh-condensed mb-0 mt-1 Link--primary' : Esta línea define el nombre de la clase CSS ( title_class ) para el elemento HTML que contiene los títulos de los temas en la página web.
2. topic_title_tags = doc.find_all('p', {'class':title_class}) : Esta línea utiliza el método find_all() del objeto BeautifulSoup para encontrar todos los elementos HTML ( <p> ) con la clase CSS especificada ( title_class ). Recupera una lista de objetos Tag de BeautifulSoup que representan las etiquetas de los títulos de los temas.
3. description_class = 'f5 color-fg-muted mb-0 mt-1' : Esta línea define el nombre de la clase CSS ( description_class ) para el elemento HTML que contiene las descripciones de los temas en la página web.
4. topic_desc_tags = doc.find_all('p', {'class':description_class}) : Esta línea utiliza el método find_all() para encontrar todos los elementos HTML ( <p> ) con la clase CSS especificada ( description_class ). Recupera una lista de objetos Tag de BeautifulSoup que representan las etiquetas de las descripciones de los temas.
5. link_class = 'no-underline flex-1 d-flex flex-column' : Esta línea define el nombre de la clase CSS ( link_class ) para el elemento HTML que contiene los enlaces de los temas en la página web.
6. topic_link_tags = doc.find_all('a',{'class':link_class}) : Esta línea utiliza el método find_all() para encontrar todos los elementos HTML ( <a> ) con la clase CSS especificada ( link_class ). Recupera una lista de objetos Tag de BeautifulSoup que representan las etiquetas de los enlaces de los temas.
7. topic_titles = [] : Esta línea inicializa una lista vacía para almacenar los títulos de los temas extraídos.
8. for tag in topic_title_tags: ... : Este bucle itera sobre la lista topic_title_tags y agrega el contenido de texto de cada etiqueta a la lista topic_titles.
9. topic_description = [] : Esta línea inicializa una lista vacía para almacenar las descripciones de los temas extraídos.
10. for tag in topic_desc_tags: ... : Este bucle itera sobre la lista topic_desc_tags y agrega el contenido de texto sin espacios de cada etiqueta a la lista topic_description.
11. topic_urls = [] : Esta línea inicializa una lista vacía para almacenar las URLs de los temas extraídos.
12. base_url = "https://github.com" : Esta línea define la URL base del sitio web.
13. for tags in topic_link_tags: ... : Este bucle itera sobre la lista topic_link_tags y agrega la URL concatenada (URL base + atributo href) de cada etiqueta a la lista topic_urls.
14. topics_dict = {...} : Este bloque crea un diccionario ( topics_dict ) que contiene los datos extraídos: títulos de temas, descripciones y URLs.
15. topics_df = pd.DataFrame(topics_dict) : Esta línea convierte el diccionario topics_dict en un DataFrame de pandas, donde cada clave se convierte en una columna en el DataFrame.
16. return topics_df : Esta línea devuelve el DataFrame de pandas que contiene los datos extraídos.
El propósito de esta función es extraer información del objeto BeautifulSoup proporcionado ( doc ). Obtiene los títulos, descripciones y URLs de los temas de elementos HTML específicos en la página web y los almacena en un marco de datos de pandas para su análisis o procesamiento posterior.
def topic_url_extractor(dataframe): url_lst = [] for i in range(len(dataframe)): topic_url = dataframe['URL'][i] url_lst.append(topic_url) return url_lstDefine una función llamada topic_url_extractor que toma un DataFrame de panda ( dataframe ) como argumento.
Esto es lo que hace el código:
1. url_lst = [] : Esta línea inicializa una lista vacía ( url_lst ) para almacenar los URLs extraídos.
2. for i in range(len(dataframe)): ... : Este bucle itera sobre los índices de las filas del DataFrame.
3. topic_url = dataframe['URL'][i] : Esta línea recupera el valor de la columna ‘URL’ para el índice de fila actual ( i ) en el marco de datos.
4. url_lst.append(topic_url) : Esta línea agrega el URL recuperado a la lista url_lst.
5. return url_lst : Esta línea devuelve la lista de url_lst que contiene los URLs extraídos.
El propósito de esta función es extraer los URLs de la columna ‘URL’ del DataFrame proporcionado.
Itera sobre cada fila del DataFrame, recupera el valor del URL para cada fila y lo agrega a una lista. Finalmente, la función devuelve la lista de URLs extraídos.
Esta función puede ser útil cuando se desea extraer los URLs de un DataFrame para su posterior procesamiento o análisis, como visitar cada URL o realizar un raspado web adicional en las páginas web individuales.
def parse_star_count(stars_str): stars_str = stars_str.strip()[6:] if stars_str[-1] == 'k': stars_str = float(stars_str[:-1]) * 1000 return int(stars_str)Define una función llamada parse_star_count que toma una cadena ( stars_str ) como argumento.
Esto es lo que hace el código:
1. stars_str = stars_str.strip()[6:] : Esta línea elimina los espacios en blanco iniciales y finales de la cadena stars_str mediante el método strip(). Luego, corta la cadena a partir del sexto carácter y asigna el resultado de nuevo a stars_str. El propósito de esta línea es eliminar cualquier carácter o espacio no deseado de la cadena.
2. if stars_str[-1] == 'k': ... : Esta línea comprueba si el último carácter de stars_str es ‘k’, lo que indica que la cuenta de estrellas está en miles.
3. stars_str = float(stars_str[:-1]) * 1000 : Esta línea convierte la parte numérica de la cadena (excluyendo el ‘k’) en un flotante y luego lo multiplica por 1000 para convertirlo en la cantidad de estrellas real.
4. return int(stars_str) : Esta línea convierte stars_str en un entero y lo devuelve.
El propósito de esta función es analizar y convertir la cuenta de estrellas de una representación de cadena a un valor entero. Maneja los casos en los que la cuenta de estrellas está en miles (‘k’) multiplicando la parte numérica de la cadena por 1000. La función devuelve la cuenta de estrellas analizada como un entero.
Esta función puede ser útil cuando se tienen cuentas de estrellas representadas como cadenas, como ‘1.2k’ para 1,200 estrellas, y se necesita convertirlas en valores numéricos para su posterior análisis o procesamiento.
def get_repo_info(h3_tags, star_tag): base_url = 'https://github.com' a_tags = h3_tags.find_all('a') username = a_tags[0].text.strip() repo_name = a_tags[1].text.strip() repo_url = base_url + a_tags[1]['href'] stars = parse_star_count(star_tag.text.strip()) return username, repo_name, stars, repo_urlDefine una función llamada get_repo_info que toma dos argumentos: h3_tags y star_tag.
A continuación se muestra un desglose de lo que hace el código:
1. base_url = 'https://github.com': Esta línea define la URL base del sitio web de GitHub.
2. a_tags = h3_tags.find_all('a'): Esta línea utiliza el método find_all() del objeto h3_tags para encontrar todos los elementos HTML (<a>) dentro de él. Recupera una lista de objetos de etiqueta BeautifulSoup que representan las etiquetas de anclaje.
3. username = a_tags[0].text.strip(): Esta línea extrae el contenido de texto de la primera etiqueta de anclaje (a_tags[0]) y lo asigna a la variable username. También elimina cualquier espacio en blanco inicial o final utilizando el método strip().
4. repo_name = a_tags[1].text.strip(): Esta línea extrae el contenido de texto de la segunda etiqueta de anclaje (a_tags[1]) y lo asigna a la variable repo_name. También elimina cualquier espacio en blanco inicial o final utilizando el método strip().
5. repo_url = base_url + a_tags[1]['href']: Esta línea recupera el valor del atributo ‘href’ de la segunda etiqueta de anclaje (a_tags[1]) y lo concatena con base_url para formar la URL completa del repositorio. La URL resultante se asigna a la variable repo_url.
- 6.
stars = parse_star_count(star_tag.text.strip()) - Esta línea extrae el contenido de texto del objeto
star_tag, elimina cualquier espacio en blanco inicial o final y lo pasa como argumento a la funciónparse_star_count. La función devuelve el recuento de estrellas analizado como un entero, que se asigna a la variablestars.
7. return username, repo_name, stars, repo_url: Esta línea devuelve una tupla que contiene la información extraída: username, repo_name, stars y repo_url.
El propósito de esta función es extraer información sobre un repositorio de GitHub de los objetos h3_tags y star_tag proporcionados. Recupera el nombre de usuario, el nombre del repositorio, el recuento de estrellas y la URL del repositorio navegando y extrayendo elementos específicos de la estructura HTML. La función luego devuelve esta información como una tupla.
Esta función puede ser útil cuando desea extraer información del repositorio de una página web que contiene una lista de repositorios, como al raspar temas de GitHub.
def topic_information_scraper(topic_url): # autenticación de página topic_doc = topic_page_authentication(topic_url) # extraer nombre h3_class = 'f3 color-fg-muted text-normal lh-condensed' repo_tags = topic_doc.find_all('h3', {'class':h3_class}) # obtener etiqueta de estrella star_class = 'tooltipped tooltipped-s btn-sm btn BtnGroup-item color-bg-default' star_tags = topic_doc.find_all('a',{'class':star_class}) # obtener información sobre el tema topic_repos_dict = { 'username': [], 'repo_name': [], 'stars': [], 'repo_url': [] } for i in range(len(repo_tags)): repo_info = get_repo_info(repo_tags[i], star_tags[i]) topic_repos_dict['username'].append(repo_info[0]) topic_repos_dict['repo_name'].append(repo_info[1]) topic_repos_dict['stars'].append(repo_info[2]) topic_repos_dict['repo_url'].append(repo_info[3]) return pd.DataFrame(topic_repos_dict)Define una función llamada topic_information_scraper que toma una topic_url como argumento.
A continuación se muestra un desglose de lo que hace el código:
- 1.
topic_doc = topic_page_authentication(topic_url) - Esta línea llama a la función
topic_page_authenticationpara autenticar y recuperar el contenido HTML detopic_url. El contenido HTML analizado se asigna a la variabletopic_doc.
2. h3_class = 'f3 color-fg-muted text-normal lh-condensed' : Esta línea define el nombre de la clase CSS (h3_class) para el elemento HTML que contiene los nombres de los repositorios dentro de la página del tema.
3. repo_tags = topic_doc.find_all('h3', {'class':h3_class}) : Esta línea utiliza el método find_all() del objeto topic_doc para encontrar todos los elementos HTML (<h3>) con la clase CSS especificada (h3_class). Recupera una lista de objetos BeautifulSoup Tag que representan las etiquetas de nombre de repositorio.
4. star_class = 'tooltipped tooltipped-s btn-sm btn BtnGroup-item color-bg-default' : Esta línea define el nombre de la clase CSS (star_class) para el elemento HTML que contiene el recuento de estrellas dentro de la página del tema.
5. star_tags = topic_doc.find_all('a',{'class':star_class}) : Esta línea utiliza el método find_all() para encontrar todos los elementos HTML (<a>) con la clase CSS especificada (star_class). Recupera una lista de objetos BeautifulSoup Tag que representan las etiquetas de recuento de estrellas.
6. topic_repos_dict = {...} : Este bloque crea un diccionario (topic_repos_dict) que almacenará la información del repositorio extraída: nombre de usuario, nombre del repositorio, recuento de estrellas y URL del repositorio.
7. for i in range(len(repo_tags)): ... : Este bucle itera sobre los índices de la lista repo_tags, asumiendo que tiene la misma longitud que la lista star_tags.
8. repo_info = get_repo_info(repo_tags[i], star_tags[i]) : Esta línea llama a la función get_repo_info para extraer información sobre un repositorio específico. Pasa las etiquetas de nombre de repositorio actual ( repo_tags[i] ) y etiqueta de recuento de estrellas ( star_tags[i] ) como argumentos. La información devuelta se asigna a la variable repo_info.
9. topic_repos_dict['username'].append(repo_info[0]) : Esta línea agrega el nombre de usuario extraído de repo_info a la lista ‘username’ en topic_repos_dict.
10. topic_repos_dict['repo_name'].append(repo_info[1]) : Esta línea agrega el nombre del repositorio extraído de repo_info a la lista ‘repo_name’ en topic_repos_dict.
- 11.
topic_repos_dict['stars'].append(repo_info[2]) - Esta línea agrega el recuento de estrellas extraído de
repo_infoa la lista ‘stars’ entopic_repos_dict.
12. topic_repos_dict['repo_url'].append(repo_info[3]) : Esta línea agrega la URL del repositorio extraída de repo_info a la lista ‘repo_url’ en topic_repos_dict.
13. return pd.DataFrame(topic_repos_dict) : Esta línea convierte el diccionario topic_repos_dict en un DataFrame de pandas, donde cada clave se convierte en una columna en el DataFrame. El DataFrame resultante contiene la información del repositorio extraída.
El propósito de esta función es raspar y extraer información sobre los repositorios dentro de un tema específico en GitHub. Autentica y recupera el contenido HTML de la página del tema, luego extrae los nombres de los repositorios y los recuentos de estrellas utilizando nombres de clase CSS específicos.
Llama a la función get_repo_info para cada repositorio para recuperar el nombre de usuario, el nombre del repositorio, el recuento de estrellas y la URL del repositorio.
La información extraída se almacena en un diccionario y luego se convierte en un DataFrame de pandas, que es devuelto por la función.
if __name__ == "__main__": url = 'https://github.com/topics' topic_dataframe = topicSraper(topic_page_authentication(url)) topic_dataframe.to_csv('GitHubtopics.csv', index=None) # Hacer otros archivos CSV de acuerdo a los temas url = topic_url_extractor(topic_dataframe) name = topic_dataframe['Title'] for i in range(len(topic_dataframe)): new_df = topic_information_scraper(url[i]) new_df.to_csv(f'GitHubTopic_CSV-Files/{name[i]}.csv', index=None)El fragmento de código demuestra el flujo principal de ejecución del script.
A continuación se muestra una descripción de lo que hace el código:
1. if __name__ == "__main__": : Esta declaración condicional verifica si el script se está ejecutando directamente (no importado como un módulo).
2. url = 'https://github.com/topics' : Esta línea define la URL de la página de temas de GitHub.
3. topic_dataframe = topicSraper(topic_page_authentication(url)) : Esta línea recupera el contenido HTML de la página de temas utilizando topic_page_authentication, y luego pasa el HTML analizado (doc) a la función topicSraper. Asigna el marco de datos resultante (topic_dataframe) a una variable.
4. topic_dataframe.to_csv('GitHubtopics.csv', index=None) : Esta línea exporta el marco de datos topic_dataframe a un archivo CSV llamado ‘GitHubtopics.csv’. El argumento index=None asegura que los índices de fila no se incluyan en el archivo CSV.
5. url = topic_url_extractor(topic_dataframe) : Esta línea llama a la función topic_url_extractor, pasando el topic_dataframe como argumento. Recupera una lista de URLs (url) extraídas del marco de datos.
6. name = topic_dataframe['Title'] : Esta línea recupera la columna ‘Title’ del topic_dataframe y la asigna a la variable name.
7. for i in range(len(topic_dataframe)): ... : Este bucle itera sobre los índices del marco de datos topic_dataframe.
8. new_df = topic_information_scraper(url[i]) : Esta línea llama a la función topic_information_scraper, pasando la URL (url[i]) como argumento. Recupera información del repositorio para la URL de tema específica y la asigna al marco de datos new_df.
9. new_df.to_csv(f'GitHubTopic_CSV-Files/{name[i]}.csv', index=None) : Esta línea exporta el marco de datos new_df a un archivo CSV. El nombre del archivo se genera dinámicamente usando una cadena f (f-string), incorporando el nombre del tema (name[i]). El argumento index=None asegura que los índices de fila no se incluyan en el archivo CSV.
El propósito de este script es extraer información de la página de temas de GitHub y crear archivos CSV que contengan los datos extraídos. Primero raspa la página principal de temas, guarda la información extraída en ‘GitHubtopics.csv’ y luego procede a raspar las páginas de temas individuales utilizando las URL extraídas.
Para cada tema, crea un nuevo archivo CSV con el nombre del tema y guarda la información del repositorio en él.
Este script se puede ejecutar directamente para realizar la extracción de datos y generar los archivos CSV deseados.
Salida Final
url = 'https://github.com/topics'topic_dataframe = topicSraper(topic_page_authentication(url))topic_dataframe.to_csv('GitHubtopics.csv', index=None)Una vez que se ejecuta este código, generará un archivo CSV con el nombre “GitHubtopics.csv”, que se verá así, y ese CSV cubre todos los nombres de temas, su descripción y sus URLs.

url = topic_url_extractor(topic_dataframe) name = topic_dataframe['Title']for i in range(len(topic_dataframe)): new_df = topic_information_scraper(url[i]) new_df.to_csv(f'GitHubTopic_CSV-Files/{name[i]}.csv', index=None)Luego, este código se ejecutará para crear los archivos CSV específicos basados en los temas que guardamos en el archivo ‘GitHubtopics.csv’ anterior. Luego, esos archivos CSV se guardan en un directorio llamado ‘GitHubTopic_CSV-Files’ con sus propios nombres de tema específicos. Esos archivos CSV se ven así.
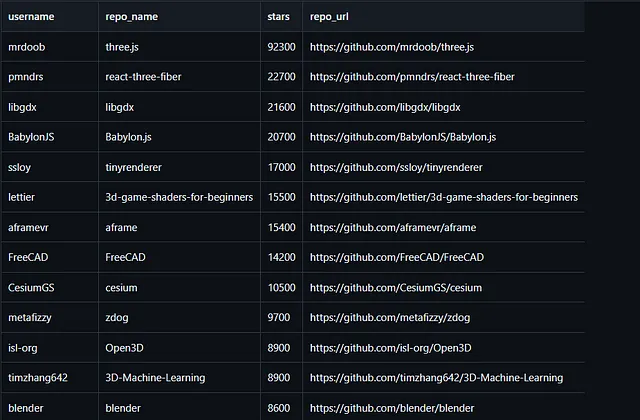
Estos archivos csv de Tema almacenan información sobre el tema, como su nombre de usuario, nombre del repositorio, estrellas del repositorio y la URL del repositorio.
Nota: Las etiquetas del sitio web pueden cambiar, así que antes de ejecutar este script de python, verifica las etiquetas una vez de acuerdo con el sitio web.
Acceso al script completo >> https://github.com/PrajjwalSule21/GitHub-Topic-Scraper/blob/main/RepoScraper.py

We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






