Generación de texto a partir de imágenes sin entrenamiento previo con BLIP-2
'Generación de texto a partir de imágenes sin entrenamiento previo con BLIP-2' can be condensed to 'Generación de texto sin entrenamiento con BLIP-2'.
Esta guía presenta BLIP-2 de Salesforce Research, que permite una suite de modelos visuales de vanguardia que ahora están disponibles en 🤗 Transformers. Te mostraremos cómo usarlo para la generación de subtítulos de imágenes, generación de subtítulos de imágenes con indicación, respuesta a preguntas visuales y generación de diálogos basada en texto.
Tabla de contenidos
- Introducción
- ¿Qué hay detrás de BLIP-2?
- Usando BLIP-2 con Hugging Face Transformers
- Generación de subtítulos de imágenes
- Generación de subtítulos de imágenes con indicación
- Respuesta a preguntas visuales
- Generación de diálogos basada en texto
- Conclusión
- Agradecimientos
Introducción
En los últimos años, ha habido avances rápidos en visión por computadora y procesamiento de lenguaje natural. Sin embargo, muchos problemas del mundo real son inherentemente multimodales, involucran varias formas distintas de datos, como imágenes y texto. Los modelos de lenguaje visual enfrentan el desafío de combinar modalidades para que puedan abrir la puerta a una amplia gama de aplicaciones. Algunas de las tareas de imagen a texto que los modelos de lenguaje visual pueden abordar incluyen la generación de subtítulos de imágenes, la recuperación de imágenes y texto, y la respuesta a preguntas visuales. La generación de subtítulos de imágenes puede ayudar a las personas con discapacidad visual, crear descripciones de productos útiles, identificar contenido inapropiado más allá del texto, y más. La recuperación de imágenes y texto se puede aplicar en la búsqueda multimodal, así como en aplicaciones como la conducción autónoma. La respuesta a preguntas visuales puede ayudar en la educación, permitir chatbots multimodales y ayudar en diversas aplicaciones de recuperación de información específicas del dominio.
Los modelos modernos de visión por computadora y lenguaje natural se han vuelto más capaces; sin embargo, también han crecido significativamente en tamaño en comparación con sus predecesores. Si bien el preentrenamiento de un modelo de una sola modalidad consume recursos y es costoso, el costo del preentrenamiento de extremo a extremo de visión y lenguaje se ha vuelto cada vez más prohibitivo. BLIP-2 aborda este desafío al introducir un nuevo paradigma de preentrenamiento de lenguaje visual que potencialmente puede aprovechar cualquier combinación de codificador de visión preentrenado y LLM sin tener que preentrenar toda la arquitectura de extremo a extremo. Esto permite lograr resultados de vanguardia en múltiples tareas de lenguaje visual mientras se reduce significativamente el número de parámetros entrenables y los costos de preentrenamiento. Además, este enfoque abre el camino para un modelo multimodal similar a ChatGPT.
¿Qué hay detrás de BLIP-2?
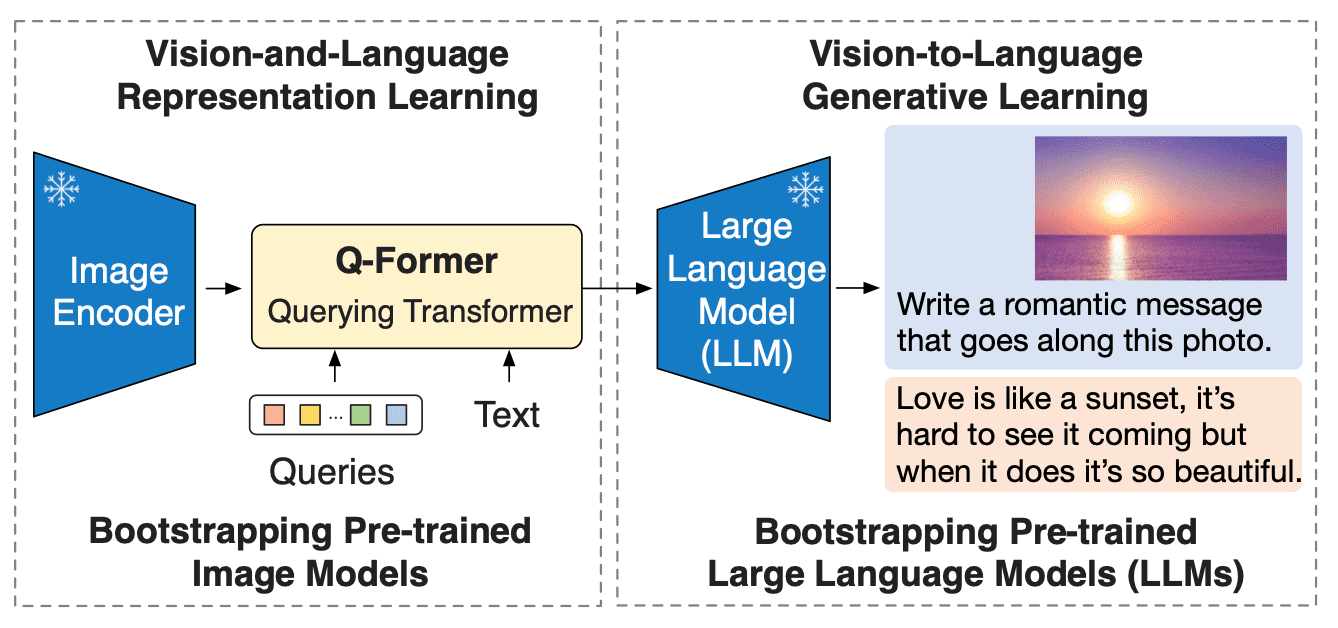
BLIP-2 cubre la brecha de modalidad entre los modelos de visión y lenguaje al agregar un Transformer de consulta liviano (Q-Former) entre un codificador de imagen preentrenado congelado y un gran modelo de lenguaje congelado. Q-Former es la única parte entrenable de BLIP-2; tanto el codificador de imagen como el modelo de lenguaje permanecen congelados.
- Hugging Face y AWS se asocian para hacer que la IA sea más accesible
- Swift 🧨Difusores – Difusión rápida y estable para Mac
- Directrices éticas para el desarrollo de la biblioteca Diffusers
Q-Former es un modelo transformer que consta de dos submódulos que comparten las mismas capas de autoatención:
- un transformer de imagen que interactúa con el codificador de imagen congelado para la extracción de características visuales
- un transformer de texto que puede funcionar tanto como codificador de texto como decodificador de texto
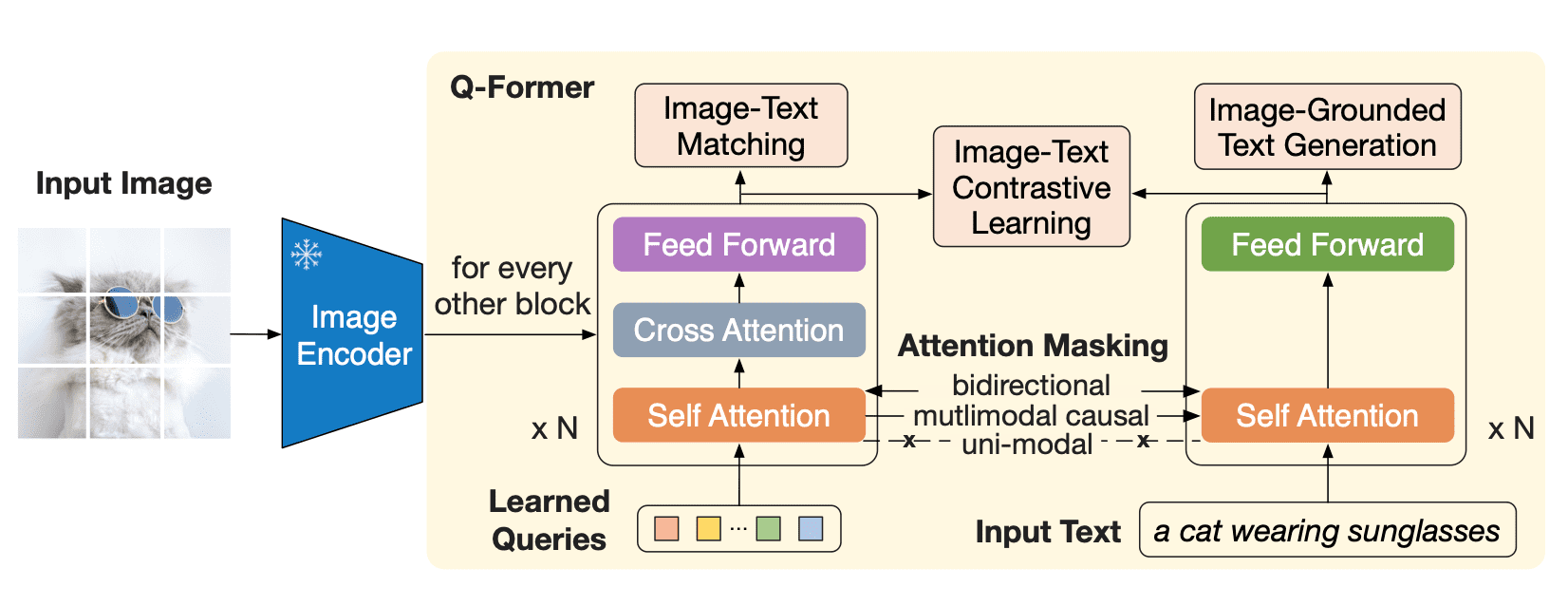
El transformer de imagen extrae un número fijo de características de salida del codificador de imagen, independientemente de la resolución de la imagen de entrada, y recibe como entrada incrustaciones de consulta entrenables. Las consultas también pueden interactuar con el texto a través de las mismas capas de autoatención.
Q-Former se preentrena en dos etapas. En la primera etapa, el codificador de imagen está congelado, y Q-Former se entrena con tres pérdidas:
- Pérdida de contraste entre imagen y texto: se calcula la similitud par a par entre cada salida de consulta y el token CLS de salida de texto, y se elige el más alto. Las incrustaciones de consulta y el texto no “se ven” entre sí.
- Generación de texto basada en la imagen: las consultas pueden atenderse entre sí pero no a los tokens de texto, y el texto tiene una máscara causal y puede atender a todas las consultas.
- Pérdida de coincidencia de imagen y texto: las consultas y el texto pueden verse entre sí, y se obtiene un logit para indicar si el texto coincide o no con la imagen. Para obtener ejemplos negativos, se utiliza el muestreo de negativos difíciles.
En la segunda etapa de preentrenamiento, las incrustaciones de consulta ahora tienen la información visual relevante para el texto, ya que ha pasado por un cuello de botella de información. Estas incrustaciones ahora se utilizan como un prefijo visual para la entrada del LLM. Esta fase de preentrenamiento involucra efectivamente una tarea de generación de texto basada en la imagen utilizando la pérdida de LM causal.
Como codificador visual, BLIP-2 utiliza ViT, y para un LLM, los autores del artículo utilizaron los modelos OPT y Flan T5. Puedes encontrar puntos de control pre-entrenados tanto para OPT como para Flan T5 en Hugging Face Hub. Sin embargo, como se mencionó antes, el enfoque de pre-entrenamiento introducido permite combinar cualquier esquema visual con cualquier LLM.
Usando BLIP-2 con Hugging Face Transformers
Usando Hugging Face Transformers, puedes descargar y ejecutar fácilmente un modelo BLIP-2 pre-entrenado en tus imágenes. Asegúrate de utilizar un entorno de GPU con alta RAM si deseas seguir los ejemplos en esta publicación del blog.
Comencemos instalando Transformers. Dado que este modelo se ha agregado a Transformers muy recientemente, necesitamos instalar Transformers desde la fuente:
pip install git+https://github.com/huggingface/transformers.gitA continuación, necesitaremos una imagen de entrada. Cada semana, The New Yorker realiza un concurso de subtítulos de caricaturas entre sus lectores, así que tomemos una de estas caricaturas para poner a prueba a BLIP-2.
import requests
from PIL import Image
url = 'https://media.newyorker.com/cartoons/63dc6847be24a6a76d90eb99/master/w_1160,c_limit/230213_a26611_838.jpg'
image = Image.open(requests.get(url, stream=True).raw).convert('RGB')
display(image.resize((596, 437)))
Tenemos una imagen de entrada. Ahora necesitamos un modelo BLIP-2 pre-entrenado y un preprocesador correspondiente para preparar las entradas. Puedes encontrar la lista de todos los puntos de control pre-entrenados disponibles en Hugging Face Hub. Aquí, cargaremos un punto de control BLIP-2 que aprovecha el modelo OPT pre-entrenado de Meta AI, que tiene 2.7 billones de parámetros.
from transformers import AutoProcessor, Blip2ForConditionalGeneration
import torch
processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16)Nótese que BLIP-2 es un caso excepcional en el que no se puede cargar el modelo con la API automática (por ejemplo, AutoModelForXXX), y se debe utilizar explícitamente Blip2ForConditionalGeneration. Sin embargo, se puede utilizar AutoProcessor para obtener la clase de procesador adecuada – Blip2Processor en este caso.
Utilicemos la GPU para hacer que la generación de texto sea más rápida:
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)Subtitulado de imágenes
Averigüemos si BLIP-2 puede hacer el subtitulado de una caricatura de The New Yorker de manera automática. Para subtitular una imagen, no es necesario proporcionar ninguna indicación de texto al modelo, solo la imagen de entrada preprocesada. Sin ninguna indicación de texto, el modelo comenzará a generar texto desde el token BOS (comienzo de secuencia), creando así un subtítulo.
inputs = processor(image, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=20)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
"dos monstruos de dibujos animados sentados alrededor de una fogata"¡Esta es una descripción impresionantemente precisa para un modelo que no fue entrenado en caricaturas al estilo de The New Yorker!
Subtitulado de imágenes con indicaciones
Podemos ampliar el subtitulado de imágenes proporcionando una indicación de texto, que el modelo continuará a partir de la imagen.
prompt = "esto es un dibujo animado de"
inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=20)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
"dos monstruos sentados alrededor de una fogata"
prompt = "parecen estar"
inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=20)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
"pasando un buen rato"Respuesta a preguntas visuales
Para responder a preguntas visuales, la indicación debe seguir un formato específico: “Pregunta: {} Respuesta:”
indicación = "Pregunta: ¿Qué está sosteniendo un dinosaurio? Respuesta:"
inputs = processor(image, text=indicación, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=10)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
"Una antorcha"Generación de respuestas basadas en chat
Finalmente, podemos crear una interfaz similar a ChatGPT concatenando cada respuesta generada a la conversación. Le indicamos al modelo un texto (como “¿Qué está sosteniendo un dinosaurio?”), el modelo genera una respuesta para ello (“una antorcha”), que podemos concatenar a la conversación. Luego, repetimos este proceso, construyendo el contexto. Sin embargo, asegúrese de que el contexto no supere los 512 tokens, ya que esta es la longitud máxima permitida por los modelos de lenguaje utilizados por BLIP-2 (OPT y T5).
contexto = [
("¿Qué está sosteniendo un dinosaurio?", "una antorcha"),
("¿Dónde están?", "En el bosque.")
]
pregunta = "¿Para qué?"
plantilla = "Pregunta: {} Respuesta: {}."
indicación = " ".join([plantilla.format(contexto[i][0], contexto[i][1]) for i in range(len(contexto))]) + " Pregunta: " + pregunta + " Respuesta:"
print(indicación)
Pregunta: ¿Qué está sosteniendo un dinosaurio? Respuesta: una antorcha. Pregunta: ¿Dónde están? Respuesta: En el bosque.. Pregunta: ¿Para qué? Respuesta:
inputs = processor(image, text=indicación, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=10)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
Para encender un fuego.Conclusión
BLIP-2 es un modelo visual-lingüístico de cero-shot que se puede utilizar para múltiples tareas de conversión de imagen a texto con indicaciones de imagen y texto. Es un enfoque eficaz y eficiente que se puede aplicar a la comprensión de imágenes en numerosos escenarios, especialmente cuando hay pocos ejemplos.
El modelo une la brecha entre las modalidades de visión y lenguaje natural mediante la incorporación de un transformador entre modelos pre-entrenados. Este nuevo paradigma de pre-entrenamiento permite que este modelo se mantenga al día con los avances en ambas modalidades individuales.
Si desea aprender cómo ajustar los modelos BLIP-2 para varias tareas de visión y lenguaje, consulte la biblioteca LAVIS de Salesforce, que ofrece un soporte integral para el entrenamiento del modelo.
Para ver BLIP-2 en acción, pruebe su demostración en Hugging Face Spaces.
Agradecimientos
Muchas gracias al equipo de investigación de Salesforce por trabajar en BLIP-2, a Niels Rogge por agregar BLIP-2 a 🤗 Transformers y a Omar Sanseviero por revisar esta publicación del blog.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ControlNet en 🧨 Difusores
- Creando Inteligencia Artificial de Preservación de Privacidad con Substra
- Aprendizaje Federado utilizando Hugging Face y Flower
- Acelerando la Inferencia de Difusión Estable en CPUs Intel
- Inferencia rápida en modelos de lenguaje grandes BLOOMZ en el acelerador Habana Gaudi2
- Boletín de Ética y Sociedad #3 Apertura Ética en Hugging Face
- StackLLaMA Una guía práctica para entrenar LLaMA con RLHF