Evaluando la síntesis del habla en varios idiomas con SQuId
Evaluating speech synthesis in multiple languages with SQuId.
Publicado por Thibault Sellam, científico investigador de Google
Anteriormente, presentamos la iniciativa de las 1,000 lenguas y el Modelo Universal de Habla con el objetivo de hacer que las tecnologías de habla y lenguaje estén disponibles para miles de millones de usuarios en todo el mundo. Parte de este compromiso implica el desarrollo de tecnologías de síntesis de voz de alta calidad, que se basan en proyectos como VDTTS y AudioLM, para usuarios que hablan muchos idiomas diferentes.
 |
Después de desarrollar un nuevo modelo, es necesario evaluar si el habla que genera es precisa y natural: el contenido debe ser relevante para la tarea, la pronunciación correcta, el tono apropiado y no debe haber artefactos acústicos como grietas o ruido correlacionado con la señal. Tal evaluación es un gran obstáculo en el desarrollo de sistemas de habla multilingüe.
El método más popular para evaluar la calidad de los modelos de síntesis de voz es la evaluación humana: un ingeniero de texto a voz (TTS) produce unas pocas mil frases del último modelo, las envía para su evaluación humana y recibe los resultados algunos días más tarde. Esta fase de evaluación típicamente involucra pruebas de escucha, durante las cuales docenas de anotadores escuchan las frases una tras otra para determinar qué tan naturales suenan. Aunque los humanos aún son imbatibles para detectar si un texto suena natural, este proceso puede ser impráctico, especialmente en las primeras etapas de los proyectos de investigación, cuando los ingenieros necesitan retroalimentación rápida para probar y replantear su enfoque. La evaluación humana es costosa, consume tiempo y puede estar limitada por la disponibilidad de calificadores para los idiomas de interés.
Otro obstáculo para el progreso es que diferentes proyectos e instituciones típicamente utilizan varias calificaciones, plataformas y protocolos, lo que hace que las comparaciones equitativas sean imposibles. En este sentido, las tecnologías de síntesis de voz se quedan atrás de la generación de texto, donde los investigadores han complementado la evaluación humana con métricas automáticas como BLEU o, más recientemente, BLEURT.
En “SQuId: Medición de la naturalidad del habla en muchos idiomas”, que se presentará en ICASSP 2023, presentamos SQuId (Identificación de calidad de habla), un modelo de regresión de 600M de parámetros que describe en qué medida un fragmento de habla suena natural. SQuId se basa en mSLAM (un modelo de habla-texto pre-entrenado desarrollado por Google), afinado en más de un millón de calificaciones de calidad en 42 idiomas y probado en 65. Demostramos cómo SQuId puede usarse para complementar las calificaciones humanas para la evaluación de muchos idiomas. Este es el esfuerzo publicado más grande de este tipo hasta la fecha.
Evaluación de TTS con SQuId
La hipótesis principal detrás de SQuId es que el entrenamiento de un modelo de regresión en calificaciones recopiladas previamente puede proporcionarnos un método de bajo costo para evaluar la calidad de un modelo TTS. El modelo puede ser una adición valiosa al conjunto de herramientas de evaluación de un investigador TTS, proporcionando una alternativa casi instantánea, aunque menos precisa, a la evaluación humana.
SQuId toma una frase como entrada y una etiqueta de localización opcional (es decir, una variante localizada de un idioma, como “portugués brasileño” o “inglés británico”). Devuelve una puntuación entre 1 y 5 que indica qué tan natural suena la forma de onda, siendo un valor más alto indicativo de una forma de onda más natural.
Internamente, el modelo incluye tres componentes: (1) un codificador, (2) una capa de agregación / regresión y (3) una capa completamente conectada. Primero, el codificador toma un espectrograma como entrada e incrusta en una matriz 2D más pequeña que contiene 3,200 vectores de tamaño 1,024, donde cada vector codifica un paso de tiempo. La capa de agregación / regresión agrega los vectores, agrega la etiqueta de localización y alimenta el resultado en una capa completamente conectada que devuelve una puntuación. Finalmente, aplicamos un post-procesamiento específico de la aplicación que reescala o normaliza la puntuación para que esté dentro del rango [1, 5], que es común para las calificaciones de naturalidad humana. Entrenamos todo el modelo de extremo a extremo con una pérdida de regresión.
El codificador es, con mucho, la pieza más grande e importante del modelo. Utilizamos mSLAM, un Conformer pre-entrenado existente de 600 millones de parámetros en el habla (51 idiomas) y el texto (101 idiomas).
 |
| El modelo SQuId. |
Para entrenar y evaluar el modelo, creamos el corpus SQuId: una colección de 1.9 millones de enunciados clasificados en 66 idiomas, recolectados para más de 2,000 proyectos de investigación y productos TTS. El corpus SQuId cubre una amplia variedad de sistemas, incluyendo modelos concatenativos y neuronales, para una amplia gama de casos de uso, como direcciones de conducción y asistentes virtuales. La inspección manual revela que SQuId está expuesto a una amplia gama de errores de TTS, como artefactos acústicos (por ejemplo, grietas y pops), prosodia incorrecta (por ejemplo, preguntas sin entonaciones ascendentes en inglés), errores de normalización de texto (por ejemplo, verbalizar “7/7” como “siete dividido por siete” en lugar de “siete de julio”) o errores de pronunciación (por ejemplo, verbalizar “tough” como “toe”).
Un problema común que surge al entrenar sistemas multilingües es que los datos de entrenamiento pueden no estar disponibles uniformemente para todos los idiomas de interés. SQuId no fue una excepción. La siguiente figura ilustra el tamaño del corpus para cada localización. Vemos que la distribución está dominada en gran medida por el inglés estadounidense.
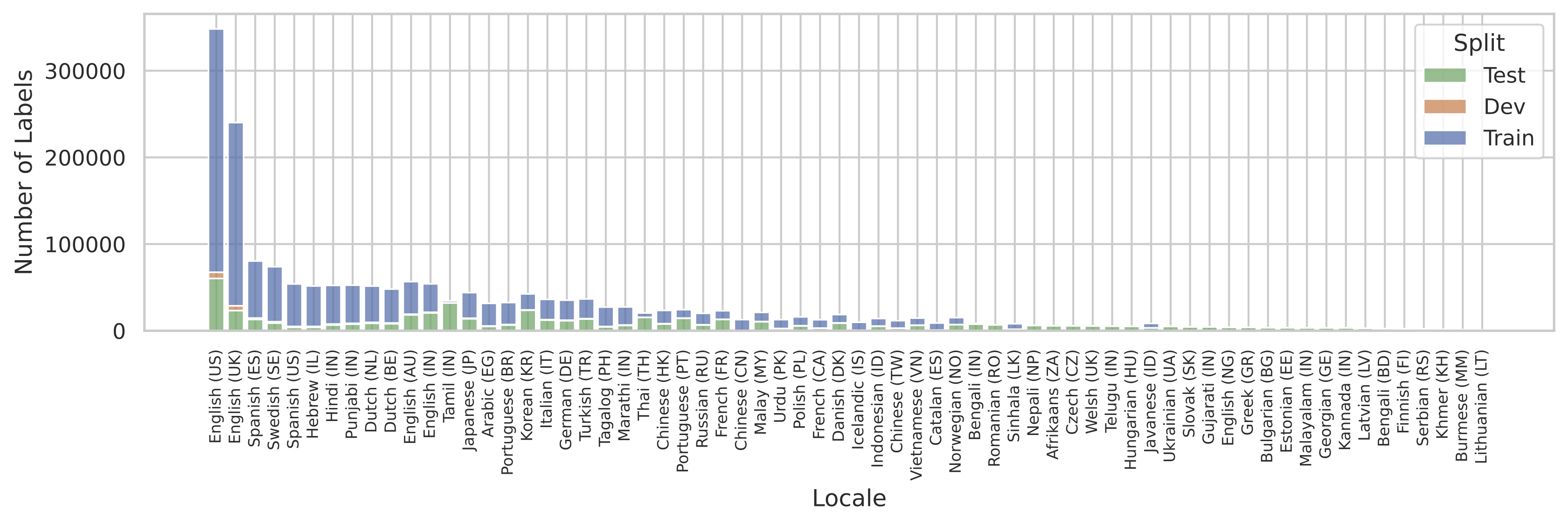 |
| Distribución local en el conjunto de datos SQuId. |
¿Cómo podemos proporcionar un buen rendimiento para todos los idiomas cuando hay tales variaciones? Inspirados por trabajos anteriores sobre traducción automática, así como por trabajos anteriores de la literatura del habla, decidimos entrenar un modelo para todos los idiomas, en lugar de usar modelos separados para cada idioma. La hipótesis es que si el modelo es lo suficientemente grande, entonces puede ocurrir una transferencia entre localizaciones: la precisión del modelo en cada localización mejora como resultado del entrenamiento conjunto en las otras. Como muestran nuestros experimentos, la transferencia entre localizaciones resulta ser un impulsor poderoso del rendimiento.
Resultados experimentales
Para comprender el rendimiento general de SQuId, lo comparamos con un modelo personalizado Big-SSL-MOS (descrito en el documento), una línea de base competitiva inspirada en MOS-SSL, un sistema de evaluación TTS de vanguardia. Big-SSL-MOS se basa en w2v-BERT y se entrenó en el conjunto de datos VoiceMOS’22 Challenge, el conjunto de datos más popular en el momento de la evaluación. Experimentamos con varias variantes del modelo y descubrimos que SQuId es hasta un 50.0% más preciso.
 |
| SQuId versus líneas de base de vanguardia. Medimos el acuerdo con las calificaciones humanas utilizando Kendall Tau, donde un valor más alto representa una mayor precisión. |
Para entender el impacto de la transferencia entre locales, realizamos una serie de estudios de ablación. Variamos la cantidad de locales introducidos en el conjunto de entrenamiento y medimos el efecto en la precisión de SQuId. En inglés, que ya está sobre-representado en el conjunto de datos, el efecto de agregar locales es insignificante.
 |
| Rendimiento de SQuId en inglés estadounidense, utilizando 1, 8 y 42 locales durante el ajuste fino. |
Sin embargo, la transferencia entre locales es mucho más efectiva para la mayoría de los demás locales:
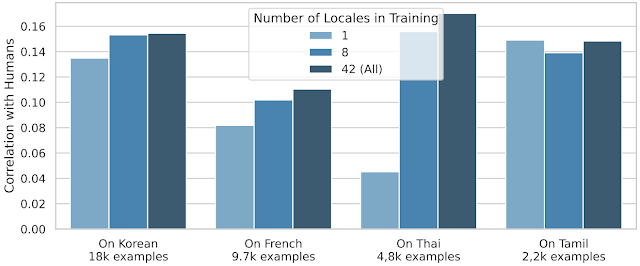 |
| Rendimiento de SQuId en cuatro locales seleccionados (coreano, francés, tailandés y tamil), utilizando 1, 8 y 42 locales durante el ajuste fino. Para cada local, también proporcionamos el tamaño del conjunto de entrenamiento. |
Para llevar la transferencia al límite, dejamos fuera 24 locales durante el entrenamiento y los usamos exclusivamente para la prueba. De esta manera, medimos en qué medida SQuId puede lidiar con idiomas que nunca ha visto antes. La gráfica a continuación muestra que aunque el efecto no es uniforme, la transferencia entre locales funciona.
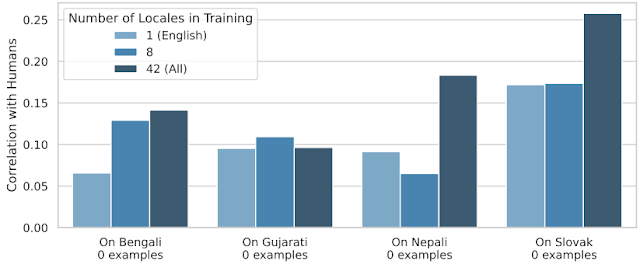 |
| Rendimiento de SQuId en cuatro locales “sin datos”; utilizando 1, 8 y 42 locales durante el ajuste fino. |
¿Cuándo y cómo se produce la transferencia entre locales? Presentamos muchas más ablaciones en el artículo y mostramos que si bien la similitud lingüística juega un papel (por ejemplo, entrenar en portugués brasileño ayuda al portugués europeo), sorprendentemente está lejos de ser el único factor que importa.
Conclusión y trabajo futuro
Presentamos SQuId, un modelo de regresión de 600 millones de parámetros que aprovecha el conjunto de datos SQuId y el aprendizaje entre locales para evaluar la calidad del habla y describir lo natural que suena. Demostramos que SQuId puede complementar a los evaluadores humanos en la evaluación de muchos idiomas. El trabajo futuro incluye mejoras en la precisión, la ampliación de la gama de idiomas cubiertos y abordar nuevos tipos de errores.
Agradecimientos
El autor de esta publicación ahora forma parte de Google DeepMind. Muchas gracias a todos los autores del artículo: Ankur Bapna, Joshua Camp, Diana Mackinnon, Ankur P. Parikh y Jason Riesa.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful





