¿Cómo genera texto un LLM?
Generación de texto por un LLM
Este artículo no discutirá transformers o cómo se entrenan los modelos de lenguaje grandes. En su lugar, nos concentraremos en el uso de un modelo pre-entrenado.
Todo el código se proporciona en Github y Colab
Echemos un vistazo a la descripción general de la generación de texto.

- El texto de entrada se pasa a un tokenizador que genera salidas de token_id, donde a cada token_id se le asigna una representación numérica única.
- El texto de entrada tokenizado se pasa a la parte del Codificador del modelo pre-entrenado. El Codificador procesa la entrada y genera una representación de características que codifica el significado y contexto de la entrada. El Codificador fue entrenado con grandes cantidades de datos, de los cuales nos beneficiamos.
- El Descodificador toma la representación de características del Codificador y comienza a generar nuevo texto basado en ese contexto, token por token. Utiliza los tokens generados previamente para crear nuevos tokens.
Hoy, nos concentraremos en el tercer paso: descodificar y generar texto. Si estás interesado en los dos primeros pasos, comenta abajo. También consideraré cubrir esos temas.
- Cobrar ‘PAYDAY 3’ se transmite en GeForce NOW
- Confrontación de modelos de chat GPT-4 vs GPT-3.5 vs LLaMA-2 en un debate simulado – Parte 1
- Investigadores de UCI y la Universidad de Zhejiang introducen Aceleración de Modelos de Lenguaje Grandes sin Pérdidas a través de la Decodificación Autoespeculativa utilizando Etapas de Borrador y Verificación.
Descodificar las salidas
Sumergámonos ahora un poco más. Digamos que queremos generar la continuación de la frase “París es la ciudad …”. El Codificador (utilizaremos el modelo Bloom-560m (enlace al código en los comentarios)) envía logits para todos los tokens que tenemos (si no sabes qué son los logits, considéralos como puntajes) que se pueden convertir, utilizando la función softmax, en probabilidades de que se seleccione el token para la generación.

Si observas los 5 tokens de salida principales, todos tienen sentido. Podemos generar las siguientes frases que suenan legítimas:
- París es la ciudad del amor.
- París es la ciudad que nunca duerme.
- París es la ciudad donde florece el arte y la cultura.
- París es la ciudad con hitos icónicos.
- París es la ciudad en la que la historia tiene un encanto único.
El desafío ahora es seleccionar el token adecuado. Y hay varias estrategias para eso.
Muestreo egoísta
En pocas palabras, en una estrategia egoísta, el modelo siempre elige el token que cree que es el más probable en cada paso, sin considerar otras posibilidades o explorar diferentes opciones. El modelo selecciona el token con la probabilidad más alta y continúa generando texto basado en la elección seleccionada.

Usar una estrategia egoísta es eficiente y sencillo desde el punto de vista computacional, pero tiene el costo de obtener salidas repetitivas o excesivamente determinísticas ocasionalmente. Dado que el modelo solo considera el token más probable en cada paso, es posible que no capture toda la diversidad del contexto y del lenguaje, o produzca las respuestas más creativas. La naturaleza miope del modelo se enfoca únicamente en el token más probable en cada paso, sin tener en cuenta el impacto general en toda la secuencia.
Salida generada: París es la ciudad del futuro. La
Búsqueda de viga
La búsqueda de viga es otra estrategia utilizada en la generación de texto. En la búsqueda de viga, el modelo asume un conjunto de los “k” tokens más probables en lugar de considerar solo el token más probable en cada paso. Este conjunto de k tokens se llama “viga”.

El modelo genera secuencias posibles para cada token y realiza un seguimiento de sus probabilidades en cada paso de la generación de texto al expandir líneas posibles para cada viga.
Este proceso continúa hasta que se alcance la longitud deseada del texto generado o se encuentre un token “fin” para cada viga. El modelo selecciona la secuencia con la mayor probabilidad general de todas las vigas como la salida final.
Desde una perspectiva algorítmica, crear beams es expandir un árbol k-nario. Después de crear los beams, seleccionas la rama con la probabilidad general más alta.
Salida generada: París es la ciudad de la historia y la cultura.
Muestreo aleatorio normal o uso directo de la probabilidad

La idea es sencilla: seleccionas la siguiente palabra eligiendo un valor aleatorio y mapeándolo al token seleccionado. Imagínalo como girar una ruleta, donde el área de cada token está definida por su probabilidad. Cuanto mayor sea la probabilidad, más posibilidades habrá de seleccionar el token. Es una solución computacional relativamente barata y debido a su alta aleatoriedad relativa, las oraciones (o secuencia de tokens) probablemente serán diferentes cada vez.

Muestreo aleatorio con temperatura
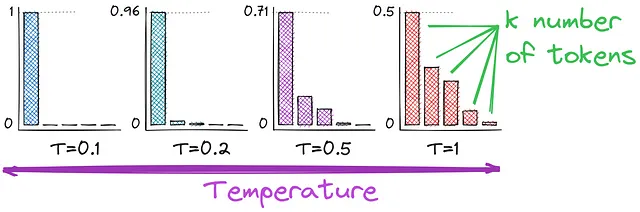
Como recordarás, hemos estado utilizando la función softmax para convertir los logits en probabilidades. Y aquí introducimos la temperatura, un hiperparámetro que afecta la aleatoriedad de la generación de texto. Comparemos las funciones de activación para entender mejor cómo la temperatura afecta nuestros cálculos de probabilidad.

Como podrás observar, la diferencia está en el denominador: dividimos por T. Valores más altos de temperatura (por ejemplo, 1.0) hacen que la salida sea más diversa, mientras que valores más bajos (por ejemplo, 0.1) la hacen más enfocada y determinista. T = 1 dará como resultado la función softmax inicial que utilizamos.
Muestreo top-k
Ahora podemos ajustar las probabilidades con la temperatura. Otra mejora es utilizar solo los tokens top-k en lugar de todos ellos. Esto aumentará la estabilidad de la generación de texto, sin disminuir demasiado la creatividad. Ahora tenemos un muestreo aleatorio con temperatura solo para los tokens top k. El único problema posible podría ser seleccionar el número k, y aquí está cómo podemos mejorarlo.
Muestreo de núcleo o muestreo top-p
La distribución de las probabilidades de los tokens puede ser muy diferente, lo que puede producir resultados inesperados durante la generación de texto.

El muestreo de núcleo está diseñado para abordar algunas limitaciones de diferentes técnicas de muestreo. En lugar de especificar un número fijo de tokens “k” a considerar, se utiliza un umbral de probabilidad “p”. Este umbral representa la probabilidad acumulativa que deseas incluir en el muestreo. El modelo calcula las probabilidades de todos los posibles tokens en cada paso y luego las ordena en orden descendente.

El modelo continúa agregando tokens al texto generado hasta que la suma de sus probabilidades supere el umbral especificado. La ventaja del muestreo de núcleo es que permite una selección de tokens más dinámica y adaptativa basada en el contexto. El número de tokens seleccionados en cada paso puede variar según las probabilidades de los tokens en ese contexto, lo que puede llevar a salidas más diversas y de mayor calidad.
Conclusión
Las estrategias de decodificación son cruciales en la generación de texto, especialmente con modelos de lenguaje pre-entrenados. Si lo piensas, tenemos varias formas de definir probabilidades, varias formas de usar esas probabilidades y al menos dos formas de determinar cuántos tokens considerar. A continuación, te dejo una tabla resumen para recapitular el conocimiento.
La temperatura controla la aleatoriedad de la selección de tokens durante la decodificación. Una temperatura más alta impulsa la creatividad, mientras que una temperatura más baja se preocupa por la coherencia y la estructura. Si bien abrazar la creatividad permite fascinantes aventuras lingüísticas, temperarla con estabilidad asegura la elegancia del texto generado.
Agradecería tu apoyo si has disfrutado de las ilustraciones y el contenido del artículo. ¡Hasta la próxima!

El artículo original fue publicado en mi página de LinkedIn.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Explorando Numexpr Un Motor Potente Detrás de Pandas
- Cómo hablar sobre datos y análisis con personas que no son expertas en datos
- Extrayendo texto de archivos PDF con Python Una guía completa
- Google PaLM 2 Revolucionando los modelos de lenguaje
- AI generativa en documentos de investigación utilizando el modelo Nougat
- 15 Mejores Inicios de ChatGPT para Twitter (X)
- En el Omniverso el lanzamiento alfa de Blender 4.0 sienta las bases para una nueva era de la artesanía de OpenUSD





