Extracción de datos de documentos sin OCR con Transformers (2/2)
Extracción de datos sin OCR con Transformers (2/2)
Donut versus Pix2Struct en datos personalizados
¿Qué tan bien entienden estos dos modelos transformadores los documentos? En esta segunda parte te mostraré cómo entrenarlos y comparar sus resultados para la tarea de extracción de índices clave.
Ajuste fino de Donut
Entonces retomemos desde la parte 1, donde explico cómo preparar los datos personalizados. Comprimí las dos carpetas del conjunto de datos y las subí a un nuevo conjunto de datos de huggingface aquí. El cuaderno de Colab que utilicé se puede encontrar aquí. Descargará el conjunto de datos, configurará el entorno, cargará el modelo Donut y lo entrenará.
Después de ajustar fino durante 75 minutos, lo detuve cuando la métrica de validación (que es la distancia de edición) alcanzó 0.116:
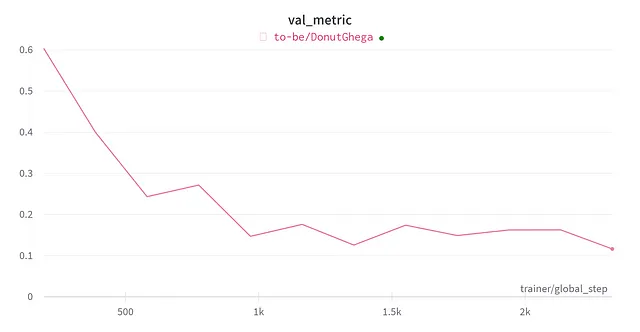
En el nivel de campo, obtengo estos resultados para el conjunto de validación:
- Analizando la defensa del FC Barcelona desde una perspectiva de ciencia de datos
- Conoce los Modelos de Difusión Compartimentados (CDM) Un enfoque de IA para entrenar diferentes modelos de difusión o indicaciones en distintas fuentes de datos.
- Dynalang Uniendo la comprensión del lenguaje y la predicción futura en el aprendizaje de agentes
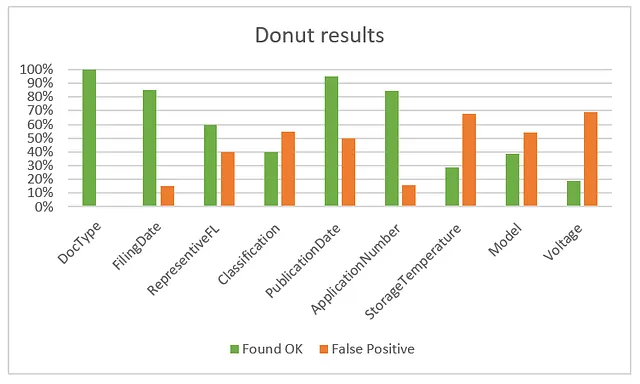
Cuando observamos el Doctype, vemos que Donut siempre identifica correctamente los documentos como una patente o una hoja de datos. Por lo tanto, podemos decir que la clasificación alcanza una precisión del 100%. También hay que tener en cuenta que aunque tengamos una clase de hoja de datos, no es necesario que esta palabra exacta esté en el documento para clasificarlo como tal. No le importa a Donut, ya que se ajustó fino para reconocerlo así.
Otros campos también tienen una puntuación bastante buena, pero es difícil decir solo con este gráfico qué sucede internamente. Me gustaría ver dónde el modelo acierta y falla en casos específicos. Así que creé una rutina en mi cuaderno para generar una tabla de informe con formato HTML. Para cada documento en mi conjunto de validación, tengo una entrada de fila como esta:

En el lado izquierdo está el dato reconocido (inferido) junto con su verdad absoluta. En el lado derecho está la imagen. También utilicé códigos de color para tener una vista general rápida:
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- La ciudad más avanzada tecnológicamente de Estados Unidos tiene dudas sobre los coches autónomos
- China redacta reglas para la tecnología de reconocimiento facial
- Ya está mucho más allá de lo que los humanos pueden hacer’ ¿Eliminará la IA a los arquitectos?
- Inmersión profunda en el modo de copia por escritura de pandas Parte I
- LLMs afinados para la predicción de sentimientos – Cómo analizar y evaluar
- AI Prowess Utilizando Docker para la implementación y escalabilidad eficiente de aplicaciones de Aprendizaje Automático
- 7 Estúpidas Razones por las que la Gente no está Utilizando la IA




