Explorando Data Mesh Un cambio de paradigma en la arquitectura de datos
Explorando Data Mesh Un cambio de paradigma en la arquitectura de datos

Ante los cambios tecnológicos, organizativos y comerciales, la arquitectura de datos ha evolucionado en la última década más o menos. Pero, ¿ha sido esta evolución lo suficientemente significativa? La mayoría de las organizaciones suelen tener una arquitectura de datos centralizada. Que, por diseño, consolida los datos bajo un solo paraguas, a menudo gestionado por un equipo de datos dedicado.
Aunque eficaz para garantizar la seguridad y una mejor gobernanza, la arquitectura de datos centralizada tiene limitaciones en términos de escalabilidad, flexibilidad y accesibilidad, entre otros.
Ingresa Data Mesh, un concepto (casi) análogo a los microservicios en la arquitectura de software. Data Mesh tiene como objetivo descentralizar la gestión de datos de la misma manera que los microservicios se centran en la descentralización de los componentes de la aplicación. Distribuye la propiedad y la responsabilidad de los datos entre equipos específicos del dominio, reconociendo los datos como un activo estratégico, mejor gestionado en su origen.
- Google actualiza su búsqueda de IA Vertex con capacidades de atención médica y ciencias de la vida.
- Optimización Interpretación Geométrica del Método de Newton-Raphson
- ¿Cómo aprender Machine Learning en línea?
En este artículo, exploraremos Data Mesh, sus principios clave, los factores a considerar y los desafíos asociados con la adopción de una arquitectura de malla de datos.
¿Qué es un Data Mesh?
El concepto de Data Mesh fue introducido por primera vez por Zhamak Dehghani en el artículo “Cómo pasar de un Lago de Datos Monolítico a una Malla de Datos Distribuida“, que describe los principios y conceptos detrás de la malla de datos. Este artículo y las discusiones posteriores dentro de las comunidades de datos desempeñaron un papel importante en la popularización de la arquitectura de malla de datos.
Un Data Mesh es un enfoque contemporáneo de la arquitectura y gestión de datos que se aleja de los modelos de datos centralizados tradicionales. Introduce una estructura descentralizada para organizar, distribuir y utilizar los activos de datos de una organización.
En una malla de datos, la propiedad y las responsabilidades de los datos se distribuyen entre equipos específicos del dominio o equipos de productos de datos, otorgándoles autonomía para gestionar sus datos dentro de sus respectivos dominios.
Este enfoque descentralizado tiene como objetivo abordar las limitaciones asociadas con los modelos de datos centralizados, como los desafíos de escalabilidad, los silos de datos y los tiempos de respuesta lentos a las necesidades cambiantes de datos. Al capacitar a los equipos específicos del dominio para gestionar independientemente sus datos, una malla de datos promueve una cultura de autonomía, agilidad y responsabilidad de los datos dentro de una organización. También facilita el manejo eficiente de diversas fuentes de datos mientras se mantiene el enfoque en la calidad y relevancia de los datos.
Principios clave en la arquitectura de la Malla de Datos
La arquitectura de la Malla de Datos se basa en un conjunto de principios diseñados para abordar los desafíos de escalar y gestionar datos dentro y entre organizaciones. Estos principios proporcionan una base para un enfoque descentralizado y más escalable para la gestión de datos.
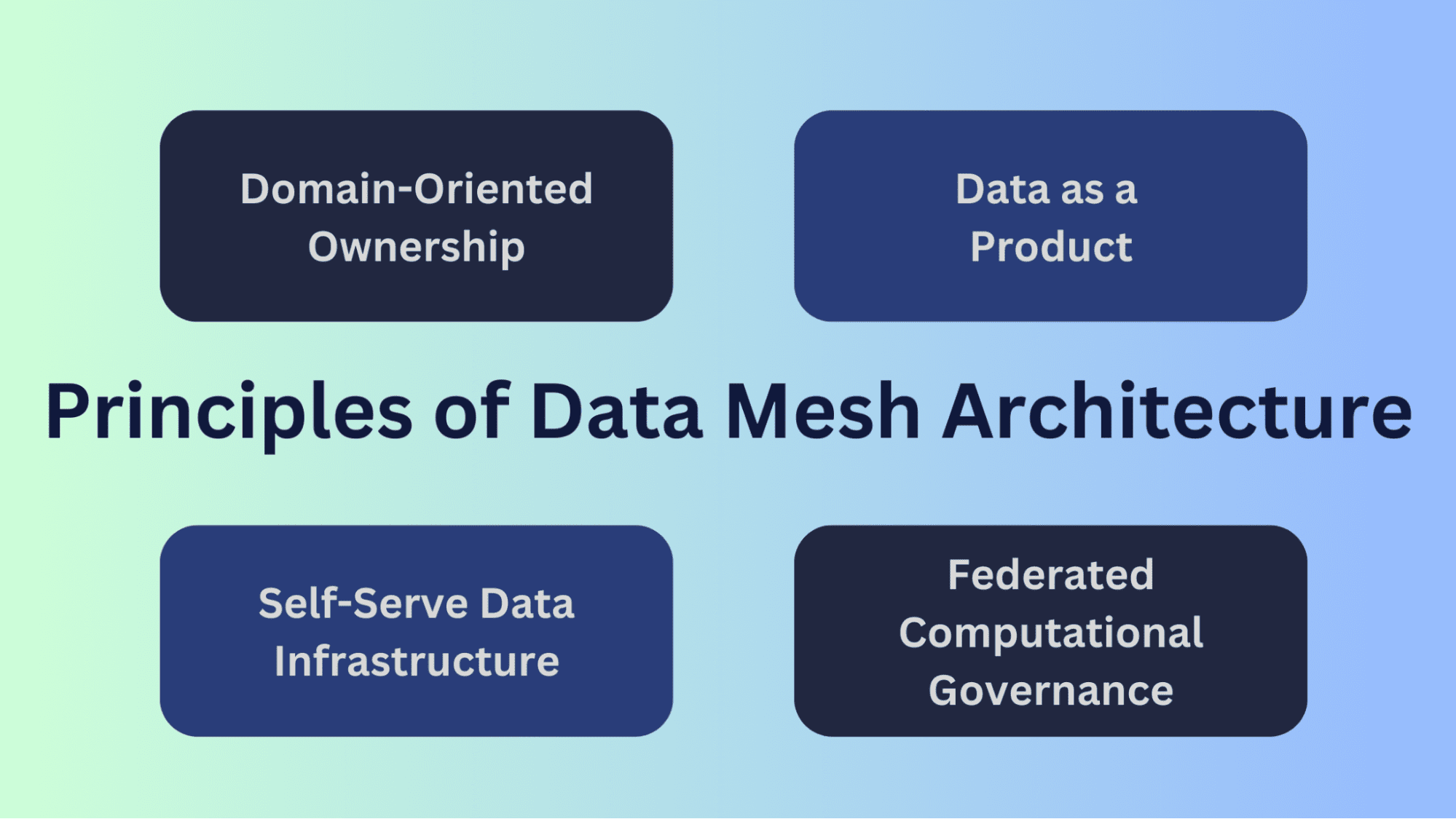
Propiedad orientada al dominio
En una malla de datos, la propiedad de los datos se descentraliza y se distribuye entre varios dominios o unidades empresariales dentro de la organización. Cada dominio es responsable de los datos generados y utilizados dentro de su área específica de experiencia o funcionalidad. Este principio reconoce que los expertos en dominios están mejor equipados para comprender y gestionar los datos dentro de sus respectivos dominios.
La propiedad orientada al dominio mejora la calidad y precisión de los datos porque quienes están más cerca de la fuente de datos tienen un profundo conocimiento de su contexto y pueden garantizar su integridad. También fomenta un sentido de pertenencia y responsabilidad por los datos, alentando a los equipos de dominio a mantener altos estándares de datos.
Datos como un producto
En una malla de datos, los datos se tratan como un producto en lugar de un subproducto de las operaciones comerciales. Cada dominio es responsable de ofrecer productos de datos bien definidos que estén diseñados, empaquetados y disponibles para su consumo por otros dominios dentro de la organización. Estos productos de datos tienen definiciones claras, mecanismos de acceso y acuerdos de nivel de servicio (SLA, por sus siglas en inglés).
Tratar los datos como un producto alienta a los productores de datos a centrarse en ofrecer datos de alta calidad y valor para los consumidores. También garantiza que los productos de datos estén diseñados teniendo en cuenta las necesidades de los usuarios, lo que hace que los datos sean más accesibles y utilizables para un mayor número de partes interesadas.
Infraestructura de Datos Auto-Servicio
Data Mesh promueve el desarrollo de una infraestructura de datos auto-servicio que permite a los consumidores de datos, como analistas de datos, científicos de datos y usuarios de negocios, acceder y procesar datos de forma independiente. Esta infraestructura incluye catálogos de datos, mecanismos de descubrimiento de datos y tuberías de procesamiento de datos que permiten a los consumidores encontrar, entender y utilizar datos sin depender en gran medida de equipos de ingeniería de datos centralizados.
La infraestructura de datos auto-servicio reduce los cuellos de botella y acelera el acceso a datos, empoderando a una variedad más amplia de usuarios para trabajar con datos. Democratiza los datos dentro de la organización, haciéndolos más accesibles y permitiendo una toma de decisiones e insights más rápidos.
Gobierno Computacional Federado
Para mantener la calidad de los datos, la seguridad y el cumplimiento en una arquitectura de datos descentralizada, Data Mesh emplea un gobierno computacional federado. Cada dominio define y aplica sus propias políticas de gobierno adaptadas a las necesidades específicas de sus datos. Si bien puede haber estándares y pautas globales, los dominios tienen la autonomía para gobernar sus activos de datos.
Esto equilibra la necesidad de estándares globales de datos con la flexibilidad requerida por los dominios individuales. Permite que los dominios adapten las prácticas de gobierno a sus desafíos de datos únicos, al tiempo que garantiza que los datos sean seguros, cumplidos y de alta calidad.
Estos cuatro principios clave del Data Mesh, por lo tanto, tienen como objetivo abordar colectivamente los desafíos de escalar las operaciones de datos en grandes organizaciones, promoviendo:
- la descentralización,
- el pensamiento de productos de datos,
- el auto-servicio y
- un gobierno efectivo.
Al implementar estos principios, las organizaciones pueden desbloquear el potencial completo de sus activos de datos, mejorar la colaboración entre los equipos de dominio y convertir los datos en un recurso más valioso y accesible para todas las partes interesadas.
¿Implementando un Data Mesh? Aquí hay Factores a Considerar
La transición a un Data Mesh a menudo implica un cambio cultural importante dentro de una organización. Un Data Mesh fomenta la colaboración, la propiedad compartida y el pensamiento centrado en productos de datos, alineando las prácticas de datos más estrechamente con la cultura y los valores en evolución de la organización. Aquí hay algunos factores que las organizaciones deben considerar al implementar un Data Mesh.
Metas y Estrategia de Negocios
Cualquier cambio importante en la arquitectura de datos debe estar alineado con las metas y objetivos estratégicos más amplios de la organización.
La implementación de un Data Mesh debe verse como un catalizador estratégico, mejorando la capacidad de la organización para aprovechar los datos de manera efectiva y lograr sus metas y objetivos generales.
Infraestructura Existente
Las organizaciones deben evaluar y considerar su infraestructura de datos actual e inversiones al evaluar la viabilidad de un Data Mesh.
La transición a un Data Mesh puede requerir ajustes en la pila tecnológica e infraestructura existente, por lo que es esencial alinear estos aspectos con el nuevo enfoque.
Complejidad y Escala de Datos
Cuando las organizaciones enfrentan una creciente complejidad y escala de datos, deben considerar enfoques alternativos de gestión de datos. Un Data Mesh ofrece escalabilidad y adaptabilidad, especialmente cuando se trata de entornos de datos cada vez más complejos y de gran escala.
Un Data Mesh es una buena opción cuando el volumen, la variedad o la velocidad de los datos dificultan su gestión de manera centralizada, o cuando los requisitos de datos son diversos en diferentes unidades o dominios de negocio.
Gobierno de Datos y Cumplimiento
Mantener la calidad, privacidad, seguridad y cumplimiento de los datos es un aspecto desafiante de la gestión de datos, especialmente en entornos descentralizados.
Una estrategia de Data Mesh debe abordar estas complejidades de manera efectiva, asegurando que se cumplan las prácticas de gobierno de datos y los requisitos regulatorios.
Accesibilidad y Propiedad de Datos
En organizaciones con fuentes de datos distribuidas y diversos dominios, la gestión de datos centralizada tradicional puede resultar insuficiente. La implementación de un Data Mesh alinea la propiedad de los datos con los equipos específicos de dominio, empoderándolos para asumir la responsabilidad de sus datos, lo cual puede ser especialmente valioso en dichos entornos.
Además, para facilitar la toma de decisiones basada en datos en toda la organización, es crucial hacer que los datos sean más accesibles. Un Data Mesh democratiza el acceso a los datos, permitiendo a una gama más amplia de usuarios acceder y utilizar los datos, lo que conduce a una mejora en la toma de decisiones en diversos departamentos o equipos.
Desafíos en la adopción de una arquitectura de malla de datos
Moverse de una arquitectura de datos centralizada a una malla de datos no está exento de desafíos. En esta sección, profundizaremos en algunos de ellos, desde la gobernanza hasta la monitorización.
Gobernanza de datos
En una malla de datos, la gobernanza de datos se vuelve más compleja debido a que los datos se distribuyen en múltiples dominios y equipos. Asegurar la consistencia en la calidad de los datos, privacidad, seguridad y cumplimiento de normas en estos dominios puede ser un desafío:
- Establecer la propiedad clara de los datos y la responsabilidad de las tareas de gobernanza de datos, como definir esquemas de datos y controles de acceso, puede ser un desafío cuando participan múltiples equipos.
- Desarrollar y hacer cumplir políticas y prácticas de gobernanza de datos que se alineen con la naturaleza descentralizada de una malla de datos requiere una planificación cuidadosa.
Descubrimiento de datos
En una malla de datos descentralizada, descubrir y acceder a los datos puede ser un desafío. Asegurar que los datos estén correctamente catalogados, etiquetados y documentados es esencial para facilitar el descubrimiento de datos. Aquí algunas estrategias:
- Implementar prácticas efectivas de gestión de metadatos para proporcionar contexto y descripciones de conjuntos de datos, facilitando a los usuarios entender los recursos de datos disponibles.
- Desarrollar y mantener un catálogo de datos o repositorio de metadatos que permita a los usuarios buscar y encontrar conjuntos de datos relevantes de manera eficiente.
Propiedad de datos
Una definición clara y consistente de propiedad y responsabilidad de datos para cada dominio de datos y producto de datos es crucial en una malla de datos. Determinar quién es responsable de mantener, actualizar y curar los datos puede ser un desafío, especialmente cuando hay múltiples partes interesadas. Las organizaciones pueden abordar este desafío mediante:
- Asegurando que los propietarios de datos tengan la autoridad y los recursos necesarios para gestionar sus dominios de datos de manera efectiva.
- Estableciendo mecanismos para resolver conflictos o disputas relacionadas con la propiedad y responsabilidades de datos.
Monitorización y observabilidad
En una malla de datos, la monitorización de la salud, el rendimiento y la fiabilidad de los flujos de datos y los productos de datos puede ser compleja. Algunas estrategias incluyen:
- Implementar herramientas y prácticas de monitorización y observabilidad robustas para rastrear la calidad de los datos, la latencia y el uso en diferentes dominios.
- Desarrollar mecanismos de alerta e informes para identificar y abordar rápidamente problemas que puedan afectar la disponibilidad o fiabilidad de los datos.
Hemos destacado algunos desafíos en la implementación de una malla de datos. Estos son más bien puntos de control de los que las organizaciones deben ser conscientes al pasar a una arquitectura de malla de datos descentralizada.
Conclusión
La malla de datos, por lo tanto, representa un cambio de paradigma en la arquitectura de datos, ofreciendo soluciones a los desafíos de los modelos centralizados. Discutimos cómo distribuir la propiedad de los datos, promover el pensamiento en productos de datos y permitir el acceso de autoservicio son beneficiosos. Sin embargo, una implementación exitosa requiere una cuidadosa consideración de los factores culturales y tecnológicos, así como un enfoque proactivo para la gobernanza de datos. Bala Priya C es una desarrolladora y escritora técnica de la India. Le gusta trabajar en la intersección de las matemáticas, la programación, la ciencia de datos y la creación de contenido. Sus áreas de interés y experiencia incluyen DevOps, ciencia de datos y procesamiento de lenguaje natural. Le gusta leer, escribir, programar y tomar café. Actualmente, está trabajando en aprender y compartir su conocimiento con la comunidad de desarrolladores escribiendo tutoriales, guías prácticas, artículos de opinión y más.
[Bala Priya C](https://twitter.com/balawc27) es una desarrolladora y escritora técnica de la India. Le gusta trabajar en la intersección de las matemáticas, la programación, la ciencia de datos y la creación de contenido. Sus áreas de interés y experiencia incluyen DevOps, ciencia de datos y procesamiento de lenguaje natural. Le gusta leer, escribir, programar y tomar café. Actualmente, está trabajando en aprender y compartir su conocimiento con la comunidad de desarrolladores escribiendo tutoriales, guías prácticas, artículos de opinión y más.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Investigadores de la Universidad de Sharjah desarrollan soluciones de inteligencia artificial para la inclusión del árabe y sus dialectos en el procesamiento del lenguaje natural
- Investigadores de Meta AI presentan un modelo de aprendizaje automático que explora la decodificación de la percepción del habla a partir de registros cerebrales no invasivos.
- Google presenta Vertex AI Search de última generación un cambio de juego para los proveedores de atención médica
- Funciones de Activación en Redes Neuronales
- Nuevas formas de inspirarse con la IA generativa en la Búsqueda
- Ponte en marcha ‘Forza Motorsport’ llega a GeForce NOW’.
- Calidad desigual de los parques expuesta a través de las redes sociales y el aprendizaje automático