Estadísticas en Ciencia de Datos Teoría y Visión General
Estadísticas en Ciencia de Datos

¿Estás interesado en dominar las estadísticas para destacarte en una entrevista de ciencia de datos? Si es así, no deberías hacerlo solo para la entrevista. Entender la estadística puede ayudarte a obtener ideas más profundas y detalladas de tus datos.
En este artículo, voy a mostrar los conceptos estadísticos más importantes que debes conocer para mejorar en la resolución de problemas de ciencia de datos.
- ¿Cómo podemos mitigar el sesgo inducido por el fondo en la clasificación de imágenes de granularidad fina? Un estudio comparativo de estrategias de enmascaramiento y arquitecturas de modelos
- Investigadores de Google proponen MEMORY-VQ un nuevo enfoque de IA para reducir los requisitos de almacenamiento de los modelos de memoria aumentada sin sacrificar el rendimiento
- ¿Qué características son perjudiciales para su modelo de clasificación?
Introducción a la Estadística
Cuando piensas en estadística, ¿cuál es tu primer pensamiento? Puede que pienses en información expresada numéricamente, como frecuencias, porcentajes y promedios. Solo con ver las noticias de televisión y los periódicos, has visto datos de inflación en el mundo, el número de personas empleadas y desempleadas en tu país, los datos sobre incidentes mortales en la calle y los porcentajes de votos para cada partido político de una encuesta. Todos estos ejemplos son estadísticas.
La producción de estas estadísticas es la aplicación más evidente de una disciplina llamada estadística. La estadística es una ciencia que se ocupa de desarrollar y estudiar métodos para recopilar, interpretar y presentar datos empíricos. Además, puedes dividir el campo de la estadística en dos sectores diferentes: Estadística Descriptiva y Estadística Inferencial.
El censo anual, las distribuciones de frecuencia, los gráficos y los resúmenes numéricos forman parte de la Estadística Descriptiva. Para la Estadística Inferencial, nos referimos al conjunto de métodos que permiten generalizar resultados basados en una parte de la población, llamada Muestra.
En los proyectos de ciencia de datos, la mayoría de las veces estamos tratando con muestras. Por lo tanto, los resultados que obtenemos con modelos de aprendizaje automático son aproximados. Un modelo puede funcionar bien en esa muestra en particular, pero no significa que vaya a tener buenos resultados en una nueva muestra. Todo depende de nuestra muestra de entrenamiento, que debe ser representativa, para generalizar bien las características de la población.
EDA con gráficos y resúmenes numéricos
En el proyecto de ciencia de datos, el análisis exploratorio de datos es el paso más importante, que nos permite realizar investigaciones iniciales sobre los datos con la ayuda de estadísticas de resumen y representaciones gráficas. También nos permite descubrir patrones, detectar anomalías y verificar suposiciones. Además, ayuda a encontrar errores que puedes encontrar en los datos.
En el análisis exploratorio de datos, el centro de atención está en las variables, que pueden ser de dos tipos:
- numéricas si la variable se mide en una escala numérica. Se puede categorizar aún más en discretas y continuas. Es discreta cuando hay cantidades distintas. Ejemplos de variables discretas son la calificación de grado y el número de personas en una familia. Cuando estamos tratando con una variable continua, el conjunto de valores posibles está dentro de un intervalo finito o infinito, como la altura, el peso y la edad.
- categóricas si la variable está típicamente constituida por dos o más categorías, como el estado ocupacional (empleados, desempleados y personas que buscan trabajo) y el tipo de trabajo. Al igual que las variables numéricas, las variables categóricas se pueden dividir en dos tipos diferentes: ordinal y nominal. Una variable es ordinal cuando hay un orden natural de las categorías. Un ejemplo puede ser el salario con niveles bajos, VoAGI y altos. Cuando la variable categórica no sigue ningún orden, es nominal. Un ejemplo simple de una variable nominal es el género con niveles femenino y masculino.
EDA de Datos Univariables
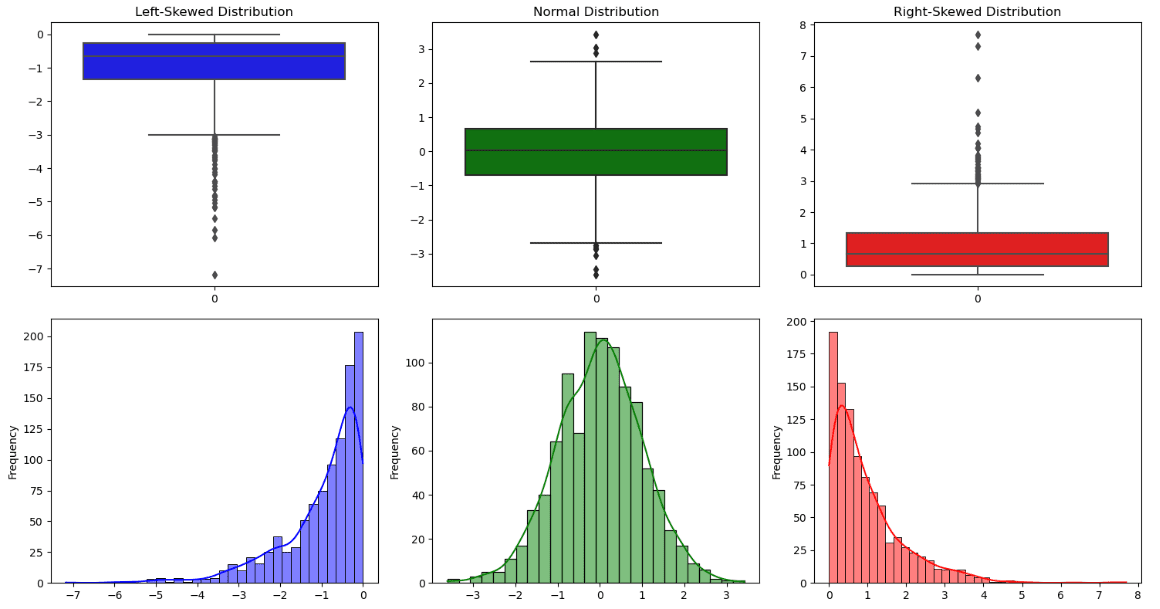
Para comprender las características numéricas, típicamente usamos df.describe() para tener una visión general de las estadísticas de cada variable. La salida contiene el recuento, el promedio, la desviación estándar, el mínimo, el máximo, la mediana, el primer y el tercer cuartil.
Toda esta información también se puede ver en una representación gráfica llamada boxplot. La línea a través de la caja es la mediana, mientras que la bisagra inferior y la bisagra superior corresponden respectivamente al primer y tercer cuartil. Además de la información proporcionada por la caja, hay dos líneas, también llamadas bigotes, que representan las dos colas de la distribución. Todos los puntos de datos fuera del límite de los bigotes son valores atípicos.
A partir de este gráfico, también es posible observar si la distribución es simétrica o asimétrica:
- Una distribución es simétrica cuando tiene una forma de campana, la mediana coincide aproximadamente con la media y las líneas de los bigotes tienen la misma longitud.
- Una distribución está sesgada hacia la derecha (sesgo positivo) si la mediana está cerca del tercer cuartil.
- Una distribución está sesgada hacia la izquierda (sesgo negativo) si la mediana está cerca del primer cuartil.
Otros aspectos importantes de la distribución se pueden visualizar a partir de un histograma que cuenta cuántos puntos de datos caen en cada intervalo. Es posible observar cuatro tipos de formas:
- un pico/moda
- dos picos/modas
- tres o más picos/modas
- uniforme sin una moda evidente
Cuando las variables son categóricas, la mejor manera es observar la tabla de frecuencias para cada factor de la característica. Para una visualización más intuitiva, podemos emplear el gráfico de barras, con barras verticales u horizontales dependiendo de la variable.
EDA de Datos Bivariados
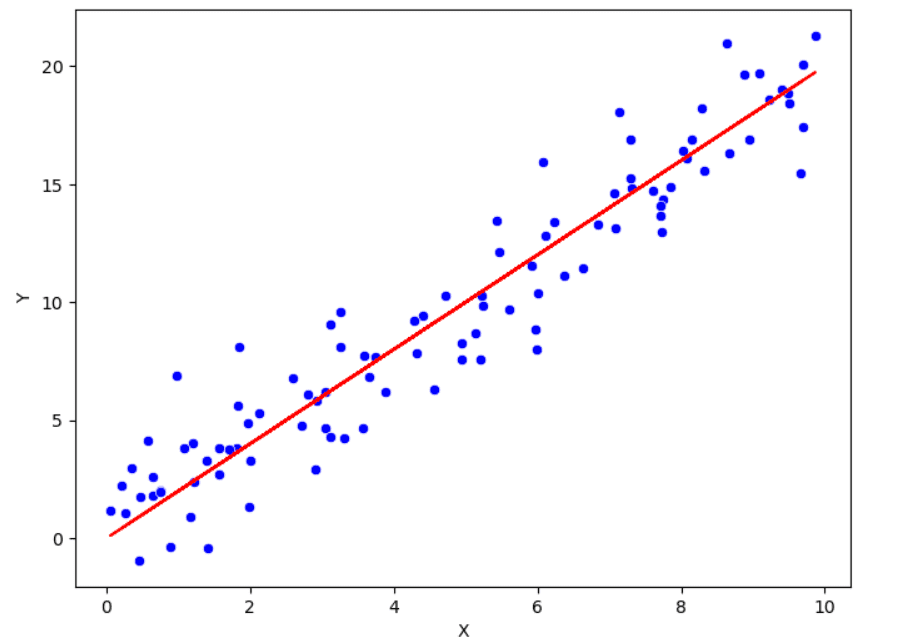
Previamente hemos enumerado los enfoques para comprender la distribución univariada. Ahora es el momento de estudiar las relaciones entre las variables. Con este propósito, es común calcular la correlación de Pearson, que es una medida de la relación lineal entre dos variables. El rango de este coeficiente de correlación está entre -1 y 1. Cuanto más cerca esté el valor de la correlación a uno de estos dos extremos, más fuerte es la relación. Si está cerca de 0, hay una relación débil entre las dos variables.
Además de la correlación, existe el diagrama de dispersión para visualizar la relación entre dos variables. En esta representación gráfica, cada punto corresponde a una observación específica. A menudo no es muy informativo cuando hay mucha variabilidad dentro de los datos. Para capturar más información del par de variables, se pueden agregar líneas suavizadas y transformar los datos.
Distribuciones de Probabilidad
El conocimiento de las distribuciones de probabilidad puede marcar la diferencia al trabajar con datos.
Estas son las distribuciones de probabilidad más utilizadas en la ciencia de datos:
- Distribución normal
- Distribución chi-cuadrado
- Distribución uniforme
- Distribución de Poisson
- Distribución exponencial
Distribución normal
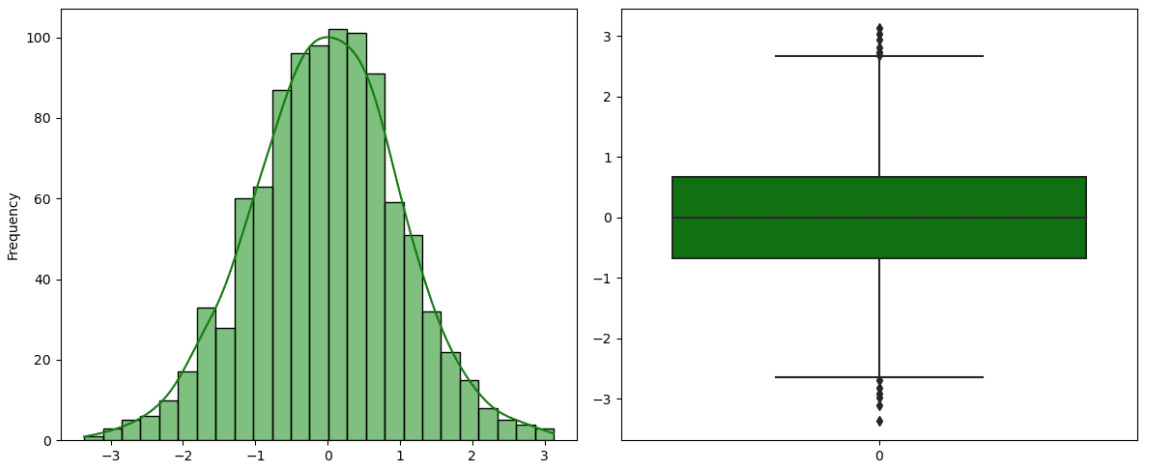
La distribución normal, también conocida como distribución gaussiana, es la distribución más popular en estadística. Se caracteriza por una curva de campana debido a su forma particular, alta en el centro y con colas hacia el final. Es simétrica y unimodal con un pico. Además, hay dos parámetros que tienen un papel crucial en la distribución normal: la media y la desviación estándar. La media coincide con el pico, mientras que la amplitud de la curva está representada por la desviación estándar. Existe un tipo particular de distribución normal llamada Distribución Normal Estándar, con media igual a 0 y varianza igual a 1. Se obtiene restando la media del valor original y, luego, dividiendo por la desviación estándar.
Distribución t de Student
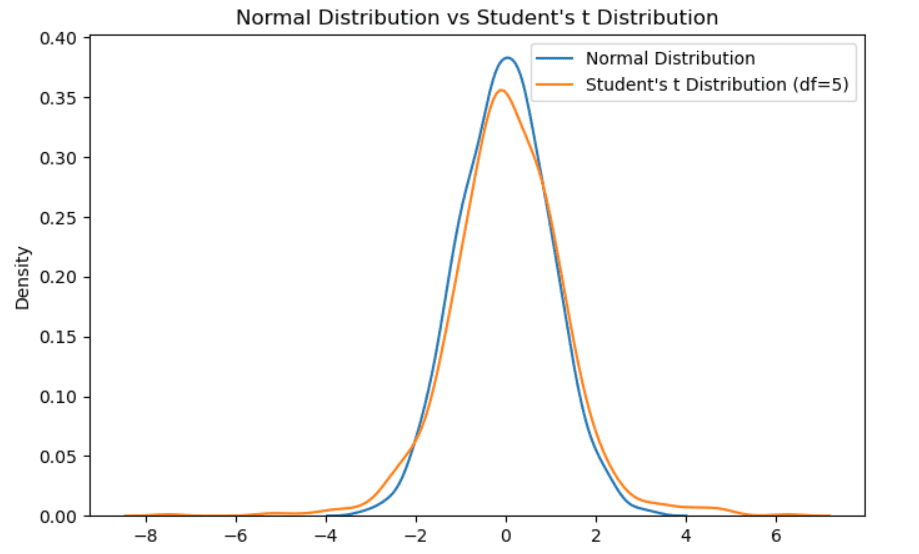
También se llama distribución t con v grados de libertad. Al igual que la distribución normal estándar, es unimodal y simétrica alrededor de cero. Difiere ligeramente de la distribución gaussiana porque tiene menos masa en el centro y hay más masas en las colas. Se considera cuando tenemos un tamaño de muestra pequeño. Cuanto más aumenta el tamaño de la muestra, más se acercará la distribución t a una distribución normal.
Distribución chi-cuadrado
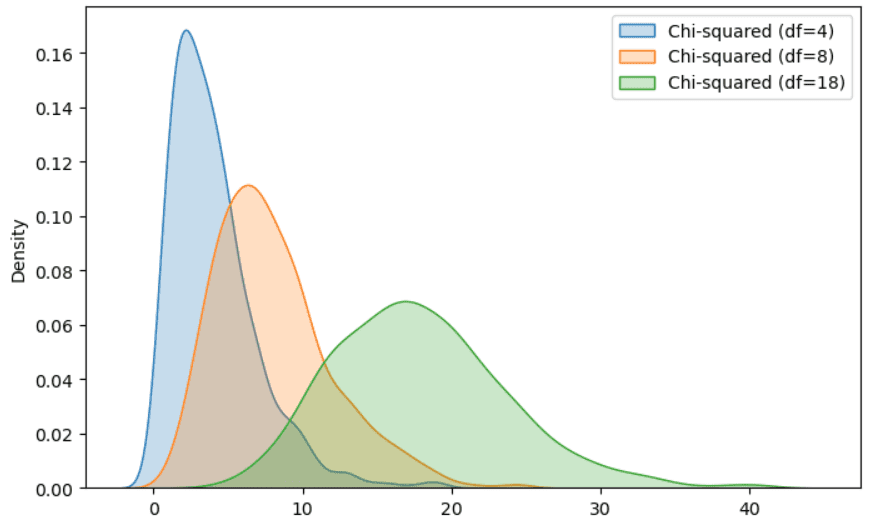
Es un caso especial de la distribución Gamma, muy conocida por sus aplicaciones en pruebas de hipótesis e intervalos de confianza. Si tenemos un conjunto de variables aleatorias independientes y distribuidas normalmente, calculamos el valor al cuadrado para cada variable aleatoria y sumamos todos los valores al cuadrado, el valor aleatorio final sigue una distribución chi-cuadrado.
Distribución uniforme
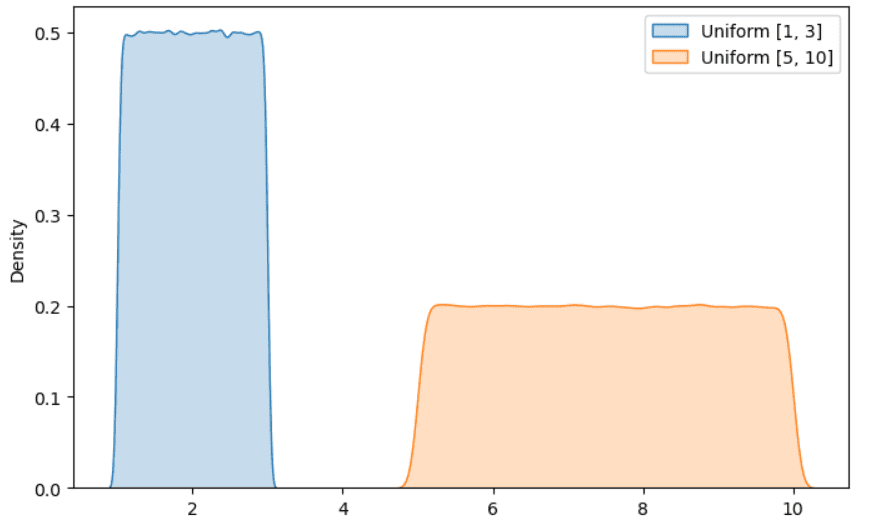
Es otra distribución popular que seguramente has encontrado al trabajar en un proyecto de ciencia de datos. La idea es que todos los resultados tienen la misma probabilidad de ocurrir. Un ejemplo popular consiste en lanzar un dado de seis caras. Como sabrás, cada cara del dado tiene la misma probabilidad de ocurrir, por lo tanto, el resultado sigue una distribución uniforme.
Distribución de Poisson
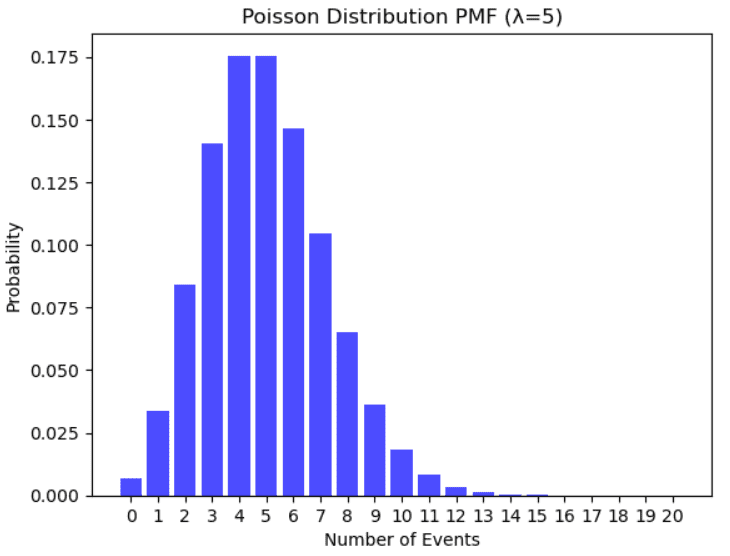 Ejemplo de distribución de Poisson. Ilustración del autor.
Ejemplo de distribución de Poisson. Ilustración del autor.
Se utiliza para modelar el número de eventos que ocurren aleatoriamente muchas veces dentro de un intervalo de tiempo específico. Ejemplos que siguen una distribución de Poisson son el número de personas en una comunidad que tienen más de 100 años, el número de fallas por día de un sistema, el número de llamadas telefónicas que llegan a la línea de ayuda en un marco de tiempo específico.
Distribución exponencial
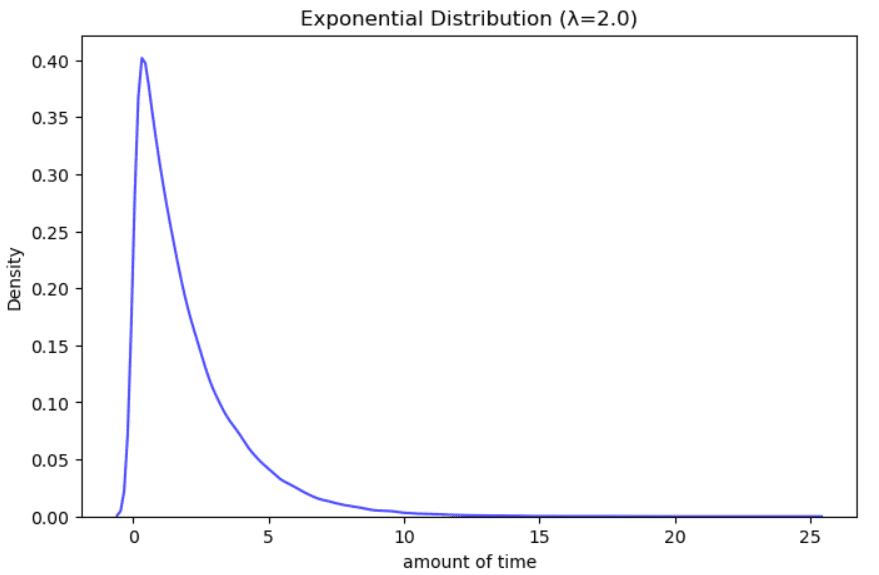 Ejemplo de distribución exponencial. Ilustración del autor.
Ejemplo de distribución exponencial. Ilustración del autor.
Se utiliza para modelar la cantidad de tiempo entre eventos que ocurren aleatoriamente muchas veces dentro de un intervalo de tiempo específico. Ejemplos pueden ser el tiempo en espera en una línea de ayuda, el tiempo hasta el próximo terremoto, los años restantes de vida para un paciente con cáncer.
Pruebas de hipótesis
Las pruebas de hipótesis son un método estadístico que permite formular y evaluar una hipótesis sobre la población basada en datos de muestra. Por lo tanto, es una forma de estadística inferencial. Este proceso comienza con una hipótesis de los parámetros de la población, también llamada hipótesis nula, que necesita ser probada, mientras que la hipótesis alternativa (H1) representa la afirmación opuesta. Si los datos son muy diferentes de las suposiciones que teníamos, entonces se rechaza la hipótesis nula (H0) y se dice que el resultado es “estadísticamente significativo”.
Una vez que se especifican las dos hipótesis, hay otros pasos a seguir:
- Establecer el nivel de significancia, que es un criterio utilizado para rechazar la hipótesis nula. Los valores típicos son 0.05 y 0.01. Este parámetro ? determina cuán fuerte es la evidencia empírica en contra de la hipótesis nula hasta que esta última sea rechazada.
- Calcular la estadística, que es la cantidad numérica calculada a partir de la muestra. Nos ayuda a determinar una regla de decisión para limitar lo más posible el riesgo de error.
- Calcular el p-valor, que es la probabilidad de obtener una estadística que sea diferente del parámetro especificado en la hipótesis nula. Si es menor o igual al nivel de significancia (por ejemplo, 0.05), rechazamos la hipótesis nula. En caso de que el p-valor sea mayor que el nivel de significancia, no podemos rechazar la hipótesis nula.
Hay una gran variedad de pruebas de hipótesis. Supongamos que estamos trabajando en un proyecto de ciencia de datos y queremos usar el modelo de regresión lineal, que se sabe que tiene fuertes suposiciones de normalidad, independencia y linealidad. Antes de aplicar el modelo estadístico, preferimos verificar la normalidad de una variable que se refiere al peso de las mujeres adultas con diabetes. El test de Shapiro-Wilk puede venir en nuestra ayuda. También existe una biblioteca de Python llamada Scipy, con la implementación de esta prueba, en la que la hipótesis nula es que la variable sigue una distribución normal. Rechazamos la hipótesis si el p-valor es menor o igual al nivel de significancia (por ejemplo, 0.05). Aceptamos la hipótesis nula, lo que significa que la variable tiene una distribución normal, si el p-valor es mayor que el nivel de significancia.
Conclusiones Finales
Espero que hayas encontrado esta introducción útil. Creo que dominar la estadística es posible si la teoría se complementa con ejemplos prácticos. Seguramente hay otros conceptos importantes de estadística que no he cubierto aquí, pero preferí centrarme en conceptos que me han resultado útiles durante mi experiencia como científico de datos. ¿Conoces otros métodos estadísticos que te hayan ayudado en tu trabajo? Déjalos en los comentarios si tienes sugerencias interesantes.
Recursos:
- Libro de texto en línea de estadística HyperStat
- Medidas de Posiciones
- Las distribuciones de probabilidad más utilizadas en la ciencia de datos
Eugenia Anello es actualmente investigadora en el Departamento de Ingeniería de la Información de la Universidad de Padua, Italia. Su proyecto de investigación se centra en el Aprendizaje Continuo combinado con la Detección de Anomalías.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Conoce T2I-Adapter-SDXL Modelos de Control Pequeños y Eficientes.
- Grandes Modelos de Lenguaje SBERT
- LLMs y Análisis de Datos Cómo la IA está dando sentido a los grandes datos para obtener información empresarial
- Ingeniería de Aprendizaje Automático en el Mundo Real
- Conoce a PhysObjects Un conjunto de datos centrado en objetos con 36.9K anotaciones físicas obtenidas de la colaboración de la multitud y 417K anotaciones físicas automáticas de objetos comunes del hogar.
- Cómo construir una estrategia de Ciencia de Datos para cualquier tamaño de equipo
- Dominio de Amazon SageMaker en modo solo VPC para admitir SageMaker Studio con configuración de ciclo de vida de apagado automático y SageMaker Canvas con Terraform





