Error de Calibración Esperado (ECE) – una explicación visual paso a paso
Explicación visual del ECE
Con un ejemplo simple y código Python
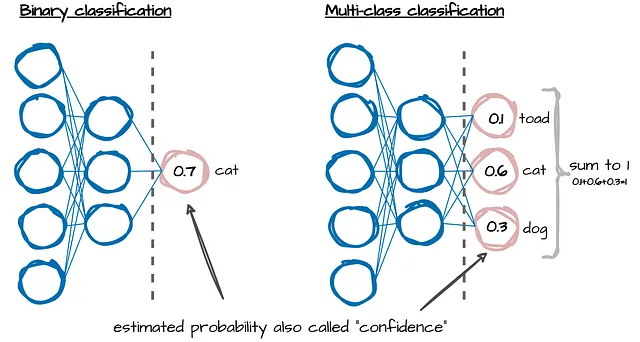
En tareas de clasificación, los modelos de aprendizaje automático producen probabilidades estimadas o también llamadas confianzas (ver imagen de arriba). Estas nos indican qué tan seguros está el modelo en sus predicciones de etiquetas. Sin embargo, para la mayoría de los modelos, estas confianzas no se alinean con las frecuencias reales de los eventos que está prediciendo. ¡Necesitan ser calibradas!
La calibración del modelo tiene como objetivo alinear las predicciones de un modelo con las probabilidades reales y asegurar así que las predicciones de un modelo sean confiables y precisas (ver esta publicación de blog para obtener más detalles sobre la importancia de la calibración del modelo).
Entonces, la calibración del modelo es importante, pero ¿cómo la medimos? Hay algunas opciones, pero el propósito y enfoque de este artículo es explicar y mostrar solo una medida simple pero relativamente suficiente para evaluar la calibración del modelo: el Error de Calibración Esperado (ECE). Calcula el error promedio ponderado de las “probabilidades” estimadas, lo que nos da un valor único que podemos usar para comparar diferentes modelos.
Repasaremos la fórmula de ECE tal como se describe en el artículo: “Sobre la calibración de las redes neuronales modernas”. Para simplificar, analizaremos un pequeño ejemplo con 9 puntos de datos y objetivos binarios. Luego, también codificaremos este ejemplo simple en Python, y por último, explicaremos cómo agregar unas pocas líneas de código para que también funcione para la clasificación de múltiples clases.
- Monitoreo de datos no estructurados para LLM y NLP
- Aliasing Tu serie de tiempo te está mintiendo
- IA generativa y el futuro de la ingeniería de datos
Definición
ECE mide qué tan bien las “probabilidades” estimadas de un modelo coinciden con las probabilidades reales (observadas), tomando un promedio ponderado de la diferencia absoluta entre la precisión (acc) y la confianza (conf):
La medida implica dividir los datos en M intervalos igualmente espaciados. B se usa para representar “intervalos” y m para el número del intervalo. Volveremos a las partes individuales de esta fórmula, como B, |Bₘ|, acc(Bₘ) y conf(Bₘ), con más detalle más adelante. Primero, veamos nuestro ejemplo, que nos ayudará a hacer que la fórmula sea más fácil de entender paso a paso.
Ejemplo
Tenemos 9 muestras con probabilidades estimadas o también llamadas ‘confianzas’ (pᵢ) para predecir la etiqueta positiva 1. Si…
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- La IA también debería aprender a olvidar
- Cómo los bancos deben aprovechar la IA responsable para abordar el crimen financiero
- Investigadores de la Universidad de Pekín presentan FastServe un sistema de servicio de inferencia distribuida para modelos de lenguaje grandes (LLMs).
- Consejos y trucos para integrar la IA en un equipo bien conectado
- Principales 6 usos de la IA en el sector del transporte
- Expande tu negocio con 3 indicaciones de ChatGPT (El método de Alex Hormozi)
- Pruebas de IVR en la era de la IA Cerrando la brecha entre humanos y máquinas






