Explicar decisiones médicas en entornos clínicos utilizando Amazon SageMaker Clarify
Explicar decisiones médicas con Amazon SageMaker Clarify
La explicabilidad de los modelos de aprendizaje automático (ML) utilizados en el ámbito médico se está volviendo cada vez más importante porque es necesario explicar los modelos desde diversas perspectivas para lograr su adopción. Estas perspectivas van desde la médica, tecnológica, legal y, la perspectiva más importante, la del paciente. Los modelos desarrollados en el ámbito médico han demostrado ser precisos estadísticamente, sin embargo, los clínicos están éticamente obligados a evaluar las áreas de debilidad relacionadas con estas predicciones para proporcionar la mejor atención a los pacientes individuales. La explicabilidad de estas predicciones es necesaria para que los clínicos puedan tomar las decisiones correctas caso por caso.
En esta publicación, mostramos cómo mejorar la explicabilidad del modelo en entornos clínicos utilizando Amazon SageMaker Clarify.
Antecedentes
Una aplicación específica de algoritmos de ML en el ámbito médico, que utiliza grandes volúmenes de texto, son los sistemas de soporte para la toma de decisiones clínicas (CDSS, por sus siglas en inglés) para la clasificación de pacientes. A diario, los pacientes son admitidos en hospitales y se toman notas de admisión. Después de tomar estas notas, se inicia el proceso de clasificación y los modelos de ML pueden ayudar a los clínicos a estimar los resultados clínicos. Esto puede ayudar a reducir los costos operativos y brindar atención óptima a los pacientes. Comprender por qué los modelos de ML sugieren estas decisiones es extremadamente importante para la toma de decisiones relacionadas con los pacientes individuales.
El propósito de esta publicación es describir cómo se pueden implementar modelos predictivos con Amazon SageMaker con el fin de realizar una clasificación de pacientes en entornos hospitalarios y utilizar SageMaker Clarify para explicar estas predicciones. El objetivo es ofrecer un camino acelerado para la adopción de técnicas predictivas en los CDSS para muchas organizaciones de atención médica.
- Robot humanoide puede pilotar un avión mejor que un humano
- ChatGPT tiende hacia el liberalismo
- Descifrando el código del contexto Técnicas de vectorización de palabras en PNL
El cuaderno de notas y el código de esta publicación están disponibles en GitHub. Para ejecutarlo usted mismo, clone el repositorio de GitHub y abra el archivo del cuaderno Jupyter.
Antecedentes técnicos
Un activo importante para cualquier organización de atención médica aguda son sus notas clínicas. En el momento de la admisión en un hospital, se toman notas de admisión. Varios estudios recientes han demostrado la capacidad predictiva de indicadores clave como diagnósticos, procedimientos, duración de la estancia y mortalidad intrahospitalaria. Ahora es altamente factible predecir estos indicadores solo a partir de las notas de admisión, mediante el uso de algoritmos de procesamiento del lenguaje natural (NLP, por sus siglas en inglés) [1].
Los avances en los modelos de NLP, como Bi-directional Encoder Representations from Transformers (BERT), han permitido realizar predicciones altamente precisas sobre un corpus de texto, como las notas de admisión, que antes era difícil obtener valor de ellas. La predicción de los indicadores clínicos es muy aplicable para su uso en un CDSS.
Sin embargo, para utilizar las nuevas predicciones de manera efectiva, todavía es necesario explicar cómo estos modelos precisos de BERT están logrando sus predicciones. Hay varias técnicas para explicar las predicciones de estos modelos. Una técnica es SHAP (SHapley Additive exPlanations), que es una técnica agnóstica al modelo para explicar la salida de los modelos de ML.
¿Qué es SHAP?
Los valores SHAP son una técnica para explicar la salida de los modelos de ML. Proporciona una forma de descomponer la predicción de un modelo de ML y comprender cuánto contribuye cada característica de entrada a la predicción final.
Los valores SHAP se basan en la teoría de juegos, específicamente en el concepto de valores de Shapley, que originalmente se propusieron para asignar el pago de un juego cooperativo entre sus jugadores [2]. En el contexto de ML, cada característica en el espacio de entrada se considera un jugador en un juego cooperativo, y la predicción del modelo es el pago. Los valores SHAP se calculan examinando la contribución de cada característica a la predicción del modelo para cada combinación posible de características. Luego se calcula la contribución promedio de cada característica en todas las combinaciones posibles de características, y esto se convierte en el valor SHAP para esa característica.
SHAP permite que los modelos expliquen predicciones sin entender el funcionamiento interno del modelo. Además, existen técnicas para mostrar estas explicaciones SHAP en texto, de modo que las perspectivas médicas y de los pacientes puedan comprender intuitivamente cómo los algoritmos llegan a sus predicciones.
Con las nuevas incorporaciones a SageMaker Clarify y el uso de modelos preentrenados de Hugging Face que se pueden usar fácilmente en SageMaker, el entrenamiento del modelo y la explicabilidad pueden realizarse fácilmente en AWS.
A modo de ejemplo completo, tomamos el resultado clínico de la mortalidad intrahospitalaria y mostramos cómo se puede implementar este proceso fácilmente en AWS utilizando un modelo BERT preentrenado de Hugging Face, y las predicciones se explicarán utilizando SageMaker Clarify.
Elección del modelo de Hugging Face
Hugging Face ofrece una variedad de modelos BERT preentrenados que se han especializado para su uso en notas clínicas. Para esta publicación, utilizamos el modelo bigbird-base-mimic-mortality. Este modelo es una versión ajustada del modelo BigBird de Google, adaptado específicamente para predecir la mortalidad utilizando las notas de admisión de la unidad de cuidados intensivos MIMIC. La tarea del modelo es determinar la probabilidad de que un paciente no sobreviva a una estancia particular en la unidad de cuidados intensivos según las notas de admisión. Una de las ventajas significativas de usar este modelo BigBird es su capacidad para procesar longitudes de contexto más largas, lo que significa que podemos ingresar las notas de admisión completas sin necesidad de truncarlas.
Nuestros pasos implican desplegar este modelo ajustado en SageMaker. Luego incorporamos este modelo en una configuración que permite una explicación en tiempo real de sus predicciones. Para lograr este nivel de explicabilidad, utilizamos SageMaker Clarify.
Descripción general de la solución
SageMaker Clarify proporciona a los desarrolladores de ML herramientas diseñadas específicamente para obtener una mayor comprensión de sus datos y modelos de entrenamiento de ML. SageMaker Clarify explica tanto las predicciones globales como las locales, y explica las decisiones tomadas por modelos de visión por computadora (CV) y modelos de procesamiento del lenguaje natural (NLP).
El siguiente diagrama muestra la arquitectura de SageMaker para alojar un punto de conexión que sirve solicitudes de explicabilidad. Incluye las interacciones entre un punto de conexión, el contenedor de modelo y el explicador de SageMaker Clarify.
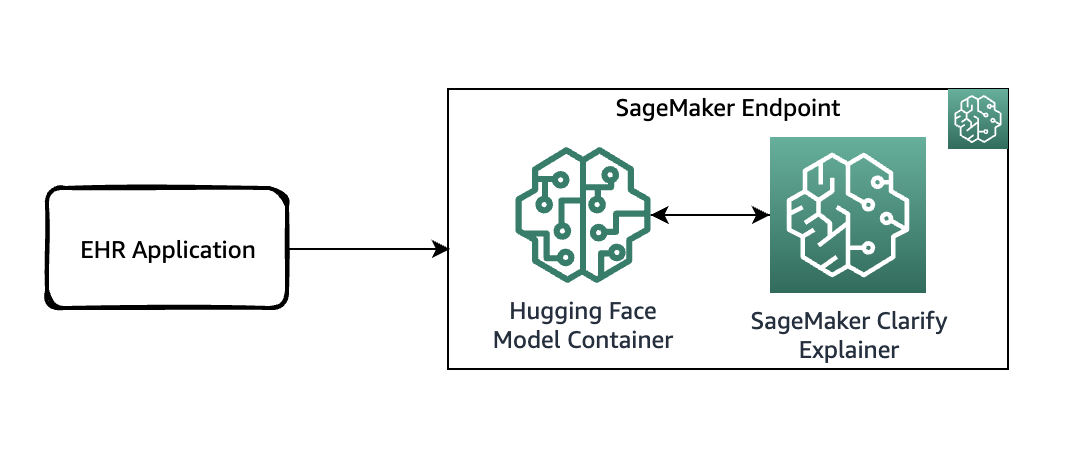
En el código de ejemplo, utilizamos un cuaderno Jupyter para mostrar la funcionalidad. Sin embargo, en un caso de uso del mundo real, los registros electrónicos de salud (EHR) u otras aplicaciones de atención hospitalaria invocarían directamente el punto de enlace de SageMaker para obtener la misma respuesta. En el cuaderno Jupyter, implementamos un contenedor de modelo Hugging Face en un punto de enlace de SageMaker. Luego, utilizamos SageMaker Clarify para explicar los resultados que obtenemos del modelo implementado.
Requisitos previos
Necesitas los siguientes requisitos previos:
- Una cuenta de AWS
- Una instancia de cuaderno SageMaker
Accede al código desde el repositorio de GitHub y cárgalo en tu instancia de cuaderno. También puedes ejecutar el cuaderno en un entorno de Amazon SageMaker Studio, que es un entorno de desarrollo integrado (IDE) para el desarrollo de ML. Recomendamos utilizar un kernel de Python 3 (Data Science) en SageMaker Studio o un kernel conda_python3 en una instancia de cuaderno de SageMaker.
Implementar el modelo con SageMaker Clarify habilitado
Como primer paso, descarga el modelo de Hugging Face y cárgalo en un bucket de Amazon Simple Storage Service (Amazon S3). Luego crea un objeto de modelo utilizando la clase HuggingFaceModel. Esto utiliza un contenedor predefinido para simplificar el proceso de implementación de modelos de Hugging Face en SageMaker. También utilizas un script de inferencia personalizado para hacer las predicciones dentro del contenedor. El siguiente código ilustra el script que se pasa como argumento a la clase HuggingFaceModel:
from sagemaker.huggingface import HuggingFaceModel
# crear la clase Hugging Face Model
huggingface_model = HuggingFaceModel(
model_data = model_path_s3,
transformers_version='4.6.1',
pytorch_version='1.7.1',
py_version='py36',
role=role,
source_dir = "./{}/code".format(model_id),
entry_point = "inference.py"
)Luego puedes definir el tipo de instancia en la que implementar este modelo:
instance_type = "ml.g4dn.xlarge"
container_def = huggingface_model.prepare_container_def(instance_type=instance_type)
container_defLuego poblamos los campos ExecutionRoleArn, ModelName y PrimaryContainer para crear un Modelo.
model_name = "modelo-de-triage-hospitalario"
sagemaker_client.create_model(
ExecutionRoleArn=role,
ModelName=model_name,
PrimaryContainer=container_def,
)
print(f"Modelo creado: {model_name}")A continuación, crea una configuración de punto de enlace llamando a la API create_endpoint_config. Aquí, proporcionas el mismo model_name utilizado en la llamada a la API create_model. La llamada a create_endpoint_config ahora admite el parámetro adicional ClarifyExplainerConfig para habilitar el explicador de SageMaker Clarify. La línea de base SHAP es obligatoria; puedes proporcionarla como datos de línea de base en línea (el parámetro ShapBaseline) o mediante un archivo de línea de base en S3 (el parámetro ShapBaselineUri). Para obtener información sobre los parámetros opcionales, consulta la guía del desarrollador.
En el siguiente código, utilizamos un token especial como línea de base:
baseline = [["<UNK>"]]
print(f"Línea de base SHAP: {baseline}")La configuración de TextConfig está configurada con una granularidad a nivel de oración (cada oración es una característica, y necesitamos algunas oraciones por reseña para una buena visualización) y el idioma es inglés:
endpoint_config_name = "hospital-triage-model-ep-config"
csv_serializer = sagemaker.serializers.CSVSerializer()
json_deserializer = sagemaker.deserializers.JSONDeserializer()
sagemaker_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"VariantName": "MainVariant",
"ModelName": model_name,
"InitialInstanceCount": 1,
"InstanceType": instance_type,
}
],
ExplainerConfig={
"ClarifyExplainerConfig": {
"InferenceConfig": {"FeatureTypes": ["text"]},
"ShapConfig": {
"ShapBaselineConfig": {"ShapBaseline": csv_serializer.serialize(baseline)},
"TextConfig": {"Granularity": "sentence", "Language": "en"},
},
}
},
)Finalmente, después de tener el modelo y la configuración del punto de enlace listos, utiliza la API create_endpoint para crear tu punto de enlace. El nombre del endpoint_name debe ser único dentro de una región en tu cuenta de AWS. La API create_endpoint es sincrónica por naturaleza y devuelve una respuesta inmediata con el estado del punto de enlace en el estado de Creación.
endpoint_name = "hospital-triage-prediction-endpoint"
sagemaker_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name,
)Explicar la predicción
Ahora que has implementado el punto de enlace con la explicabilidad en tiempo real habilitada, puedes probar algunos ejemplos. Puedes invocar el punto de enlace en tiempo real utilizando el método invoke_endpoint proporcionando la carga útil serializada, que en este caso es una muestra de notas de admisión:
response = sagemaker_runtime_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="text/csv",
Accept="text/csv",
Body=csv_serializer.serialize(sample_admission_note.iloc[:1, :].to_numpy())
)
result = json_deserializer.deserialize(response["Body"], content_type=response["ContentType"])
pprint.pprint(result)En el primer escenario, supongamos que se tomó la siguiente nota de admisión médica por parte de un trabajador de la salud:
“El paciente es un hombre de 25 años con una queja principal de dolor torácico agudo. El paciente informa que el dolor comenzó repentinamente mientras trabajaba y ha sido constante desde entonces. El paciente califica el dolor con una severidad de 8/10. El paciente niega cualquier irradiación del dolor, falta de aliento, náuseas o vómitos. El paciente no reporta antecedentes previos de dolor torácico. Los signos vitales son los siguientes: presión arterial 140/90 mmHg. Frecuencia cardíaca 92 latidos por minuto. Frecuencia respiratoria 18 respiraciones por minuto. Saturación de oxígeno del 96% con aire ambiente. El examen físico revela leve sensibilidad a la palpación sobre el precordio y campos pulmonares claros. El EKG muestra taquicardia sinusal sin elevación ni depresión del segmento ST.”La siguiente captura de pantalla muestra los resultados del modelo.

Después de que esto se envía al punto de enlace de SageMaker, la etiqueta se predice como 0, lo que indica que el riesgo de mortalidad es bajo. En otras palabras, 0 implica que el paciente admitido se encuentra en una condición no aguda según el modelo. Sin embargo, necesitamos la razón detrás de esa predicción. Para eso, puedes utilizar los valores SHAP como respuesta. La respuesta incluye los valores SHAP correspondientes a las frases de la nota de entrada, que se pueden codificar con colores verde o rojo en función de cómo contribuyen los valores SHAP a la predicción. En este caso, vemos más frases en verde, como “El paciente no reporta antecedentes previos de dolor torácico” y “El EKG muestra taquicardia sinusal sin elevación ni depresión del segmento ST”, en lugar de rojo, lo que se alinea con la predicción de mortalidad de 0.
En el segundo escenario, supongamos que se tomó la siguiente nota de admisión médica por parte de un trabajador de la salud:
“La paciente es una mujer de 72 años con una queja principal de sepsis severa y shock séptico. La paciente informa tener fiebre, escalofríos y debilidad durante los últimos 3 días, así como disminución de la producción de orina y confusión. La paciente tiene antecedentes de enfermedad pulmonar obstructiva crónica (EPOC) y una hospitalización reciente por neumonía. Los signos vitales son los siguientes: presión arterial 80/40 mmHg. Frecuencia cardíaca 130 latidos por minuto. Frecuencia respiratoria 30 respiraciones por minuto. Saturación de oxígeno del 82% con 4L de oxígeno a través de cánula nasal. El examen físico revela eritema y calor difuso en las extremidades inferiores y hallazgos positivos de sepsis como alteración del estado mental, taquicardia y taquipnea. Se tomaron cultivos de sangre y se inició terapia con antibióticos con la cobertura adecuada.”La siguiente captura de pantalla muestra nuestros resultados.
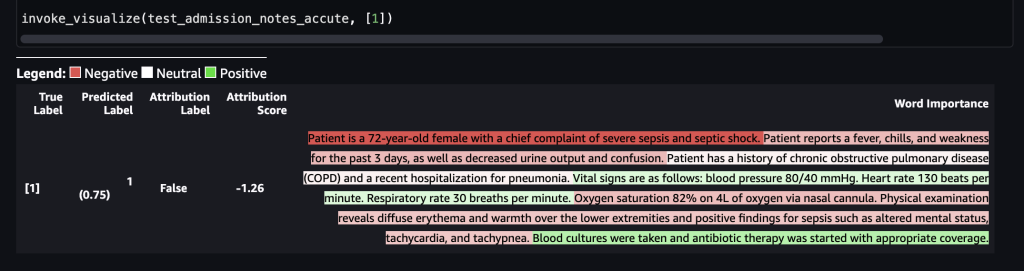
Después de que esto se envía al punto final de SageMaker, la etiqueta se predijo como 1, lo que indica que el riesgo de mortalidad es alto. Esto implica que el paciente admitido se encuentra en una condición aguda según el modelo. Sin embargo, necesitamos el razonamiento detrás de esa predicción. Nuevamente, puedes usar los valores SHAP como respuesta. La respuesta incluye los valores SHAP correspondientes a las frases de la nota de entrada, que se pueden codificar con colores. En este caso, vemos más frases en rojo, como “El paciente informa fiebre, escalofríos y debilidad durante los últimos 3 días, así como disminución de la producción de orina y confusión” y “La paciente es una mujer de 72 años con un principal queja de choque séptico grave”, en lugar de verde, alineándose con la predicción de mortalidad de 1.
El equipo de atención clínica puede utilizar estas explicaciones para ayudar en sus decisiones sobre el proceso de atención para cada paciente individual.
Limpiar
Para limpiar los recursos que se han creado como parte de esta solución, ejecuta las siguientes declaraciones:
huggingface_model.delete_model()
predictor = sagemaker.Predictor(endpoint_name="triage-prediction-endpoint")
predictor.delete_endpoint()Conclusión
Esta publicación te mostró cómo utilizar SageMaker Clarify para explicar decisiones en un caso de uso de atención médica basado en las notas médicas capturadas durante diversas etapas del proceso de triaje. Esta solución se puede integrar en los sistemas de apoyo a decisiones existentes para proporcionar otro punto de datos a los médicos mientras evalúan a los pacientes para su admisión en la UCI. Para obtener más información sobre cómo utilizar los servicios de AWS en la industria de la salud, consulta las siguientes publicaciones de blog:
- Presentación de la Lente de la Industria de la Salud para el Marco Bien-Arquitectado de AWS
- Cómo Telescope Health optimiza la atención virtual en la nube
- El camino hacia una mejor atención quirúrgica con análisis de quirófano en AWS
- Predicción de la readmisión de pacientes diabéticos utilizando entrenamiento multimodelo en Amazon SageMaker Pipelines
- Cómo Pieces Technologies aprovecha los servicios de AWS para predecir los resultados de los pacientes
Referencias
[1] https://aclanthology.org/2021.eacl-main.75/
[2] https://arxiv.org/pdf/1705.07874.pdf
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Métricas ROUGE Evaluando Resúmenes en Modelos de Lenguaje Grandes.
- El poder de la IA generativa en Snapchat
- Revelando Redes de Flujo Bayesiano Una Nueva Frontera en la Modelización Generativa
- Revisión de Copy AI ¿La mejor herramienta de escritura AI?
- Aceptando el Arte de la Visualización Narrativa de Datos
- Este artículo de IA de China propone un Agente de Planificación de Tareas (TaPA) en Tareas Encarnadas para la Planificación Fundamentada con Restricciones de Escena Física
- 10 Mejores Herramientas de IA para el Marketing de Afiliados (Agosto 2023)






