Desbloqueando el poder del difuminado facial en los medios una exploración exhaustiva y comparación de modelos
Exploración y comparación exhaustiva de modelos de difuminado facial en los medios
Comparación de varios algoritmos de detección y desenfoque de rostros

En el mundo actual impulsado por los datos, garantizar la privacidad y el anonimato de las personas es de suma importancia. Desde proteger las identidades personales hasta cumplir con regulaciones rigurosas como el GDPR, la necesidad de soluciones eficientes y confiables para anonimizar rostros en varios formatos de medios nunca ha sido mayor.
Contenidos
- Introducción
- Detección de rostros – Haar Cascade – MTCNN – YOLO
- Desenfoque de rostros – Desenfoque gaussiano – Pixelización
- Resultados y discusión – Rendimiento en tiempo real – Evaluación basada en escenarios – Privacidad
- Uso en videos
- Aplicación web
- Conclusión
Introducción
En este proyecto, exploramos y comparamos varias soluciones para el tema del desenfoque de rostros y desarrollamos una aplicación web que permite una evaluación fácil. Veamos las diversas aplicaciones que impulsan la demanda de un sistema de este tipo:
- Preservación de la privacidad
- Navegación en paisajes regulatorios: Con la evolución rápida del panorama regulatorio, las industrias y regiones de todo el mundo están aplicando normas más estrictas para proteger las identidades de las personas.
- Confidencialidad de los datos de entrenamiento: Los modelos de aprendizaje automático se benefician de datos de entrenamiento diversos y bien preparados. Sin embargo, compartir este tipo de datos a menudo requiere una anonimización cuidadosa.
Esta solución se puede dividir en dos componentes esenciales:
- Detección de rostros
- Técnicas de desenfoque de rostros
Detección de rostros
Para abordar el desafío de la anonimización, el primer paso es localizar el área en la imagen donde se encuentra un rostro. Para este propósito, probé tres modelos de detección de imágenes.
- 10 formas de mejorar el rendimiento de los sistemas de generación mejorada de recuperación
- 9 Razones por las que tu jefe quiere que asistas a ODSC West 2023
- Cómo se puede utilizar datos sintéticos para modelos de lenguaje grandes
Haar Cascade

Haar Cascade es un método de aprendizaje automático utilizado para la detección de objetos, como rostros, en imágenes o videos. Funciona utilizando un conjunto de características entrenadas llamadas “características tipo Haar” (Figura 1), que son filtros rectangulares simples que se centran en las variaciones en la intensidad de los píxeles dentro de regiones de la imagen. Estas características pueden capturar bordes, ángulos y otras características comúnmente encontradas en los rostros.
El proceso de entrenamiento implica proporcionar al algoritmo ejemplos positivos (imágenes que contienen rostros) y ejemplos negativos (imágenes sin rostros). Luego, el algoritmo aprende a diferenciar entre estos ejemplos ajustando los pesos de las características. Después del entrenamiento, Haar Cascade se convierte en una jerarquía de clasificadores, donde cada etapa refina progresivamente el proceso de detección.
Para la detección de rostros, utilicé un modelo Haar Cascade pre-entrenado entrenado en imágenes de rostros de frente.
import cv2face_cascade = cv2.CascadeClassifier('./configs/haarcascade_frontalface_default.xml')def haar(image): gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30)) print(len(faces) + " rostros detectados en total.") for (x, y, w, h) in faces: print(f"Rostro detectado en la caja {x} {y} {x+w} {y+h}")MTCNN
MTCNN (Redes Convolucionales en Cascada de Tareas Múltiples) es un algoritmo sofisticado y altamente preciso para la detección de rostros, que supera las capacidades de Haar Cascades. Diseñado para destacar en escenarios con diferentes tamaños de rostros, orientaciones y condiciones de iluminación, MTCNN aprovecha una serie de redes neuronales, cada una diseñada para ejecutar tareas específicas dentro del proceso de detección de rostros.
- Fase Uno – Generación de Propuestas: MTCNN inicia el proceso generando una multitud de regiones potenciales de rostros (cuadros delimitadores) a través de una pequeña red neuronal.
- Fase Dos – Refinamiento: Los candidatos generados en la primera fase pasan por un filtrado en este paso. Una segunda red neuronal evalúa los cuadros delimitadores propuestos, ajustando sus posiciones para una alineación más precisa con los límites verdaderos del rostro. Esto ayuda a mejorar la precisión.
- Fase Tres – Puntos de Características Faciales: Esta etapa identifica puntos de referencia faciales, como las esquinas de los ojos, la nariz y la boca. Se utiliza una red neuronal para localizar con precisión estos rasgos.
La arquitectura en cascada de MTCNN le permite descartar rápidamente regiones sin rostros al principio del proceso, concentrando los cálculos en áreas con una mayor probabilidad de contener rostros. Su capacidad para manejar diferentes escalas (niveles de zoom) de rostros y rotaciones lo hace muy adecuado para escenarios complicados en comparación con los Cascades de Haar. Sin embargo, su intensidad computacional se debe a su enfoque secuencial basado en redes neuronales.
Para la implementación de MTCNN, utilicé la biblioteca mtcnn.
import cv2from mtcnn import MTCNNdetector = MTCNN()def mtcnn_detector(image): faces = detector.detect_faces(image) print(len(faces) + " rostros detectados en total.") for face in faces: x, y, w, h = face['box'] print(f"Se detectó un rostro en el cuadro {x} {y} {x+w} {y+h}")YOLOv5
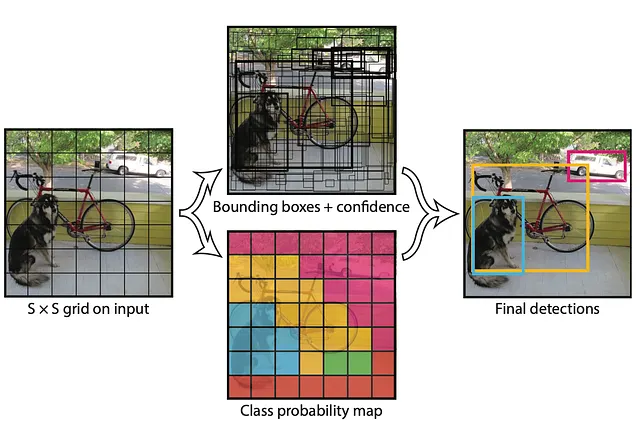
YOLO (You Only Look Once) es un algoritmo utilizado para detectar una multitud de objetos, incluyendo rostros. A diferencia de sus predecesores, YOLO realiza la detección en un solo paso a través de una red neuronal, lo que lo hace más rápido y más adecuado para aplicaciones en tiempo real y videos. El proceso de detección de rostros en medios con YOLO se puede resumir en cuatro partes:
- División de la Rejilla de Imágenes: La imagen de entrada se divide en una rejilla de celdas. Cada celda es responsable de predecir objetos ubicados dentro de sus límites. Para cada celda, YOLO predice cuadros delimitadores, probabilidades de objetos y probabilidades de clase.
- Predicción de Cuadros Delimitadores: Dentro de cada celda, YOLO predice uno o más cuadros delimitadores junto con sus correspondientes probabilidades. Estos cuadros delimitadores representan ubicaciones potenciales de objetos. Cada cuadro delimitador se define mediante sus coordenadas del centro, ancho, altura y la probabilidad de que exista un objeto dentro de ese cuadro delimitador.
- Predicción de Clase: Para cada cuadro delimitador, YOLO predice las probabilidades de varias clases (por ejemplo, ‘rostro’, ‘auto’, ‘perro’) a las que el objeto puede pertenecer.
- Supresión de No Máximo (NMS): Para eliminar cuadros delimitadores duplicados, YOLO aplica NMS. Este proceso descarta cuadros delimitadores redundantes evaluando sus probabilidades y superposición con otros cuadros, reteniendo solo los más confiables y no superpuestos.
La principal ventaja de YOLO radica en su velocidad. Dado que procesa la imagen completa en un solo paso a través de la red neuronal, es significativamente más rápido que los algoritmos que utilizan ventanas deslizantes o propuestas de región. Sin embargo, esta velocidad podría implicar un ligero compromiso con la precisión, especialmente para objetos más pequeños o escenas concurridas.
YOLO se puede adaptar para la detección de rostros entrenándolo con datos específicos de rostros y modificando sus clases de salida para incluir solo una clase (‘rostro’). Para esto, utilicé la biblioteca ‘yoloface’, construida sobre YOLOv5.
import cv2from yoloface import face_analysisface=face_analysis()def yolo_face_detection(image): img,box,conf=face.face_detection(image, model='tiny') print(len(box) + " rostros detectados en total.") for i in range(len(box)): x, y, h, w = box[i] print(f"Se detectó un rostro en el cuadro {x} {y} {x+w} {y+h}")Desenfoque de Rostros
Después de identificar los cuadros delimitadores alrededor de los posibles rostros en la imagen, el siguiente paso es desenfocarlos para eliminar sus identidades. Para esta tarea, desarrollé dos implementaciones. Se proporciona una imagen de referencia para su demostración en la Figura 4.
Desenfoque Gaussiano

El desenfoque gaussiano es una técnica de procesamiento de imágenes utilizada para reducir el ruido de la imagen y difuminar los detalles. Esto es especialmente útil en el ámbito del desenfoque de caras, ya que borra los detalles de esa parte de la imagen. Calcula un promedio de los valores de píxeles en el vecindario alrededor de cada píxel. Este promedio está centrado en el píxel que se está difuminando y se calcula utilizando una distribución gaussiana, dándole más peso a los píxeles cercanos y menos peso a los lejanos. El resultado es una imagen suavizada con menos ruido de alta frecuencia y detalles finos. El resultado de aplicar el desenfoque gaussiano se muestra en la Figura 5.
El desenfoque gaussiano tiene tres parámetros:
- Porción de la imagen que se va a difuminar.
- Tamaño del kernel: la matriz utilizada para la operación de difuminado. Un tamaño de kernel más grande produce un difuminado más fuerte.
- Desviación estándar: un valor más alto mejora el efecto de difuminado.
f = imagen[y:y + h, x:x + w]cara_difuminada = cv2.GaussianBlur(f, (99, 99), 15) # Puedes ajustar los parámetros del difuminadoimagen[y:y + h, x:x + w] = cara_difuminadaPixelización

La pixelización es una técnica de procesamiento de imágenes en la que los píxeles de una imagen se reemplazan con bloques más grandes de un solo color. Este efecto se logra dividiendo la imagen en una cuadrícula de celdas, donde cada celda corresponde a un grupo de píxeles. El color o intensidad de todos los píxeles en la celda se toma como el valor promedio de los colores de todos los píxeles en esa celda, y este valor promedio se aplica a todos los píxeles en la celda. Este proceso crea una apariencia simplificada, reduciendo el nivel de detalles finos en la imagen. El resultado de aplicar la pixelización se muestra en la Figura 6. Como se puede observar, la pixelización dificulta significativamente la identificación de la identidad de una persona.
La pixelización tiene un parámetro principal, que determina cuántos píxeles agrupados deben representar un área específica. Por ejemplo, si tenemos una sección (10,10) de la imagen que contiene una cara, esta se reemplazará con un grupo de píxeles de 10×10. Un número más pequeño produce un mayor difuminado.
f = imagen[y:y + h, x:x + w]f = cv2.resize(f, (10, 10), interpolation=cv2.INTER_NEAREST)imagen[y:y + h, x:x + w] = cv2.resize(f, (w, h), interpolation=cv2.INTER_NEAREST)Resultados y discusión
Evaluaré los diferentes algoritmos desde dos perspectivas: análisis de rendimiento en tiempo real y escenarios de imágenes específicos.
Rendimiento en tiempo real
Utilizando la misma imagen de referencia (Figura 4), se midió el tiempo requerido para que cada algoritmo de detección facial localice el cuadro delimitador de la cara en la imagen. Los resultados se basan en el valor promedio de 10 mediciones para cada algoritmo. El tiempo necesario para los algoritmos de difuminado es insignificante y no se tendrá en cuenta en el proceso de evaluación.

Se puede observar que YOLOv5 logra el mejor rendimiento (velocidad) debido a su procesamiento de una sola pasada a través de la red neuronal. En contraste, métodos como MTCNN requieren un recorrido secuencial a través de múltiples redes neuronales. Esto complica aún más el proceso de paralelización del algoritmo.
Rendimiento basado en escenarios
Para evaluar el rendimiento de los algoritmos mencionados anteriormente, además de la imagen de referencia (Figura 4), he seleccionado varias imágenes que prueban los algoritmos en varios escenarios:
- Imagen de referencia (Figura 4)
- Grupo de personas juntas – para evaluar la capacidad del algoritmo de capturar diferentes tamaños de rostros, algunos más cerca y otros más lejos (Figura 8)
- Rostros vistos de lado – probando la capacidad de los algoritmos para detectar rostros que no miran directamente a la cámara (Figura 10)
- Rostro volteado 180 grados – probando la capacidad de los algoritmos para detectar un rostro rotado 180 grados (Figura 11)
- Rostro volteado 90 grados – probando la capacidad de los algoritmos para detectar un rostro rotado 90 grados, de costado (Figura 12)



Haar Cascade
El algoritmo Haar Cascade generalmente tiene un buen rendimiento al anonimizar rostros, con algunas excepciones. Detecta exitosamente la imagen de referencia (Figura 4) y el escenario de ‘Múltiples rostros’ (Figura 9) de manera excelente. En el escenario de ‘Grupo de personas’ (Figura 8), maneja la tarea decentemente, aunque hay rostros que no se detectan por completo o están más lejos. Haar Cascade enfrenta desafíos con rostros que no miran directamente a la cámara (Figura 10) y rostros rotados (Figuras 11 y 12), donde no logra reconocer los rostros por completo.

MTCNN
MTCNN logra resultados muy similares a Haar Cascade, con las mismas fortalezas y debilidades. Además, MTCNN tiene dificultades para detectar el rostro en la Figura 9 con un tono de piel más oscuro.

YOLOv5
YOLOv5 produce resultados ligeramente diferentes a Haar Cascade y MTCNN. Detecta con éxito una de las caras cuando las personas no están mirando directamente a la cámara (Figura 10), así como la cara girada 180 grados (Figura 11). Sin embargo, en la imagen de ‘Grupo de personas’ (Figura 8), no detecta las caras más lejanas de manera tan efectiva como los algoritmos mencionados anteriormente.

Privacidad
Cuando se aborda el desafío de la privacidad en el procesamiento de imágenes, un aspecto crucial a considerar es el delicado equilibrio entre hacer que las caras no sean reconocibles y mantener el aspecto natural de las imágenes.
Desenfoque gaussiano
El desenfoque gaussiano desenfoca eficazmente la región facial en una imagen (como se muestra en la Figura 5). Sin embargo, su éxito depende de los parámetros de la distribución gaussiana utilizada para el efecto de desenfoque. En la Figura 5, es evidente que las características faciales siguen siendo discernibles, lo que sugiere la necesidad de desviaciones estándar y tamaños de kernel más altos para lograr resultados óptimos.
Pixelización
La pixelización (como se ilustra en la Figura 6) a menudo resulta más agradable a la vista debido a su familiaridad como método de difuminado de caras en comparación con el desenfoque gaussiano. El número de píxeles utilizados para la pixelización juega un papel fundamental en este contexto, ya que un recuento de píxeles más pequeño hace que la cara sea menos reconocible pero puede resultar en una apariencia menos natural.
En general, se ha preferido la pixelización sobre el algoritmo de desenfoque gaussiano. Se basa en su familiaridad y naturalidad contextual, logrando un equilibrio entre privacidad y estética.
Ingeniería inversa
Con el aumento de las herramientas de inteligencia artificial, se vuelve imperativo anticipar el potencial de técnicas de ingeniería inversa destinadas a eliminar los filtros de privacidad de las imágenes difuminadas. Sin embargo, el simple acto de difuminar una cara reemplaza de manera irreversible detalles faciales específicos con otros más generalizados. Hasta ahora, las herramientas de inteligencia artificial solo pueden realizar ingeniería inversa en una cara difuminada cuando se presentan imágenes de referencia claras de la misma persona. Paradójicamente, esto contradice la necesidad de ingeniería inversa en primer lugar, ya que presupone el conocimiento de la identidad del individuo. Por lo tanto, el difuminado facial se erige como un medio eficiente y necesario para salvaguardar la privacidad frente a las capacidades en constante evolución de la inteligencia artificial.
Uso en videos
Dado que los videos son esencialmente una secuencia de imágenes, es relativamente sencillo modificar cada algoritmo para realizar la anonimización en videos. Sin embargo, aquí el tiempo de procesamiento se vuelve crucial. Para un video de 30 segundos grabado a 60 cuadros por segundo (imágenes por segundo), los algoritmos necesitarían procesar 1800 cuadros. En este contexto, algoritmos como MTCNN no serían viables, a pesar de sus mejoras en ciertos escenarios. Por lo tanto, decidí implementar la anonimización de video utilizando el modelo YOLO.
import cv2from yoloface import face_analysisface=face_analysis()def yolo_face_detection_video(video_path, output_path, pixelate): cap = cv2.VideoCapture(video_path) if not cap.isOpened(): raise ValueError("No se pudo abrir el archivo de video") # Obtener propiedades del video fps = int(cap.get(cv2.CAP_PROP_FPS)) frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # Definir el códec y crear un objeto VideoWriter para el video de salida fourcc = cv2.VideoWriter_fourcc(*'H264') out = cv2.VideoWriter(output_path, fourcc, fps, (frame_width, frame_height)) while cap.isOpened(): ret, frame = cap.read() if not ret: break tm = time.time() img, box, conf = face.face_detection(frame_arr=frame, frame_status=True, model='tiny') print(pixelate) for i in range(len(box)): x, y, h, w = box[i] if pixelate: f = img[y:y + h, x:x + w] f = cv2.resize(f, (10, 10), interpolation=cv2.INTER_NEAREST) img[y:y + h, x:x + w] = cv2.resize(f, (w, h), interpolation=cv2.INTER_NEAREST) else: blurred_face = cv2.GaussianBlur(img[y:y + h, x:x + w], (99, 99), 30) # Puedes ajustar los parámetros de desenfoque img[y:y + h, x:x + w] = blurred_face print(time.time() - tm) out.write(img) cap.release() out.release() cv2.destroyAllWindows()Aplicación web
Para una evaluación simplificada de los diferentes algoritmos, creé una aplicación web donde los usuarios pueden cargar cualquier imagen o video, seleccionar el algoritmo de detección y difuminado de rostros, y después de procesarlo, se devuelve el resultado al usuario. La implementación se realizó utilizando Flask con Python en el backend, utilizando las bibliotecas mencionadas, así como OpenCV, y React.js en el frontend para la interacción del usuario con los modelos. El código completo está disponible en este enlace.
Conclusión
Dentro del alcance de esta publicación, se exploraron, compararon y analizaron varios algoritmos de detección de rostros, incluyendo Haar Cascade, MTCNN y YOLOv5, en diferentes aspectos. El proyecto también se centró en técnicas de difuminado de imágenes.
Haar Cascade demostró ser un método eficiente en ciertos escenarios, exhibiendo un rendimiento temporal generalmente bueno. MTCNN se destacó como un algoritmo con sólidas capacidades de detección de rostros en diversas condiciones, aunque tuvo dificultades con rostros que no suelen estar en una orientación convencional. YOLOv5, con sus capacidades de detección de rostros en tiempo real, se convirtió en una excelente opción para escenarios donde el tiempo es un factor crítico (como videos), aunque con una precisión ligeramente reducida en entornos de grupo.
Todos los algoritmos y técnicas se integraron en una sola aplicación web. Esta aplicación proporciona un acceso fácil y la utilización de todos los métodos de detección y difuminado de rostros, junto con la capacidad de procesar videos utilizando técnicas de difuminado.
Esta publicación es una conclusión de mi trabajo para el curso “Procesamiento Digital de Imágenes” en la Facultad de Ciencias de la Computación y la Ingeniería en Skopje. ¡Gracias por leer!
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Control de versiones de datos para lagos de datos manejo de los cambios a gran escala
- 10 Temas populares que llegarán a ODSC West 2023
- Python en Excel Esto Cambiará la Ciencia de Datos para Siempre
- Técnicas de Aprendizaje en Conjunto Un Recorrido con Bosques Aleatorios en Python
- Nueva forma revolucionaria de entrenar chips neuromórficos
- Integración de IA y Blockchain para preservar la privacidad
- Binny Gill, Fundador y CEO de Kognitos – Serie de Entrevistas





