Esta investigación de IA presenta Point-Bind un modelo de multimodalidad 3D que alinea nubes de puntos con imágenes 2D, lenguaje, audio y video
Esta investigación de IA presenta Point-Bind, un modelo 3D multimodal que alinea nubes de puntos con imágenes 2D, lenguaje, audio y video.


En el actual panorama tecnológico, la visión 3D ha emergido como una estrella en ascenso, capturando el foco de atención debido a su rápido crecimiento y evolución. Este aumento en el interés puede atribuirse en gran medida a la creciente demanda de conducción autónoma, sistemas de navegación mejorados, comprensión avanzada de escenas en 3D y el floreciente campo de la robótica. Para ampliar sus escenarios de aplicación, se han realizado numerosos esfuerzos para incorporar nubes de puntos en 3D con datos de otras modalidades, lo que permite una mejor comprensión en 3D, generación de texto a 3D y respuesta a preguntas en 3D.

Los investigadores han presentado Point-Bind, un revolucionario modelo de multimodalidad 3D diseñado para integrar sin problemas nubes de puntos con diversas fuentes de datos como imágenes 2D, lenguaje, audio y video. Guiado por los principios de ImageBind, este modelo construye un espacio de incrustación unificado que une la brecha entre los datos 3D y las multimodalidades. Este avance permite una multitud de aplicaciones emocionantes, que incluyen, entre otras, generación de cualquier modalidad a 3D, aritmética de incrustación en 3D y comprensión exhaustiva del mundo abierto en 3D.
En la imagen anterior podemos ver la tubería general de Point-Bind. Los investigadores recolectan primero pares de datos de texto-imagen-audio-texto en 3D para el aprendizaje por contraste, que alinea la modalidad 3D con las demás guiado por ImageBind. Con un espacio de incrustación conjunto, Point-Bind se puede utilizar para la recuperación cruzada modal en 3D, generación de cualquier modalidad a 3D, comprensión en 3D sin entrenamiento y desarrollo de un modelo de lenguaje en 3D a gran escala, Point-LLM.
- Los programas piloto de IA buscan reducir el consumo de energía y las emisiones en el campus del MIT
- Implementar un índice de búsqueda inteligente de documentos con Amazon Textract y Amazon OpenSearch
- Primera parte del cuerpo humano derivada 3D impresa en el espacio
Las principales contribuciones de Point Blind en este estudio incluyen:
- Alineación de 3D con ImageBind: Dentro de un espacio de incrustación conjunto, Point-Bind alinea en primer lugar nubes de puntos en 3D con multimodalidades guiadas por ImageBind, incluyendo imágenes 2D, video, lenguaje, audio, etc.
- Generación de cualquier modalidad a 3D: Basado en modelos generativos existentes de texto a 3D, Point-Bind permite la síntesis de formas en 3D condicionada a cualquier modalidad, es decir, generación de texto/imagen/audio/puntos a malla.
- Aritmética de espacio de incrustación en 3D: Observamos que las características en 3D de Point-Bind se pueden sumar con otras modalidades para incorporar su semántica, logrando una recuperación cruzada modal compuesta.
- Comprensión en 3D sin entrenamiento: Point-Bind logra un rendimiento de vanguardia en la clasificación en 3D sin entrenamiento. Además, nuestro enfoque también admite la comprensión del mundo abierto en 3D referida por audio, además de la referencia de texto.
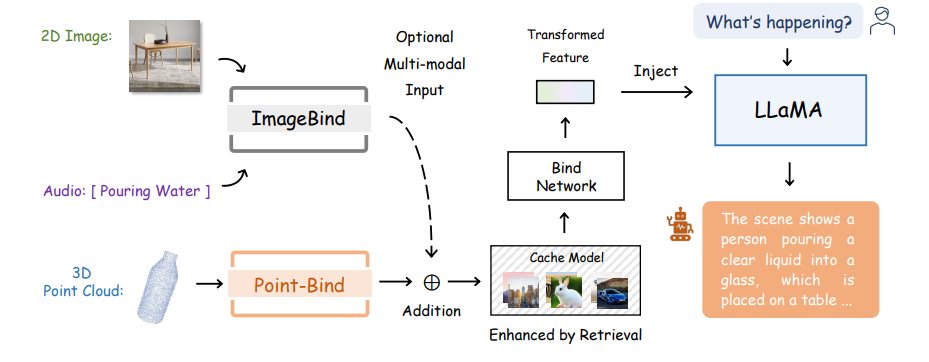
Los investigadores aprovechan Point-Bind para desarrollar modelos de lenguaje en 3D a gran escala (LLMs), denominados Point-LLM, que ajustan finamente LLaMA para lograr respuesta a preguntas en 3D y razonamiento multimodal. La tubería general de Point-LLM se puede ver en la imagen anterior.
Las principales contribuciones de Point LLM incluyen:
- Point-LLM para Preguntas y Respuestas en 3D: Utilizando PointBind, presentamos Point-LLM, el primer modelo de lenguaje y visión en 3D que responde a instrucciones con condiciones de nube de puntos en 3D, compatible tanto con inglés como con chino.
- Eficiencia de Datos y Parámetros: Utilizamos únicamente datos públicos de visión y lenguaje para ajuste sin ningún dato de instrucción en 3D, y adoptamos técnicas de ajuste de parámetros eficientes, ahorrando recursos extensos.
- Razonamiento en 3D y Multimodal: A través del espacio de incrustación conjunta, Point-LLM puede generar respuestas descriptivas razonando una combinación de entrada 3D y multimodal, por ejemplo, una nube de puntos con una imagen/sonido.
El trabajo futuro se enfocará en alinear la multimodalidad con datos 3D más diversos, como escenas interiores y exteriores, lo cual permitirá una aplicación más amplia de escenarios.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Mejores prácticas de automatización de pruebas
- Cómo optimizar conjuntos de características con algoritmos genéticos
- Cómo la plataforma de VAST Data está eliminando las barreras a la innovación en IA
- DeepFace para reconocimiento facial avanzado
- El problema de los dos sobres
- Introducción a las bases de datos en la ciencia de datos
- ¿Cómo construir LLMs para código?





