Cómo gané en el fútbol de fantasía italiano ⚽ utilizando el aprendizaje automático
Gané en el fútbol de fantasía italiano usando aprendizaje automático ⚽
Descifrando el código de Fantacalcio a través del poder de la IA
Como ingeniero mecánico con un gran interés en la programación y la informática, me fasciné por el mundo del aprendizaje automático e inteligencia artificial hace unos años. Reconociendo su potencial en diversas disciplinas de ingeniería, me embarqué en un viaje para estudiar el aprendizaje automático. Sin embargo, a pesar de adquirir conocimientos teóricos, me costó encontrar formas prácticas de aplicar y poner en práctica mis nuevas habilidades. Si bien existían conjuntos de datos predefinidos, no proporcionaban la experiencia completa de recopilar y procesar datos. Entonces, se me ocurrió un pensamiento: ¿por qué no aplicar el aprendizaje automático para ayudarme a ganar en el fútbol fantasy?
Introducción a Fantacalcio

Fantacalcio es un juego muy popular entre los aficionados al fútbol italiano. Los participantes forman grupos y compiten durante todo el año basándose en las actuaciones de los jugadores reales en la Serie A, la principal liga de fútbol italiana. Antes del inicio de la temporada, los participantes realizan una subasta para seleccionar sus plantillas de más de 20 jugadores. Después de cada jornada de la Serie A, los jugadores reciben votos en función de su rendimiento, con bonificaciones adicionales por goles y asistencias. Estos votos acumulados y bonificaciones determinan las puntuaciones de los participantes. Uno de los aspectos cruciales del juego es seleccionar una alineación semanal de jugadores y tomar decisiones sobre quién jugar regularmente y quién dejar en el banquillo.
Objetivo de mi trabajo
El objetivo principal de mi algoritmo de aprendizaje automático sería predecir el voto y el fanta-voto (voto más bonificación) de los jugadores de la Serie A en función del partido de su equipo. El fútbol es un juego inherentemente incierto, ya que es imposible garantizar si un jugador marcará o no. Sin embargo, ciertos jugadores tienen una mayor probabilidad de marcar en comparación con otros, y su rendimiento puede variar según el equipo al que se enfrenten. Mi objetivo era encontrar un método objetivo para determinar qué jugador tenía una mayor probabilidad de ofrecer un mejor rendimiento en cualquier jornada de la Serie A.
Descargo de responsabilidad: secciones como esta se utilizarán en el artículo para proporcionar ejemplos reales de Fantacalcio, para ilustrar los conceptos discutidos. Si no estás familiarizado con el juego o los jugadores de la Serie A, siéntete libre de omitir estas secciones.
Recopilación y procesamiento de los datos
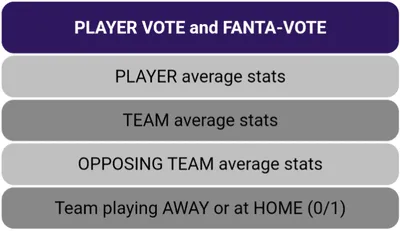
Una vez descargado el archivo de votos de Fantacalcio, el siguiente paso fue recopilar un conjunto completo de características para entrenar el algoritmo de aprendizaje automático. Para construir este conjunto de datos, encontré que fbref.com era un recurso invaluable, que proporcionaba una forma conveniente de recopilar estadísticas tanto de jugadores como de equipos de la Serie A. El sitio ofrecía una amplia gama de estadísticas meticulosamente compiladas, que abarcaban diversas métricas como goles esperados, entradas, pases y número promedio de oportunidades creadas. La abundancia de datos detallados disponibles en FBRef facilitó en gran medida el proceso de reunir un conjunto sólido de características para entrenar el algoritmo de aprendizaje automático.


El enfoque que adopté implicó la construcción de un conjunto de datos que comprende más de 50 características para cada jugador. Este conjunto de datos combina las estadísticas promedio procesadas del jugador, fusionadas con las estadísticas de su equipo y las estadísticas del equipo contrario para una jornada de partidos determinada. Las salidas objetivo para cada fila del conjunto de datos fueron el voto del jugador y el voto de fantasía. Para construir el conjunto de datos, se consideraron las últimas tres temporadas de la Serie A.
Para abordar el desafío de las estadísticas poco confiables para los jugadores con poco tiempo de juego en la temporada, empleé tres estrategias:
- Promedio ponderado con las estadísticas de la temporada anterior.
- En ausencia de datos históricos confiables, las estadísticas del jugador se promediaron con las de un jugador promedio en un rol similar.
- Utilicé una lista predefinida para promediar parcialmente las estadísticas de un jugador con las de un jugador anterior del mismo equipo que desempeñó un rol similar.
Por ejemplo, el rendimiento del novato Kim del Napoli podría compararse con el rendimiento anterior de Koulibaly, o el rendimiento de Thauvin podría evaluarse en relación con su predecesor, Deulofeu (pero esto resultó ser incorrecto).
Definición y entrenamiento del algoritmo
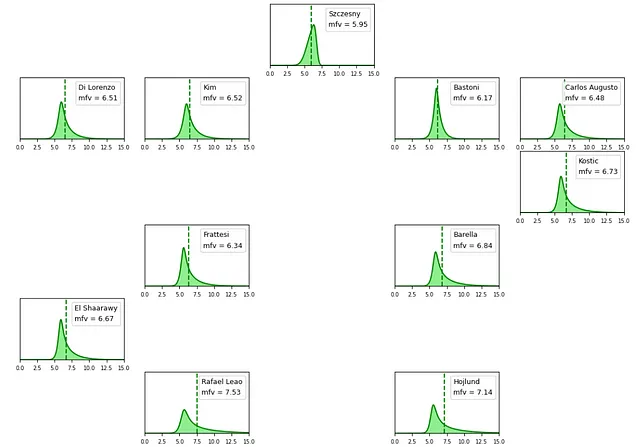
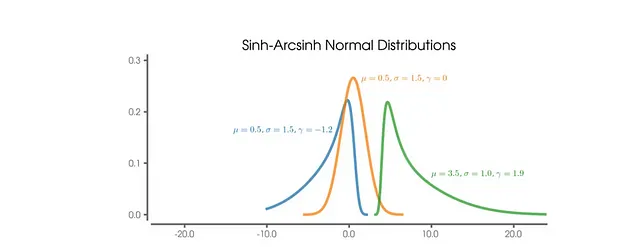
Para hacer las cosas más interesantes y que los resultados sean más agradables de visualizar, se diseñó un algoritmo de aprendizaje automático que va más allá de las simples predicciones de voto y voto de fantasía. En su lugar, se adoptó un enfoque probabilístico, aprovechando TensorFlow y TensorFlow Probability para construir una red neuronal capaz de generar una distribución de probabilidad. Específicamente, la red predecía los parámetros de una distribución de probabilidad sinh-arcsinh. Esta elección se hizo para tener en cuenta la sesgo inherente en la distribución del voto del rendimiento del jugador. Por ejemplo, en el caso de un jugador ofensivo, aunque su voto de fantasía promedio puede ser alrededor de 6.5, el algoritmo reconocía que un voto de 10 (que indica un rendimiento excepcional, como marcar un gol) sería mucho más probable que ocurriera que un voto de 4 (que representa un rendimiento deficiente raro).
La arquitectura de la red neuronal profunda utilizada para esta tarea comprendía múltiples capas densas, cada una utilizando la función de activación sigmoide. Para evitar el sobreajuste y mejorar la generalización, se utilizaron técnicas de regularización como Dropout y Early Stopping. Dropout desactiva aleatoriamente una fracción de las unidades de la red neuronal durante el entrenamiento, mientras que Early Stopping detiene el proceso de entrenamiento si la pérdida de validación deja de mejorar. La función de pérdida elegida para entrenar el modelo fue Negative Log Likelihood, que mide la discrepancia entre la distribución de probabilidad predicha y los resultados reales.
A continuación se muestra un fragmento del código escrito para construir la red neuronal:
callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience = 10)neg_log_likelihood = lambda x, rv_x: -rv_x.log_prob(x)inputs = tfk.layers.Input(shape=(X_len,), name="input")x = tfk.layers.Dropout(0.2)(inputs)x = tfk.layers.Dense(16, activation="relu") (x)x = tfk.layers.Dropout(0.2)(x)x = tfk.layers.Dense(16, activation="relu") (x)prob_dist_params = 4def prob_dist(t): return tfp.distributions.SinhArcsinh(loc=t[..., 0], scale=1e-3 + tf.math.softplus(t[..., 1]), skewness = t[..., 2], tailweight = tailweight_min + tailweight_range * tf.math.sigmoid(t[..., 3]), allow_nan_stats = False)x1 = tfk.layers.Dense(8, activation="sigmoid")(x)x1 = tfk.layers.Dense(prob_dist_params, activation="linear")(x1)out_1 = tfp.layers.DistributionLambda(prob_dist)(x1)x2 = tfk.layers.Dense(8, activation="sigmoid")(x)x2 = tfk.layers.Dense(prob_dist_params, activation="linear")(x2)out_2 = tfp.layers.DistributionLambda(prob_dist)(x2)modelb = tf.keras.Model(inputs, [out_1, out_2])modelb.compile(optimizer=tf.keras.optimizers.Nadam(learning_rate = 0.001), loss=neg_log_likelihood)modelb.fit(X_train.astype('float32'), [y_train[:, 0].astype('float32'), y_train[:, 1].astype('float32')], validation_data = (X_test.astype('float32'), [y_test[:, 0].astype('float32'), y_test[:, 1].astype('Empleando la red neuronal para predicciones
El algoritmo entrenado ofrecía predicciones de distribución de probabilidad para el voto de un jugador y el voto de fantasía. Al considerar las estadísticas promediadas del jugador, la información del equipo, los datos del oponente y los factores de local/visitante, era capaz de predecir el rendimiento del jugador para futuros partidos de la Serie A. A través del postprocesamiento de las distribuciones de probabilidad, se podía obtener una predicción numérica esperada del voto y un voto máximo potencial, simplificando la toma de decisiones para la selección de alineaciones en Fantacalcio.
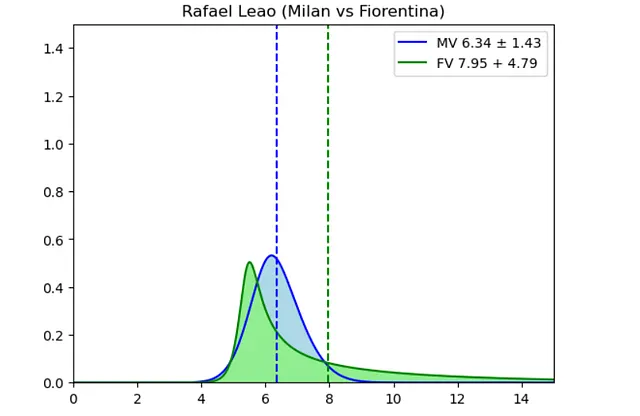
Utilizando la técnica de Monte Carlo, las distribuciones de probabilidad de cada jugador se emplearon para predecir el voto total esperado de una alineación. El método de Monte Carlo implica ejecutar múltiples simulaciones aleatorias para estimar posibles resultados. ¡Y eso es todo! Tenía todas las herramientas que me permitían elegir la mejor alineación de mi plantilla de Fantacalcio para cada jornada de la Serie A.

Donde el algoritmo tuvo éxito
Como una métrica adicional, comparé los votos esperados con mis propias expectativas subjetivas y encontré los resultados satisfactorios. El algoritmo demostró ser particularmente efectivo en la variante Mantra de Fantacalcio, que implica que los jugadores asuman múltiples roles similares al fútbol real, desde defensas centrales y laterales hasta extremos y delanteros. Seleccionar la alineación óptima de los módulos disponibles presentaba un desafío complejo, ya que no siempre era el caso de que los jugadores ofensivos superaran a los defensivos.
Además, al utilizar el algoritmo para predecir la selección de un equipo de la Serie A con estadísticas promedio como oponente, fue útil para prepararse para la subasta del mercado de enero. Me permitió identificar jugadores subvalorados que pueden haber sido subestimados por la opinión popular.
Jugadores como El Shaarawy y Orsolini son ejemplos destacados de jugadores que tuvieron un rendimiento excepcional en las etapas posteriores de la temporada de la Serie A. El algoritmo predijo que su rendimiento esperado estaría al nivel de otros centrocampistas de élite ya a fines de enero.
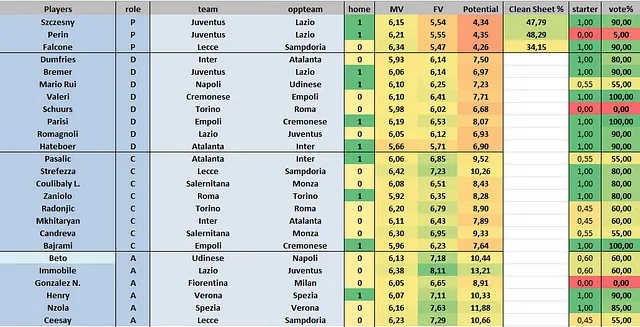
Donde falló o se podría mejorar
El punto débil del algoritmo radica en predecir el rendimiento de los porteros. Se desarrolló una red neuronal separada, utilizando diferentes características y agregando la probabilidad de mantener la portería a cero como resultado. Sin embargo, los resultados no fueron tan satisfactorios, probablemente debido al número limitado de porteros (solo uno por equipo) en comparación con los jugadores de campo. Esto resultó en un conjunto de datos menos diverso, aumentando el riesgo de sobreajuste.
Además, el algoritmo solo consideró las estadísticas promedio de cada jugador durante toda la temporada. Si bien este enfoque fue suficiente, incorporar datos de los dos o tres partidos anteriores del jugador antes de una determinada jornada podría mejorar la capacidad del algoritmo para tener en cuenta su forma actual. Esto proporcionaría una evaluación más completa del rendimiento reciente del jugador.
Todo el trabajo en público
Puedes encontrar el código escrito para este proyecto, así como los resultados generados para varias jornadas de la Serie A en Github. Planeo realizar más mejoras para la próxima temporada siempre que el tiempo lo permita. Si tienes alguna pregunta o necesitas aclaraciones, no dudes en contactarme.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Explorando las últimas tendencias en IA/DL Desde el Metaverso hasta la Computación Cuántica
- Mejores plataformas para encontrar trabajos remotos en 2023
- 10 formas de utilizar el complemento del intérprete de código ChatGPT
- Experimenta la Realidad Aumentada (AR) directamente con tus propios ojos utilizando la IA
- Inteligencia Artificial vs. Inteligencia Humana Top 7 Diferencias
- Una introducción a la llamada de funciones de OpenAI
- El jefe de Microsoft no está preocupado de que la inteligencia artificial se apodere’.





