Las Gemas Subestimadas Pt.1 8 Métodos de Pandas Que Te Convertirán en un Experto
Gemas Subestimadas Pt.1 8 Métodos de Pandas para Convertirte en un Experto
Subestimado, poco apreciado y poco explorado
“En medio del ruido de la multitud, son las palabras susurradas las que contienen la sabiduría oculta 💎”
Olvida ChatGPT por un momento. Para algunos de nosotros, nos cansamos de buscar soluciones en Google cada vez que queremos realizar una operación simple de Pandas. Parece haber numerosas formas de hacer lo mismo, ¿cuál es cuál? Tener muchas posibles soluciones para elegir, por supuesto, es genial, pero también conlleva inconsistencia y confusión al entender lo que se supone que hace la línea de código.
Hay 1000 rutas posibles para llegar a Roma, tal vez incluso más. La pregunta es, ¿tomas el atajo oculto o tomas la ruta complicada?

He aquí lo que puedes aprender de esta publicación. Te guiaré en cómo utilizar estos métodos en la práctica trabajando con el conjunto de datos de bicicletas compartidas de UCI Machine Learning¹. Al adoptar estos métodos, no solo optimizarás tu código de manipulación de datos, sino que también obtendrás una comprensión más profunda del código que escribes. ¡Empecemos importando el conjunto de datos y echando un vistazo rápido al DataFrame!
- Trabajando con MS SQL Server en Julia
- Optimiza eficazmente tu modelo de regresión con ajuste de hiperparámetros bayesianos
- Aprendizaje automático con efectos mixtos para datos longitudinales y de panel con GPBoost (Parte III)
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltbike = (pd .read_csv("../../dataset/bike_sharing/day.csv") )bike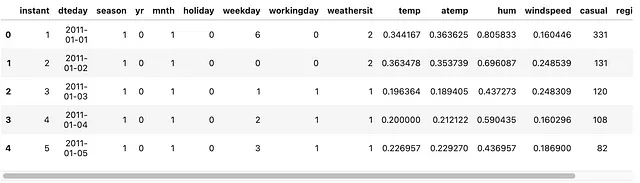
Tabla de contenidos
- Método #1:
.assign() - Método #2:
.groupby() - Método #3:
.agg() - Método #4:
.transform() - Método #5:
.pivot_table() - Método #6:
.resample() - Método #7:
.unstack() - Método #8:
.pipe()
☕️ Método #1: .assign()
Olvida el uso de operaciones como df["new_col"] = y df.new_col = para crear nuevas columnas. Aquí está por qué deberías usar el método .assign(): te devuelve un objeto DataFrame, lo que te permite continuar con tus operaciones encadenadas para manipular aún más tu DataFrame. A diferencia del método .assign(), las dos operaciones infames anteriores te devuelven un None, lo que significa que no puedes encadenar tus operaciones posteriormente.
Si no estás convencido, déjame traer de vuelta al viejo enemigo: SettingWithCopyWarning. Estoy seguro de que cada uno de nosotros se ha encontrado con esto en algún momento.

Basta de advertencias, ¡quiero dejar de ver esas feas cajas rojas en mi cuaderno!
Usando .assign(), agreguemos algunas nuevas columnas como ratio_casual_registered, avg_temp y ratio_squared
(bike .assign(ratio_casual_registered = bike.casual.div(bike.registered), avg_temp = bike.temp.add(bike.atemp).div(2), ratio_squared = lambda df_: df_.ratio_casual_registered.pow(2)))En resumen, esto es lo que hace el método anterior:
- Podemos crear tantas columnas nuevas como queramos utilizando el método
.assign(), separadas por la coma delimitadora. - La función lambda al crear la columna
ratio_squaredsirve para acceder al DataFrame más reciente después de haber agregado la columnaratio_casual_registered. Por ejemplo, si no usamos una función lambda para acceder al DataFrame más recientedf_, sino que continuamos conbike.ratio_casual_registered.pow(2), obtendríamos un error ya que el DataFrame original no tiene la columnaratio_casual_registered, incluso después de agregarla en el método.assign()antes de crearratio_squared. Si no puedes entender este concepto para decidir si debes o no usar una función lambda, ¡mi sugerencia es que simplemente uses una! - ¡Bonus! Dejo algunas formas no tan comunes de realizar operaciones aritméticas utilizando métodos.
☕️ Método #2: .groupby()
Bueno, el método .groupby() no es poco común de usar, pero es necesario para empezar antes de adentrarnos en los siguientes métodos. Una cosa que a menudo pasa desapercibida y no se menciona es que el método .groupby() tiene una naturaleza perezosa. Con esto quiero decir que el método se evalúa de forma perezosa. En otras palabras, no se evalúa de inmediato, por eso a menudo se ve <pandas.core.groupby.generic.DataFrameGroupBy object at 0x14fdc3610> justo después de llamar al método .groupby()
Según la documentación de Pandas DataFrame², el valor que se pasa al parámetro by puede ser un mapeo, función, etiqueta, pd.Grouper o una lista de ellos. No obstante, el más común con el que probablemente te encuentres es agrupar por nombres de columnas (una lista de nombres de Series separados por comas). Después de la operación .groupby(), podemos realizar operaciones como .mean(), .median(), o aplicar una función personalizada utilizando .apply().
El valor de las columnas especificadas que pasamos como parámetros en el método
byde.groupby()se convertirá en el índice del resultado. Si especificamos más de 1 columna para agrupar, obtendremos un MultiIndex.
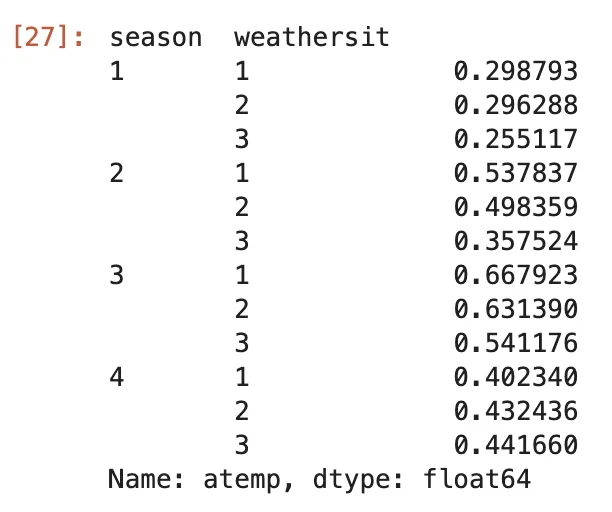
(bike .groupby(['season', 'weathersit']) .mean(numeric_only=True) #versión alternativa: apply(lambda df_: df_.mean(numeric_only=True)) .atemp)Aquí, agrupamos nuestro DataFrame por la columna season y weathersit. Luego, calculamos el valor medio y seleccionamos solo la columna atemp.
☕️ Método #3: .agg()
Si eres lo suficientemente meticuloso como para investigar en la documentación de Pandas², es posible que te encuentres con los métodos .agg() y .aggregate(). Puede que te preguntes cuál es la diferencia y cuándo usar cada uno. ¡Ahorra tiempo! Son lo mismo, .agg() es simplemente un alias de .aggregate().
.agg() tiene un parámetro func, que básicamente acepta una función, el nombre de una función como string o una lista de funciones. Por cierto, ¡también puedes agregar diferentes funciones a las columnas! ¡Continuemos con nuestro ejemplo anterior!
#Ejemplo 1: Agregando usando más de 1 función (bike .groupby(['season']) .agg(['mean', 'median']) .atemp)#Ejemplo 2: Agregando usando diferentes funciones para diferentes columnas (bike .groupby(['season']) .agg(Meann=('temp', 'mean'), Mediann=('atemp', np.median)))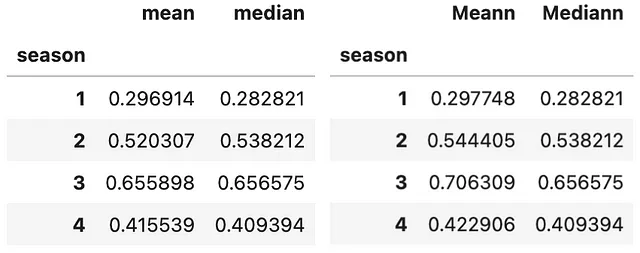
☕️ Método #4: .transform()
Con .agg(), el resultado que obtenemos tiene una dimensionalidad reducida en comparación con el conjunto de datos inicial. En términos simples, la dimensión de sus datos se reduce con un menor número de filas y columnas, que contienen la información agregada. Si lo que desea es resumir los datos agrupados y obtener valores agregados, entonces .groupby() es la solución.
Con .transform(), también comenzamos con la intención de hacer una agregación de información. Sin embargo, en lugar de crear un resumen de información, queremos que la salida tenga la misma forma que el DataFrame original, sin reducir el tamaño del DataFrame original.
Aquellos de ustedes que tienen experiencia en sistemas de bases de datos como SQL pueden encontrar que la idea detrás de .transform() es similar a la de una función de ventana. ¡Veamos cómo funciona .transform() en el ejemplo anterior!
(bike .assign(mean_atemp_season = lambda df_: df_ .groupby(['season']) .atemp .transform(np.mean, numeric_only=True)))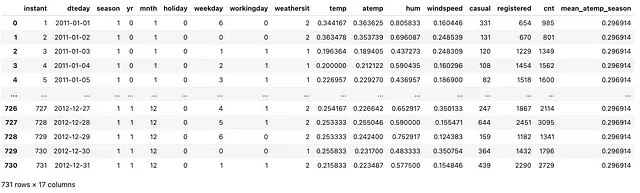
Como se puede ver arriba, creamos una nueva columna con el nombre de columna — mean_atemp_season donde llenamos la columna con el agregado (media) de la columna atemp. Por lo tanto, siempre que season es 1, tenemos el mismo valor para mean_atemp_season. ¡Observa que la observación importante aquí es que conservamos la dimensión original del conjunto de datos más una columna adicional!
☕️ Método #5: .pivot_table()
Aquí hay un bono para aquellos obsesionados con Microsoft Excel. Es posible que estés tentado de usar .pivot_table() para crear una tabla resumen. ¡Bueno, por supuesto, este método también funciona! Pero aquí hay una sugerencia, .groupby() es más versátil y se utiliza para una gama más amplia de operaciones más allá de solo remodelar, como filtrar, transformar o aplicar cálculos específicos de grupo.
Así es cómo se usa .pivot_table() en resumen. Especificas la(s) columna(s) que deseas agregar en el argumento values. A continuación, especificas el índice de la tabla resumen que deseas crear utilizando un subconjunto del DataFrame original. Esto puede ser más de una columna y la tabla resumen será un DataFrame de MultiIndex. A continuación, especificas las columnas de la tabla resumen que deseas crear utilizando un subconjunto del DataFrame original que no se ha seleccionado como el índice. ¡Por último pero no menos importante, no olvides especificar aggfunc! Echemos un vistazo rápido.
(bike .pivot_table(values=['temp', 'atemp'], index=['season'], columns=['workingday'], aggfunc=np.mean))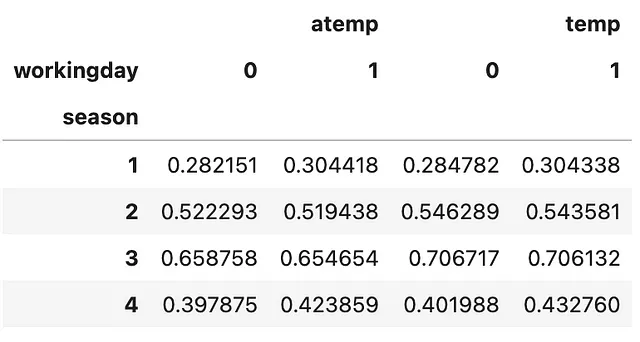
☕️ Método #6: .resample()
Hablando en términos generales, el método .resample() se puede ver como agrupar y agregar específicamente para datos de series temporales, donde
El índice del DataFrame o Serie es un objeto similar a una fecha y hora.
Esto te permite agrupar y agregar datos según diferentes frecuencias de tiempo, como por hora, diario, semanal, mensual, etc. Más en general, .resample() puede tomar DateOffset, Timedelta o str como la regla para realizar el remuestreo. Apliquemos esto a nuestro ejemplo anterior.
def tweak_bike(bike: pd.DataFrame) -> pd.DataFrame: return (bike .drop(columns=['instant']) .assign(dteday=lambda df_: pd.to_datetime(df_.dteday)) .set_index('dteday') )bike = tweak_bike(bike)(bike .resample('M') .temp .mean())En resumen, lo que hacemos anteriormente es eliminar la columna instant, sobrescribir la columna dteday con la columna dteday convertida de tipo object a tipo datetime64[ns], y finalmente establecer esta columna datetime64[ns] como el índice del DataFrame.
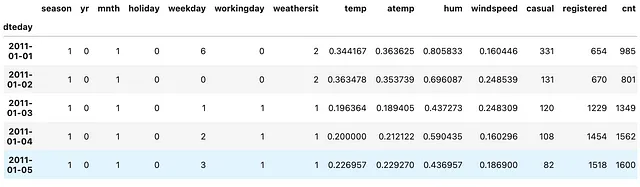
(bicicleta .resample('M') .temp .mean())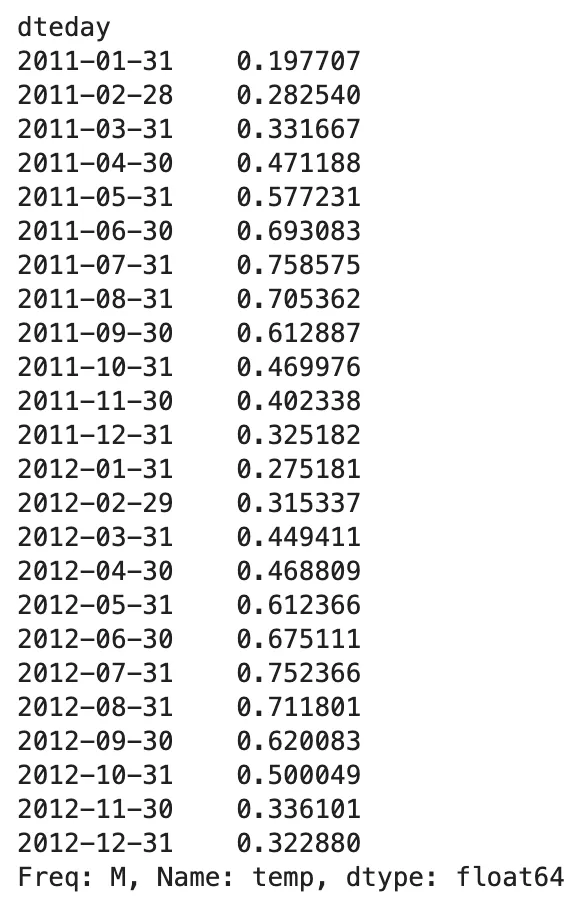
Aquí, obtenemos un resumen estadístico descriptivo (media) de la característica temp con frecuencia mensual. Intente y juegue con el método .resample() utilizando diferentes frecuencias como Q, 2M, A y así sucesivamente.
☕️ Método #7: .unstack()
¡Estamos cerca del final! Permítame mostrarle por qué .unstack() es tanto poderoso como útil. Pero antes, volvamos a uno de los ejemplos anteriores donde queremos encontrar la temperatura media en diferentes estaciones y situaciones climáticas utilizando .groupby() y .agg()
(bicicleta .groupby(['estación', 'situación_climática']) .agg('media') .temp)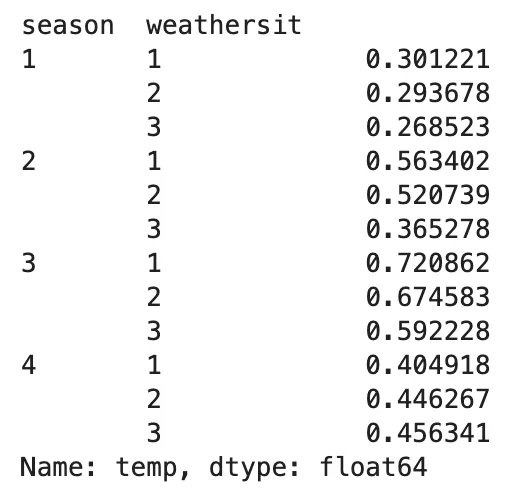
Ahora, visualicemos esto utilizando un gráfico de líneas producido mínimamente encadenando los métodos .plot y .line() al código anterior. Detrás de escena, Pandas aprovecha el backend de trazado de Matplotlib para realizar la tarea de trazado. Esto da como resultado lo siguiente, que ninguno de nosotros quería, ya que el eje x del gráfico está agrupado por el MultiIndex, lo que lo hace más difícil de interpretar y menos significativo.
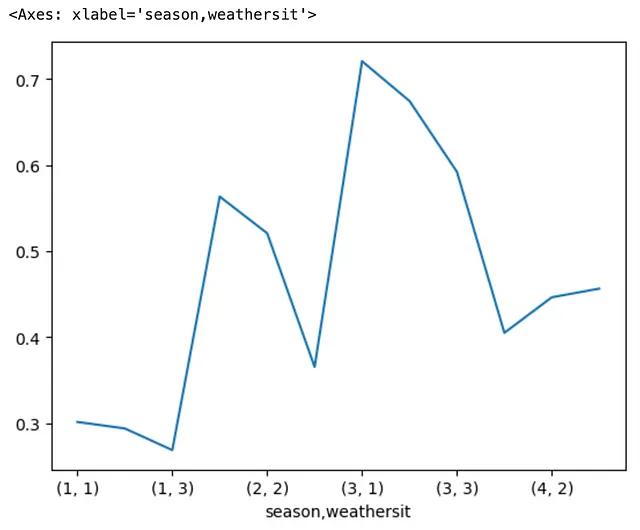
Compara el gráfico anterior y el siguiente después de que introducimos el método .unstack().
(bicicleta .groupby(['estación', 'situación_climática']) .agg('media') .temp .unstack() .plot .line())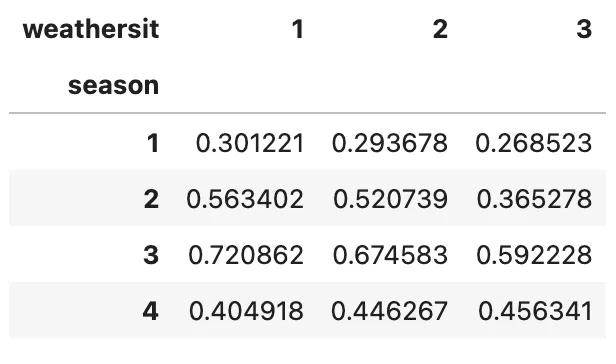
En resumen, lo que hace el método .unstack() es desapilar el índice más interno del DataFrame MultiIndex, que en este caso es situación_climática. Este índice desapilado se convierte en las columnas del nuevo DataFrame, lo que permite que nuestra trama de líneas dé resultados más significativos para fines de comparación.
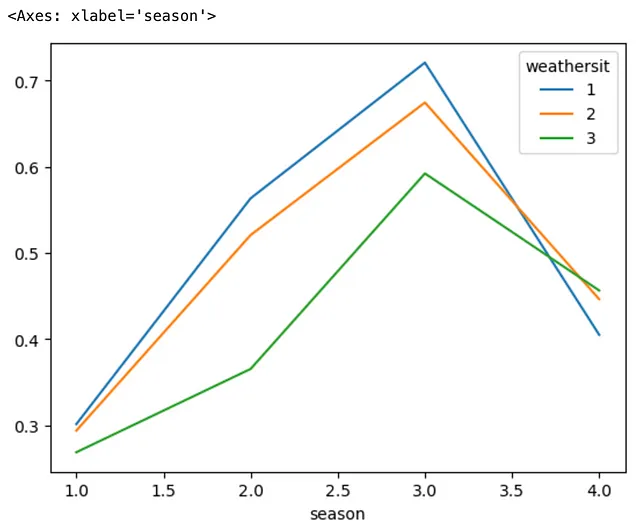
También puede desapilar el índice más externo en lugar del índice más interno del DataFrame, especificando el argumento level=0 como parte del método .unstack(). Veamos cómo podemos lograr esto.
(bicicleta .groupby(['estación', 'situación_climática']) .agg('media') .temp .unstack(level=0) .plot .line())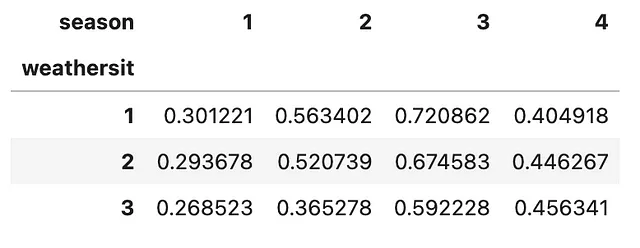
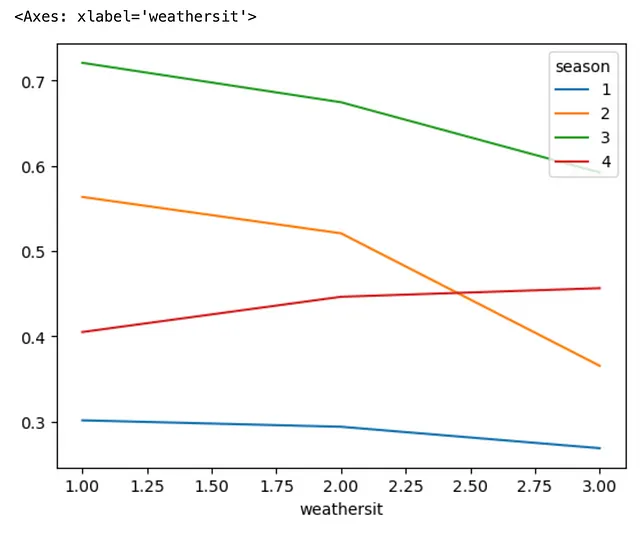
☕️ Método #8: .pipe()
Por lo que he observado, casi nunca ves a personas comunes implementar este método en su código de Pandas cuando buscas en línea. Por una razón, .pipe() de alguna manera tiene su propia aura misteriosa e inexplicable que no lo hace amigable para principiantes e intermedios por igual. Cuando vas a la documentación² de Pandas, la breve explicación que encontrarás es “Aplica funciones encadenables que esperan Series o DataFrames”. Creo que esta explicación es un poco confusa y no muy útil, especialmente si nunca has trabajado con encadenamiento antes.
En resumen, lo que .pipe() te ofrece es la capacidad de continuar tu técnica de encadenamiento de métodos utilizando una función, en caso de que no puedas encontrar una solución directa para realizar una operación y devolver un DataFrame.
El método .pipe() toma una función como argumento, de esa manera puedes definir un método fuera de la cadena y luego referirte al método como un argumento del método .pipe().
Con
.pipe(), puedes pasar un DataFrame o Series como el primer argumento a una función personalizada, y la función se aplicará al objeto que se pasa, seguido de cualquier argumento adicional especificado posteriormente.
La mayoría de las veces, verás una función lambda de una sola línea dentro del método .pipe() por conveniencia (es decir, tener acceso al DataFrame más reciente después de algunas etapas de modificación en el proceso de encadenamiento).
Permíteme ilustrar usando un ejemplo simplificado. Digamos que queremos obtener información sobre la siguiente pregunta: “Para el año 2012, ¿cuál es la proporción de días laborables por temporada, en relación con el total de días laborables de ese año?”
(bike .loc[bike.index.year == 2012] .groupby(['season']) .workingday .agg(sum) .pipe(lambda x: x.div(x.sum())))Aquí, usamos .pipe() para inyectar una función en nuestro método de encadenamiento. Dado que después de realizar .agg(sum), no podemos simplemente continuar encadenando con .div(), el siguiente código no funcionará ya que hemos perdido acceso al estado más reciente del DataFrame después de algunas modificaciones a través del proceso de encadenamiento.
#No funciona bien!(bike .loc[bike.index.year == 2012] .groupby(['season']) .workingday .agg(sum) .div(...))Consejo: ¡Si no puedes encontrar una forma de continuar encadenando tus métodos, intenta pensar en cómo
.pipe()puede ayudarte! La mayoría de las veces, ¡lo hará!
Epílogo
¡Esto concluye la primera parte de Las Gemas Infravaloradas 💎! Son todos métodos que no utilicé tanto antes, quizás debido a mi mal hábito de forzar mi código con el pensamiento de que “¡Mientras funcione, es suficiente!” Desafortunadamente, no lo es.
Solo después de dedicar tiempo a aprender cómo usarlos correctamente, resultan ser salvadores, por decir lo menos. También quiero agradecer a Matt Harrison y su libro Effective Pandas³, que cambió por completo la forma en que escribo mi código de Pandas. Ahora puedo decir que mi código es más conciso, legible y simplemente tiene más sentido.
Si encuentras algo útil en este artículo, considera seguirme en VoAGI. ¡Fácil, 1 artículo a la semana para mantenerte actualizado y estar por delante de la curva!
¡Conéctate Conmigo!
- LinkedIn 👔
- Twitter 🖊
Referencias
- Fanaee-T, Hadi. (2013). Conjunto de Datos de Compartir Bicicletas. Repositorio de Aprendizaje Automático de la UCI. https://doi.org/10.24432/C5W894.
- Documentación de Pandas: https://pandas.pydata.org/docs/reference/frame.html
- Effective Pandas por Matt Harrison: https://store.metasnake.com/effective-pandas-book
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Explora el poder de las imágenes dinámicas con Text2Cinemagraph una nueva herramienta de IA para la generación de cinemagraphs a partir de indicaciones de texto
- Introducción práctica a los modelos de Transformer BERT
- Principios efectivos de ingeniería de indicaciones para la aplicación de IA generativa
- Esta es la razón por la que deberías leer esto antes de usar Pandas en la limpieza de datos
- ChatGPT destronado cómo Claude se convirtió en el nuevo líder de IA
- Justin McGill, Fundador y CEO de Content at Scale – Serie de entrevistas
- Conoce a Tongyi Qianwen, el competidor de ChatGPT de Alibaba un modelo de lenguaje grande que se integrará en sus altavoces inteligentes Tmall Genie y en la plataforma de mensajería laboral DingTalk.






