Generar automáticamente impresiones a partir de hallazgos en informes de radiología utilizando IA generativa en AWS
Generar impresiones automáticas de informes de radiología con IA generativa en AWS
Los informes de radiología son documentos exhaustivos y extensos que describen e interpretan los resultados de un examen radiológico. En un flujo de trabajo típico, el radiólogo supervisa, lee e interpreta las imágenes, y luego resume de manera concisa los hallazgos clave. La resumen (o impresión) es la parte más importante del informe porque ayuda a los médicos y pacientes a centrarse en los contenidos críticos del informe que contienen información para la toma de decisiones clínicas. Crear una impresión clara y impactante implica mucho más esfuerzo que simplemente reafirmar los hallazgos. Todo el proceso es laborioso, consume mucho tiempo y propenso a errores. A menudo lleva años de entrenamiento para que los médicos acumulen suficiente experiencia en la redacción de resúmenes concisos e informativos de informes de radiología, lo que destaca aún más la importancia de automatizar el proceso. Además, la generación automática de resúmenes de hallazgos de informes es fundamental para los informes de radiología. Permite la traducción de los informes a un lenguaje comprensible para los humanos, aliviando así la carga de los pacientes de leer informes extensos y oscuros.
Para resolver este problema, proponemos el uso de la IA generativa, un tipo de IA que puede crear nuevo contenido e ideas, incluyendo conversaciones, historias, imágenes, videos y música. La IA generativa está impulsada por modelos de aprendizaje automático (ML) – modelos muy grandes que están preentrenados con grandes cantidades de datos y comúnmente conocidos como modelos base (FMs). Los avances recientes en ML (específicamente la invención de la arquitectura de red neuronal basada en transformadores) han llevado al surgimiento de modelos que contienen miles de millones de parámetros o variables. La solución propuesta en esta publicación utiliza el ajuste fino de modelos de lenguaje grandes preentrenados (LLMs) para ayudar a generar resúmenes basados en los hallazgos en informes de radiología.
Esta publicación demuestra una estrategia para el ajuste fino de LLMs disponibles públicamente para la tarea de resumen de informes de radiología utilizando servicios de AWS. Los LLMs han demostrado capacidades notables en comprensión y generación de lenguaje natural, sirviendo como modelos base que se pueden adaptar a varios dominios y tareas. Hay beneficios significativos en el uso de un modelo preentrenado. Reduce los costos de cálculo, disminuye la huella de carbono y le permite utilizar modelos de última generación sin tener que entrenar uno desde cero.
Nuestra solución utiliza el modelo FLAN-T5 XL FM, utilizando Amazon SageMaker JumpStart, que es un centro de aprendizaje automático que ofrece algoritmos, modelos y soluciones de aprendizaje automático. Demostramos cómo lograr esto utilizando un cuaderno en Amazon SageMaker Studio. El ajuste fino de un modelo preentrenado implica un entrenamiento adicional en datos específicos para mejorar el rendimiento en una tarea diferente pero relacionada. Esta solución implica el ajuste fino del modelo FLAN-T5 XL, que es una versión mejorada de T5 (Text-to-Text Transfer Transformer), modelos LLM de propósito general. T5 reformula las tareas de procesamiento de lenguaje natural (NLP) en un formato unificado de texto a texto, a diferencia de los modelos de estilo BERT que solo pueden generar una etiqueta de clase o un fragmento de la entrada. Se ajusta finamente para una tarea de resumen en 91,544 informes de radiología en formato de texto libre obtenidos del conjunto de datos MIMIC-CXR.
- Por qué los científicos se adentran en el mundo virtual
- Doce naciones instan a los gigantes de las redes sociales a abordar el raspado ilegal de datos
- El papel de la IA en la creciente Economía Azul
Resumen de la solución
En esta sección, discutimos los componentes clave de nuestra solución: elegir la estrategia para la tarea, ajustar finamente un LLM y evaluar los resultados. También ilustramos la arquitectura de la solución y los pasos para implementarla.
Identificar la estrategia para la tarea
Existen varias estrategias para abordar la tarea de automatizar el resumen de informes clínicos. Por ejemplo, podríamos utilizar un modelo de lenguaje especializado preentrenado en informes clínicos desde cero. Alternativamente, podríamos ajustar finamente directamente un modelo de lenguaje de propósito general disponible públicamente para realizar la tarea clínica. El uso de un modelo de dominio agnóstico ajustado finamente puede ser necesario en entornos donde entrenar un modelo de lenguaje desde cero es demasiado costoso. En esta solución, demostramos el último enfoque utilizando un modelo FLAN-T5 XL, que ajustamos finamente para la tarea clínica de resumir informes de radiología. El siguiente diagrama ilustra el flujo de trabajo del modelo.
Un informe de radiología típico está bien organizado y sucinto. Dichos informes suelen tener tres secciones clave:
– Antecedentes: proporciona información general sobre la demografía del paciente con información esencial sobre el paciente, historia clínica e historia médica relevante, y detalles de los procedimientos de examen.
– Hallazgos: presenta el diagnóstico y los resultados del examen en detalle.
– Impresión: resume de manera concisa los hallazgos más relevantes o la interpretación de los hallazgos con una evaluación de su importancia y un posible diagnóstico basado en las anomalías observadas.
Utilizando la sección de hallazgos en los informes de radiología, la solución genera la sección de impresiones, que corresponde a la sumarización de los médicos. La siguiente figura es un ejemplo de un informe de radiología.

Ajustar un modelo LLM de propósito general para una tarea clínica
En esta solución, ajustamos un modelo FLAN-T5 XL (ajustando todos los parámetros del modelo y optimizándolos para la tarea). Ajustamos el modelo utilizando el conjunto de datos clínicos MIMIC-CXR, que es un conjunto de datos públicamente disponible de radiografías de tórax. Para ajustar este modelo a través de SageMaker Jumpstart, se deben proporcionar ejemplos etiquetados en forma de pares {prompt, completado}. En este caso, utilizamos pares de {Hallazgos, Impresiones} de los informes originales en el conjunto de datos MIMIC-CXR. Para inferencia, usamos un prompt como se muestra en el siguiente ejemplo:

El modelo se ajusta en una instancia de cómputo acelerado ml.p3.16xlarge con 64 CPUs virtuales y 488 GiB de memoria. Para la validación, se seleccionó aleatoriamente el 5% del conjunto de datos. El tiempo transcurrido del trabajo de entrenamiento de SageMaker con ajuste fino fue de 38,468 segundos (aproximadamente 11 horas).
Evaluar los resultados
Cuando el entrenamiento está completo, es importante evaluar los resultados. Para un análisis cuantitativo de la impresión generada, utilizamos ROUGE (Recall-Oriented Understudy for Gisting Evaluation), la métrica más comúnmente utilizada para evaluar la sumarización. Esta métrica compara un resumen producido automáticamente con un resumen o traducción de referencia (producido por humanos). ROUGE1 se refiere a la superposición de unigramas (cada palabra) entre el candidato (la salida del modelo) y los resúmenes de referencia. ROUGE2 se refiere a la superposición de bigramas (dos palabras) entre el candidato y los resúmenes de referencia. ROUGEL es una métrica a nivel de oración y se refiere a la subsecuencia común más larga (LCS) entre dos fragmentos de texto. Ignora los saltos de línea en el texto. ROUGELsum es una métrica a nivel de resumen. Para esta métrica, los saltos de línea en el texto no se ignoran, sino que se interpretan como límites de oración. Luego se calcula el LCS entre cada par de oraciones de referencia y candidatas, y luego se calcula la unión de LCS. Para la agregación de estos puntajes sobre un conjunto dado de oraciones de referencia y candidatas, se calcula el promedio.
Recorrido y arquitectura
La arquitectura general de la solución, como se muestra en la siguiente figura, consiste principalmente en un entorno de desarrollo de modelos que utiliza SageMaker Studio, la implementación del modelo con un punto de enlace de SageMaker y un panel de informes utilizando Amazon QuickSight.
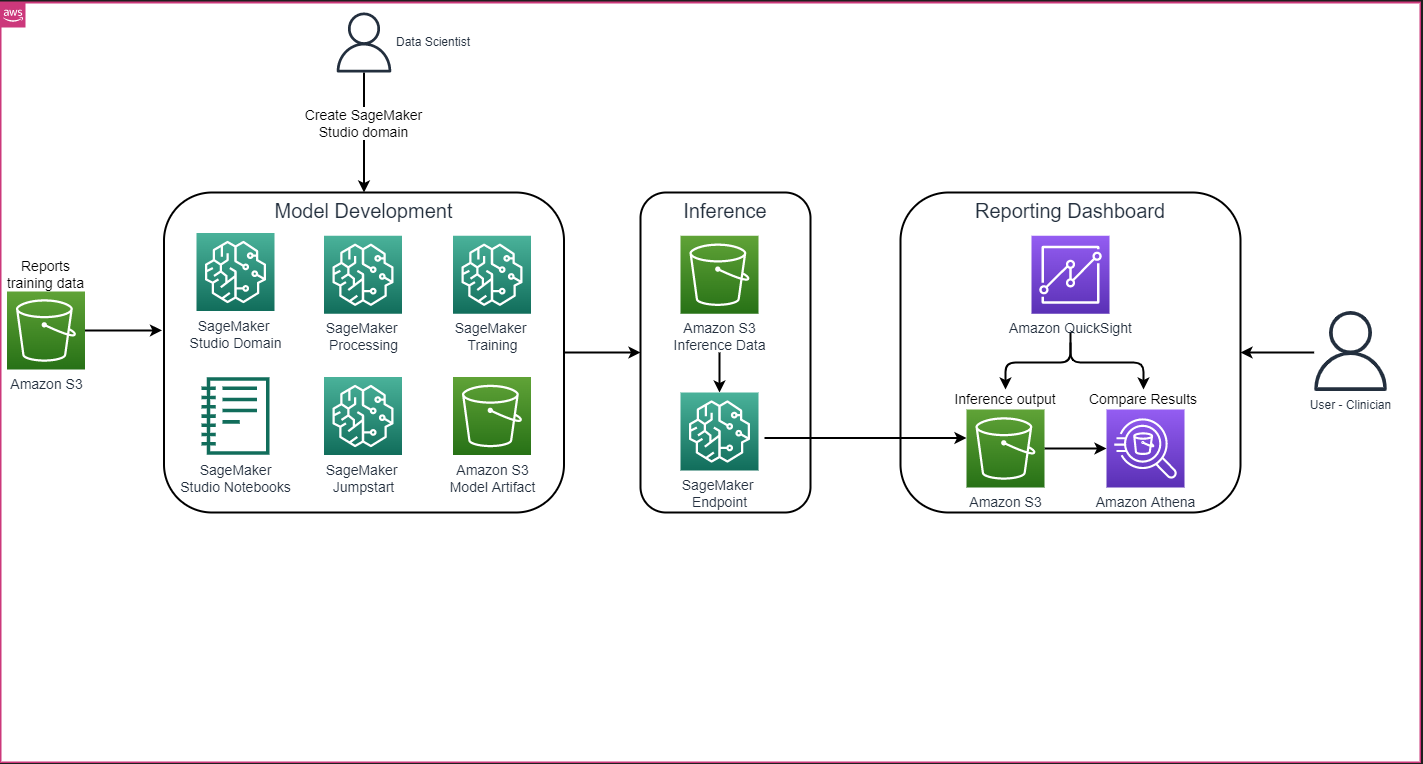
En las siguientes secciones, demostraremos cómo ajustar finamente un LLM disponible en SageMaker JumpStart para la sumarización de una tarea específica del dominio a través del SDK de Python de SageMaker. En particular, discutimos los siguientes temas:
- Pasos para configurar el entorno de desarrollo
- Una descripción general de los conjuntos de datos de informes de radiología en los que se ajusta finamente y evalúa el modelo
- Una demostración de cómo ajustar finamente el modelo FLAN-T5 XL utilizando SageMaker JumpStart de forma programática con el SDK de Python de SageMaker
- Inferencia y evaluación de los modelos preentrenados y ajustados finamente
- Comparación de los resultados del modelo preentrenado y los modelos ajustados finamente
La solución está disponible en el repositorio de AWS GitHub para Generación de impresión de informes de radiología utilizando Inteligencia Artificial generativa con un Modelo de Lenguaje Grande.
Prerrequisitos
Para comenzar, necesita una cuenta de AWS en la que pueda usar SageMaker Studio. Deberá crear un perfil de usuario para SageMaker Studio si aún no tiene uno.
El tipo de instancia de entrenamiento utilizado en esta publicación es ml.p3.16xlarge. Tenga en cuenta que el tipo de instancia p3 requiere un aumento en el límite de cuota de servicio.
El conjunto de datos MIMIC CXR se puede acceder a través de un acuerdo de uso de datos, que requiere registro de usuario y completar un proceso de acreditación.
Configurar el entorno de desarrollo
Para configurar su entorno de desarrollo, cree un bucket S3, configure un cuaderno, cree endpoints e implemente los modelos y cree un panel de QuickSight.
Crear un bucket S3
Cree un bucket S3 llamado llm-radiology-bucket para alojar los conjuntos de datos de entrenamiento y evaluación. También se utilizará para almacenar el artefacto del modelo durante el desarrollo del modelo.
Configurar un cuaderno
Complete los siguientes pasos:
- Inicie SageMaker Studio desde la consola de SageMaker o la Interfaz de línea de comandos de AWS (AWS CLI).
Para obtener más información sobre cómo incorporarse a un dominio, consulte Incorporarse a un dominio de Amazon SageMaker.
- Cree un nuevo cuaderno de SageMaker Studio para limpiar los datos del informe y ajustar el modelo. Utilizamos una instancia de cuaderno ml.t3.medium 2vCPU+4GiB con un kernel de Python 3.
- Dentro del cuaderno, instale los paquetes relevantes como
nest-asyncio,IPyWidgets(para widgets interactivos para el cuaderno Jupyter) y el SDK de Python de SageMaker:
!pip install nest-asyncio==1.5.5 --quiet
!pip install ipywidgets==8.0.4 --quiet
!pip install sagemaker==2.148.0 --quietCrear endpoints e implementar los modelos para inferencia
Para realizar inferencias en los modelos preentrenados y ajustados, cree un endpoint e implemente cada modelo en el cuaderno de la siguiente manera:
- Cree un objeto de modelo a partir de la clase Model que se puede implementar en un endpoint HTTPS.
- Cree un endpoint HTTPS con el método
deploy()del objeto de modelo precompilado:
from sagemaker import model_uris, script_uris
from sagemaker.model import Model
from sagemaker.predictor import Predictor
from sagemaker.utils import name_from_base
# Obtenga la URI del modelo preentrenado
pre_trained_model_uri =model_uris.retrieve(model_id=model_id, model_version=model_version, model_scope="inference")
large_model_env = {"SAGEMAKER_MODEL_SERVER_WORKERS": "1", "TS_DEFAULT_WORKERS_PER_MODEL": "1"}
pre_trained_name = name_from_base(f"jumpstart-demo-pre-trained-{model_id}")
# Cree la instancia del modelo de SageMaker del modelo preentrenado
if ("small" in model_id) or ("base" in model_id):
deploy_source_uri = script_uris.retrieve(
model_id=model_id, model_version=model_version, script_scope="inference"
)
pre_trained_model = Model(
image_uri=deploy_image_uri,
source_dir=deploy_source_uri,
entry_point="inference.py",
model_data=pre_trained_model_uri,
role=aws_role,
predictor_cls=Predictor,
name=pre_trained_name,
)
else:
# Para esos modelos grandes, ya hemos vuelto a empaquetar el script de inferencia y el modelo
# artefactos para usted, por lo que no se requiere el argumento `source_dir` para Model.
pre_trained_model = Model(
image_uri=deploy_image_uri,
model_data=pre_trained_model_uri,
role=aws_role,
predictor_cls=Predictor,
name=pre_trained_name,
env=large_model_env,
)
# Implemente el modelo preentrenado. Tenga en cuenta que debemos pasar la clase Predictor cuando implementamos el modelo
# a través de la clase Model, para poder ejecutar inferencias a través de la API de SageMaker
pre_trained_predictor = pre_trained_model.deploy(
initial_instance_count=1,
instance_type=inference_instance_type,
predictor_cls=Predictor,
endpoint_name=pre_trained_name,
)Crear un panel de QuickSight
Cree un panel de QuickSight con una fuente de datos de Athena con resultados de inferencia en Amazon Simple Storage Service (Amazon S3) para comparar los resultados de inferencia con la verdad fundamental. La siguiente captura de pantalla muestra nuestro panel de ejemplo. 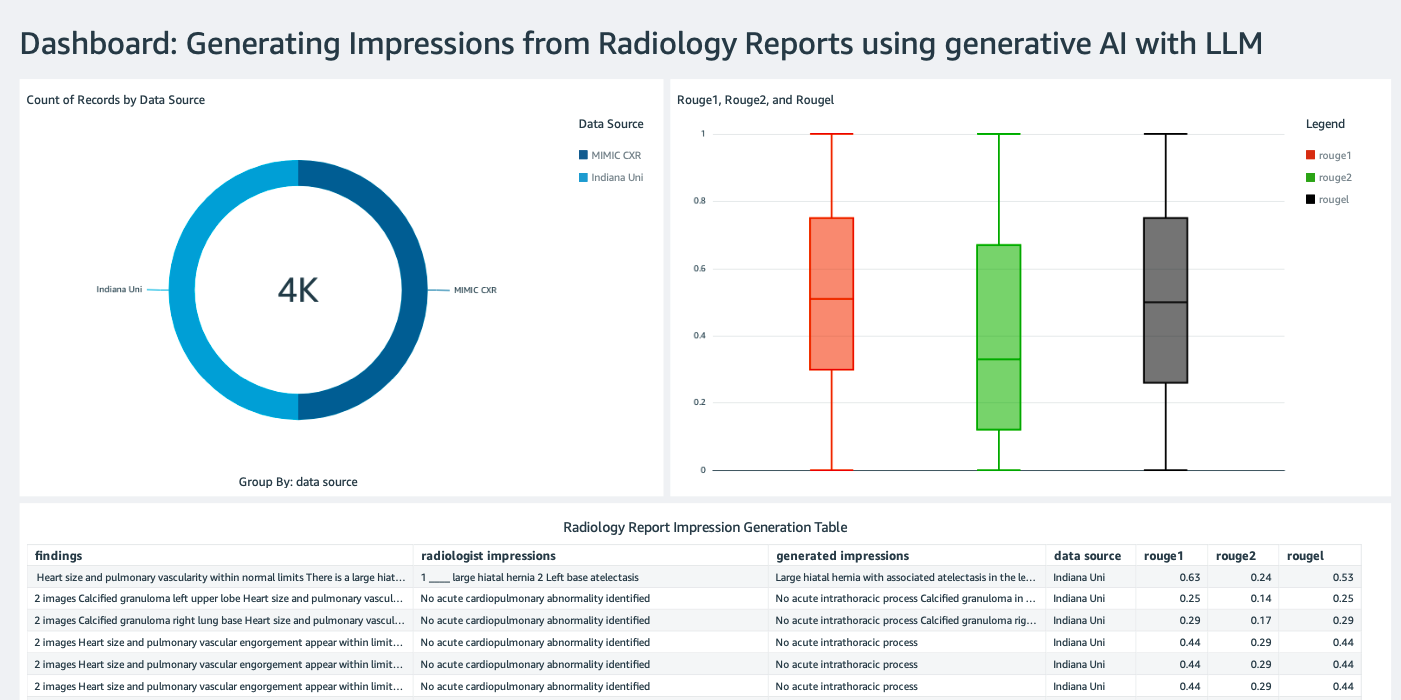
Conjuntos de datos de informes de radiología
El modelo ahora está ajustado, todos los parámetros del modelo están ajustados en 91,544 informes descargados del conjunto de datos MIMIC-CXR v2.0. Debido a que solo utilizamos los datos de texto de los informes de radiología, descargamos solo un archivo de informe comprimido (mimic-cxr-reports.zip) del sitio web de MIMIC-CXR. Ahora evaluamos el modelo ajustado en 2,000 informes (llamados conjunto de datos dev1) del subconjunto separado de este conjunto de datos. Utilizamos otros 2,000 informes de radiología (llamados dev2) para evaluar el modelo ajustado de la colección de radiografías de tórax de la red del hospital de la Universidad de Indiana. Todos los conjuntos de datos se leen como archivos JSON y se cargan en el nuevo bucket de S3 llm-radiology-bucket. Tenga en cuenta que, de forma predeterminada, todos los conjuntos de datos no contienen ninguna Información de Salud Protegida (PHI); toda la información sensible es reemplazada por tres guiones bajos consecutivos (___) por parte de los proveedores.
Ajuste fino con el SDK de Python de SageMaker
Para el ajuste fino, se especifica model_id como huggingface-text2text-flan-t5-xl de la lista de modelos de SageMaker JumpStart. El training_instance_type se establece como ml.p3.16xlarge y el inference_instance_type como ml.g5.2xlarge. Los datos de entrenamiento en formato JSON se leen del bucket de S3. El siguiente paso es utilizar el model_id seleccionado para extraer las URIs de recursos de SageMaker JumpStart, incluyendo image_uri (la URI del Registro de Contenedores Elásticos de Amazon (Amazon ECR) para la imagen Docker), model_uri (la URI del artefacto del modelo pre-entrenado en Amazon S3) y script_uri (el script de entrenamiento):
from sagemaker import image_uris, model_uris, script_uris
# La instancia de entrenamiento utilizará esta imagen
train_image_uri = image_uris.retrieve(
region=aws_region,
framework=None, # inferido automáticamente a partir de model_id
model_id=model_id,
model_version=model_version,
image_scope="training",
instance_type=training_instance_type,
)
# Modelo pre-entrenado
train_model_uri = model_uris.retrieve(
model_id=model_id, model_version=model_version, model_scope="training"
)
# Script a ejecutar en la instancia de entrenamiento
train_script_uri = script_uris.retrieve(
model_id=model_id, model_version=model_version, script_scope="training"
)
output_location = f"s3://{output_bucket}/demo-llm-rad-fine-tune-flan-t5/"También se configura una ubicación de salida como una carpeta dentro del bucket de S3.
Solo se cambia un hiperparámetro, epochs, a 3, y el resto se establece como predeterminado:
from sagemaker import hyperparameters
# Obtener los hiperparámetros predeterminados para el ajuste fino del modelo
hyperparameters = hyperparameters.retrieve_default(model_id=model_id, model_version=model_version)
# Sobrescribiremos algunos hiperparámetros predeterminados con valores personalizados
hyperparameters["epochs"] = "3"
print(hyperparameters)Se definen y enumeran las métricas de entrenamiento como eval_loss (para la pérdida de validación), loss (para la pérdida de entrenamiento) y epoch a rastrear:
from sagemaker.estimator import Estimator
from sagemaker.utils import name_from_base
model_name = "-".join(model_id.split("-")[2:]) # obtener la parte más informativa del ID
training_job_name = name_from_base(f"js-demo-{model_name}-{hyperparameters['epochs']}")
print(f"{bold}nombre del trabajo:{unbold} {training_job_name}")
training_metric_definitions = [
{"Name": "val_loss", "Regex": "'eval_loss': ([0-9\\.]+)"},
{"Name": "train_loss", "Regex": "'loss': ([0-9\\.]+)"},
{"Name": "epoch", "Regex": "'epoch': ([0-9\\.]+)"},
]Utilizamos las URIs de recursos de SageMaker JumpStart (image_uri, model_uri, script_uri) identificadas anteriormente para crear un estimador y ajustarlo fino en el conjunto de datos de entrenamiento especificando la ruta S3 del conjunto de datos. La clase Estimator requiere un parámetro entry_point. En este caso, JumpStart utiliza transfer_learning.py. El trabajo de entrenamiento falla si este valor no está configurado.
# Crear instancia de Estimador de SageMaker
sm_estimator = Estimator(
role=aws_role,
image_uri=train_image_uri,
model_uri=train_model_uri,
source_dir=train_script_uri,
entry_point="transfer_learning.py",
instance_count=1,
instance_type=training_instance_type,
volume_size=300,
max_run=360000,
hyperparameters=hyperparameters,
output_path=output_location,
metric_definitions=training_metric_definitions,
)
# Lanzar un trabajo de entrenamiento de SageMaker sobre los datos ubicados en la ruta S3 dada
# Los trabajos de entrenamiento pueden llevar horas, se recomienda establecer wait=False,
# y monitorear el estado del trabajo a través de la consola de SageMaker
sm_estimator.fit({"training": train_data_location}, job_name=training_job_name, wait=True)Este trabajo de entrenamiento puede llevar horas en completarse; por lo tanto, se recomienda establecer el parámetro wait en False y monitorear el estado del trabajo de entrenamiento en la consola de SageMaker. Use la función TrainingJobAnalytics para realizar un seguimiento de las métricas de entrenamiento en diferentes momentos:
from sagemaker import TrainingJobAnalytics
# Espere un par de minutos para que el trabajo comience antes de ejecutar esta celda
# Esto se puede llamar mientras el trabajo aún se está ejecutando
df = TrainingJobAnalytics(training_job_name=training_job_name).dataframe()Implementar puntos finales de inferencia
Con el fin de realizar comparaciones, implementamos puntos finales de inferencia tanto para los modelos pre-entrenados como para los modelos afinados.
Primero, obtenemos la URI de la imagen Docker de inferencia utilizando model_id, y usamos esta URI para crear una instancia de modelo de SageMaker del modelo pre-entrenado. Implementamos el modelo pre-entrenado creando un punto final HTTPS con el método deploy() del objeto del modelo. Para realizar inferencia a través de la API de SageMaker, asegúrese de pasar la clase Predictor.
from sagemaker import image_uris
# Obtener la URI de la imagen Docker de inferencia. Esta es la imagen base del contenedor HuggingFace
deploy_image_uri = image_uris.retrieve(
region=aws_region,
framework=None, # inferido automáticamente a partir de model_id
model_id=model_id,
model_version=model_version,
image_scope="inference",
instance_type=inference_instance_type,
)
# Obtener la URI del modelo pre-entrenado
pre_trained_model_uri = model_uris.retrieve(
model_id=model_id, model_version=model_version, model_scope="inference"
)
pre_trained_model = Model(
image_uri=deploy_image_uri,
model_data=pre_trained_model_uri,
role=aws_role,
predictor_cls=Predictor,
name=pre_trained_name,
env=large_model_env,
)
# Implementar el modelo pre-entrenado. Tenga en cuenta que necesitamos pasar la clase Predictor cuando implementamos el modelo
# a través de la clase Model, para poder realizar inferencia a través de la API de SageMaker
pre_trained_predictor = pre_trained_model.deploy(
initial_instance_count=1,
instance_type=inference_instance_type,
predictor_cls=Predictor,
endpoint_name=pre_trained_name,
)Repita el paso anterior para crear una instancia de modelo de SageMaker del modelo afinado y crear un punto final para implementar el modelo.
Evaluar los modelos
Primero, establezca la longitud del texto resumido, el número de salidas del modelo (debe ser mayor que 1 si se necesitan generar varios resúmenes) y el número de beams para la búsqueda de beams.
Construya la solicitud de inferencia como una carga útil JSON y úsela para consultar los puntos finales de los modelos pre-entrenados y afinados.
Calcule los puntajes ROUGE agregados (ROUGE1, ROUGE2, ROUGEL, ROUGELsum) como se describió anteriormente.
Comparar los resultados
La siguiente tabla muestra los resultados de evaluación para los conjuntos de datos dev1 y dev2. El resultado de evaluación en dev1 (2,000 hallazgos del Informe de Radiología MIMIC CXR) muestra una mejora de aproximadamente 38 puntos porcentuales en los puntajes ROUGE1 y ROUGE2 promedio agregados en comparación con el modelo pre-entrenado. Para dev2, se observa una mejora de 31 puntos porcentuales y 25 puntos porcentuales en los puntajes ROUGE1 y ROUGE2. En general, el ajuste fino condujo a una mejora de 38.2 puntos porcentuales y 31.3 puntos porcentuales en los puntajes ROUGELsum para los conjuntos de datos dev1 y dev2, respectivamente.
|
Evaluación Conjunto de datos |
Modelo pre-entrenado | Modelo afinado | ||||||
| ROUGE1 | ROUGE2 | ROUGEL | ROUGELsum | ROUGE1 | ROUGE2 | ROUGEL | ROUGELsum | |
dev1 |
0.2239 | 0.1134 | 0.1891 | 0.1891 | 0.6040 | 0.4800 | 0.5705 | 0.5708 |
dev2 |
0.1583 | 0.0599 | 0.1391 | 0.1393 | 0.4660 | 0.3125 | 0.4525 | 0.4525 |
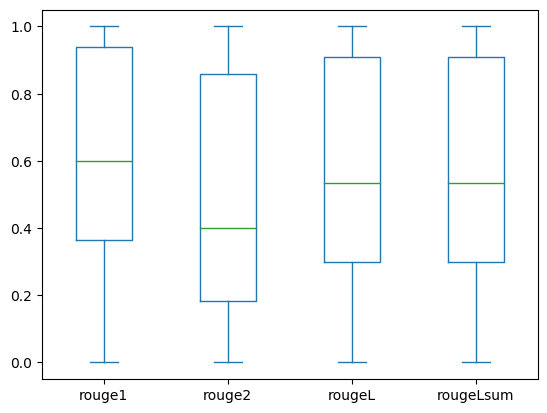
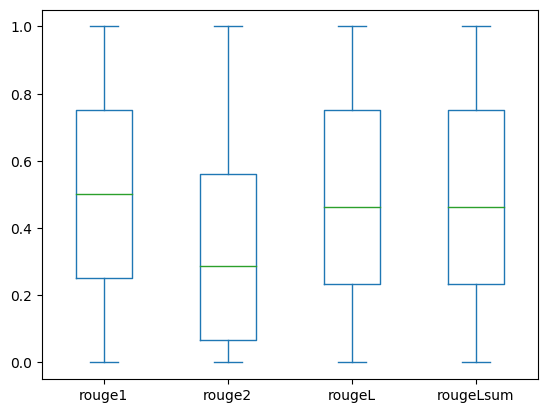
Las siguientes gráficas de caja representan la distribución de las puntuaciones ROUGE para los conjuntos de datos dev1 y dev2 evaluados utilizando el modelo afinado.
 |
 |
(a): dev1 |
(b): dev2 |
La siguiente tabla muestra que las puntuaciones ROUGE para los conjuntos de datos de evaluación tienen aproximadamente la misma mediana y media, por lo que están distribuidas simétricamente.
| Conjuntos de datos | Puntuaciones | Cantidad | Media | Desviación estándar | Mínimo | Percentil 25% | Percentil 50% | Percentil 75% | Máximo |
dev1 |
ROUGE1 | 2000.00 | 0.6038 | 0.3065 | 0.0000 | 0.3653 | 0.6000 | 0.9384 | 1.0000 |
| ROUGE 2 | 2000.00 | 0.4798 | 0.3578 | 0.0000 | 0.1818 | 0.4000 | 0.8571 | 1.0000 | |
| ROUGE L | 2000.00 | 0.5706 | 0.3194 | 0.0000 | 0.3000 | 0.5345 | 0.9101 | 1.0000 | |
| ROUGELsum | 2000.00 | 0.5706 | 0.3194 | 0.0000 | 0.3000 | 0.5345 | 0.9101 | 1.0000 | |
dev2 |
ROUGE 1 | 2000.00 | 0.4659 | 0.2525 | 0.0000 | 0.2500 | 0.5000 | 0.7500 | 1.0000 |
RO
LimpiezaPara evitar incurrir en cargos futuros, elimina los recursos que creaste con el siguiente código: ConclusiónEn esta publicación, demostramos cómo ajustar un modelo FLAN-T5 XL para una tarea de resumen específica de dominio clínico utilizando SageMaker Studio. Para aumentar la confianza, comparamos las predicciones con la verdad absoluta y evaluamos los resultados utilizando métricas ROUGE. Demostramos que un modelo ajustado para una tarea específica devuelve mejores resultados que un modelo preentrenado en una tarea genérica de procesamiento del lenguaje natural. Nos gustaría señalar que ajustar un LLM de propósito general elimina por completo el costo del preentrenamiento. Aunque el trabajo presentado aquí se centra en informes de radiografías de tórax, tiene el potencial de expandirse a conjuntos de datos más grandes con anatomías y modalidades variadas, como resonancias magnéticas y tomografías computarizadas, para los cuales los informes de radiología pueden ser más complejos con múltiples hallazgos. En tales casos, los radiólogos podrían generar impresiones en orden de criticidad e incluir recomendaciones de seguimiento. Además, establecer un ciclo de retroalimentación para esta aplicación permitiría a los radiólogos mejorar el rendimiento del modelo con el tiempo. Como mostramos en esta publicación, el modelo ajustado genera impresiones para informes de radiología con altas puntuaciones ROUGE. Puedes intentar ajustar LLM en otros informes médicos específicos de dominio de diferentes departamentos. We will continue to update Zepes; if you have any questions or suggestions, please contact us! Was this article helpful?93 out of 132 found this helpful Related articles

Discover more
Inteligencia Artificial
Conoce Universal Simulator (UniSim) Un simulador interactivo de la interacción del mundo real a través del modelado generativoLos modelos generativos han transformado la creación de contenido en texto, imágenes y videos. La próxima frontera es...
Inteligencia Artificial
Potenciando los tubos RAG en Haystack Presentando DiversityRanker y LostInTheMiddleRankerLos recientes avances en Procesamiento de Lenguaje Natural (NLP) y Respuesta a Preguntas de Forma Larga (LFQA) hubier...
Ciencias de la Computación
Vidrio de grado óptico impreso en 3D a escala nanométrica.Los ingenieros han impreso en tres dimensiones vidrio de calidad óptica a escala nanométrica a baja temperatura utili...
Inteligencia Artificial
Lista de Modelos de Inteligencia Artificial para el Campo Médico (2023)Dado el número de avances que ha hecho la inteligencia artificial (IA) en este año, no es de sorprender que haya sido...
Inteligencia Artificial
Investigadores de Eindhoven y la Universidad Northwestern han desarrollado un nuevo biosensor neuromórfico capaz de aprendizaje en el chip que no necesita entrenamiento externo.La computación neuromórfica está inspirada en la estructura y función del cerebro humano. Un chip neuromórfico es un ...
Inteligencia Artificial
Google AI presenta MedLM una familia de modelos base afinados para casos de uso en la industria de la saludInvestigadores de Google han introducido una base de modelos ajustados para la industria de la salud, MedLM, que actu...
Want to read more? Go here
|




