Toma esto y conviértelo en una marioneta digital GenMM es un modelo de IA que puede sintetizar movimiento usando un solo ejemplo.
GenMM es un modelo de IA que puede sintetizar movimiento con un solo ejemplo, convirtiendo lo que se le da en una marioneta digital.


Las animaciones generadas por computadora se están volviendo cada vez más realistas cada día. Este avance se puede ver mejor en los videojuegos. Piense en la primera Lara Croft en la serie Tomb Raider y la más reciente Lara Croft. Pasamos de una marioneta con 230 polígonos haciendo movimientos divertidos a un personaje realista que se mueve suavemente en nuestras pantallas.
Generar movimientos naturales y diversos en la animación por computadora ha sido durante mucho tiempo un problema difícil. Los métodos tradicionales, como los sistemas de captura de movimiento y la autoría de animación manual, son conocidos por ser costosos y llevar mucho tiempo, lo que resulta en conjuntos de datos de movimiento limitados que carecen de diversidad en estilo, estructuras esqueléticas y tipos de modelos. Esta naturaleza manual y que lleva mucho tiempo de generación de animación trae la necesidad de una solución automatizada en la industria.
Los métodos existentes de síntesis de movimiento impulsados por datos están limitados en su efectividad. Sin embargo, en los últimos años, el aprendizaje profundo ha surgido como una técnica poderosa en la animación por computadora, capaz de sintetizar movimientos diversos y realistas cuando se entrena en conjuntos de datos grandes y completos.
- Batalla de los gigantes de LLM Google PaLM 2 vs OpenAI GPT-3.5.
- Conoce Video-ControlNet Un nuevo modelo de difusión de texto a video que cambiará el juego y dará forma al futuro de la generación de video controlable.
- Una comparación de algoritmos de aprendizaje automático en Python y R.
Los métodos de aprendizaje profundo han demostrado resultados impresionantes en la síntesis de movimientos, pero sufren de inconvenientes que limitan su aplicabilidad práctica. En primer lugar, requieren largos tiempos de entrenamiento, lo que puede ser un cuello de botella significativo en la producción de animación. En segundo lugar, son propensos a artefactos visuales como temblores o suavizado excesivo, que afectan la calidad de los movimientos sintetizados. Por último, les resulta difícil escalar bien a estructuras esqueléticas grandes y complejas, lo que limita su uso en escenarios donde se requieren movimientos intrincados.
Sabemos que hay una demanda de un método confiable de síntesis de movimiento que se pueda aplicar en escenarios prácticos. Sin embargo, estos problemas no son fáciles de superar. Entonces, ¿cuál puede ser la solución? Es hora de conocer a GenMM.
GenMM es un enfoque alternativo basado en la idea clásica de los vecinos más cercanos del movimiento y la coincidencia del movimiento. Utiliza la coincidencia del movimiento, una técnica ampliamente utilizada en la industria para la animación de personajes, y produce animaciones de alta calidad que parecen naturales y se adaptan a diferentes contextos locales.
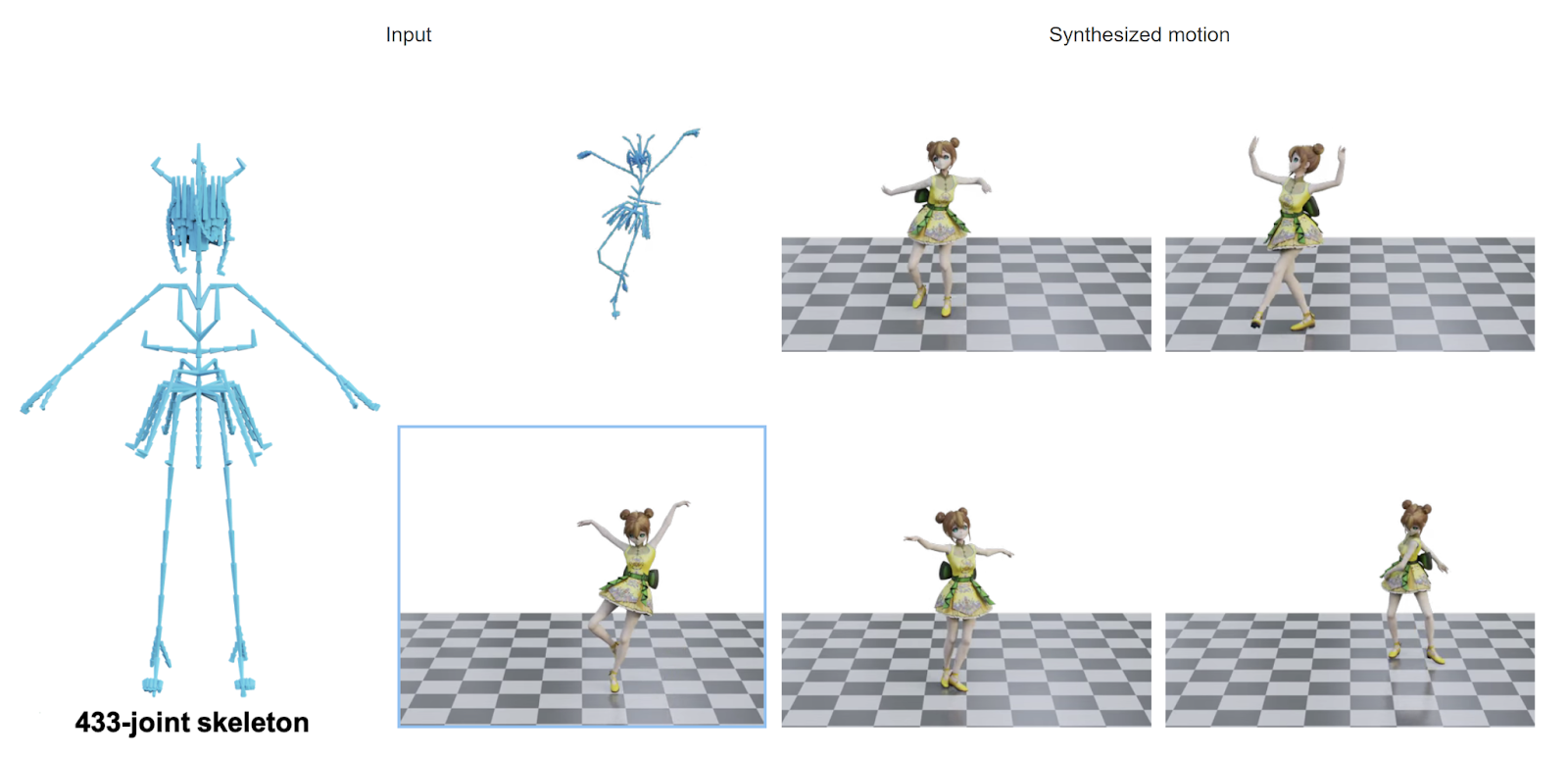
GenMM es un modelo generativo que puede extraer movimientos diversos de una o unas pocas secuencias de ejemplo. Logra esto aprovechando una amplia base de datos de captura de movimiento como una aproximación de todo el espacio de movimiento natural.
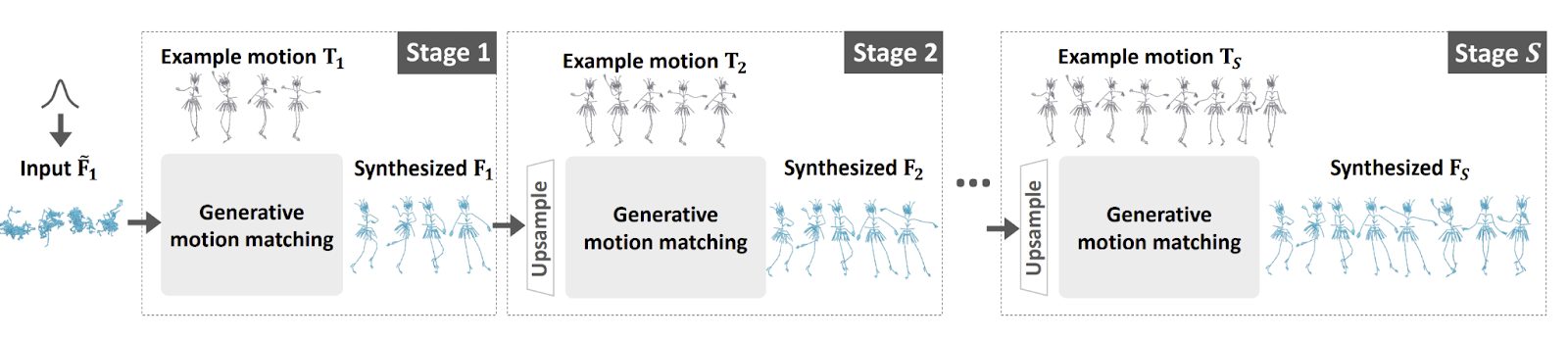
GenMM incorpora la similitud bidireccional como una nueva función de costo generativa. Esta medida de similitud asegura que la secuencia de movimiento sintetizada contenga solo parches de movimiento de los ejemplos proporcionados y viceversa. Este enfoque mantiene la calidad de la coincidencia del movimiento al permitir capacidades generativas. Para mejorar aún más la diversidad, utiliza un marco de trabajo de varias etapas que sintetiza progresivamente secuencias de movimiento con discrepancias de distribución mínimas en comparación con los ejemplos. Además, se introduce una entrada de ruido incondicional en la canalización, inspirada en el éxito de los métodos basados en GAN en la síntesis de imágenes, para lograr resultados de síntesis altamente diversos.
Además de su capacidad de generación de movimiento diverso, GenMM también demuestra ser un marco de trabajo versátil que se puede extender a varios escenarios más allá de las capacidades de la coincidencia de movimiento sola. Estos incluyen la finalización de movimiento, la generación guiada por fotogramas clave, el bucle infinito y el reensamblaje de movimientos, demostrando la amplia gama de aplicaciones habilitadas por el enfoque generativo de coincidencia de movimiento.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Búsqueda de similitud, Parte 5 Hashing sensible a la localidad (LSH)
- Moldeando el Futuro de la IA Una Encuesta Exhaustiva sobre Modelos de Pre-Entrenamiento Visión-Lenguaje y su Papel en Tareas Uni-Modales y Multi-Modales.
- Implemente un punto final de inferencia de ML sin servidor para modelos de lenguaje grandes utilizando FastAPI, AWS Lambda y AWS CDK.
- GPT vs BERT ¿Cuál es mejor?
- Inmersión teórica profunda en la Regresión Lineal
- Conoce BITE Un Nuevo Método Que Reconstruye la Forma y Poses 3D de un Perro a Partir de una Imagen, Incluso con Poses Desafiantes como Sentado y Acostado.
- Conoce Paella Un Nuevo Modelo de IA Similar a Difusión que Puede Generar Imágenes de Alta Calidad Mucho Más Rápido que Usando Difusión Estable.






