Explorando NLP – Comenzando con NLP (Paso #1)
Explorando NLP - Paso #1
Si eres nuevo en mi serie “Explorando NLP”, por favor revisa mi artículo introductorio aquí.
Explorando y Dominando NLP — Un viaje a través de las profundidades
Hola, soy Deepthi Sudharsan, una estudiante de tercer año persiguiendo la carrera de B.Tech en Inteligencia Artificial. Dado que ya…
VoAGI.com
Este semestre, tengo NLP como parte de mi currículo. ¡YAY! Así que, como parte de una próxima evaluación para la materia, estaba repasando los materiales proporcionados y haciendo algunos apuntes que compartiré hoy. Espero que sea útil. También aprovecho este momento para agradecer a mis profesores del departamento de CEN, Amrita Vishwa Vidhyapeetham, Coimbatore, India. Es gracias a su guía, motivación y apoyo que he comenzado esta serie. Son todos sus enseñanzas las que me han llevado a seguir mi amor por NLP. Quisiera agradecer especialmente al Sr. Sachin Kumar S del departamento de CEN, Amrita Coimbatore, por impartir este curso para mí este semestre. Algunas de la información e imágenes recopiladas aquí son de los recursos y materiales proporcionados o creados por él.
¿Qué es NLP?
El estudio de la interacción entre las computadoras y los lenguajes humanos se llama Procesamiento del Lenguaje Natural. Intenta dar a las computadoras la capacidad de entender el contenido de textos y discursos de una manera similar a como lo hacen los humanos.
- Explorando el Procesamiento del Lenguaje Natural – Inicio de NLP (Paso #2)
- Explorando NLP – Iniciando NLP (Paso #3)
- Guía completa de métricas de evaluación de clasificación
Objetivo: Capturar completamente el significado contextual. (El contexto se refiere a la información derivada del significado de un texto)

- Fonética: estudia cómo los humanos producen y perciben sonidos o los aspectos equivalentes de la lengua de señas
- Fonología: estudia cómo los idiomas o dialectos organizan sistemáticamente sus sonidos o partes constituyentes de señas en lenguajes de señas
- Morfología: el estudio de la estructura interna de las palabras – Morfema es la unidad básica de la morfología – Una palabra es la unidad independiente más pequeña de un idioma – Las palabras simples no tienen una estructura interna (o consisten en un morfema). Ejemplo: trabajo, correr – Las palabras complejas tienen una estructura interna (consisten en uno o más morfemas). Ejemplo: trabajador (trabajo+er), edificio (construir+ing)
- Sintaxis: el estudio de cómo las palabras y los morfemas se combinan para formar unidades más grandes como frases y oraciones
- Semántica: el estudio de la referencia, el significado o la verdad
- Pragmática: el estudio de cómo el contexto contribuye al significado
Algunos términos importantes:
- Los tokens pueden considerarse como palabras, caracteres, subpalabras, etc.
- La tokenización es el proceso de separar las partes del texto en oraciones en tokens.
- El corpus es una colección de datos de texto.
- El vocabulario es una colección de tokens únicos en el corpus.
- El léxico se refiere a las palabras y sus significados.

Tipos de Tokenización
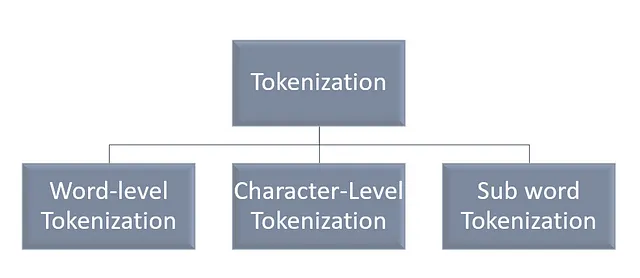
Tokenización a nivel de palabras
Divide la oración dada en palabras basándose en un cierto delimitador
“Ella es más inteligente” se convierte en “ella”, “es”, “más inteligente”. Aquí el delimitador es el espacio.
Desventajas :
Cuando hay palabras “fuera del vocabulario (OOV)”. (Una solución es reemplazar las palabras raras con un token desconocido (UNK). En este caso, el vocabulario solo contendrá las palabras más frecuentes, pero se perderá información sobre la nueva palabra)
El tamaño del vocabulario creado será enorme, lo que llevará a problemas de memoria y rendimiento (una solución: cambiar a la tokenización a nivel de caracteres)
Cuando se dividen las oraciones en función de espacios en blanco y puntuación, hay problemas para manejar palabras que se consideran un solo token pero están separadas por espacio o puntuación, como “don’t”, “New York”, etc.
Tokenización a nivel de caracteres:
Divide la oración dada en una secuencia de caracteres.
“Más inteligente” se convierte en “m”, “á”, “s”, ” “, “i”, “n”, “t”, “e”, “l”, “i”, “g”, “e”, “n”, “t”, “e”.
Ventajas :
Tamaño de vocabulario más pequeño (26 letras del alfabeto + caracteres especiales, etc.) Se manejan los errores de ortografía
Tokenización de subpalabras:
Divide las palabras en piezas más pequeñas.
“Más inteligente” se convierte en “Más”, “inteligente”
Palabras vacías:
Las palabras vacías son las palabras comúnmente utilizadas en un texto, como “el”, “en”, “donde”, etc.
import nltkfrom nltk.corpus import stopwords #Pythonprint(set(stopwords.words('english')))Algunos desafíos del procesamiento del lenguaje natural (NLP):
- Ambigüedad (oraciones o frases con múltiples interpretaciones. Dos tipos: sintácticas – múltiples interpretaciones de una oración y léxicas – múltiples interpretaciones de una palabra)
- Abreviaturas (formas cortas)
- Token no lingüístico
- Datos de redes sociales (en forma de código mixto)
Modelado del lenguaje:
Predicción de la posible unidad lingüística (palabra, texto, oración, token, símbolo, etc.) que puede ocurrir a continuación considerando el contexto.
Los modelos que asignan valores de probabilidad a la secuencia de tokens se llaman modelos de lenguaje
El modelo de lenguaje más simple es el “N-gram”. Asigna probabilidades a una oración o secuencia de “n” tokens.
Utiliza la suposición de Markov; la probabilidad de la siguiente palabra depende solo de la palabra anterior. Los modelos de N-grama analizan (n-1) palabras en el pasado para predecir la siguiente palabra.


Referencias
Visión general de algoritmos de tokenización en NLP
Introducción a los métodos de tokenización, incluyendo subpalabras, BPE y SentencePiece
towardsdatascience.com
- “Speech & language processing”, Daniel Jurafsky, James H Martin, preparación [citado el 1 de junio de 2020] (Disponible en: https://web.stanford.edu/~jurafsky/slp3 (2018))
- https://www.slideshare.net/YuriyGuts/natural-language-processing-nlp
- “Foundations of Statistical Natural Language Processing”, Christopher Manning y Hinrich Schütze, MIT Press, 1999
- “Natural Language Processing with Python”, Steven Bird, Ewan Klein y Edward Loper, O’Reilly Media, Inc.”, 2009.
- “Deep Learning for Natural Language Processing: Develop Deep Learning Models for your Natural Language Problems (Ebook)”, Jason Browlee, Machine Learning Mastery, 2017.
- “Speech & language processing”, Daniel Jurafsky, James H Martin, preparación [citado el 1 de junio de 2020]
- https://all-about-linguistics.group.shef.ac.uk/branches-of-linguistics/morphology/what-is-morphology//
- http://sams.edu.eg/en/faculties/flt/academic-programs-and-courses/department-of-english-language/
- https://www.coursehero.com/file/127598328/Human-Comm-Ch-2-4-Notesdocx//
- https://slideplayer.com/slide/7728110/
- https://www.geeksforgeeks.org/removing-stop-words-nltk-python/
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ¿Qué tan aleatorios son los goles en el fútbol?
- Consulta tus DataFrames con potentes modelos de lenguaje grandes utilizando LangChain.
- Transformada de Fourier para series de tiempo Graficando números complejos
- 5 Programas de Certificación en IA en línea – Explora e Inscríbete
- Optimizando Conexiones Optimización Matemática dentro de Grafos
- Utilizando cámaras en los autobuses de transporte público para monitorear el tráfico
- OpenAI discontinúa su detector de escritura de IA debido a una baja tasa de precisión






