De Experimentos 🧪 a Despliegue 🚀 MLflow 101 | Parte 01
Experimentos a Despliegue MLflow 101 | Parte 01
Potencia tu viaje de MLOps creando un filtro de spam usando Streamlit y MLflow

¿Por qué❓
Imagina esto: tienes una nueva idea de negocio, y los datos que necesitas están justo al alcance de tu mano. Estás emocionado/a por sumergirte en la creación de ese fantástico modelo de aprendizaje automático 🤖. Pero seamos realistas, ¡este viaje no es pan comido! Estarás experimentando como loco/a, lidiando con el preprocesamiento de datos, eligiendo algoritmos y ajustando hiperparámetros hasta que te mareas 😵💫. A medida que el proyecto se vuelve más complicado, es como tratar de atrapar humo: pierdes el rastro de todos esos experimentos locos y brillantes ideas que tuviste en el camino. Y créeme, recordarlo todo es más difícil que pastorear gatos 😹
Pero espera, ¡hay más! Una vez que tienes ese modelo, ¡tienes que implementarlo como un campeón! Y con datos y necesidades de los clientes en constante cambio, ¡reentrenarás tu modelo más veces de las que te cambias los calcetines! Es como una montaña rusa interminable, y necesitas una solución sólida como una roca para mantenerlo todo en orden 🔗. ¡Entra MLOps! Es la salsa secreta que pone orden en el caos ⚡
De acuerdo, amigos, ahora que tenemos el Por qué detrás de nosotros, sumerjámonos en el Qué y lo jugoso del Cómo en este blog.
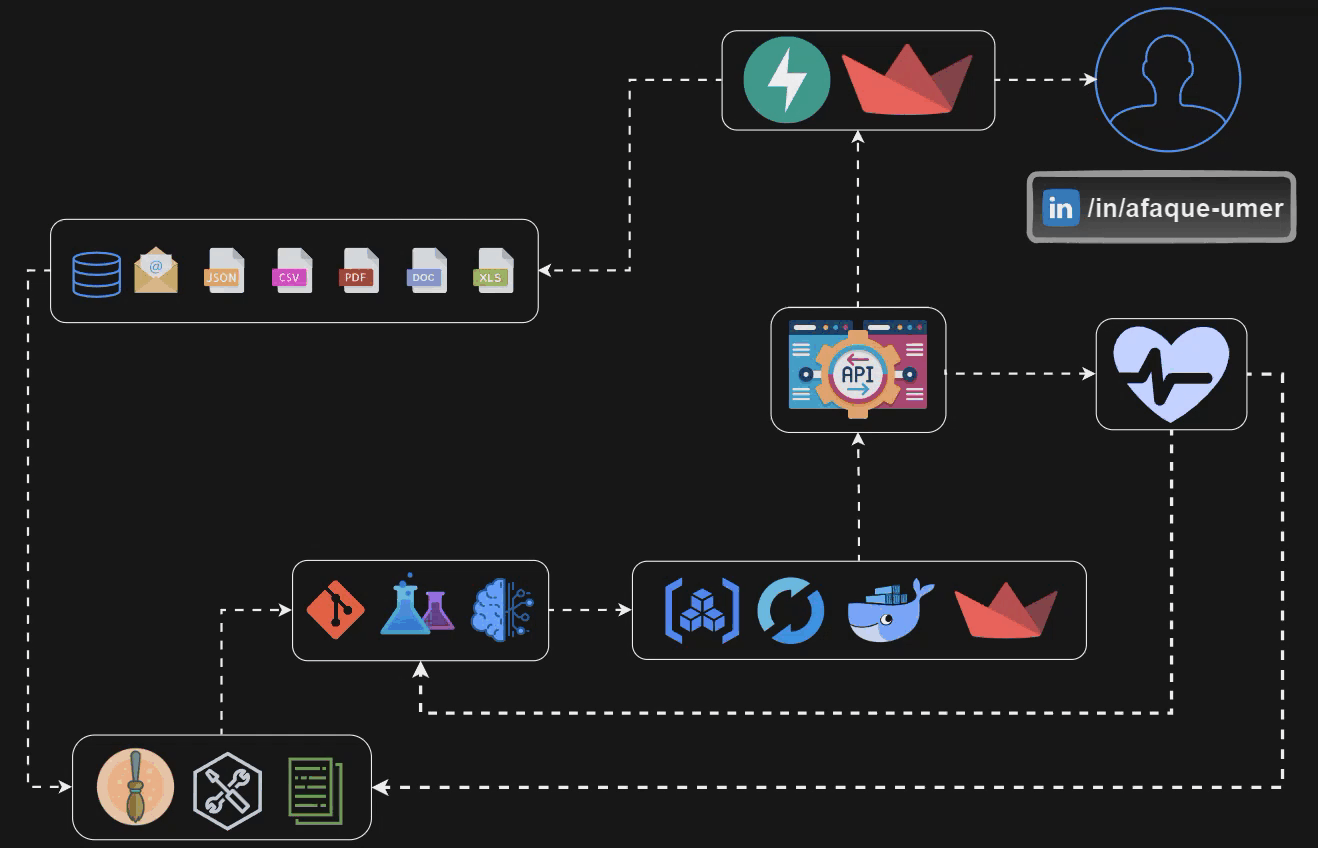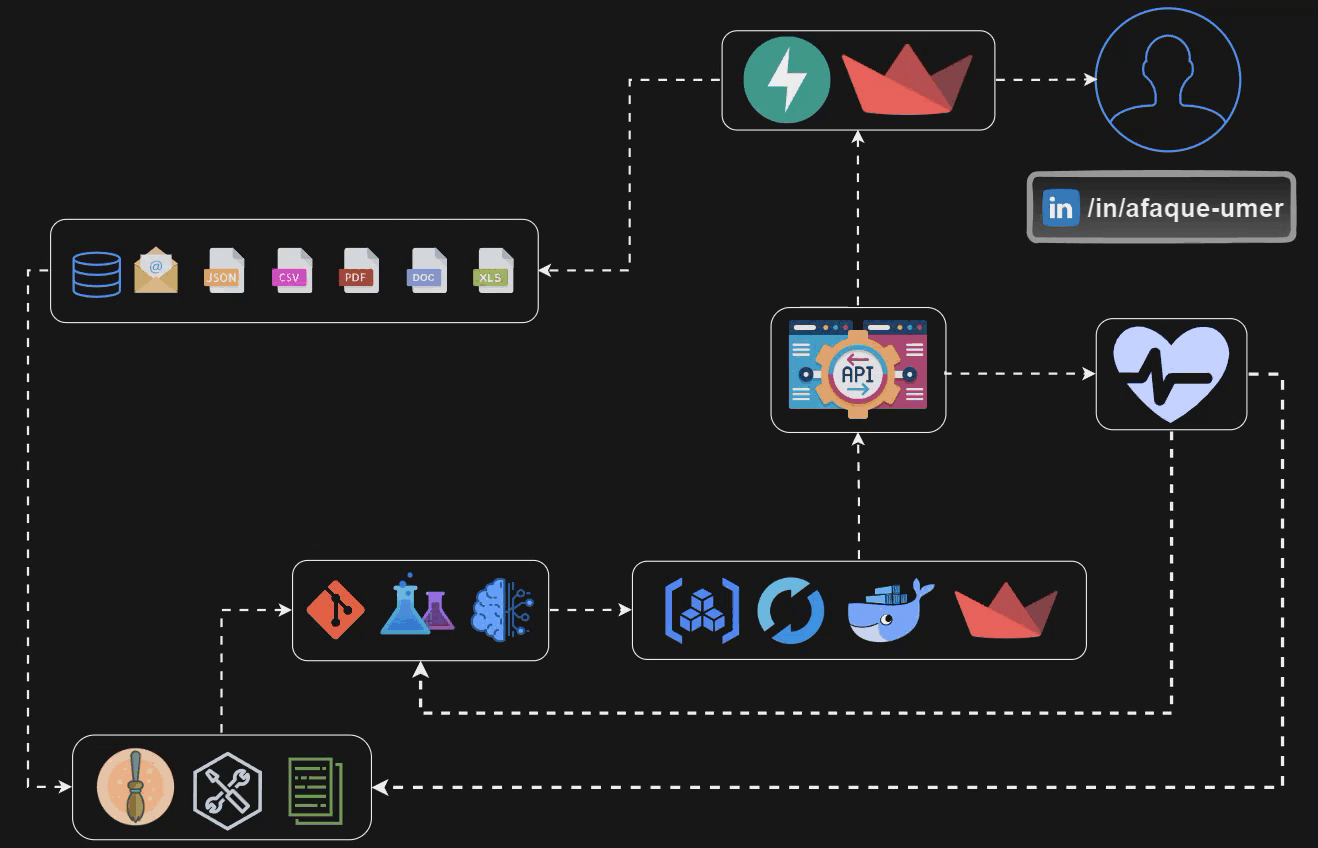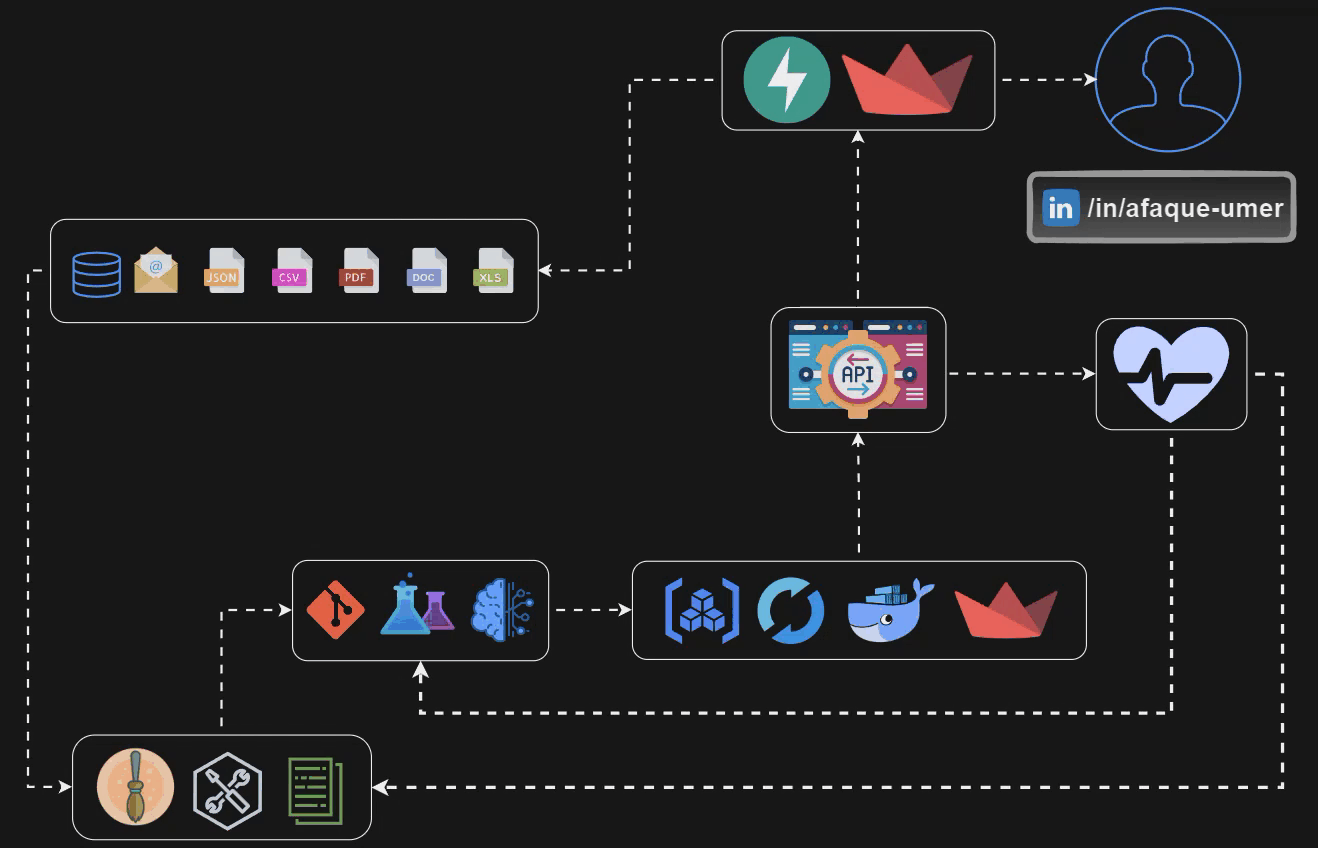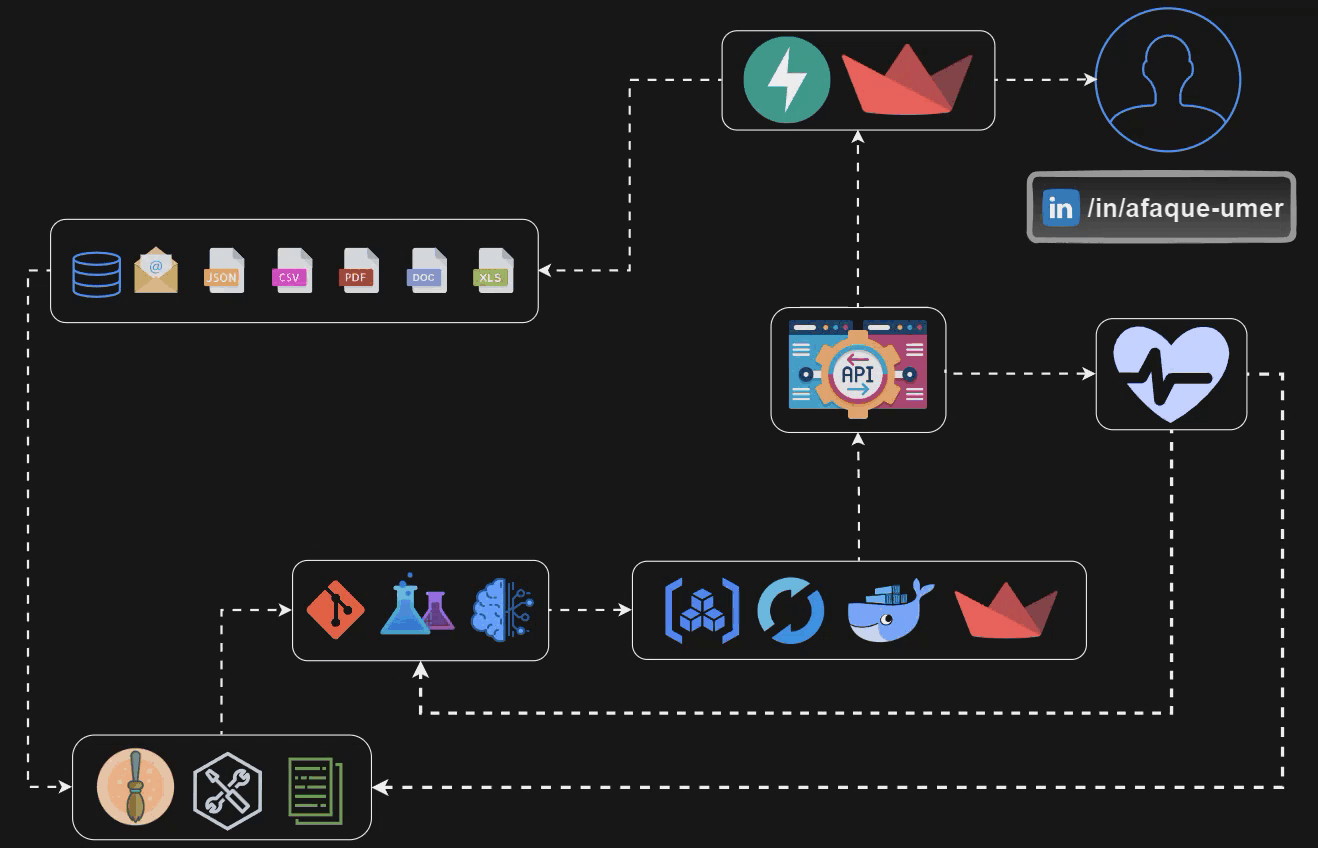
Echemos un vistazo a la tubería que vamos a construir al final de este blog 👆
- Langchain 101 Extraer datos estructurados (JSON)
- VoAGI Noticias, 9 de agosto Olvídate de ChatGPT, este nuevo asistente de IA está a años luz • 7 pasos para dominar las técnicas de limpieza y preprocesamiento de datos
- Conoce a MetaGPT El marco de inteligencia artificial de código abierto que transforma a los GPT en ingenieros, arquitectos y gerentes.
¡Agárrate fuerte, porque esto no será una lectura rápida! porque condensarlo significaría perder detalles esenciales. Estamos creando una solución de MLOps de principio a fin, y para mantenerlo real, tuve que dividirlo en tres secciones. Sin embargo, debido a ciertas pautas de publicación, tendré que dividirlo en una serie de 2 publicaciones de blog.
Sección 1: Estableceremos los fundamentos y teorías 📜
Sección 2: ¡Ahí es donde está la acción! Estamos construyendo un filtro de spam y rastreando todos esos experimentos locos con MLflow 🥼🧪
Sección 3: Nos enfocaremos en lo real: implementar y monitorear nuestro modelo campeón, haciéndolo listo para producción 🚀
¡Vamos a rockear con MLOps!
Sección 1: Los fundamentos 🌱
¿Qué es MLOps ❔
MLOps representa una colección de metodologías y mejores prácticas de la industria destinadas a ayudar a los científicos de datos a simplificar y automatizar todo el ciclo de vida de entrenamiento, implementación y gestión de modelos dentro de un entorno de producción a gran escala.
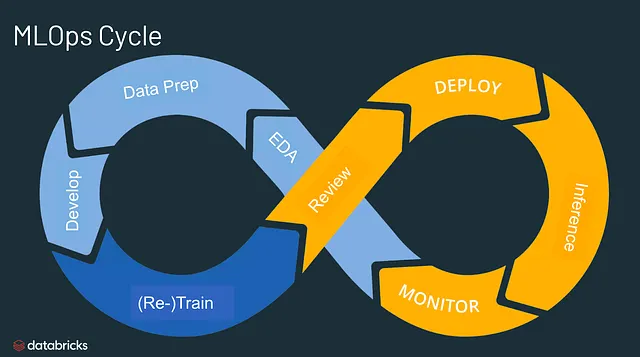
Gradualmente está emergiendo como un enfoque distintivo e independiente para gestionar todo el ciclo de vida del aprendizaje automático. Las etapas esenciales en el proceso de MLOps incluyen las siguientes:
- Recolección de datos: Recopilación de datos relevantes de diversas fuentes para su análisis.
- Análisis de datos: Explorar y examinar los datos recopilados para obtener información.
- Transformación/Preparación de datos: Limpiar, transformar y preparar los datos para el entrenamiento del modelo.
- Entrenamiento y desarrollo del modelo: Diseñar y desarrollar modelos de aprendizaje automático utilizando los datos preparados.
- Validación del modelo: Evaluar el rendimiento del modelo y garantizar su precisión.
- Servicio del modelo: Implementar el modelo entrenado para ofrecer predicciones del mundo real.
- Monitoreo del modelo: Monitorear continuamente el rendimiento del modelo en producción para mantener su eficacia.
- Reentrenamiento del modelo: Reentrenar periódicamente el modelo con nuevos datos para mantenerlo actualizado y preciso.
¿Cómo lo vamos a implementar? Aunque hay varias opciones disponibles como Neptune, Comet y Kubeflow, etc., nos quedaremos con MLflow. Así que vamos a familiarizarnos con MLflow y sumergirnos en sus principios.
MLflow 101
MLflow es como la navaja suiza del aprendizaje automático: es muy versátil y de código abierto, lo que te ayuda a gestionar todo tu viaje de aprendizaje automático como un jefe. Se lleva bien con todas las bibliotecas de aprendizaje automático más importantes (TensorFlow, PyTorch, Scikit-learn, spaCy, Fastai, Statsmodels, etc.). Aun así, también puedes usarlo con cualquier otra biblioteca, algoritmo o herramienta de implementación que prefieras. Además, está diseñado para ser muy personalizable: puedes agregar fácilmente nuevos flujos de trabajo, bibliotecas y herramientas utilizando complementos personalizados.

MLflow sigue una filosofía de diseño modular y basada en API, dividiendo su funcionalidad en cuatro partes distintas.

¡Ahora, veamos cada una de estas partes una por una!
MLflow Tracking:Es una API y una interfaz de usuario que te permite registrar parámetros, versiones de código, métricas y artefactos durante tus ejecuciones de aprendizaje automático y visualizar los resultados más tarde. Funciona en cualquier entorno, lo que te permite registrar en archivos locales o en un servidor y comparar varias ejecuciones. Los equipos también pueden utilizarlo para comparar resultados de diferentes usuarios.Proyectos de MLflow:Es una forma de empaquetar y reutilizar fácilmente código de ciencia de datos. Cada proyecto es un directorio con código o un repositorio de Git y un archivo de descripción para especificar dependencias e instrucciones de ejecución. MLflow hace un seguimiento automático de la versión y los parámetros del proyecto cuando utilizas la API de seguimiento, lo que facilita la ejecución de proyectos desde GitHub o tu repositorio de Git y encadenarlos en flujos de trabajo de varios pasos.Modelos de MLflow:Te permite empaquetar modelos de aprendizaje automático en diferentes sabores y ofrece diversas herramientas para la implementación. Cada modelo se guarda como un directorio con un archivo de descripción que enumera sus sabores admitidos. MLflow proporciona herramientas para implementar tipos comunes de modelos en diversas plataformas, como servidores REST basados en Docker, Azure ML, AWS SageMaker y Apache Spark para inferencia por lotes y en streaming. Cuando produces Modelos de MLflow utilizando la API de seguimiento, MLflow realiza un seguimiento automático de su origen, incluido el Proyecto y la ejecución de la que provienen.Registro de MLflow:Es un repositorio centralizado de modelos con API e interfaz de usuario para gestionar colaborativamente todo el ciclo de vida de un Modelo de MLflow. Incluye linaje de modelos, versionado, transiciones de etapa y anotaciones para una gestión efectiva de modelos.
Eso es todo para nuestra comprensión básica de las ofertas de MLflow. Para obtener más detalles en profundidad, consulta su documentación oficial aquí 👉📄. Ahora, armados con este conocimiento, sumerjámonos en la Sección 2. Comenzaremos creando una aplicación simple de filtrado de spam, y luego entraremos en modo de experimentación total, realizando un seguimiento de diferentes experimentos con ejecuciones únicas.
Sección 2: Experimentar 🧪 y Observar 🔍
¡Muy bien, gente, prepárense para un emocionante viaje! Antes de sumergirnos en el laboratorio y ensuciarnos las manos con experimentos, vamos a establecer nuestro plan de ataque para saber qué vamos a construir. En primer lugar, vamos a crear un clasificador de spam utilizando el clasificador de bosques aleatorios (sé que Multinomial NB funciona mejor para la clasificación de documentos, pero hey, queremos jugar con los hiperparámetros de bosques aleatorios). Al principio, lo haremos a propósito no tan bueno, solo por la emoción. Luego, desataremos nuestra creatividad y realizaremos un seguimiento de varias ejecuciones, ajustando los hiperparámetros y experimentando con cosas geniales como Bag of Words y Tfidf. ¿Y sabes qué? Utilizaremos la interfaz de usuario de MLflow como unos jefes para todas esas dulces acciones de seguimiento y nos prepararemos para la siguiente sección. ¡Así que abróchense los cinturones, porque nos vamos a divertir! 🧪💥
Convertirse en uno con los datos 🗃️
Para esta tarea, utilizaremos el conjunto de datos de Spam Collection disponible en Kaggle. Este conjunto de datos contiene 5,574 mensajes SMS en inglés, etiquetados como ham (legítimo) o spam. Sin embargo, hay un desequilibrio en el conjunto de datos, con alrededor de 4,825 etiquetas ham. Para evitar desviaciones y mantener las cosas concisas, decidí eliminar algunas muestras ham, reduciéndolas a alrededor de 3,000, y guardé el archivo CSV resultante para su uso posterior en nuestro modelo y preprocesamiento de texto. Siéntete libre de elegir tu enfoque según tus necesidades, esto fue solo para ser breve. Aquí tienes el fragmento de código que muestra cómo logré esto.
Construyendo un Clasificador Básico de Spam 🤖
Ahora que tenemos los datos listos para usar, construyamos rápidamente un clasificador básico. No te aburriré con el viejo cliché de que las computadoras no pueden entender el lenguaje del texto, por lo tanto, necesitamos vectorizarlo para representarlo. Una vez hecho esto, podemos alimentarlo a algoritmos de ML/DL y no te diré si necesitas un repaso o tienes alguna duda, no te preocupes, te tengo cubierto en uno de mis blogs anteriores para que puedas consultarlo. ¿Ya lo sabías, verdad? 🤗
Dominando los Modelos de Regresión: Una Guía Integral para el Análisis Predictivo
Introducción
levelup.gitconnected.com
¡Bien, vamos al grano! Cargaremos los datos y preprocesaremos los mensajes para eliminar palabras vacías, puntuaciones y más. Incluso los estemizaremos o lematizaremos por si acaso. Luego viene la parte emocionante: vectorizar los datos para obtener características increíbles con las que trabajar. A continuación, dividiremos los datos para entrenamiento y prueba, los ajustaremos al clasificador de bosques aleatorios y realizaremos esas jugosas predicciones en el conjunto de prueba. ¡Finalmente, es hora de evaluar para ver qué tan bien se desempeña nuestro modelo! ¡Vamos a ponerlo en práctica! ⚡
En este código, he proporcionado varias opciones para experimentar como comentarios, como el preprocesamiento con o sin palabras vacías, lematización, estemización, etc. De manera similar, para la vectorización, puedes elegir entre Bolsa de palabras, TF-IDF o embeddings. ¡Ahora, vamos a la parte divertida! Entrenaremos nuestro primer modelo llamando a estas funciones secuencialmente y pasando hiperparámetros.
Sí, estoy de acuerdo, este modelo es prácticamente inútil. La precisión es casi cero, lo que conduce a un puntaje F1 cercano a 0 también. Dado que tenemos un ligero desequilibrio de clases, el puntaje F1 se vuelve más crucial que la precisión, ya que proporciona una medida general de precisión y recall. ¡Esa es su magia! Así que aquí lo tenemos: nuestro primer modelo terrible, sin sentido e inútil. Pero hey, no te preocupes, ¡todo forma parte del proceso de aprendizaje! 🪜
Ahora, encendamos MLflow y prepárate para experimentar con diferentes opciones e hiperparámetros. Una vez que ajustemos las cosas, todo comenzará a tener sentido. ¡Podremos visualizar y analizar nuestro progreso como profesionales!
Comenzando con MLflow ♾️
Lo primero es lo primero, pongamos en marcha MLflow. Para mantener las cosas ordenadas, se recomienda configurar un entorno virtual. Simplemente puedes instalar MLflow usando pip 👉pip install mlflow
Una vez instalado, inicia la interfaz de usuario de MLflow ejecutando 👉mlflow ui en la terminal (asegúrate de estar dentro del entorno virtual donde instalaste MLflow). Esto lanzará el servidor de MLflow en tu navegador local alojado en http://localhost:5000. Verás una página similar a 👇

Dado que aún no hemos registrado nada, no habrá mucho que verificar en la interfaz de usuario. MLflow ofrece varias opciones de seguimiento, como local, local con una base de datos, en un servidor o incluso en la nube. Para este proyecto, nos quedaremos con todo local por ahora. Una vez que nos familiaricemos con la configuración local, más adelante se puede pasar la URI del servidor de seguimiento y configurar algunos parámetros, los principios subyacentes siguen siendo los mismos.
Ahora, sumerjámonos en la parte divertida: almacenar métricas, parámetros e incluso modelos, visualizaciones u otros objetos, también conocidos como artefactos.
La funcionalidad de seguimiento de MLflow se puede ver como una evolución o reemplazo del registro tradicional en el contexto del desarrollo de aprendizaje automático. En el registro tradicional, normalmente se utiliza el formato de cadena personalizado para registrar información como hiperparámetros, métricas y otros detalles relevantes durante el entrenamiento y la evaluación del modelo. Este enfoque de registro puede volverse tedioso y propenso a errores, especialmente al tratar con un gran número de experimentos o tuberías de aprendizaje automático complejas, mientras que MLflow automatiza el proceso de registro y organización de esta información, facilitando su gestión y comparación de experimentos, lo que conduce a flujos de trabajo de aprendizaje automático más eficientes y reproducibles.
Seguimiento de MLflow 📈
El seguimiento de MLflow se centra en tres funciones principales: log_param para registrar parámetros, log_metric para registrar métricas y log_artifact para registrar artefactos (por ejemplo, archivos de modelo o visualizaciones). Estas funciones facilitan el seguimiento organizado y estandarizado de datos relacionados con el experimento durante el proceso de desarrollo de aprendizaje automático.
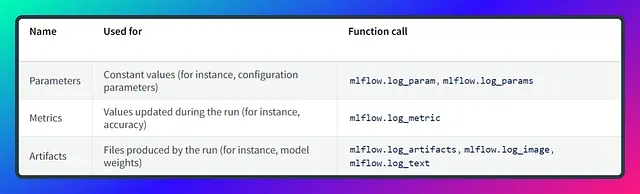
Cuando se registra un solo parámetro, se registra utilizando un par clave-valor dentro de una tupla. Por otro lado, al tratar con múltiples parámetros, se utilizaría un diccionario con pares clave-valor. El mismo concepto se aplica al registro de métricas. Aquí tienes un fragmento de código para ilustrar el proceso.
# Registrar un parámetro (par clave-valor)log_param("valor_config", randint(0, 100))# Registrar un diccionario de parámetroslog_params({"param1": randint(0, 100), "param2": randint(0, 100)})Comprender el experimento 🧪 vs las ejecuciones 🏃♀️
Un experimento actúa como un contenedor que representa un grupo de ejecuciones de aprendizaje automático relacionadas, proporcionando una agrupación lógica para las ejecuciones con un objetivo compartido. Cada experimento tiene un ID de experimento único y se puede asignar un nombre amigable para facilitar su identificación.
Por otro lado, una ejecución corresponde a la ejecución de tu código de aprendizaje automático dentro de un experimento. Puedes tener múltiples ejecuciones con diferentes configuraciones dentro de un solo experimento, y a cada ejecución se le asigna un ID de ejecución único. La información de seguimiento, que incluye parámetros, métricas y artefactos, se almacena en un almacén de backend, como un sistema de archivos local, una base de datos (por ejemplo, SQLite o MySQL) o un almacenamiento en la nube remota (por ejemplo, AWS S3 o Azure Blob Storage).
MLflow ofrece una API unificada para registrar y realizar un seguimiento de estos detalles del experimento, independientemente del almacén de backend que se utilice. Este enfoque simplificado permite recuperar y comparar los resultados del experimento sin esfuerzo, mejorando la transparencia y la capacidad de gestión del proceso de desarrollo de aprendizaje automático.
Para empezar, puedes crear un experimento utilizando mlflow.create_experiment() o un método más sencillo, mlflow.set_experiment("nombre_del_experimento"). Si se proporciona un nombre, se utilizará el experimento existente; de lo contrario, se creará uno nuevo para registrar las ejecuciones.
A continuación, llama a mlflow.start_run() para inicializar la ejecución activa actual y comenzar el registro. Después de registrar la información necesaria, cierra la ejecución utilizando mlflow.end_run().
Aquí tienes un fragmento básico que ilustra el proceso:
import mlflow# Crear un experimento (o utilizar uno existente)mlflow.set_experiment("nombre_del_experimento")# Iniciar la ejecución y comenzar el registrowith mlflow.start_run(): # Registrar parámetros, métricas y artefactos aquí mlflow.log_param("nombre_parametro", valor_parametro) mlflow.log_metric("nombre_metrica", valor_metrica) mlflow.log_artifact("ruta_al_artefacto")# La ejecución se cierra automáticamente al final del bloque 'with'Creando una interfaz de usuario para la sintonización de hiperparámetros utilizando Streamlit🔥
En lugar de ejecutar scripts a través de la línea de comandos y proporcionar parámetros allí, optaremos por un enfoque más amigable para el usuario. Construyamos una interfaz de usuario básica que permita a los usuarios ingresar tanto el nombre del experimento como valores de hiperparámetros específicos. Cuando se haga clic en el botón de entrenamiento, se invocará la función de entrenamiento con los inputs especificados. Además, exploraremos cómo hacer consultas de experimentos y ejecuciones una vez que tengamos un número considerable de ejecuciones guardadas.
Con esta interfaz de usuario interactiva, los usuarios pueden experimentar sin esfuerzo con diferentes configuraciones y realizar un seguimiento de sus ejecuciones para un desarrollo de aprendizaje automático más eficiente. No entraré en detalles específicos sobre Streamlit, ya que el código es sencillo. He realizado ajustes menores a la función de entrenamiento anterior para el registro de MLflow, así como la implementación de ajustes de tema personalizados. Antes de ejecutar un experimento, se solicita a los usuarios que elijan entre ingresar un nuevo nombre de experimento (que registra las ejecuciones en ese experimento) o seleccionar un experimento existente del menú desplegable, generado mediante mlflow.search_experiments(). Además, los usuarios pueden ajustar fácilmente los hiperparámetros según sea necesario. Aquí está el código de la aplicación 👇
y aquí es cómo se verá la aplicación 🚀
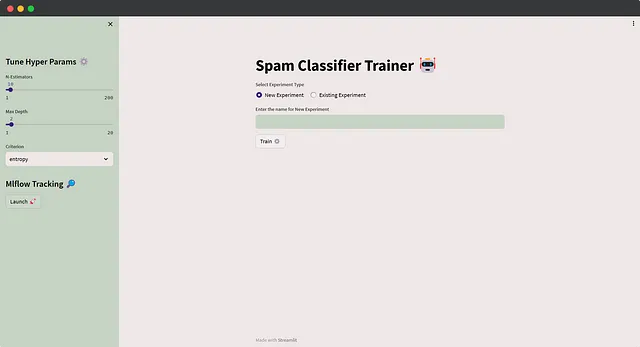
De acuerdo, es hora de una despedida temporal 👋, pero no te preocupes, nos reuniremos en la próxima entrega de esta serie de blogs 🤝. En la próxima parte, nos sumergiremos de lleno en los experimentos y pondremos a nuestros modelos en una pelea enjaulada y solo los mejores prosperarán en el Coliseo del seguimiento de MLflow 🦾. Una vez que estés en el ritmo, no querrás detenerte, así que toma una taza de café 🍵, recárgate 🔋 y únete a nosotros para el próximo capítulo emocionante ⚡. Aquí está el enlace a la Parte 02 👇
VoAGI
Editar descripción
pub.towardsai.net
¡Nos vemos allí 👀
Gracias por leer 🙏 ¡Sigue rockeando 🤘 Sigue aprendiendo 🧠 Sigue compartiendo 🤝 y sobre todo sigue experimentando! 🧪🔥✨😆
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Ajusta ChatGPT a tus necesidades con instrucciones personalizadas
- Desvelando GPTBot La audaz movida de OpenAI para rastrear la web
- ¿SE HA VUELTO LA IA DEMASIADO HUMANA? Investigadores de Google AI descubren que los LLM ahora pueden utilizar modelos de ML y APIs solo con la documentación de la herramienta.
- Investigadores de UCLA presentan GedankenNet un modelo de IA auto-supervisado que aprende a partir de leyes de la física y experimentos mentales, avanzando en la imagen computacional.
- Desplegando modelos de Hugging Face con BentoML DeepFloyd IF en acción
- Aumente el rendimiento de latencia y rendimiento de Llama 2 hasta 4 veces
- Ingenieros de Aprendizaje Automático ¿Qué hacen en realidad?






