¿Es bueno tu modelo? Un análisis en profundidad de las métricas avanzadas de Amazon SageMaker Canvas
¿Es bueno tu modelo? Análisis de métricas avanzadas de Amazon SageMaker Canvas
Si eres un analista de negocios, entender el comportamiento del cliente probablemente sea una de las cosas más importantes en las que te preocupas. Comprender las razones y mecanismos detrás de las decisiones de compra del cliente puede facilitar el crecimiento de los ingresos. Sin embargo, la pérdida de clientes (comúnmente conocida como abandono de clientes) siempre plantea un riesgo. Obtener información sobre por qué los clientes se van puede ser igual de crucial para mantener ganancias y ingresos.
Aunque el aprendizaje automático (ML) puede proporcionar información valiosa, hasta la introducción de Amazon SageMaker Canvas se necesitaban expertos en ML para construir modelos de predicción de abandono de clientes.
SageMaker Canvas es un servicio administrado de bajo código/sin código que te permite crear modelos de ML que pueden resolver muchos problemas comerciales sin escribir una sola línea de código. También te permite evaluar los modelos utilizando métricas avanzadas como si fueras un científico de datos.
En esta publicación, mostramos cómo un analista de negocios puede evaluar y entender un modelo de abandono de clasificación creado con SageMaker Canvas utilizando la pestaña de Métricas avanzadas. Explicamos las métricas y mostramos técnicas para tratar los datos y obtener un mejor rendimiento del modelo.
- Esta semana en IA, 31 de julio de 2023
- AI Equipaje para Personas con Discapacidad Visual Recibe Excelentes Críticas
- ¡Ahora puedes ver la Cumbre de IA Generativa a pedido aquí!
Prerrequisitos
Si deseas implementar todas o algunas de las tareas descritas en esta publicación, necesitas una cuenta de AWS con acceso a SageMaker Canvas. Consulta Predecir el abandono de clientes con aprendizaje automático sin código utilizando Amazon SageMaker Canvas para aprender los conceptos básicos sobre SageMaker Canvas, el modelo de abandono y el conjunto de datos.
Introducción a la evaluación del rendimiento del modelo
Como guía general, cuando necesitas evaluar el rendimiento de un modelo, estás tratando de medir qué tan bien el modelo predecirá algo cuando vea nuevos datos. Esta predicción se llama inferencia. Comienzas entrenando el modelo utilizando datos existentes y luego le pides al modelo que prediga el resultado en datos que aún no ha visto. La precisión con la que el modelo predice este resultado es lo que observas para entender el rendimiento del modelo.
Si el modelo no ha visto los nuevos datos, ¿cómo se sabría si la predicción es buena o mala? Bueno, la idea es utilizar datos históricos donde los resultados ya se conocen y comparar estos valores con los valores predichos por el modelo. Esto se logra apartando una parte del conjunto de datos de entrenamiento histórico para poder compararla con lo que el modelo predice para esos valores.
En el ejemplo de abandono de clientes (que es un problema de clasificación categórica), comienzas con un conjunto de datos históricos que describe a los clientes con muchas características (una en cada registro). Una de las características, llamada Abandono, puede ser Verdadero o Falso, describiendo si el cliente abandonó el servicio o no. Para evaluar la precisión del modelo, dividimos este conjunto de datos y entrenamos el modelo utilizando una parte (el conjunto de datos de entrenamiento) y le pedimos al modelo que prediga el resultado (clasifique al cliente como Abandono o no) con la otra parte (el conjunto de datos de prueba). Luego comparamos la predicción del modelo con la verdad absoluta contenida en el conjunto de datos de prueba.
Interpretación de métricas avanzadas
En esta sección, discutimos las métricas avanzadas en SageMaker Canvas que pueden ayudarte a entender el rendimiento del modelo.
Matriz de confusión
SageMaker Canvas utiliza matrices de confusión para ayudarte a visualizar cuándo un modelo genera predicciones correctamente. En una matriz de confusión, los resultados se organizan para comparar los valores predichos con los valores históricos (conocidos) reales. El siguiente ejemplo explica cómo funciona una matriz de confusión para un modelo de predicción de dos categorías que predice etiquetas positivas y negativas:
- Verdadero positivo – El modelo predijo correctamente positivo cuando la etiqueta verdadera era positiva
- Verdadero negativo – El modelo predijo correctamente negativo cuando la etiqueta verdadera era negativa
- Falso positivo – El modelo predijo incorrectamente positivo cuando la etiqueta verdadera era negativa
- Falso negativo – El modelo predijo incorrectamente negativo cuando la etiqueta verdadera era positiva
La siguiente imagen es un ejemplo de una matriz de confusión para dos categorías. En nuestro modelo de abandono, los valores reales provienen del conjunto de datos de prueba y los valores predichos provienen de preguntar a nuestro modelo.
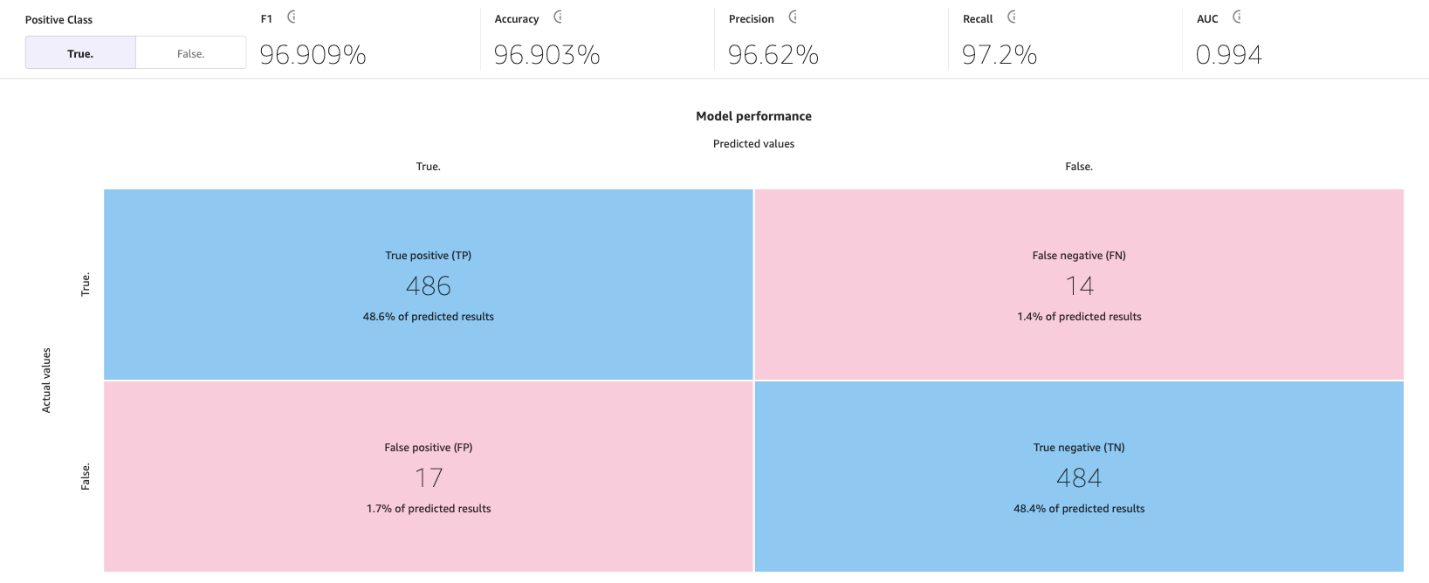
Precisión
La precisión es el porcentaje de predicciones correctas sobre todas las filas o muestras del conjunto de prueba. Son las muestras verdaderas que se predijeron como verdaderas, más las muestras falsas que se predijeron correctamente como falsas, dividido por el número total de muestras en el conjunto de datos.
Es una de las métricas más importantes para entender porque te dirá en qué porcentaje el modelo predijo correctamente, pero puede ser engañosa en algunos casos. Por ejemplo:
- Desbalance de clases – Cuando las clases en tu conjunto de datos no están distribuidas de manera uniforme (tienes un número desproporcionado de muestras de una clase y muy pocas de las demás), la exactitud puede ser engañosa. En tales casos, incluso un modelo que simplemente predice la clase mayoritaria para cada instancia puede lograr una alta exactitud.
- Clasificación sensible al costo – En algunas aplicaciones, el costo de clasificar incorrectamente diferentes clases puede ser diferente. Por ejemplo, si estuviéramos prediciendo si un medicamento puede agravar una condición, un falso negativo (por ejemplo, predecir que el medicamento podría no agravar cuando en realidad sí lo hace) puede ser más costoso que un falso positivo (por ejemplo, predecir que el medicamento podría agravar cuando en realidad no lo hace).
Precisión, recordatorio y puntuación F1
La precisión es la fracción de verdaderos positivos (VP) sobre todos los positivos predichos (VP + FP). Mide la proporción de predicciones positivas que son realmente correctas.
El recordatorio es la fracción de verdaderos positivos (VP) sobre todos los positivos reales (VP + FN). Mide la proporción de instancias positivas que fueron correctamente predichas como positivas por el modelo.
La puntuación F1 combina precisión y recordatorio para proporcionar una única puntuación que equilibra el compromiso entre ellos. Se define como la media armónica de precisión y recordatorio:
Puntuación F1 = 2 * (precisión * recordatorio) / (precisión + recordatorio)
La puntuación F1 varía de 0 a 1, siendo una puntuación más alta indicativa de un mejor rendimiento. Una puntuación F1 perfecta de 1 indica que el modelo ha logrado tanto una precisión perfecta como un recordatorio perfecto, y una puntuación de 0 indica que las predicciones del modelo son completamente incorrectas.
La puntuación F1 proporciona una evaluación equilibrada del rendimiento del modelo. Considera precisión y recordatorio, proporcionando una métrica de evaluación más informativa que refleja la capacidad del modelo para clasificar correctamente instancias positivas y evitar falsos positivos y falsos negativos.
Por ejemplo, en el diagnóstico médico, la detección de fraudes y el análisis de sentimientos, F1 es especialmente relevante. En el diagnóstico médico, identificar con precisión la presencia de una enfermedad o condición específica es crucial, y los falsos negativos o falsos positivos pueden tener consecuencias significativas. La puntuación F1 tiene en cuenta tanto la precisión (la capacidad de identificar correctamente casos positivos) como el recordatorio (la capacidad de encontrar todos los casos positivos), proporcionando una evaluación equilibrada del rendimiento del modelo en la detección de la enfermedad. De manera similar, en la detección de fraudes, donde el número de casos de fraude reales es relativamente bajo en comparación con los casos no fraudulentos (clases desequilibradas), la exactitud por sí sola puede ser engañosa debido a un gran número de verdaderos negativos. La puntuación F1 proporciona una medida integral de la capacidad del modelo para detectar tanto casos fraudulentos como no fraudulentos, considerando tanto la precisión como el recordatorio. Y en el análisis de sentimientos, si el conjunto de datos está desequilibrado, la exactitud puede no reflejar con precisión el rendimiento del modelo en la clasificación de instancias de la clase de sentimiento positivo.
AUC (área bajo la curva)
La métrica AUC evalúa la capacidad de un modelo de clasificación binaria para distinguir entre clases positivas y negativas en todos los umbrales de clasificación. Un umbral es un valor utilizado por el modelo para tomar una decisión entre las dos posibles clases, convirtiendo la probabilidad de que una muestra sea parte de una clase en una decisión binaria. Para calcular el AUC, se trazan la tasa de verdaderos positivos (TPR) y la tasa de falsos positivos (FPR) en diferentes configuraciones de umbral. La TPR mide la proporción de verdaderos positivos sobre todos los positivos reales, mientras que la FPR mide la proporción de falsos positivos sobre todos los negativos reales. La curva resultante, llamada curva característica de operación del receptor (ROC), proporciona una representación visual de la TPR y la FPR en diferentes configuraciones de umbral. El valor AUC, que varía de 0 a 1, representa el área bajo la curva ROC. Valores de AUC más altos indican un mejor rendimiento, con un clasificador perfecto logrando un AUC de 1.
El siguiente gráfico muestra la curva ROC, con la TPR como eje Y y la FPR como eje X. Cuanto más cerca esté la curva de la esquina superior izquierda del gráfico, mejor lo hace el modelo al clasificar los datos en categorías.
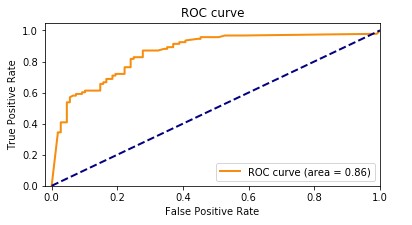
Para aclarar, veamos un ejemplo. Pensemos en un modelo de detección de fraudes. Por lo general, estos modelos se entrenan con conjuntos de datos desequilibrados. Esto se debe a que, por lo general, casi todas las transacciones en el conjunto de datos no son fraudulentas, con solo algunas etiquetadas como fraudes. En este caso, la precisión por sí sola puede no capturar adecuadamente el rendimiento del modelo porque probablemente esté fuertemente influenciada por la abundancia de casos no fraudulentos, lo que lleva a puntuaciones de precisión engañosamente altas.
En este caso, el AUC sería una métrica mejor para evaluar el rendimiento del modelo porque proporciona una evaluación integral de la capacidad de un modelo para distinguir entre transacciones fraudulentas y no fraudulentas. Ofrece una evaluación más matizada, teniendo en cuenta el equilibrio entre la tasa de verdaderos positivos y la tasa de falsos positivos en varios umbrales de clasificación.
Al igual que la puntuación F1, es particularmente útil cuando el conjunto de datos está desequilibrado. Mide el equilibrio entre TPR y FPR y muestra qué tan bien el modelo puede diferenciar entre las dos clases independientemente de su distribución. Esto significa que incluso si una clase es significativamente más pequeña que la otra, la curva ROC evalúa el rendimiento del modelo de manera equilibrada al considerar ambas clases por igual.
Temas clave adicionales
Las métricas avanzadas no son las únicas herramientas importantes disponibles para evaluar y mejorar el rendimiento del modelo de aprendizaje automático. La preparación de datos, la ingeniería de características y el análisis del impacto de las características son técnicas esenciales para la construcción del modelo. Estas actividades desempeñan un papel crucial en la extracción de ideas significativas de los datos en bruto y en la mejora del rendimiento del modelo, lo que lleva a resultados más sólidos y perspicaces.
Preparación de datos e ingeniería de características
La ingeniería de características es el proceso de seleccionar, transformar y crear nuevas variables (características) a partir de datos en bruto, y desempeña un papel clave en la mejora del rendimiento de un modelo de aprendizaje automático. Seleccionar las variables o características más relevantes de los datos disponibles implica eliminar características irrelevantes o redundantes que no contribuyen al poder predictivo del modelo. Transformar las características de los datos en un formato adecuado incluye el escalado, la normalización y el manejo de valores faltantes. Y finalmente, crear nuevas características a partir de los datos existentes se realiza a través de transformaciones matemáticas, combinando o interactuando diferentes características, o creando nuevas características a partir del conocimiento específico del dominio.
Análisis de importancia de características
SageMaker Canvas genera un análisis de importancia de características que explica el impacto que cada columna en su conjunto de datos tiene en el modelo. Cuando genera predicciones, puede ver el impacto de la columna que identifica qué columnas tienen el mayor impacto en cada predicción. Esto le brindará información sobre qué características deben formar parte de su modelo final y cuáles deben descartarse. El impacto de la columna es un puntaje porcentual que indica cuánto peso tiene una columna en la toma de predicciones en relación con las demás columnas. Para un impacto de columna del 25%, Canvas pondera la predicción en un 25% para la columna y un 75% para las demás columnas.
Enfoques para mejorar la precisión del modelo
Aunque existen múltiples métodos para mejorar la precisión del modelo, los científicos de datos y los profesionales de aprendizaje automático suelen seguir uno de los dos enfoques discutidos en esta sección, utilizando las herramientas y métricas descritas anteriormente.
Enfoque centrado en el modelo
En este enfoque, los datos siempre permanecen iguales y se utilizan para mejorar iterativamente el modelo para obtener los resultados deseados. Las herramientas utilizadas con este enfoque incluyen:
- Probar múltiples algoritmos de aprendizaje automático relevantes
- Ajuste y optimización de algoritmos e hiperparámetros
- Diferentes métodos de conjunto de modelos
- Uso de modelos pre-entrenados (SageMaker proporciona varios modelos incorporados o pre-entrenados para ayudar a los profesionales de aprendizaje automático)
- AutoML, que es lo que SageMaker Canvas hace detrás de escena (utilizando Amazon SageMaker Autopilot), que abarca todo lo anterior
Enfoque centrado en los datos
En este enfoque, el enfoque se centra en la preparación de datos, la mejora de la calidad de los datos y la modificación iterativa de los datos para mejorar el rendimiento:
- Explorar las estadísticas del conjunto de datos utilizado para entrenar el modelo, también conocido como análisis exploratorio de datos (EDA)
- Mejorar la calidad de los datos (limpieza de datos, imputación de valores faltantes, detección y gestión de valores atípicos)
- Selección de características
- Ingeniería de características
- Aumento de datos
Mejorar el rendimiento del modelo con Canvas
Comenzamos con el enfoque centrado en los datos. Utilizamos la funcionalidad de vista previa del modelo para realizar un análisis exploratorio de datos inicial. Esto nos proporciona una línea de base que podemos utilizar para realizar el aumento de datos, generar una nueva línea de base y finalmente obtener el mejor modelo con un enfoque centrado en el modelo utilizando la funcionalidad de construcción estándar.
Utilizamos el conjunto de datos sintéticos de una compañía de telefonía móvil. Este conjunto de datos de muestra contiene 5,000 registros, donde cada registro utiliza 21 atributos para describir el perfil del cliente. Consulte Predecir la rotación de clientes con aprendizaje automático sin código utilizando Amazon SageMaker Canvas para obtener una descripción completa.
Vista previa del modelo en un enfoque centrado en los datos
Como primer paso, abrimos el conjunto de datos, seleccionamos la columna a predecir como ¿Churn? y generamos un modelo de vista previa eligiendo Modelo de vista previa.
El panel de Modelo de vista previa mostrará el progreso hasta que el modelo de vista previa esté listo.
Cuando el modelo esté listo, SageMaker Canvas generará un análisis de importancia de características.
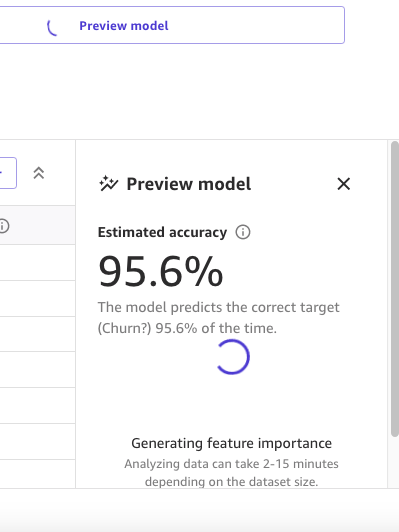
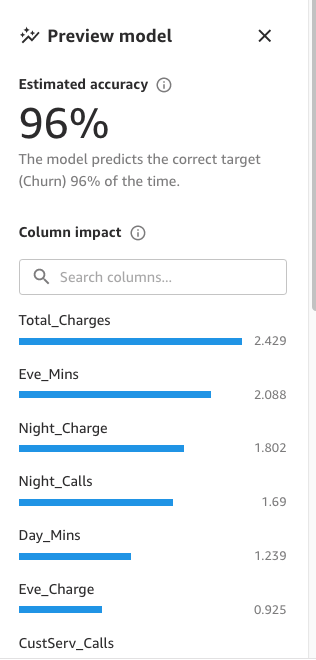
Finalmente, cuando esté completo, el panel mostrará una lista de columnas con su impacto en el modelo. Estos son útiles para comprender qué tan relevantes son las características en nuestras predicciones. El impacto de la columna es un puntaje porcentual que indica cuánto peso tiene una columna en la toma de predicciones en relación con las otras columnas. En el siguiente ejemplo, para la columna de Llamadas nocturnas, SageMaker Canvas pondera la predicción como 4.04% para la columna y 95.9% para las otras columnas. Cuanto mayor sea el valor, mayor será el impacto.
Como podemos ver, el modelo de vista previa tiene una precisión del 95.6%. Intentemos mejorar el rendimiento del modelo utilizando un enfoque centrado en los datos. Realizamos la preparación de datos y utilizamos técnicas de ingeniería de características para mejorar el rendimiento.
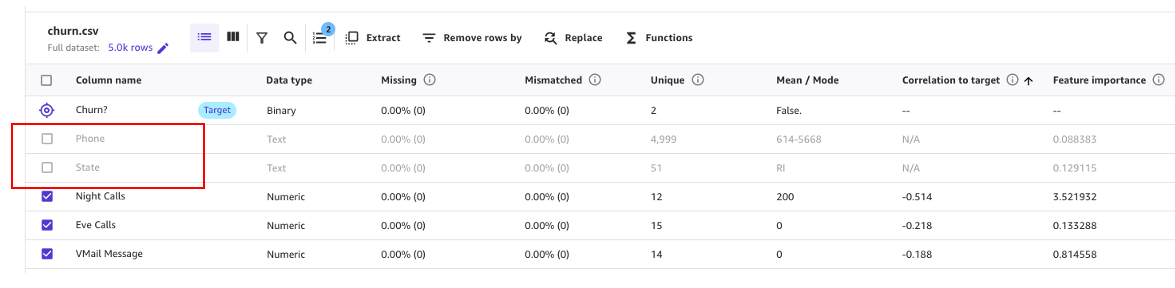
Como se muestra en la siguiente captura de pantalla, podemos observar que las columnas de Teléfono y Estado tienen mucho menos impacto en nuestra predicción. Por lo tanto, utilizaremos esta información como entrada para nuestra próxima fase, la preparación de datos.

SageMaker Canvas proporciona transformaciones de datos de ML con las que puede limpiar, transformar y preparar sus datos para la construcción del modelo. Puede utilizar estas transformaciones en sus conjuntos de datos sin ningún código y se agregarán a la receta del modelo, que es un registro de la preparación de datos realizada en sus datos antes de construir el modelo.
Tenga en cuenta que cualquier transformación de datos que utilice solo modifica los datos de entrada al construir un modelo y no modifica su conjunto de datos ni su fuente de datos original.
Las siguientes transformaciones están disponibles en SageMaker Canvas para preparar sus datos para la construcción:
- Extracción de fechas y horas
- Eliminar columnas
- Filtrar filas
- Funciones y operadores
- Gestionar filas
- Renombrar columnas
- Eliminar filas
- Reemplazar valores
- Remuestrear datos de series temporales
Comencemos eliminando las columnas que hemos encontrado que tienen poco impacto en nuestra predicción.
Por ejemplo, en este conjunto de datos, el número de teléfono es simplemente el equivalente a un número de cuenta, es inútil e incluso perjudicial para predecir la probabilidad de rotación de otras cuentas. Del mismo modo, el estado del cliente no impacta mucho en nuestro modelo. Eliminemos las columnas de Teléfono y Estado desmarcando esas características en Nombre de columna.
Ahora, realicemos algunas transformaciones adicionales de datos y de ingeniería de características.
Por ejemplo, observamos en nuestro análisis anterior que el monto cobrado a los clientes tiene un impacto directo en la rotación. Por lo tanto, creemos una nueva columna que calcule los cargos totales a nuestros clientes combinando Cargo, Minutos y Llamadas para Día, Tarde, Noche e Internacional. Para hacerlo, utilizamos fórmulas personalizadas en SageMaker Canvas.
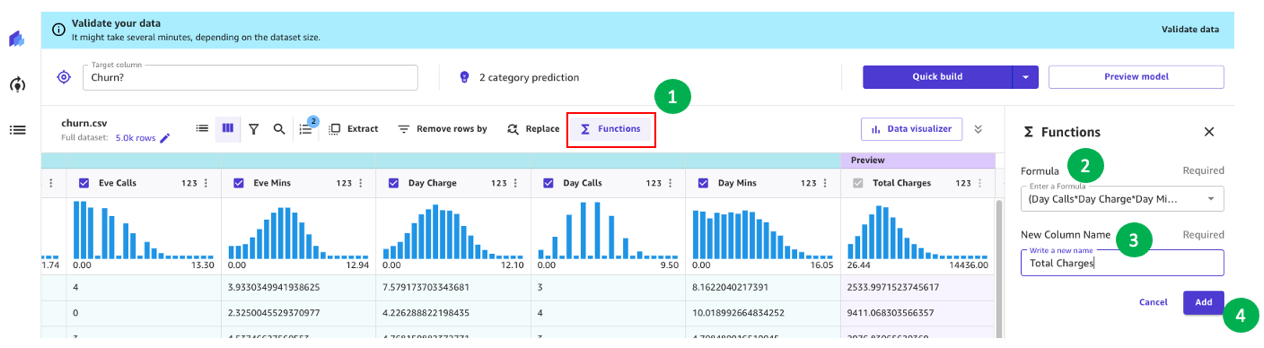
Comencemos eligiendo Funciones, luego agregamos al cuadro de fórmula el siguiente texto:
(Llamadas diurnas*Cargo diurno*Minutos diurnos)+(Llamadas vespertinas*Cargo vespertino*Minutos vespertinos)+(Llamadas nocturnas*Cargo nocturno*Minutos nocturnos)+(Llamadas internacionales*Cargo internacional*Minutos internacionales)
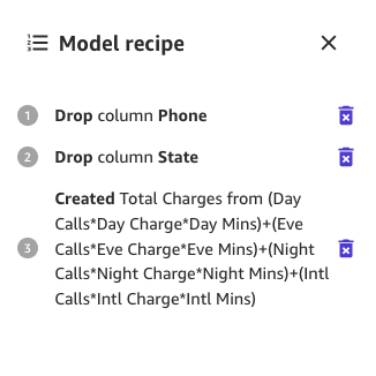
Asignemos un nombre a la nueva columna (por ejemplo, Cargos totales) y elijamos Añadir después de que se haya generado la vista previa. La receta del modelo ahora debería verse como se muestra en la siguiente captura de pantalla.
Cuando se complete esta preparación de datos, entrenamos un nuevo modelo de vista previa para ver si el modelo mejoró. Elija nuevamente Vista previa del modelo y el panel inferior derecho mostrará el progreso.

Cuando termine el entrenamiento, procederá a recalcular la precisión pronosticada y también creará un análisis de impacto de columna.
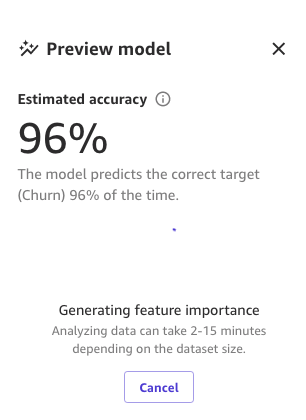
Y finalmente, cuando todo el proceso esté completo, podemos ver el mismo panel que vimos antes, pero con la nueva precisión del modelo de vista previa. Puede notar que la precisión del modelo aumentó en un 0,4% (de 95,6% a 96%).
Los números en las imágenes anteriores pueden diferir de los suyos porque ML introduce cierta estocasticidad en el proceso de entrenamiento de modelos, lo que puede llevar a diferentes resultados en diferentes compilaciones.
Enfoque centrado en el modelo para crear el modelo
Canvas ofrece dos opciones para construir sus modelos:
- Construcción estándar: construye el mejor modelo a partir de un proceso optimizado donde la velocidad se intercambia por una mejor precisión. Utiliza Auto-ML, que automatiza varias tareas de ML, incluida la selección del modelo, la prueba de varios algoritmos relevantes para su caso de uso de ML, la sintonización de hiperparámetros y la creación de informes de explicabilidad del modelo.
- Construcción rápida: construye un modelo simple en una fracción del tiempo en comparación con una construcción estándar, pero se intercambia la precisión por la velocidad. El modelo rápido es útil cuando se itera para comprender más rápidamente el impacto de los cambios de datos en la precisión del modelo.
Continuemos utilizando un enfoque de construcción estándar.
Construcción estándar
Como vimos antes, la construcción estándar construye el mejor modelo a partir de un proceso optimizado para maximizar la precisión.
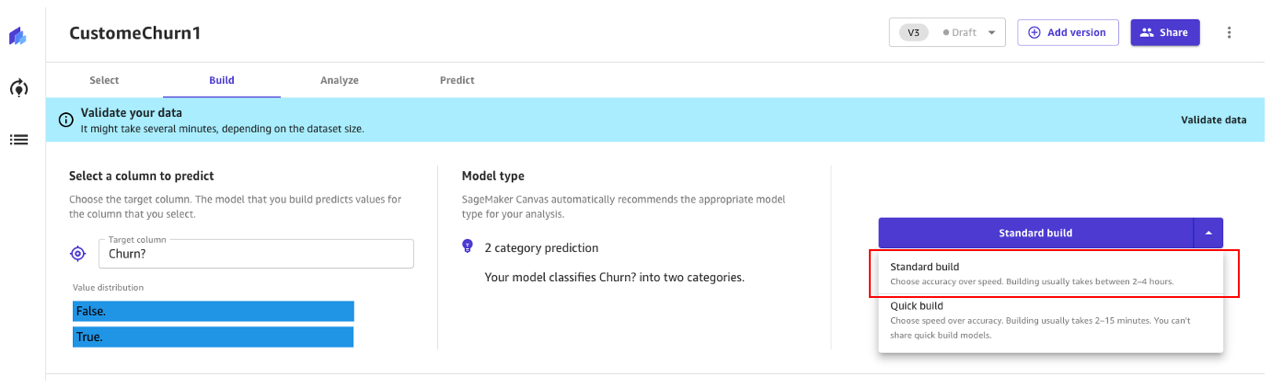
El proceso de construcción para nuestro modelo de abandono demora alrededor de 45 minutos. Durante este tiempo, Canvas prueba cientos de tuberías candidatas, seleccionando el mejor modelo. En la siguiente captura de pantalla, podemos ver el tiempo de construcción esperado y el progreso.
Con el proceso de construcción estándar, nuestro modelo de ML ha mejorado la precisión del modelo al 96,903%, lo cual es una mejora significativa.

Explorar métricas avanzadas
¡Vamos a explorar el modelo usando la pestaña de métricas avanzadas! En la pestaña de Puntuación, elige métricas avanzadas.

En esta página se mostrará la siguiente matriz de confusión junto con las métricas avanzadas: puntuación F1, precisión, recall, puntuación F1 y AUC.
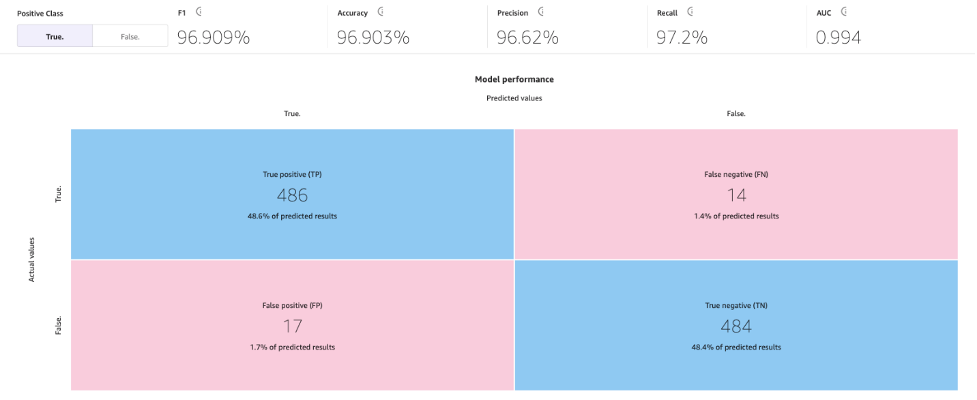
Generar predicciones
Ahora que las métricas lucen bien, podemos realizar una predicción interactiva en la pestaña de Predicción, ya sea en modo de lote o en tiempo real (individual).
Tenemos dos opciones:
- Utilizar este modelo para realizar predicciones en modo de lote o individual
- Enviar el modelo a Amazon Sagemaker Studio para compartirlo con científicos de datos
Limpiar
Para evitar incurrir en cargos futuros de sesión, cierra sesión en SageMaker Canvas.

Conclusión
SageMaker Canvas proporciona herramientas poderosas que te permiten construir y evaluar la precisión de modelos, mejorando su rendimiento sin necesidad de programación ni experiencia especializada en ciencia de datos y aprendizaje automático. Como hemos visto en el ejemplo a través de la creación de un modelo de rotación de clientes, al combinar estas herramientas con un enfoque centrado en los datos y en el modelo utilizando métricas avanzadas, los analistas de negocios pueden crear y evaluar modelos de predicción. Con una interfaz visual, también tienes la capacidad de generar predicciones de IA precisas por ti mismo. Te animamos a explorar las referencias y ver cómo muchos de estos conceptos pueden aplicarse en otros tipos de problemas de IA.
Referencias
- Pronosticar la rotación de clientes con aprendizaje automático sin código utilizando Amazon SageMaker Canvas
- Construir, compartir, implementar: cómo los analistas de negocios y científicos de datos logran un tiempo de comercialización más rápido utilizando aprendizaje automático sin código y Amazon SageMaker Canvas
- Personalizar y reutilizar modelos generados por Amazon SageMaker Autopilot
- Taller de Inmersión en Amazon SageMaker Canvas
- Gestionar flujos de trabajo de AutoML con AWS Step Functions y AutoGluon en Amazon SageMaker
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ¿SEER ¿Un avance en los modelos de visión por computadora con autoaprendizaje?
- El mercado global de chips de inteligencia artificial experimentará una enorme tasa de crecimiento anual compuesta (CAGR) del 31.8% hasta el año 2031.
- 6 Razones por las cuales los eventos presenciales siguen siendo los reyes de la generación de leads
- Basura entra, basura sale El papel crucial de la calidad de los datos en la IA
- Parte 1 Crear paso a paso un entorno virtual para ejecutar tus tuberías de datos en sistemas basados en Windows
- EE.UU. busca malware chino que podría perturbar las operaciones militares estadounidenses
- Por qué Meta está regalando su modelo de IA extremadamente poderoso






