Explorando NLP – Iniciando NLP (Paso #3)
Explorando NLP - Iniciando NLP (Paso #3)
Si eres nuevo en mi serie “Explorando NLP”, por favor revisa mi artículo introductorio aquí.
Explorando y Dominando NLP – Un viaje a través de las profundidades
Hola, soy Deepthi Sudharsan, una estudiante de tercer año persiguiendo B.Tech en Inteligencia Artificial. Dado que ya estoy…
VoAGI.com
Aquí hay algunos conceptos que revisé durante la semana, especialmente sobre embeddings de palabras. ¡Hice algunas prácticas, que compartiré como parte de la serie pronto! Me gustaría agradecer al Sr. Sachin Kumar S de CEN, Amrita Coimbatore, por impartir este curso para mí este semestre y parte de la información e imágenes recopiladas aquí son de los recursos y materiales proporcionados o creados por él.
N-gramas :
N-grama es el modelo de lenguaje más simple que asigna probabilidades a una oración o secuencia de tokens. (Los modelos que asignan un valor de probabilidad a la secuencia de tokens se llaman modelos de lenguaje)
- Guía completa de métricas de evaluación de clasificación
- ¿Qué tan aleatorios son los goles en el fútbol?
- Consulta tus DataFrames con potentes modelos de lenguaje grandes utilizando LangChain.
Un n-grama es una secuencia de n tokens. La intuición detrás de los n-gramas es que en lugar de calcular la probabilidad de una palabra dada toda la historia, aproximamos la historia utilizando algunas palabras. La suposición de que la probabilidad de la siguiente palabra depende solo de la palabra anterior se conoce como la suposición de Markov. Los modelos de n-gramas examinan n-1 palabras en el pasado para predecir la probabilidad de una palabra.
Embeddings de Palabras :
La transformación de una palabra a su representación vectorial n-dimensional (de palabras que llevan un significado semántico) para otras tareas de NLP se llama embedding de palabras. Ejemplo: Word2Vec
Hay más de 10 millones de tokens en el corpus del idioma inglés. Los embeddings de palabras codifican cada palabra como un vector que se convierte en un punto en un espacio vectorial de palabras
La intuición es que dicho espacio vectorial de palabras codificará todas las semánticas del lenguaje o las palabras que tienen un contexto similar se asignarán a puntos próximos en un espacio vectorial.
Codificación One-Hot :
Representar una palabra en un formato vectorial de manera que la longitud del vector sea igual al tamaño del vocabulario y el elemento en el índice de esa palabra en particular será 1 y el resto serán 0.
Supongamos que tenemos una oración “Amo NLP”. La codificación One-Hot para la oración se ve así.

Este tipo de representación no proporciona una intuición sobre la semántica entre palabras o qué tan relacionadas están las palabras (cercanía contextual).
Creo que la desventaja de la codificación One-Hot también surge del hecho de que para datos muy grandes, el vector One-Hot va a ser extremadamente grande y disperso (con muchos ceros para almacenar). La representación One-Hot tampoco captura el contexto.
Enfoque basado en SVD :
Para un corpus enorme, realizamos SVD en una matriz de co-ocurrencia, y después de la descomposición, obtenemos los vectores U (matriz de vectores propios), S (matriz de valores propios) y V.T (transpuesta de V – inversa de la matriz de vectores propios).
A continuación se muestra la matriz de co-ocurrencia para las oraciones “Las rosas son rojas” y “El cielo es azul”. La matriz de co-ocurrencia indica cuántas veces la palabra de la fila está rodeada por la palabra de la columna en las oraciones.
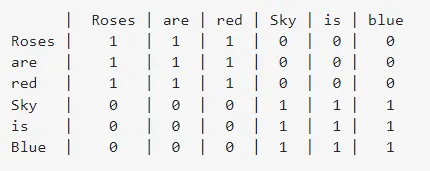
Los vectores de la matriz U, que es la matriz de vectores propios o los vectores singulares izquierdos, se considerarán como las representaciones vectoriales para las palabras.
Personalmente encontré interesante este artículo para aprender más sobre este enfoque: https://medium.com/analytics-vidhya/co-occurrence-matrix-singular-value-decomposition-svd-31b3d3deb305
Así que a partir del enlace anterior, aprendí las ventajas y desventajas de este método.
- Conocemos la relación entre las palabras en la matriz de co-ocurrencia.
2. Se puede calcular una vez y referirse a ella varias veces una vez calculada, pero esto conlleva una desventaja cuando se agregan nuevas palabras con frecuencia al corpus y las dimensiones de la matriz cambian continuamente.
3. Generalmente, requiere mucha memoria, especialmente cuando hay muchas palabras que no co-ocurren y la mayoría de los elementos son cero.
Matriz Término-Documento :
Como sugiere el nombre, creamos una representación matricial de dimensiones tamaño del vocabulario x número de documentos. Para una palabra del vocabulario, estamos representando el número de veces que aparece en cada documento.
No captura el orden/posición ni la semántica de las palabras.
Naturaleza distribucional del vector de palabras :
Se basa en la hipótesis de que se puede inferir el significado de la palabra en función del contexto en el que aparece.
No son buenos para representar palabras raras que ocurren muy pocas veces en el corpus. Sufre del problema de ambigüedad y no puede manejar la morfología (evaluar y evaluación se consideran diferentes).
Las incrustaciones de palabras se pueden clasificar ampliamente en dos categorías: Frecuencia (Ejemplo: Vector de conteo, Vector TF-IDF, Matriz de co-ocurrencia) y Predicción (Continuous Bag of Words (CBOW), Skip-Gram) basadas en incrustaciones.
Word2Vec :
Word2Vec es una red neuronal superficial de dos capas, entrenada para reconstruir los contextos lingüísticos de las palabras. Tiene dos arquitecturas: Continuous Bag-of-Words y Skip-gram.
Continuous Bag of Words :
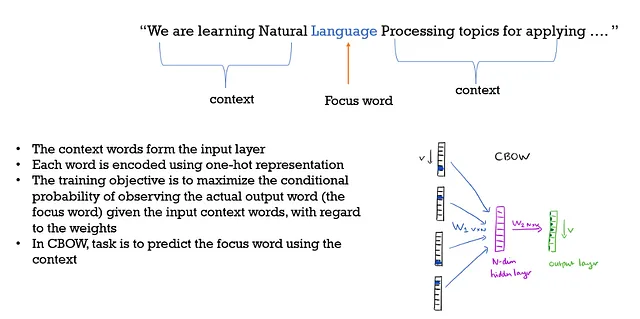
Función Objetivo :
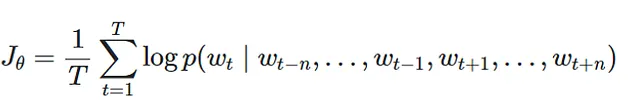
Para crear incrustaciones de palabras, se utilizan n palabras en el pasado y en el futuro.
Aumentar el tamaño de la ventana no ayuda, solo agrega más ruido.
Aquí, el contexto y el orden de las palabras no importan, por lo que solo estamos tomando el conjunto de palabras, y por eso “BOW” forma parte de su nombre. También proporciona la relación semántica de las palabras.
CBOW funciona mejor que Skip-gram porque pueden aprovechar mejor los datos de entrada para capturar de manera más eficiente los vectores de palabras.
Skip Grams :

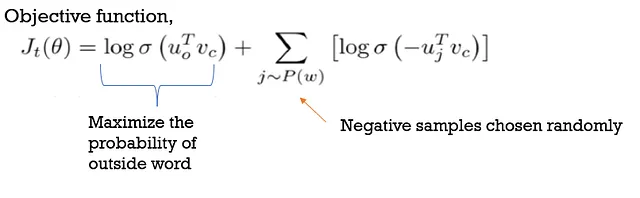
Aquí, la palabra objetivo es “input” mientras que las palabras de contexto son “output”, a diferencia de CBOW.
Es un enfoque de aprendizaje no supervisado, por lo que puede aprender de cualquier texto sin procesar proporcionado y requiere menos memoria. Configurar el número de neuronas en la capa oculta y obtener la posición del contexto es difícil y requiere mucho tiempo de entrenamiento.
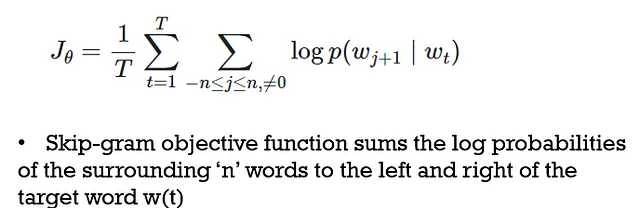
GLoVE (Vectores Globales para Representaciones de Palabras):
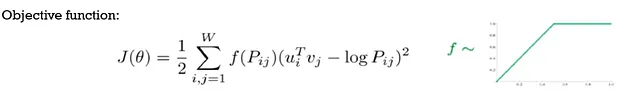
•El modelo Glove combina recuentos de co-ocurrencia palabra-palabra y enfoques basados en ventanas
<p•Se necesita calcular una matriz de co-ocurrencia muy grande al principio, denotada por 'P'
•Para cada par de palabras que puedan co-ocurrir, se minimiza la distancia entre el producto interno de dos palabras y el logaritmo del recuento de dos palabras
•El valor de la distancia al cuadrado se pondera utilizando f(Pij), lo que asignará pesos más bajos al par que tenga un recuento alto
•Aquí se consideran las ocurrencias individuales de palabras
FastText:
Se utiliza para la clasificación y representación eficiente de texto, FastText representa cada palabra como un conjunto de n-gramas de caracteres. Como los embeddings se aprenden utilizando n-gramas, tendrán información sobre los sufijos y prefijos.
La biblioteca de FastText para la representación y clasificación de palabras permite crear algoritmos de aprendizaje no supervisado o supervisado para obtener representaciones vectoriales de palabras.
FastText puede obtener vectores, incluso para palabras fuera del vocabulario (OOV), sumando los vectores de sus componentes de n-gramas de caracteres, siempre que al menos uno de los n-gramas de caracteres estuviera presente en los datos de entrenamiento.
Referencias:
- ‘Speech & language processing’, Daniel Jurafsky, James H Martin, preparation [citado el 1 de junio de 2020] (Disponible en: https://web. Stanford. edu/~ jurafsky/slp3 (2018))
- https://en.wikipedia.org/wiki/Word_embedding
- https://towardsdatascience.com/https-VoAGI-com-tanaygahlot-moving-beyond-the-distributional-model-for-word-representation-b0823f1769f8
- https://medium.com/analytics-vidhya/co-occurrence-matrix-singular-value-decomposition-svd-31b3d3deb305
- https://deepdatascience.wordpress.com/2017/04/25/word2vec-continous-bag-of-words/
- https://towardsdatascience.com/skip-gram-nlp-context-words-prediction-algorithm-5bbf34f84e0c
- https://www.kdnuggets.com/2016/05/amazing-power-word-vectors.html/2
Partes anteriores de esta serie:
Parte #1: https://medium.com/@deepthi.sudharsan/exploring-nlp-kickstarting-nlp-step-1-e4ad0029694f
Parte #2: https://medium.com/@deepthi.sudharsan/exploring-nlp-kickstarting-nlp-step-2-157a6c0b308b
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Transformada de Fourier para series de tiempo Graficando números complejos
- 5 Programas de Certificación en IA en línea – Explora e Inscríbete
- Optimizando Conexiones Optimización Matemática dentro de Grafos
- Utilizando cámaras en los autobuses de transporte público para monitorear el tráfico
- OpenAI discontinúa su detector de escritura de IA debido a una baja tasa de precisión
- Cómo la IA está transformando el panorama de la contratación a través de la coincidencia de candidatos
- LLMs en IA Conversacional Construyendo Chatbots y Asistentes más Inteligentes





