Escala el entrenamiento y la inferencia de miles de modelos de aprendizaje automático con Amazon SageMaker
Escala entrenamiento e inferencia de miles de modelos de ML con SageMaker
A medida que el aprendizaje automático (ML) se vuelve cada vez más prevalente en una amplia gama de industrias, las organizaciones encuentran la necesidad de entrenar y servir grandes cantidades de modelos de ML para satisfacer las diversas necesidades de sus clientes. Para los proveedores de software como servicio (SaaS) en particular, la capacidad de entrenar y servir miles de modelos de manera eficiente y rentable es crucial para mantenerse competitivos en un mercado en constante evolución.
Entrenar y servir miles de modelos requiere una infraestructura sólida y escalable, y ahí es donde Amazon SageMaker puede ayudar. SageMaker es una plataforma completamente administrada que permite a los desarrolladores y científicos de datos construir, entrenar y implementar modelos de ML rápidamente, al mismo tiempo que ofrece los beneficios de ahorro de costos de utilizar la infraestructura de la nube de AWS.
En esta publicación, exploramos cómo puede utilizar las características de SageMaker, incluido el procesamiento de Amazon SageMaker, los trabajos de entrenamiento de SageMaker y los puntos finales de múltiples modelos de SageMaker (MME), para entrenar y servir miles de modelos de manera rentable. Para comenzar con la solución descrita, puede consultar el cuaderno adjunto en GitHub.
Caso de uso: Pronóstico de energía
Para esta publicación, asumimos el papel de una empresa ISV que ayuda a sus clientes a ser más sostenibles mediante el seguimiento de su consumo de energía y proporcionando pronósticos. Nuestra empresa tiene 1,000 clientes que desean comprender mejor su consumo de energía y tomar decisiones informadas sobre cómo reducir su impacto ambiental. Para hacer esto, utilizamos un conjunto de datos sintéticos y entrenamos un modelo de ML basado en Prophet para cada cliente para hacer pronósticos de consumo de energía. Con SageMaker, podemos entrenar y servir eficientemente estos 1,000 modelos, proporcionando a nuestros clientes información precisa y acciones para mejorar su consumo de energía.
- Dando a los usuarios más de lo que pueden manejar
- Píldoras de la impresora 3D
- Luchando contra los ‘hechos’ falsos con dos pequeñas palabras
Hay tres características en el conjunto de datos generado:
- customer_id: este es un identificador entero para cada cliente, que varía de 0 a 999.
- timestamp: este es un valor de fecha/hora que indica la hora en que se midió el consumo de energía. Las marcas de tiempo se generan aleatoriamente entre las fechas de inicio y finalización especificadas en el código.
- consumption: este es un valor flotante que indica el consumo de energía, medido en alguna unidad arbitraria. Los valores de consumo se generan aleatoriamente entre 0 y 1,000 con una estacionalidad sinusoidal.
Resumen de la solución
Para entrenar y servir eficientemente miles de modelos de ML, podemos utilizar las siguientes características de SageMaker:
- Procesamiento de SageMaker: el procesamiento de SageMaker es un servicio de preparación de datos completamente administrado que le permite realizar tareas de procesamiento de datos y evaluación de modelos en sus datos de entrada. Puede utilizar el procesamiento de SageMaker para transformar datos sin procesar en el formato necesario para el entrenamiento y la inferencia, así como para ejecutar evaluaciones por lotes y en línea de sus modelos.
- Trabajos de entrenamiento de SageMaker: puede utilizar los trabajos de entrenamiento de SageMaker para entrenar modelos con una variedad de algoritmos y tipos de datos de entrada, y especificar los recursos informáticos necesarios para el entrenamiento.
- MME de SageMaker: los puntos finales de múltiples modelos le permiten alojar varios modelos en un solo punto final, lo que facilita la obtención de predicciones de múltiples modelos mediante una sola API. Los MME de SageMaker pueden ahorrar tiempo y recursos al reducir el número de puntos finales necesarios para obtener predicciones de varios modelos. Los MME admiten la implementación de modelos respaldados tanto por CPU como por GPU. Tenga en cuenta que en nuestro escenario, usamos 1,000 modelos, pero esta no es una limitación del servicio en sí.
El siguiente diagrama ilustra la arquitectura de la solución.
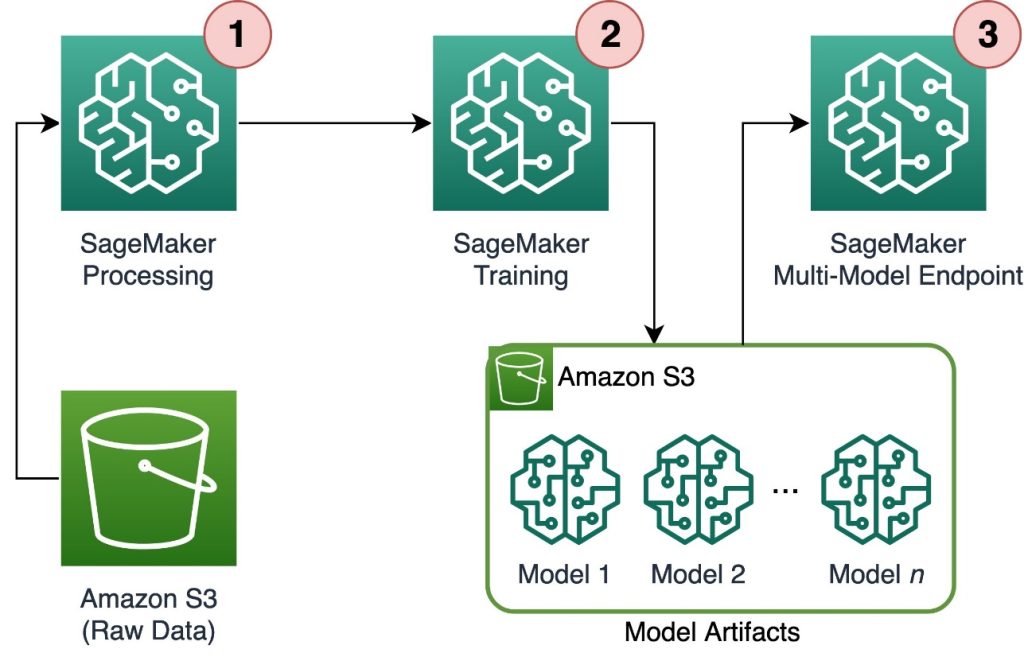
El flujo de trabajo incluye los siguientes pasos:
- Utilizamos el procesamiento de SageMaker para preprocesar los datos y crear un archivo CSV único por cliente y almacenarlo en el servicio de almacenamiento simple de Amazon (Amazon S3).
- El trabajo de entrenamiento de SageMaker está configurado para leer la salida del trabajo de procesamiento de SageMaker y distribuirla de manera circular entre las instancias de entrenamiento. Tenga en cuenta que esto también se puede lograr con Amazon SageMaker Pipelines.
- Los artefactos del modelo son almacenados en Amazon S3 por el trabajo de entrenamiento y se sirven directamente desde el MME de SageMaker.
Escalado del entrenamiento a miles de modelos
El escalado del entrenamiento de miles de modelos es posible a través del parámetro distribution de la clase TrainingInput en el SDK de Python de SageMaker, que le permite especificar cómo se distribuyen los datos en múltiples instancias de entrenamiento para un trabajo de entrenamiento. Hay tres opciones para el parámetro distribution: FullyReplicated, ShardedByS3Key y ShardedByRecord. La opción ShardedByS3Key significa que los datos de entrenamiento se dividen por clave de objeto de S3, con cada instancia de entrenamiento recibiendo un subconjunto único de los datos, evitando la duplicación. Después de que SageMaker copie los datos en los contenedores de entrenamiento, podemos leer la estructura de carpetas y archivos para entrenar un modelo único por archivo de cliente. A continuación, se muestra un ejemplo de fragmento de código:
# Suponemos que los datos de entrenamiento ya se encuentran en un bucket de S3, se pasa la carpeta principal
s3_input_train = sagemaker.inputs.TrainingInput(
s3_data='s3://mi-bucket/datos_cliente',
distribution='ShardedByS3Key'
)
# Crea un estimador de SageMaker y establece la entrada de entrenamiento
estimator = sagemaker.estimator.Estimator(...)
estimator.fit(inputs=s3_input_train)Cada trabajo de entrenamiento de SageMaker guarda el modelo guardado en la carpeta /opt/ml/model del contenedor de entrenamiento antes de archivarlo en un archivo model.tar.gz y luego carga el archivo a Amazon S3 al finalizar el trabajo de entrenamiento. Los usuarios avanzados también pueden automatizar este proceso con SageMaker Pipelines. Cuando se almacenan varios modelos mediante el mismo trabajo de entrenamiento, SageMaker crea un solo archivo model.tar.gz que contiene todos los modelos entrenados. Esto significa que, para servir el modelo, primero debemos descomprimir el archivo. Para evitar esto, usamos puntos de control para guardar el estado de los modelos individuales. SageMaker proporciona la funcionalidad para copiar los puntos de control creados durante el trabajo de entrenamiento a Amazon S3. Aquí, los puntos de control deben guardarse en una ubicación predefinida, siendo la ubicación predeterminada /opt/ml/checkpoints. Estos puntos de control se pueden utilizar para reanudar el entrenamiento en un momento posterior o como un modelo para implementar en un punto final. Para obtener un resumen general de cómo la plataforma de entrenamiento de SageMaker administra las rutas de almacenamiento para conjuntos de datos de entrenamiento, artefactos de modelos, puntos de control y salidas entre el almacenamiento en la nube de AWS y los trabajos de entrenamiento en SageMaker, consulte Carpetas de almacenamiento de entrenamiento de Amazon SageMaker para conjuntos de datos de entrenamiento, puntos de control, artefactos de modelos y salidas.
El siguiente código utiliza una función ficticia model.save() dentro del script train.py que contiene la lógica de entrenamiento:
import tarfile
import boto3
import os
[ ... argumentos de análisis ... ]
for customer in os.list_dir(args.input_path):
# Leer los datos localmente dentro del trabajo de entrenamiento
df = pd.read_csv(os.path.join(args.input_path, customer, 'data.csv'))
# Definir y entrenar el modelo
model = MyModel()
model.fit(df)
# Guardar el modelo en el directorio de salida
with open(os.path.join(output_dir, 'model.json'), 'w') as fout:
fout.write(model_to_json(model))
# Crear el archivo model.tar.gz que contiene el modelo y el script de entrenamiento
with tarfile.open(os.path.join(output_dir, '{customer}.tar.gz'), "w:gz") as tar:
tar.add(os.path.join(output_dir, 'model.json'), "model.json")
tar.add(os.path.join(args.code_dir, "training.py"), "training.py")Escalar la inferencia a miles de modelos con SageMaker MMEs
Las MMEs de SageMaker te permiten servir varios modelos al mismo tiempo creando una configuración de punto final que incluye una lista de todos los modelos a servir, y luego creando un punto final utilizando esa configuración. No es necesario volver a implementar el punto final cada vez que se agrega un nuevo modelo porque el punto final automáticamente servirá todos los modelos almacenados en las rutas de S3 especificadas. Esto se logra con Multi Model Server (MMS), un marco de código abierto para servir modelos de ML que se puede instalar en contenedores para proporcionar la interfaz que cumple con los requisitos de las nuevas API de contenedores MME. Además, puedes usar otros servidores de modelos como TorchServe y Triton. MMS se puede instalar en tu contenedor personalizado a través de la SageMaker Inference Toolkit. Para obtener más información sobre cómo configurar tu Dockerfile para incluir MMS y usarlo para servir tus modelos, consulta Crear tu propio contenedor para puntos finales multinivel de SageMaker.
El siguiente fragmento de código muestra cómo crear una MME utilizando el SDK de Python de SageMaker:
from sagemaker.multidatamodel import MultiDataModel
# Crea la definición del MultiDataModel
multimodel = MultiDataModel(
name='modelos-cliente',
model_data_prefix=f's3://{bucket}/escalando-miles-modelos/modelos',
model=your_model,
)
# Implementar en un punto final en tiempo real
predictor = multimodel.deploy(
initial_instance_count=1,
instance_type='ml.c5.xlarge',
)Cuando la MME está en funcionamiento, podemos invocarla para generar predicciones. Las invocaciones se pueden realizar en cualquier SDK de AWS, así como con el SDK de Python de SageMaker, como se muestra en el siguiente fragmento de código:
predictor.predict(
data='{"periodo": 7}', # la carga útil, en este caso JSON
target_model='{customer}.tar.gz' # el nombre del modelo objetivo
)Cuando se llama a un modelo, este se carga inicialmente desde Amazon S3 en la instancia, lo que puede resultar en un arranque en frío al llamar a un nuevo modelo. Los modelos utilizados con frecuencia se almacenan en caché en la memoria y en el disco para proporcionar inferencia de baja latencia.
Conclusión
SageMaker es una plataforma poderosa y rentable para entrenar y servir miles de modelos de ML. Sus características, incluyendo el procesamiento de SageMaker, trabajos de entrenamiento y MMEs, permiten a las organizaciones entrenar y servir eficientemente miles de modelos a escala, al mismo tiempo que se benefician de las ventajas de ahorro de costos de utilizar la infraestructura de la nube de AWS. Para obtener más información sobre cómo utilizar SageMaker para entrenar y servir miles de modelos, consulte Procesar datos, Entrenar un Modelo con Amazon SageMaker y Hospedar múltiples modelos en un contenedor detrás de un único punto de enlace.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- EE.UU. busca malware chino que podría interrumpir las operaciones militares
- Los robots submarinos podrían abrir paso a un futuro de alta tecnología para la minería en aguas profundas
- SQL para Ciencia de Datos Comprender y Aprovechar las Uniones
- GPT y más allá Los fundamentos técnicos de los LLMs
- Actores que apoyan el uso de la IA, y aquellos que no lo hacen
- 5 Millonarios Utilizando ChatGPT
- Sistemas de IA Sesgos desenterrados y la apasionante búsqueda de la verdadera equidad






