Proyecto de Ciencia de Datos de Predicción de Calificación de Películas de Rotten Tomatoes Primer Enfoque
'First Approach Rotten Tomatoes Movie Rating Prediction Data Science Project'
Prediciendo el estado de una película basado en características numéricas y categóricas.

No es ningún secreto que predecir el éxito de una película en la industria del entretenimiento puede hacer o deshacer las perspectivas financieras de un estudio.
Las predicciones precisas permiten a los estudios tomar decisiones bien informadas sobre diversos aspectos, como el marketing, la distribución y la creación de contenido.
- Después de Twitter
- Gestionando los costos de almacenamiento en la nube de aplicaciones de Big Data
- Cómo utilizar el método loc de Pandas para trabajar eficientemente con su DataFrame.
Lo mejor de todo es que estas predicciones pueden ayudar a maximizar los beneficios y minimizar las pérdidas optimizando la asignación de recursos.
Afortunadamente, las técnicas de aprendizaje automático proporcionan una herramienta poderosa para abordar este problema complejo. No hay duda al respecto, al aprovechar los conocimientos basados en datos, los estudios pueden mejorar significativamente su proceso de toma de decisiones.
Este proyecto de ciencia de datos se ha utilizado como una tarea para llevar a casa en el proceso de contratación en Meta (Facebook). En esta tarea para llevar a casa, descubriremos cómo Rotten Tomatoes está etiquetando como ‘Podrida’, ‘Fresca’ o ‘Certified Fresh’.
Para hacer eso, desarrollaremos dos enfoques diferentes.
A lo largo de nuestra exploración, discutiremos la preprocesamiento de datos, varios clasificadores y posibles mejoras para mejorar el rendimiento de nuestros modelos.
Al final de este artículo, habrás adquirido una comprensión de cómo se puede emplear el aprendizaje automático para predecir el éxito de una película y cómo se puede aplicar este conocimiento en la industria del entretenimiento.
Pero antes de profundizar, descubramos los datos en los que trabajaremos.
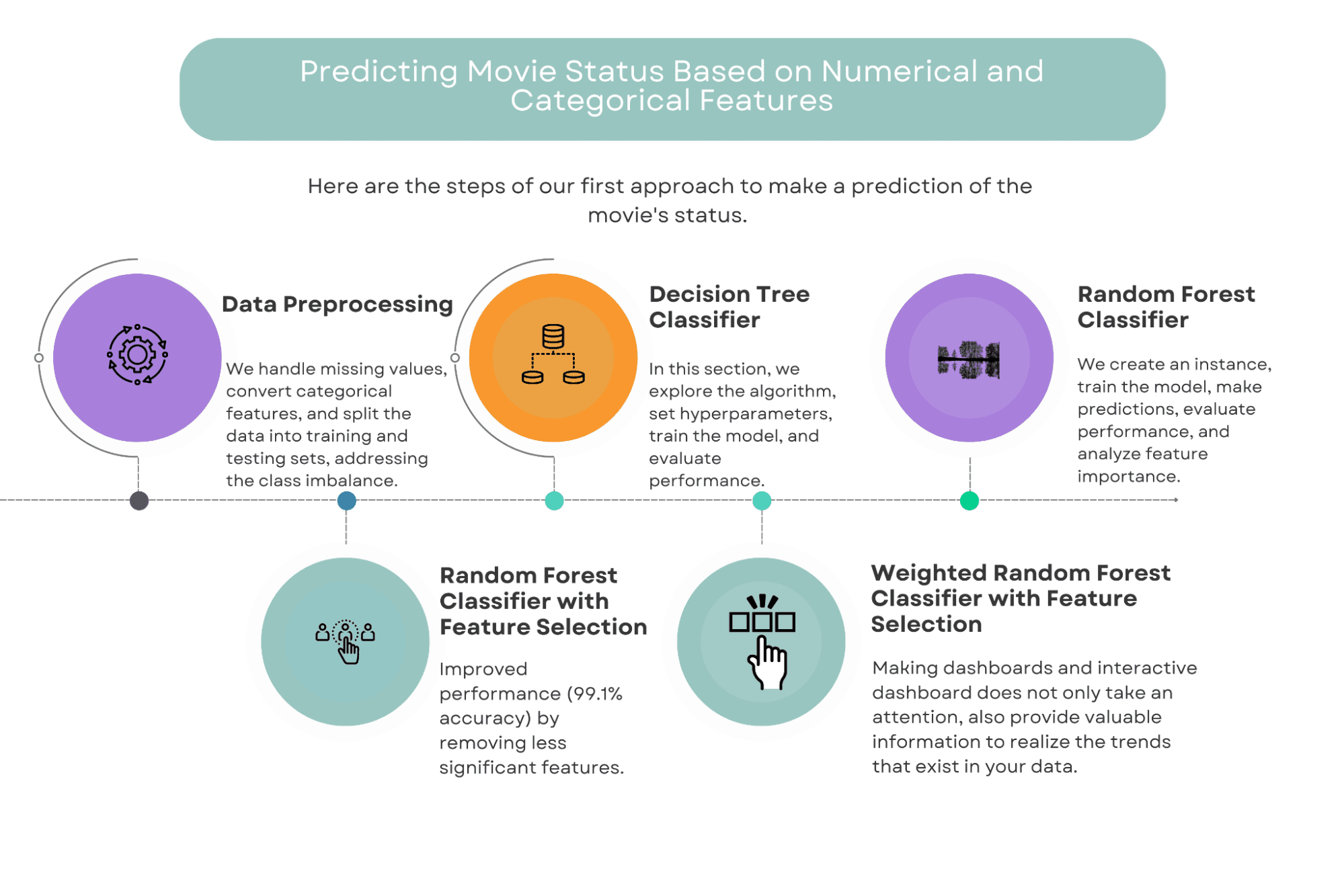
Primer Enfoque: Predicción del estado de la película basado en características numéricas y categóricas
En este enfoque, utilizaremos una combinación de características numéricas y categóricas para predecir el éxito de una película.
Las características que consideraremos incluyen factores como presupuesto, género, duración y director, entre otros.
Utilizaremos varios algoritmos de aprendizaje automático para construir nuestros modelos, incluyendo árboles de decisión, bosques aleatorios y bosques aleatorios ponderados con selección de características.
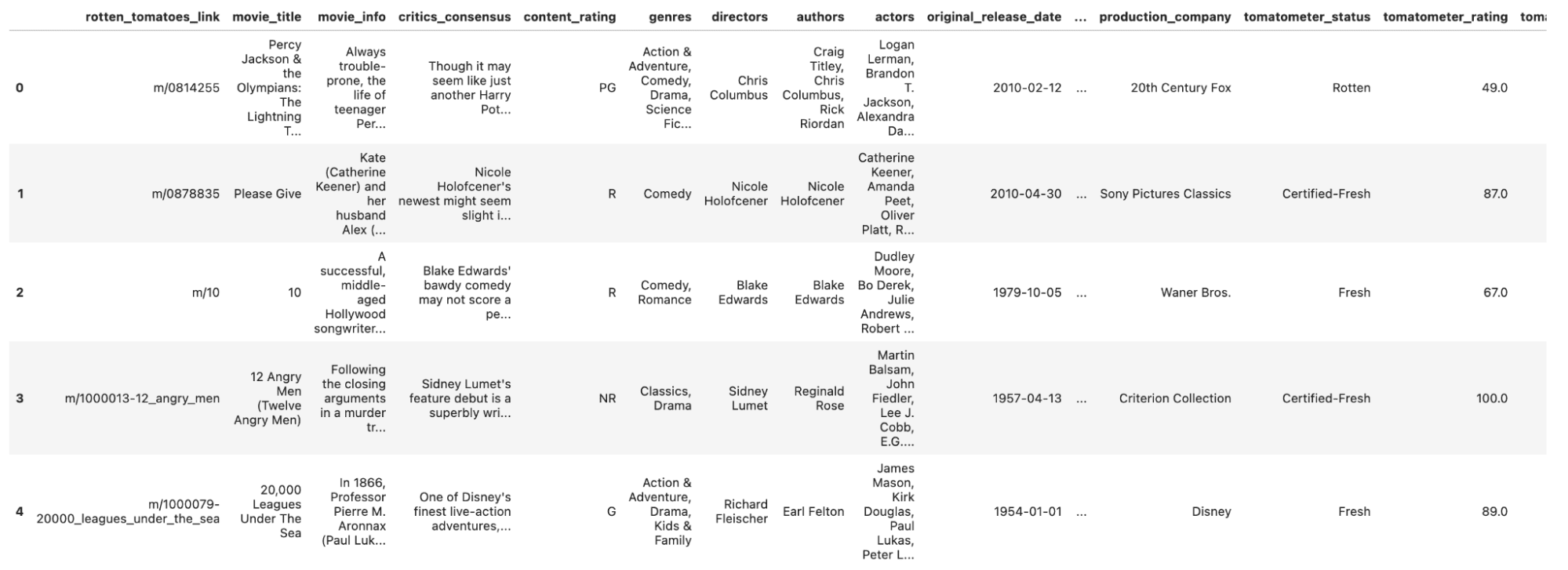
Leamos nuestros datos y echemos un vistazo.
Aquí está el código.
df_movie = pd.read_csv('rotten_tomatoes_movies.csv')
df_movie.head()Aquí está la salida.
Ahora, comencemos con el preprocesamiento de datos.
Hay muchas columnas en nuestro conjunto de datos.
Veamos.
Para desarrollar una mejor comprensión de las características estadísticas, usemos el método describe (). Aquí está el código.
df_movie.describe()Aquí está la salida.

Ahora tenemos una visión general rápida de nuestros datos, vamos a la etapa de preprocesamiento.
Preprocesamiento de datos
Antes de poder comenzar a construir nuestros modelos, es esencial preprocesar nuestros datos.
Esto implica limpiar los datos al manejar características categóricas y convertirlas en representaciones numéricas, y escalar los datos para asegurarnos de que todas las características tengan la misma importancia.
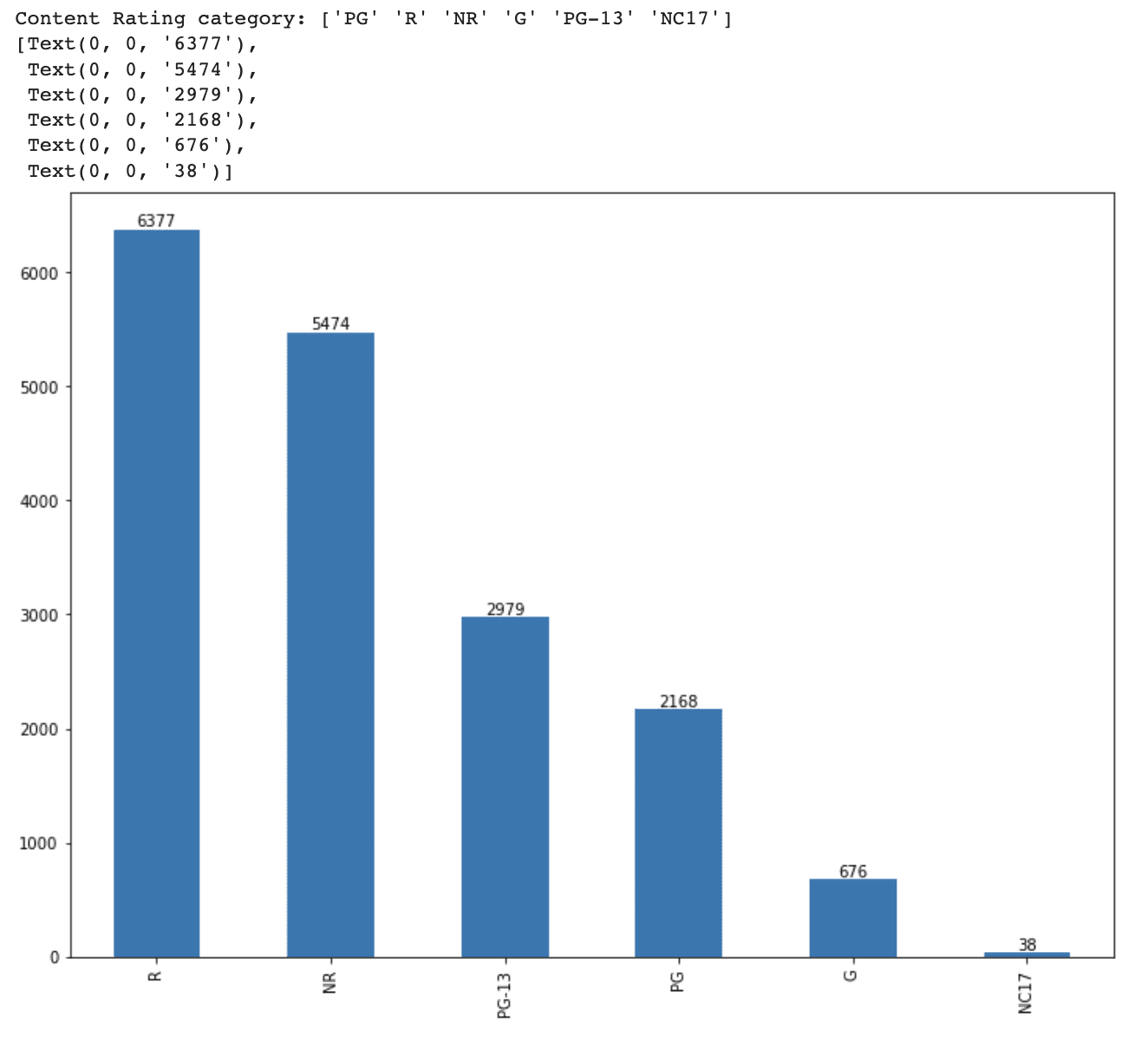
Primero examinamos la columna content_rating para ver las categorías únicas y su distribución en el conjunto de datos.
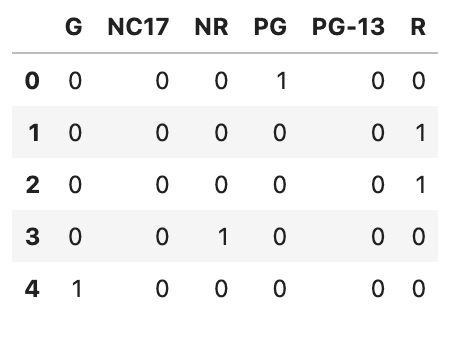
print(f'Categoría de Clasificación de Contenido: {df_movie.content_rating.unique()}')Luego, crearemos un gráfico de barras para ver la distribución de cada categoría de clasificación de contenido.
ax = df_movie.content_rating.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])Aquí está el código completo.
print(f'Categoría de Clasificación de Contenido: {df_movie.content_rating.unique()}')
ax = df_movie.content_rating.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])Aquí está la salida.
Es esencial convertir características categóricas en formas numéricas para nuestros modelos de aprendizaje automático que requieren entradas numéricas. Para varios elementos en este proyecto de ciencia de datos, vamos a aplicar dos métodos generalmente aceptados: codificación ordinal y codificación one-hot. La codificación ordinal es mejor cuando las categorías implican un grado de intensidad, pero la codificación one-hot es ideal cuando no se proporciona una representación de magnitud. Para los activos de “content_rating”, utilizaremos un método de codificación one-hot.
Aquí está el código.
content_rating = pd.get_dummies(df_movie.content_rating)
content_rating.head()Aquí está la salida.
Continuemos y procesemos otra característica, audience_status.
Esta variable tiene dos opciones: ‘Spilled’ y ‘Upright’.
Ya hemos aplicado la codificación one-hot, así que ahora es el momento de transformar esta variable categórica en una numérica usando la codificación ordinal.
Como cada categoría ilustra un orden de magnitud, transformaremos estas en valores numéricos usando la codificación ordinal.
Como hicimos anteriormente, primero busquemos los estados únicos de la audiencia.
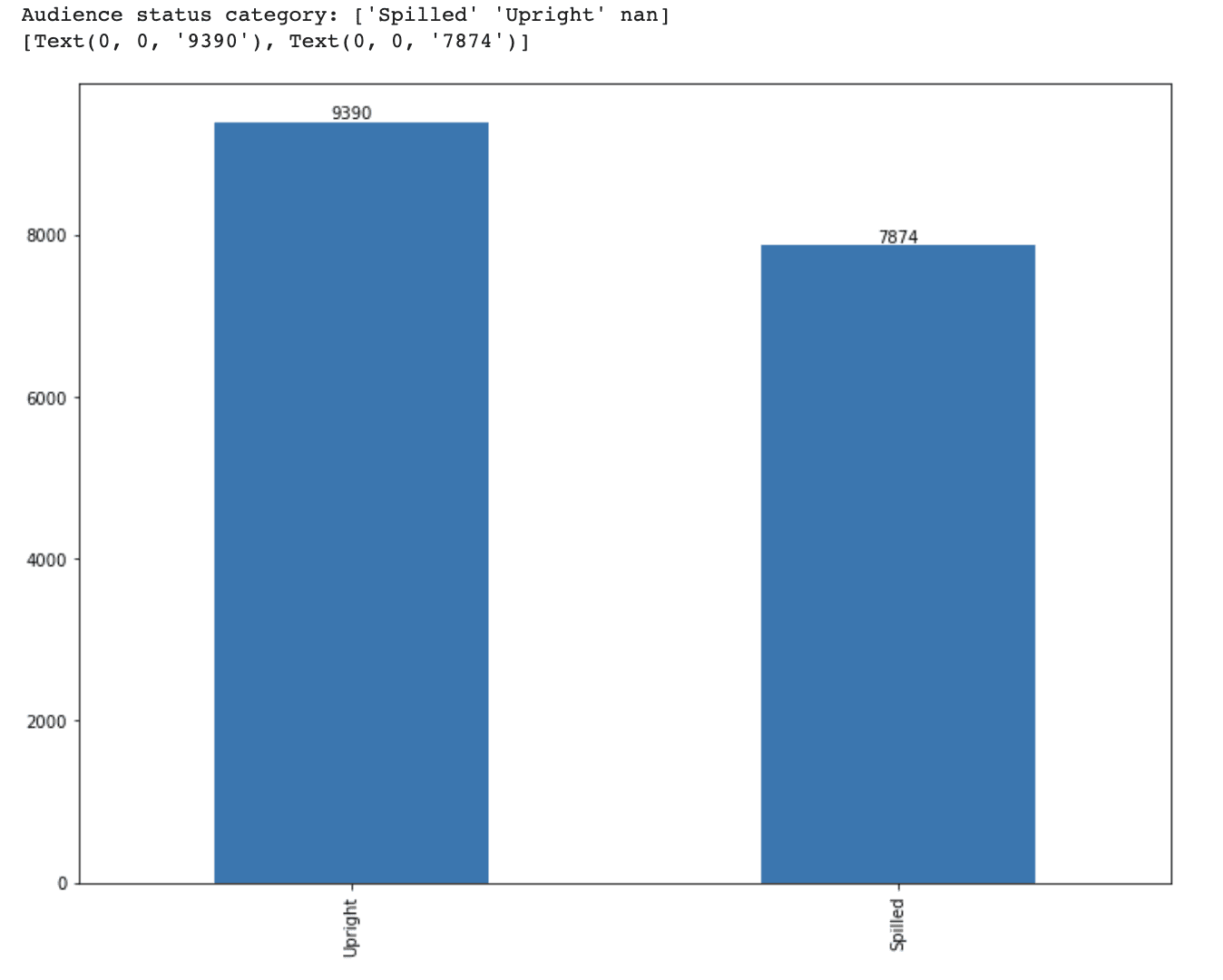
print(f'Categoría de estado de la audiencia: {df_movie.audience_status.unique()}')Luego, creemos un gráfico de barras y imprimamos los valores encima de las barras.
# Visualizar la distribución de cada categoría
ax = df_movie.audience_status.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])Aquí está el código completo.
print(f'Categoría de estado de la audiencia: {df_movie.audience_status.unique()}')
# Visualizar la distribución de cada categoría
ax = df_movie.audience_status.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])Aquí está la salida.
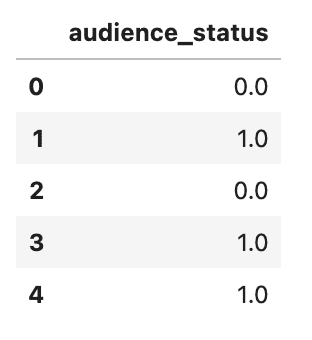
De acuerdo, ahora es el momento de hacer la codificación ordinal usando el método replace.
Luego veamos las primeras cinco filas usando el método head().
Aquí está el código.
# Codificar la variable de estado de la audiencia con codificación ordinal
audience_status = pd.DataFrame(df_movie.audience_status.replace(['Spilled','Upright'],[0,1]))
audience_status.head()Aquí está la salida.
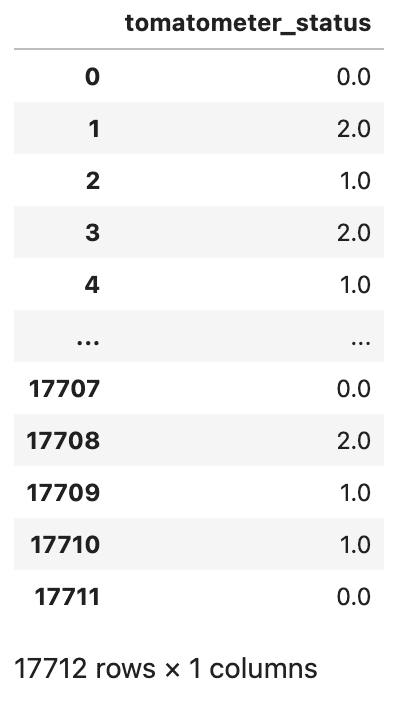
Dado que nuestra variable objetivo, tomatometer_status, tiene tres categorías distintas, ‘Rotten’, ‘Fresh’ y ‘Certified-Fresh’, estas categorías también representan un orden de magnitud.
Por eso, nuevamente haremos la codificación ordinal para transformar estas variables categóricas en variables numéricas.
Aquí está el código.
# Codificar la variable de estado de tomatometer con codificación ordinal
tomatometer_status = pd.DataFrame(df_movie.tomatometer_status.replace(['Rotten','Fresh','Certified-Fresh'],[0,1,2]))
tomatometer_statusAquí está la salida.
Después de cambiar de categórico a numérico, ahora es el momento de combinar los dos marcos de datos. Usaremos la función pd.concat() de Pandas para esto, y el método dropna() para eliminar filas con valores faltantes en todas las columnas.
Después de eso, usaremos la función head para ver el DataFrame recién formado.
Aquí está el código.
df_feature = pd.concat([df_movie[['runtime', 'tomatometer_rating', 'tomatometer_count', 'audience_rating', 'audience_count', 'tomatometer_top_critics_count', 'tomatometer_fresh_critics_count', 'tomatometer_rotten_critics_count']], content_rating, audience_status, tomatometer_status], axis=1).dropna()
df_feature.head()Aquí está la salida.

Genial, ahora vamos a inspeccionar nuestras variables numéricas utilizando el método describe.
Aquí está el código.
df_feature.describe()Aquí está la salida.

Ahora vamos a verificar la longitud de nuestro DataFrame utilizando el método len.
Aquí está el código.
len(df)Aquí está la salida.

Después de eliminar las filas con valores faltantes y hacer la transformación para construir el aprendizaje automático, ahora nuestro marco de datos tiene 17017 filas.
Ahora vamos a analizar la distribución de nuestras variables objetivo.
Como hemos estado haciendo constantemente desde el principio, dibujaremos un gráfico de barras y colocaremos los valores en la parte superior de la barra.
Aquí está el código.
ax = df_feature.tomatometer_status.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])Aquí está la salida.

Nuestro conjunto de datos contiene 7375 películas ‘Rotten’, 6475 películas ‘Fresh’ y 3167 películas ‘Certified-Fresh’, lo que indica un problema de desequilibrio de clases.
El problema se abordará más adelante.
Por el momento, vamos a dividir nuestro conjunto de datos en conjuntos de prueba y entrenamiento utilizando una división del 80% al 20%.
Aquí está el código.
X_train, X_test, y_train, y_test = train_test_split(df_feature.drop(['tomatometer_status'], axis=1), df_feature.tomatometer_status, test_size= 0.2, random_state=42)
print(f'El tamaño de los datos de entrenamiento es {len(X_train)} y el tamaño de los datos de prueba es {len(X_test)}')Aquí está la salida.

Clasificador de Árbol de Decisión
En esta sección, vamos a ver el Clasificador de Árbol de Decisión, una técnica de aprendizaje automático que se utiliza comúnmente para problemas de clasificación y a veces para regresión.
El clasificador trabaja dividiendo los puntos de datos en ramas, cada una de las cuales tiene un nodo interno (que incluye un conjunto de condiciones) y un nodo hoja (que tiene el valor predicho).
Al seguir estas ramas y considerar las condiciones (Verdadero o Falso), los puntos de datos se separan en las categorías adecuadas. El proceso se muestra a continuación.
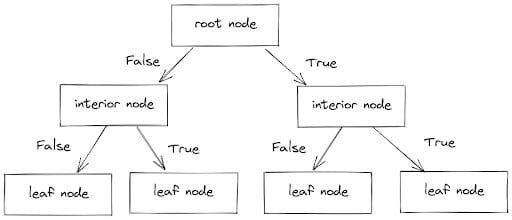 Imagen de Autor
Imagen de Autor
Cuando aplicamos un Clasificador de Árbol de Decisión, podemos alterar múltiples hiperparámetros, como la profundidad máxima del árbol y el número máximo de nodos hoja.
Para nuestro primer intento, limitaremos el número de nodos hoja a tres para que el árbol sea simple y comprensible.
Para empezar, crearemos un objeto Clasificador de Árbol de Decisión con un máximo de tres nodos hoja. Este clasificador se entrenará con nuestros datos de entrenamiento y se utilizará para generar predicciones en los datos de prueba. Por último, examinaremos la precisión, la precisión y las métricas de recuperación para evaluar el rendimiento de nuestro Clasificador de Árbol de Decisión limitado.
Ahora vamos a implementar el algoritmo del Árbol de Decisión paso a paso con sci-kit learn.
Primero, vamos a definir un objeto Clasificador de Árbol de Decisión con un máximo de tres nodos hoja, utilizando la función DecisionTreeClassifier() de la biblioteca scikit-learn.
El parámetro random_state se utiliza para asegurar que se produzcan los mismos resultados cada vez que se ejecute el código.
tree_3_leaf = DecisionTreeClassifier(max_leaf_nodes= 3, random_state=2)Luego es el momento de entrenar el Clasificador de Árbol de Decisión en los datos de entrenamiento (X_train y y_train), utilizando el método .fit().
tree_3_leaf.fit(X_train, y_train)A continuación, realizamos predicciones en los datos de prueba (X_test) utilizando el clasificador entrenado con el método predict.
y_predict = tree_3_leaf.predict(X_test)Aquí imprimimos el puntaje de precisión y el informe de clasificación de los valores predichos en comparación con los valores reales del objetivo de los datos de prueba. Utilizamos las funciones accuracy_score() y classification_report() de la biblioteca scikit-learn.
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))Finalmente, trazaremos la matriz de confusión para visualizar el rendimiento del Clasificador de Árbol de Decisión en los datos de prueba. Utilizamos la función plot_confusion_matrix() de la biblioteca scikit-learn.
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(tree_3_leaf, X_test, y_test, cmap='cividis', ax=ax)Aquí está el código.
# Instantiate Decision Tree Classifier with max leaf nodes = 3
tree_3_leaf = DecisionTreeClassifier(max_leaf_nodes= 3, random_state=2)
# Train the classifier on the training data
tree_3_leaf.fit(X_train, y_train)
# Predict the test data with trained tree classifier
y_predict = tree_3_leaf.predict(X_test)
# Print accuracy and classification report on test data
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# Plot confusion matrix on test data
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(tree_3_leaf, X_test, y_test, cmap ='cividis', ax=ax)Aquí está la salida.

Se puede ver claramente a partir de la salida que nuestro Árbol de Decisión funciona bien, especialmente teniendo en cuenta que lo limitamos a tres nodos hoja. Una de las ventajas de tener un clasificador simple es que el árbol de decisión se puede visualizar y comprender.
Ahora, para comprender cómo toma decisiones el árbol de decisión, visualicemos el clasificador de árbol de decisión utilizando el método plot_tree de sklearn.tree.
Aquí está el código.
fig, ax = plt.subplots(figsize=(12, 9))
plot_tree(tree_3_leaf, ax= ax)
plt.show()Aquí está la salida.
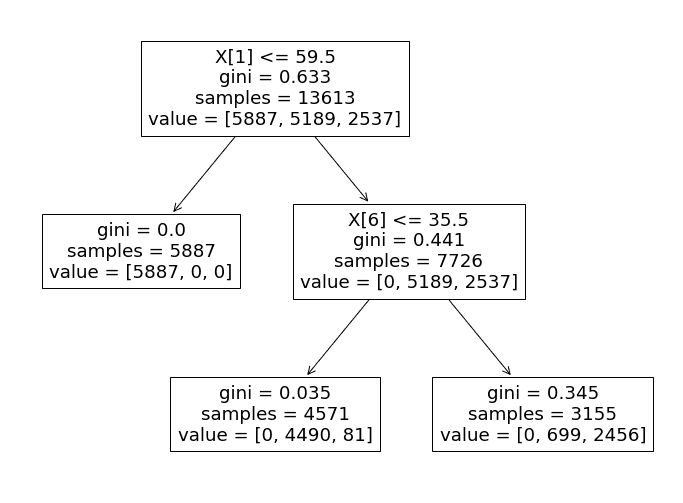
Ahora analicemos este árbol de decisión y descubramos cómo lleva a cabo el proceso de toma de decisiones.
Específicamente, el algoritmo utiliza la característica ‘tomatometer_rating’ como el determinante principal de la clasificación de cada punto de datos de prueba.
- Si el ‘tomatometer_rating’ es menor o igual a 59.5, se asigna al punto de datos una etiqueta de 0 (‘Podrido’). De lo contrario, el clasificador avanza hacia la siguiente rama.
- En la segunda rama, el clasificador utiliza la característica ‘tomatometer_fresh_critics_count’ para clasificar los puntos de datos restantes.
- Si el valor de esta característica es menor o igual a 35.5, se etiqueta al punto de datos como 1 (‘Fresco’).
- De lo contrario, se etiqueta como 2 (‘Certificado-Fresco’).
Este proceso de toma de decisiones se alinea estrechamente con las reglas y criterios que utiliza Rotten Tomatoes para asignar el estado de las películas.
Según el sitio web de Rotten Tomatoes, las películas se clasifican como
- ‘Fresco’ si su tomatometer_rating es del 60% o más.
- ‘Podrido’ si es inferior al 60%.
Nuestro Clasificador de Árbol de Decisión sigue una lógica similar, clasificando las películas como ‘Podrido’ si su tomatometer_rating es inferior a 59.5 y ‘Fresco’ en caso contrario.
Sin embargo, al distinguir entre películas ‘Fresco’ y ‘Certificado-Fresco’, el clasificador debe tener en cuenta varias características más.
Según Rotten Tomatoes, las películas deben cumplir con criterios específicos para ser clasificadas como ‘Certificado-Fresco’, como:
- Tener una puntuación de Tomatometer consistente de al menos el 75%
- Al menos cinco reseñas de críticos destacados.
- Mínimo de 80 reseñas para películas de estreno amplio.
Nuestro modelo de Árbol de Decisiones limitado solo tiene en cuenta el número de críticas de los principales críticos para diferenciar entre películas ‘Fresh’ y ‘Certified-Fresh’.
Ahora, entendemos la lógica detrás del Árbol de Decisiones. Entonces, para aumentar su rendimiento, sigamos los mismos pasos pero esta vez no agregaremos el argumento de nodos máximos.
Aquí está la explicación paso a paso de nuestro código. Esta vez no expandiré el código demasiado como lo hicimos antes.
Define el clasificador del árbol de decisiones.
tree = DecisionTreeClassifier(random_state=2)Entrena el clasificador con los datos de entrenamiento.
tree.fit(X_train, y_train)Predice los datos de prueba con un clasificador de árbol entrenado.
y_predict = tree.predict(X_test)Imprime la precisión y el informe de clasificación.
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))Diagrama de matriz de confusión.
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(tree, X_test, y_test, cmap ='cividis', ax=ax)Genial, ahora veámoslos juntos.
Aquí está todo el código.
fig, ax = plt.subplots(figsize=(12, 9))
# Instantiate Decision Tree Classifier with default hyperparameter settings
tree = DecisionTreeClassifier(random_state=2)
# Train the classifier on the training data
tree.fit(X_train, y_train)
# Predict the test data with trained tree classifier
y_predict = tree.predict(X_test)
# Print accuracy and classification report on test data
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# Plot confusion matrix on test data
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(tree, X_test, y_test, cmap ='cividis', ax=ax)Aquí está la salida.
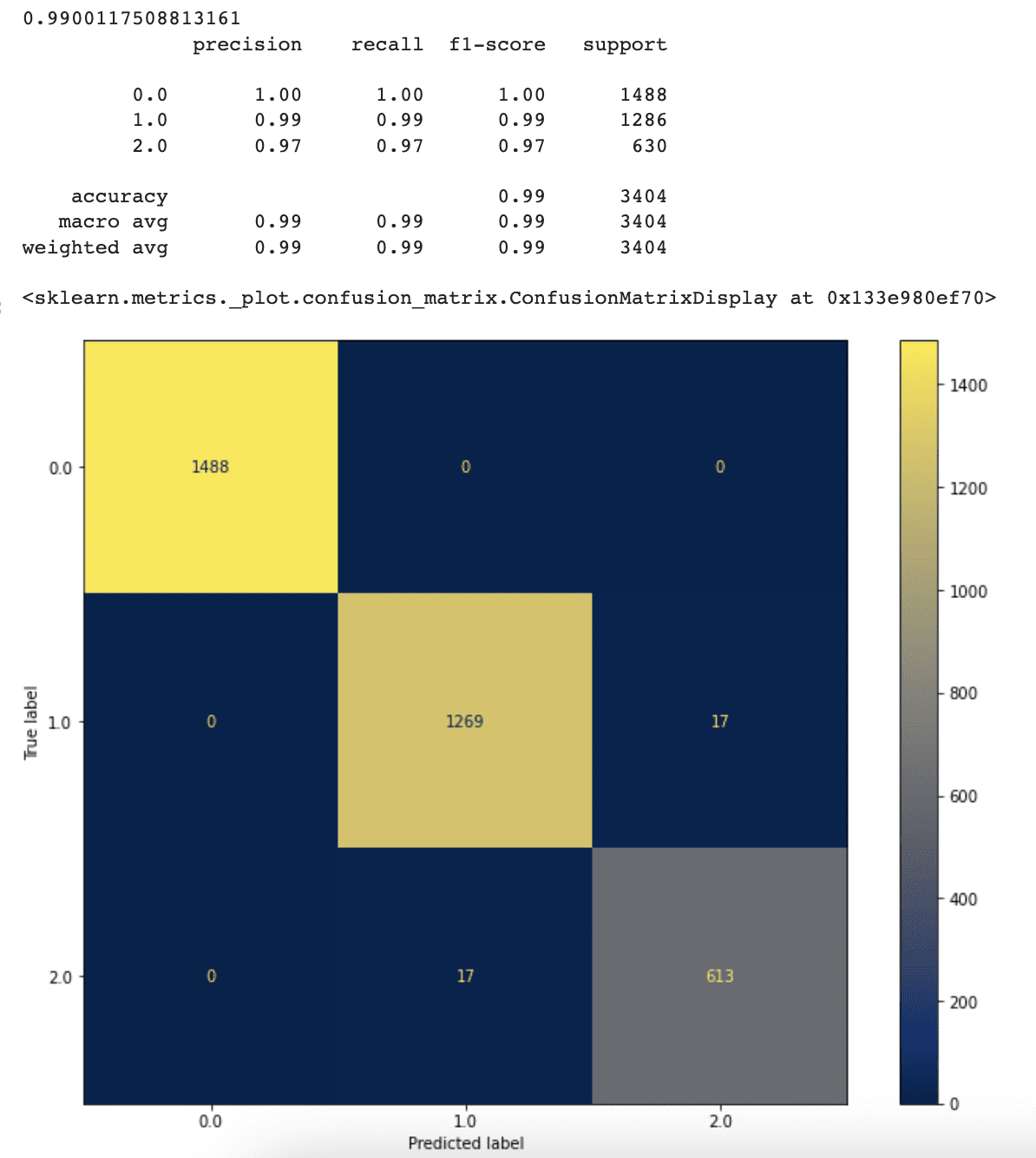
La precisión, la precisión y los valores de recuperación de nuestro clasificador han aumentado como resultado de eliminar la limitación de los nodos máximos de hoja. Ahora el clasificador alcanza una precisión del 99%, frente al 94% anterior.
Esto demuestra que cuando permitimos que nuestro clasificador elija el número óptimo de nodos de hoja por sí mismo, funciona mejor.
Aunque el resultado actual parece excepcional, todavía es posible ajustar más para lograr una precisión aún mejor. En la siguiente parte, analizaremos esta opción.
Clasificador de Bosque Aleatorio
El Bosque Aleatorio es un conjunto de Clasificadores de Árbol de Decisiones combinados en un solo algoritmo. Utiliza una estrategia de bagging para entrenar cada Árbol de Decisiones, lo que incluye la selección aleatoria de puntos de datos de entrenamiento. Como resultado de esta técnica, cada árbol se entrena en un subconjunto separado de los datos de entrenamiento.
El método de bagging se ha vuelto conocido por utilizar una metodología de bootstrap para muestrear puntos de datos, lo que permite que el mismo punto de datos sea seleccionado para varios Árboles de Decisiones.
 Imagen por Autor
Imagen por Autor
Usando scikit-learn, es realmente fácil aplicar un clasificador de Bosque Aleatorio.
Usar Scikit-learn para configurar el algoritmo de Bosque Aleatorio es un proceso sencillo.
El rendimiento del algoritmo, al igual que el rendimiento del Clasificador de Árbol de Decisiones, se puede mejorar cambiando los valores de hiperparámetros como el número de Clasificadores de Árbol de Decisiones, los nodos máximos de hoja y la profundidad máxima del árbol.
Aquí usaremos las opciones predeterminadas en primer lugar.
Veamos el código paso a paso de nuevo.
Primero, instanciemos un objeto clasificador de Bosque Aleatorio usando la función RandomForestClassifier() de la biblioteca scikit-learn, con un parámetro random_state establecido en 2 para reproducibilidad.
rf = RandomForestClassifier(random_state=2)Luego, entrena el clasificador de Bosque Aleatorio en los datos de entrenamiento (X_train y y_train), usando el método .fit().
rf.fit(X_train, y_train)A continuación, utiliza el clasificador entrenado para hacer predicciones sobre los datos de prueba (X_test), usando el método .predict().
y_predict = rf.predict(X_test)Luego, imprime la puntuación de precisión y el informe de clasificación de los valores predichos en comparación con los valores reales del objetivo de los datos de prueba.
Utilizamos las funciones accuracy_score() y classification_report() de la biblioteca scikit-learn nuevamente.
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))Finalmente, vamos a graficar una matriz de confusión para visualizar el rendimiento del Clasificador de Bosques Aleatorios en los datos de prueba. Utilizamos la función plot_confusion_matrix() de la biblioteca scikit-learn.
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, X_test, y_test, cmap ='cividis', ax=ax)Aquí está el código completo.
# Instanciar el Clasificador de Bosques Aleatorios
rf = RandomForestClassifier(random_state=2)
# Entrenar el Clasificador de Bosques Aleatorios con los datos de entrenamiento
rf.fit(X_train, y_train)
# Predecir los datos de prueba con el modelo entrenado
y_predict = rf.predict(X_test)
# Imprimir la puntuación de precisión y el informe de clasificación
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# Graficar la matriz de confusión
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, X_test, y_test, cmap ='cividis', ax=ax)Aquí está el resultado. 
La precisión y los resultados de la matriz de confusión muestran que el algoritmo de Bosques Aleatorios supera al Clasificador de Árbol de Decisión. Esto muestra la ventaja de los enfoques de conjunto como los Bosques Aleatorios sobre los algoritmos de clasificación individuales.
Además, los métodos de aprendizaje automático basados en árboles nos permiten identificar la importancia de cada característica una vez que se ha entrenado el modelo. Por esta razón, Scikit-learn proporciona la función feature_importances_.
Genial, una vez más, veamos el código paso a paso para entenderlo.
Primero, se utiliza el atributo feature_importances_ del objeto Clasificador de Bosques Aleatorios para obtener la puntuación de importancia de cada característica en el conjunto de datos.
La puntuación de importancia indica cuánto contribuye cada característica al rendimiento de predicción del modelo.
# Obtener la importancia de las características
feature_importance = rf.feature_importances_A continuación, se imprimen las importancias de las características en orden descendente, junto con sus nombres de características correspondientes.
# Imprimir la importancia de las características
for i, feature in enumerate(X_train.columns):
print(f'{feature} = {feature_importance[i]}')Luego, para visualizar las características de la más importante a la menos importante, vamos a utilizar el método argsort() de numpy.
# Visualizar las características de la más importante a la menos importante
indices = np.argsort(feature_importance)Finalmente, se crea un gráfico de barras horizontales para visualizar las importancias de las características, con las características clasificadas de más a menos importantes en el eje y y las puntuaciones de importancia correspondientes en el eje x.
Este gráfico nos permite identificar fácilmente las características más importantes en el conjunto de datos y determinar qué características tienen el mayor impacto en el rendimiento del modelo.
plt.figure(figsize=(12,9))
plt.title('Importancia de las Características')
plt.barh(range(len(indices)), feature_importance[indices], color='b', align='center')
plt.yticks(range(len(indices)), [X_train.columns[i] for i in indices])
plt.xlabel('Importancia Relativa')
plt.show()Aquí está el código completo.
# Obtener la importancia de las características
feature_importance = rf.feature_importances_
# Imprimir la importancia de las características
for i, feature in enumerate(X_train.columns):
print(f'{feature} = {feature_importance[i]}')
# Visualizar las características de la más importante a la menos importante
indices = np.argsort(feature_importance)
plt.figure(figsize=(12,9))
plt.title('Importancia de las Características')
plt.barh(range(len(indices)), feature_importance[indices], color='b', align='center')
plt.yticks(range(len(indices)), [X_train.columns[i] for i in indices])
plt.xlabel('Importancia Relativa')
plt.show()Aquí está el resultado.
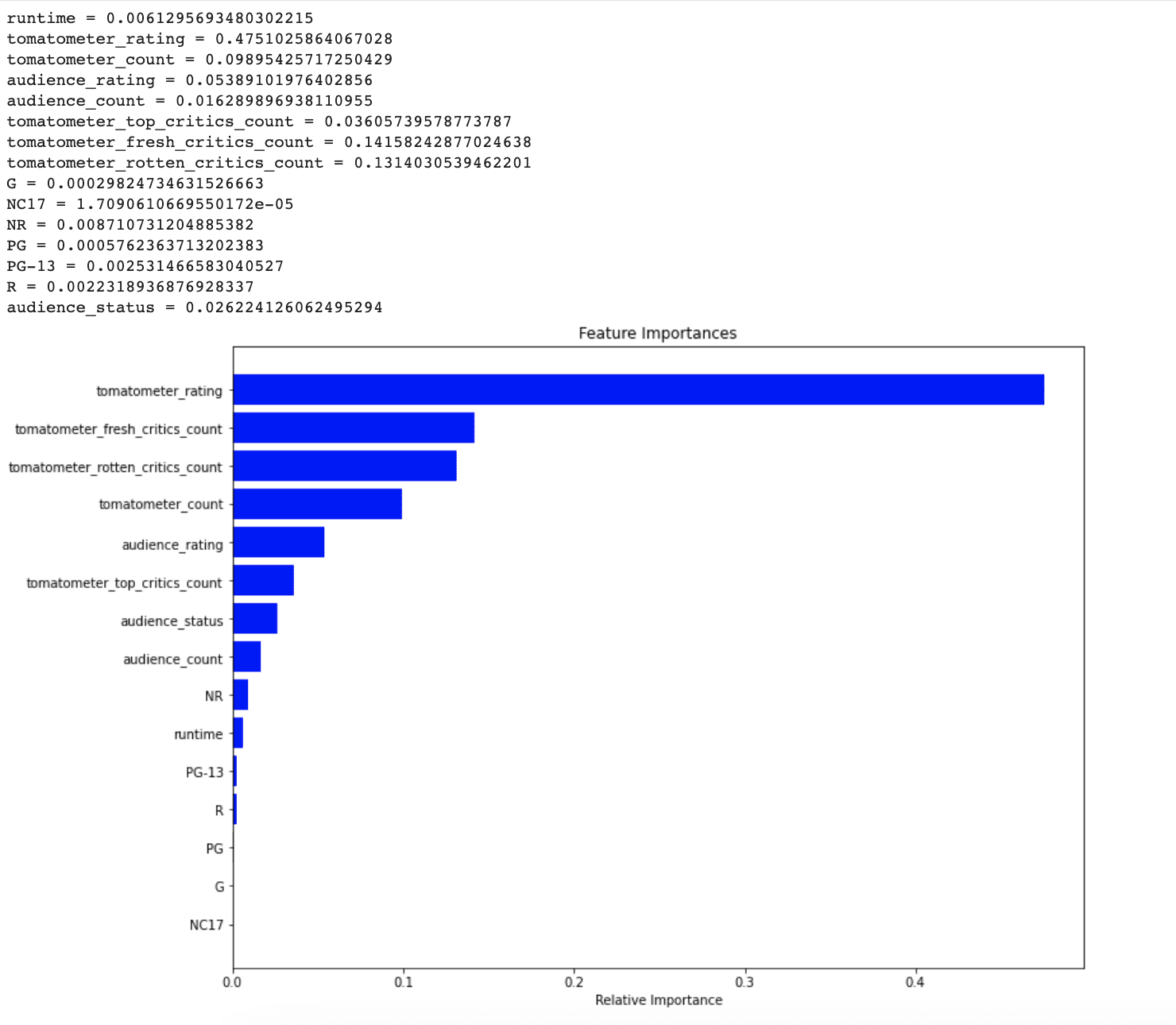
Al ver este gráfico, queda claro que NR, PG-13, R y la duración no son consideradas importantes por el modelo para predecir puntos de datos no vistos. En la siguiente sección, veremos si abordar este problema puede mejorar el rendimiento de nuestro modelo o no.
Clasificador de Bosque Aleatorio con Selección de Características
Aquí está el código.
En la última sección, descubrimos que algunas de nuestras características fueron consideradas menos significativas por nuestro modelo de Bosque Aleatorio, al hacer predicciones.
Como resultado, para mejorar el rendimiento del modelo, excluyamos estas características menos relevantes, incluyendo NR, tiempo de ejecución, PG-13, R, PG, G y NC17.
En el siguiente código, obtendremos primero la importancia de las características, luego dividiremos en conjuntos de entrenamiento y prueba, pero dentro del bloque de código eliminamos estas características menos significativas. Luego imprimiremos el tamaño de los conjuntos de entrenamiento y prueba.
Aquí está el código.
# Obtener la importancia de las características
importancia_caracteristicas = rf.feature_importances_
X_train, X_test, y_train, y_test = train_test_split(df_feature.drop(['tomatometer_status', 'NR', 'runtime', 'PG-13', 'R', 'PG','G', 'NC17'], axis=1),df_feature.tomatometer_status, test_size= 0.2, random_state=42)
print(f'El tamaño de los datos de entrenamiento es {len(X_train)} y el tamaño de los datos de prueba es {len(X_test)}')Aquí está la salida.
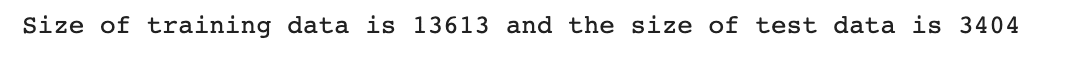
Genial, dado que eliminamos estas características menos significativas, veamos si nuestro rendimiento aumentó o no.
Debido a que hicimos esto muchas veces, explicaré rápidamente los siguientes códigos.
En el siguiente código, primero inicializamos un clasificador de bosque aleatorio y luego entrenamos el bosque aleatorio con los datos de entrenamiento.
rf = RandomForestClassifier(random_state=2)
rf.fit(X_train, y_train)Luego calculamos el puntaje de precisión y el informe de clasificación utilizando los datos de prueba y los imprimimos.
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))Finalmente, trazamos la matriz de confusión.
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, X_test, y_test, cmap ='cividis', ax=ax)Aquí está todo el código.
# Inicializar la clase Bosque Aleatorio
rf = RandomForestClassifier(random_state=2)
# Entrenar el Bosque Aleatorio con los datos de entrenamiento después de la selección de características
rf.fit(X_train, y_train)
# Predecir el modelo entrenado en los datos de prueba después de la selección de características
y_predict = rf.predict(X_test)
# Imprimir el puntaje de precisión y el informe de clasificación
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# Trazar la matriz de confusión
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, X_test, y_test, cmap ='cividis', ax=ax)Aquí está la salida.
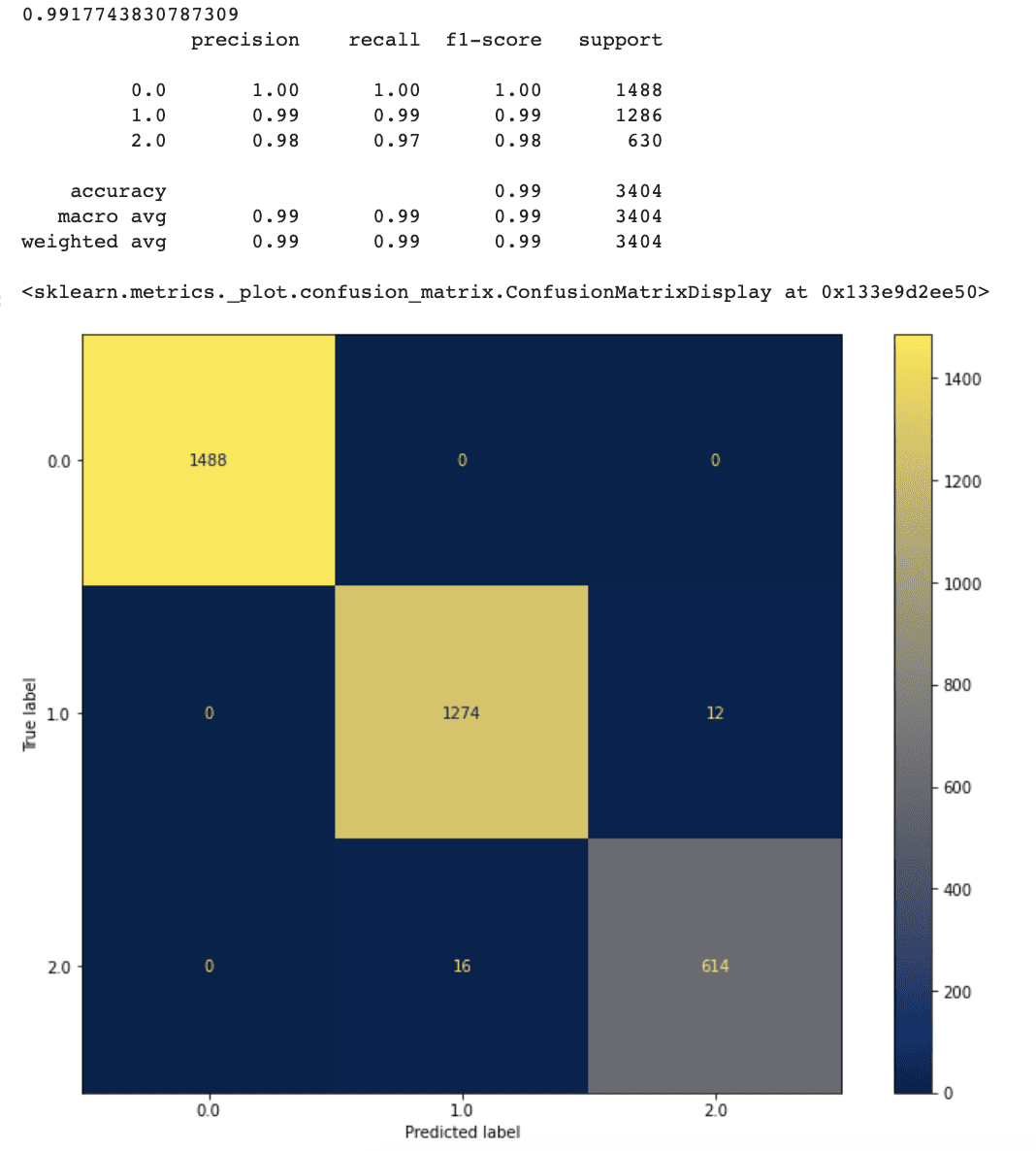
Parece que nuestro nuevo enfoque funciona bastante bien.
Después de hacer la selección de características, la precisión ha aumentado al 99.1 %.
Las tasas de falsos positivos y falsos negativos de nuestro modelo también han disminuido marginalmente en comparación con el modelo anterior.
Esto indica que tener más características no siempre implica un mejor modelo. Algunas características insignificantes pueden crear ruido, lo que podría ser la razón de la disminución de la precisión de predicción del modelo.
Ahora que el rendimiento de nuestro modelo ha aumentado hasta ese punto, descubramos otros métodos para verificar si podemos aumentar aún más.
Clasificador de Bosque Aleatorio Ponderado con Selección de Características
En la primera sección, nos dimos cuenta de que nuestras características estaban un poco desequilibradas. Tenemos tres valores diferentes, ‘Rotten’ (representado por 0), ‘Fresh’ (representado por 1) y ‘Certified-Fresh’ (representado por 2).
Primero, veamos la distribución de nuestras características.
Aquí está el código para visualizar la distribución de etiquetas.
ax = df_feature.tomatometer_status.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])Aquí está la salida.
Está claro que la cantidad de datos con la característica ‘Certified Fresh’ es mucho menor que los demás.
Para resolver el problema del desequilibrio de datos, podemos utilizar enfoques como el algoritmo SMOTE para sobremuestrear la clase minoritaria o proporcionar información sobre el peso de las clases al modelo durante la fase de entrenamiento.
Aquí utilizaremos el segundo enfoque.
Para calcular el peso de las clases, utilizaremos la función compute_class_weight() de la biblioteca scikit-learn.
Dentro de esta función, el parámetro class_weight se establece en ‘balanced’ para tener en cuenta las clases desequilibradas, y el parámetro classes se establece en los valores únicos en la columna tomatometer_status de df_feature.
El parámetro y se establece en los valores de la columna tomatometer_status en df_feature.
class_weight = compute_class_weight(class_weight= 'balanced', classes= np.unique(df_feature.tomatometer_status),
y = df_feature.tomatometer_status.values)A continuación, se crea un diccionario para asignar los pesos de las clases a sus respectivos índices.
Esto se hace convirtiendo la lista de pesos de clase en un diccionario utilizando la función dict() y la función zip().
La función range() se utiliza para generar una secuencia de enteros correspondientes a la longitud de la lista de pesos de clase, que luego se utiliza como claves para el diccionario.
class_weight_dict = dict(zip(range(len(class_weight.tolist())), class_weight.tolist()Finalmente, veamos nuestro diccionario.
class_weight_dictAquí está todo el código.
class_weight = compute_class_weight(class_weight= 'balanced', classes= np.unique(df_feature.tomatometer_status),
y = df_feature.tomatometer_status.values)
class_weight_dict = dict(zip(range(len(class_weight.tolist())), class_weight.tolist()))
class_weight_dictAquí está la salida.
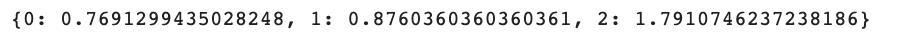
La clase 0 (‘Rotten’) tiene el menor peso, mientras que la clase 2 (‘Certified-Fresh’) tiene el peso más alto.
Cuando aplicamos nuestro clasificador Random Forest, ahora podemos incluir esta información de peso como argumento.
El código restante es el mismo que hicimos anteriormente muchas veces.
Construyamos un nuevo modelo de Random Forest con datos de peso de clase, lo entrenamos en el conjunto de entrenamiento, predecimos los datos de prueba y mostramos la puntuación de exactitud y la matriz de confusión.
Aquí está el código.
# Inicializar el modelo Random Forest con información de peso
rf_weighted = RandomForestClassifier(random_state=2, class_weight=class_weight_dict)
# Entrenar el modelo con los datos de entrenamiento
rf_weighted.fit(X_train, y_train)
# Predecir los datos de prueba con el modelo entrenado
y_predict = rf_weighted.predict(X_test)
# Imprimir la puntuación de exactitud y el informe de clasificación
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# Graficar la matriz de confusión
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf_weighted, X_test, y_test, cmap ='cividis', ax=ax)Aquí está la salida.

El rendimiento de nuestro modelo aumentó cuando agregamos pesos de clase, y ahora tiene una exactitud del 99,2%.
El número de predicciones correctas para la etiqueta “Fresh” también aumentó en uno.
Utilizar pesos de clase para abordar el problema del desequilibrio de datos es un método útil, ya que anima a nuestro modelo a prestar más atención a las etiquetas con pesos más altos durante la fase de entrenamiento.
Enlace a este proyecto de ciencia de datos: https://platform.stratascratch.com/data-projects/rotten-tomatoes-movies-rating-prediction
Nate Rosidi es un científico de datos y estrategia de producto. También es profesor adjunto de análisis y fundador de StrataScratch, una plataforma que ayuda a los científicos de datos a prepararse para sus entrevistas con preguntas reales de las principales empresas. Conéctate con él en Twitter: StrataScratch o LinkedIn.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Cómo crear gráficos de violín con estilo Cyberpunk utilizando Seaborn con un mínimo de código Python.
- ¿Qué es la Gestión de Datos y por qué es importante?
- Más allá de la precisión Abrazando la serendipia y la novedad en recomendaciones para la retención a largo plazo del usuario.
- Ingrese sus innovaciones de síntesis de datos para reformar la policía y ganar dinero.
- Cercanía y Comunidades Analizando Redes Sociales con Python y NetworkX – Parte 3
- Cómo preparar tus datos para visualizaciones
- Aprendizaje Profundo en Sistemas de Recomendación Una introducción.






