Ajuste de Fine-Tuning Eficiente en Parámetros usando 🤗 PEFT
Fine-Tuning Eficiente en Parámetros usando 🤗 PEFT
Motivación
Los Modelos de Lenguaje Grandes (LLMs) basados en la arquitectura de transformadores, como GPT, T5 y BERT, han logrado resultados de vanguardia en varias tareas de Procesamiento de Lenguaje Natural (NLP). También han comenzado a incursionar en otros dominios, como Visión por Computadora (CV) (VIT, Stable Diffusion, LayoutLM) y Audio (Whisper, XLS-R). El paradigma convencional es el preentrenamiento a gran escala en datos genéricos a escala web, seguido de la puesta a punto en tareas específicas. La puesta a punto de estos LLM preentrenados en conjuntos de datos específicos da como resultado grandes mejoras en el rendimiento en comparación con el uso de los LLM preentrenados tal cual (inferencia de cero disparos, por ejemplo).
Sin embargo, a medida que los modelos se hacen más grandes, se vuelve inviable entrenarlos completamente en hardware de consumo. Además, almacenar e implementar modelos ajustados por separado para cada tarea específica se vuelve muy costoso, ya que los modelos ajustados tienen el mismo tamaño que el modelo preentrenado original. ¡Los enfoques de Puesta a Punto Eficiente de Parámetros (PEFT) están destinados a abordar ambos problemas!
Los enfoques de PEFT solo ajustan un pequeño número de parámetros (extra) del modelo mientras se congelan la mayoría de los parámetros de los LLM preentrenados, lo que reduce considerablemente los costos computacionales y de almacenamiento. Esto también supera los problemas de olvido catastrófico, un comportamiento observado durante la puesta a punto completa de los LLM. Los enfoques de PEFT también han demostrado ser mejores que la puesta a punto en regímenes con pocos datos y generalizan mejor a escenarios fuera del dominio. Se puede aplicar a varias modalidades, por ejemplo, clasificación de imágenes y difusión estable de dreambooth.
También ayuda en la portabilidad, donde los usuarios pueden ajustar los modelos utilizando métodos de PEFT para obtener puntos de control pequeños que valen solo unos pocos MB en comparación con los grandes puntos de control de la puesta a punto completa, por ejemplo, bigscience/mt0-xxl ocupa 40 GB de almacenamiento y la puesta a punto completa daría como resultado puntos de control de 40 GB para cada conjunto de datos específico, mientras que utilizando métodos de PEFT serían solo unos pocos MB para cada conjunto de datos específico, logrando al mismo tiempo un rendimiento comparable a la puesta a punto completa. Los pequeños pesos entrenados de los enfoques de PEFT se agregan en la parte superior del LLM preentrenado. Por lo tanto, el mismo LLM se puede utilizar para múltiples tareas agregando pequeños pesos sin tener que reemplazar todo el modelo.
- Generación de texto a partir de imágenes sin entrenamiento previo con BLIP-2
- Hugging Face y AWS se asocian para hacer que la IA sea más accesible
- Swift 🧨Difusores – Difusión rápida y estable para Mac
En resumen, los enfoques de PEFT te permiten obtener un rendimiento comparable a la puesta a punto completa teniendo solo un pequeño número de parámetros entrenables.
Hoy nos complace presentar la biblioteca 🤗 PEFT, que proporciona las últimas técnicas de Puesta a Punto Eficiente de Parámetros integradas de manera fluida con los 🤗 Transformers y 🤗 Accelerate. Esto permite utilizar los modelos más populares y efectivos de Transformers junto con la simplicidad y escalabilidad de Accelerate. A continuación se muestran los métodos de PEFT actualmente compatibles, con más por venir:
- LoRA: LORA: ADAPTACIÓN DE BAJA RANGO DE GRANDES MODELOS DE LENGUAJE
- Ajuste de Prefijos: P-Tuning v2: Ajuste de Indicaciones puede ser comparable a la puesta a punto universalmente en diferentes escalas y tareas
- Ajuste de Indicaciones: El Poder de la Escala para el Ajuste de Indicaciones Eficiente de Parámetros
- P-Tuning: GPT también entiende
Casos de Uso
Exploramos muchos casos de uso interesantes aquí. Estos son algunos de los más interesantes:
-
Usando 🤗 PEFT LoRA para ajustar el modelo
bigscience/T0_3B(3 mil millones de parámetros) en hardware de consumo con 11 GB de RAM, como Nvidia GeForce RTX 2080 Ti, Nvidia GeForce RTX 3080, etc. utilizando la integración de 🤗 Accelerate con DeepSpeed: peft_lora_seq2seq_accelerate_ds_zero3_offload.py. Esto significa que puedes ajustar esos grandes LLMs en Google Colab. -
Llevando el ejemplo anterior un poco más allá al permitir el ajuste INT8 del modelo
OPT-6.7b(6.7 mil millones de parámetros) en Google Colab utilizando 🤗 PEFT LoRA y bitsandbytes:
-
Entrenamiento de Stable Diffusion Dreambooth utilizando 🤗 PEFT en hardware de consumo con 11 GB de RAM, como Nvidia GeForce RTX 2080 Ti, Nvidia GeForce RTX 3080, etc. Prueba la demostración espacial, que debería funcionar sin problemas en una instancia T4 (16 GB de GPU): smangrul/peft-lora-sd-dreambooth.
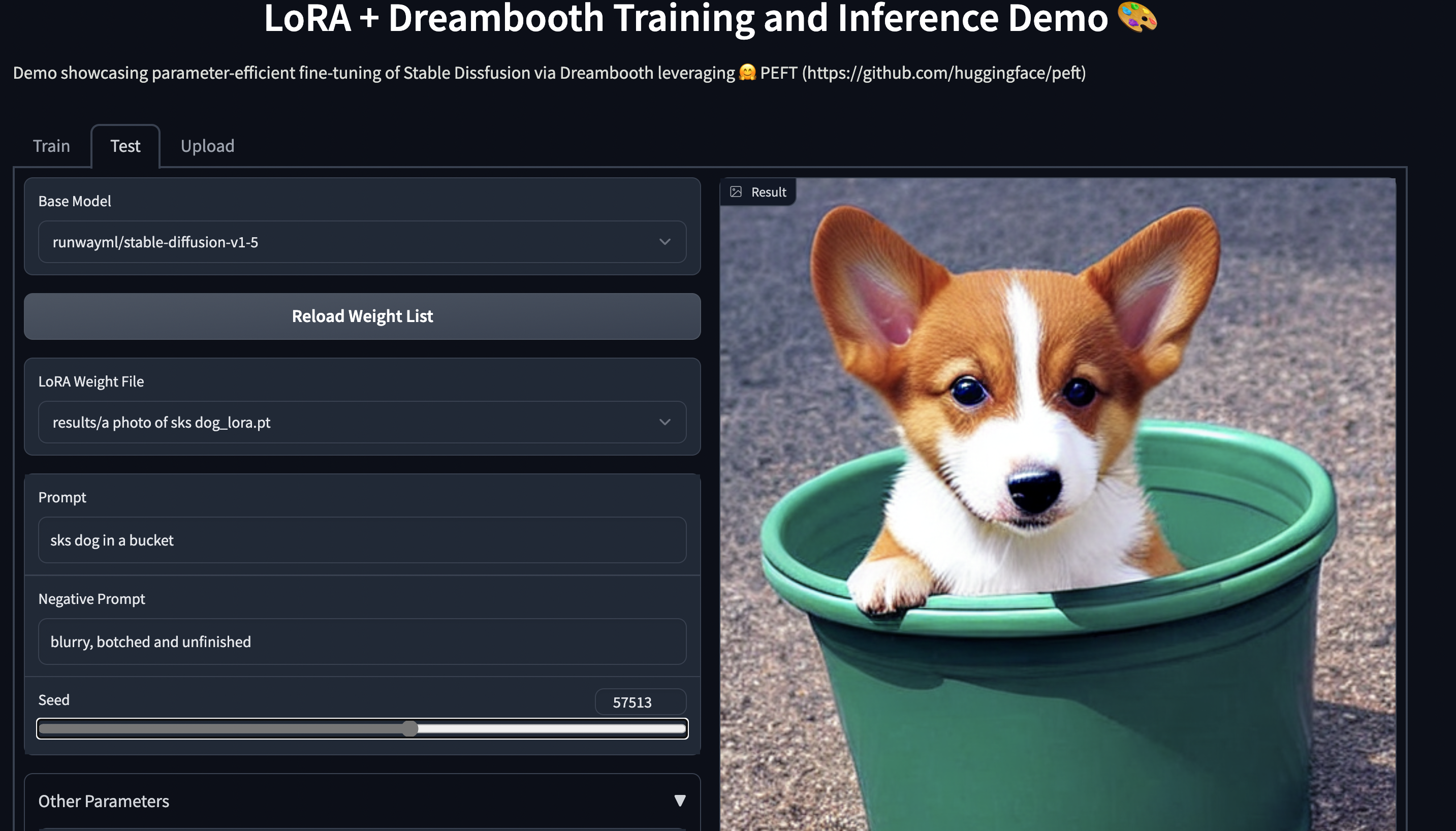 Espacio de Gradio de PEFT LoRA Dreambooth
Espacio de Gradio de PEFT LoRA Dreambooth
Entrenando tu modelo usando 🤗 PEFT
Consideremos el caso de ajustar finamente bigscience/mt0-large usando LoRA.
- Vamos a obtener las importaciones necesarias
from transformers import AutoModelForSeq2SeqLM
+ from peft import get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"- Creando la configuración correspondiente al método PEFT
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)- Envolviendo el modelo base de 🤗 Transformers llamando a
get_peft_model
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
+ model = get_peft_model(model, peft_config)
+ model.print_trainable_parameters()
# salida: parámetros entrenables: 2359296 || todos los parámetros: 1231940608 || % entrenables: 0.19151053100118282¡Eso es todo! El resto del bucle de entrenamiento sigue siendo el mismo. Consulta el ejemplo peft_lora_seq2seq.ipynb para ver un ejemplo completo.
- Cuando estés listo para guardar el modelo para inferencia, simplemente haz lo siguiente.
model.save_pretrained("output_dir")
# model.push_to_hub("my_awesome_peft_model") también funcionaEsto solo guardará los pesos incrementales de PEFT que fueron entrenados. Por ejemplo, puedes encontrar el bigscience/T0_3B ajustado usando LoRA en el conjunto de datos de balsa twitter_complaints aquí: smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM . Observa que solo contiene 2 archivos: adapter_config.json y adapter_model.bin, siendo este último de solo 19MB.
- Para cargarlo para inferencia, sigue el fragmento de código a continuación:
from transformers import AutoModelForSeq2SeqLM
+ from peft import PeftModel, PeftConfig
peft_model_id = "smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
+ model = PeftModel.from_pretrained(model, peft_model_id)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = model.to(device)
model.eval()
inputs = tokenizer("Texto del tuit : @HondaCustSvc Tu servicio al cliente ha sido horrible durante el proceso de recall. Nunca volveré a comprar un Honda. Etiqueta :", return_tensors="pt")
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=10)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])
# 'queja'Siguientes pasos
Hemos lanzado PEFT como una forma eficiente de ajustar finamente grandes LLMs en tareas y dominios posteriores, ahorrando mucho cálculo y almacenamiento al tiempo que se logra un rendimiento comparable al ajuste fino completo. En los próximos meses, exploraremos más métodos de PEFT, como (IA)3 y adaptadores de cuello de botella. Además, nos centraremos en nuevos casos de uso, como el entrenamiento INT8 del modelo whisper-large en Google Colab y el ajuste de componentes RLHF como políticas y clasificadores utilizando enfoques de PEFT.
Mientras tanto, nos emociona ver cómo los profesionales de la industria aplican PEFT a sus casos de uso; si tienes alguna pregunta o comentario, abre un problema en nuestro repositorio de GitHub 🤗.
¡Feliz Ajuste Fino Eficiente de Parámetros!
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Directrices éticas para el desarrollo de la biblioteca Diffusers
- ControlNet en 🧨 Difusores
- Creando Inteligencia Artificial de Preservación de Privacidad con Substra
- Aprendizaje Federado utilizando Hugging Face y Flower
- Acelerando la Inferencia de Difusión Estable en CPUs Intel
- Inferencia rápida en modelos de lenguaje grandes BLOOMZ en el acelerador Habana Gaudi2
- Boletín de Ética y Sociedad #3 Apertura Ética en Hugging Face






