Training a un Agente para Dominar un Juego Simple a través de Juego Autónomo
Entrenamiento de un Agente para Dominar un Juego Simple mediante Juego Autónomo
Simular juegos y predecir los resultados.

Introducción
¿No es asombroso que todo lo que necesitas para sobresalir en un juego de información perfecta esté ahí para que todos lo vean en las reglas del juego?
Desafortunadamente, para simples mortales como yo, leer las reglas de un juego nuevo es solo una pequeña fracción del camino para aprender a jugar un juego complejo. La mayor parte del tiempo se pasa jugando, idealmente contra un jugador de fuerza comparable (o un jugador mejor que tenga la paciencia suficiente para ayudarnos a exponer nuestras debilidades). Perder a menudo y, con suerte, ganar a veces, nos brinda los castigos y recompensas psicológicas que nos llevan a jugar de manera incrementalmente mejor.
Tal vez, en un futuro no muy lejano, un modelo de lenguaje leerá las reglas de un juego complejo como el ajedrez y, desde el principio, jugará al nivel más alto posible. Mientras tanto, propongo un desafío más modesto: aprender mediante el autojuego.
En este proyecto, entrenaremos a un agente para que aprenda a jugar juegos de información perfecta de dos jugadores observando los resultados de partidas jugadas por versiones anteriores de sí mismo. El agente aproximará un valor (el resultado esperado del juego) para cualquier estado del juego. Como desafío adicional, nuestro agente no podrá mantener una tabla de búsqueda del espacio de estados, ya que este enfoque no sería manejable para juegos complejos.
- Microsoft Research lanza el ‘Cuarteto de Heavy Metal’ de los compiladores de IA Rammer, Roller, Welder y Grinder
- Las 50 mejores herramientas de escritura de IA para probar (septiembre de 2023)
- Python en Excel Abriendo la puerta al análisis avanzado de datos
Resolviendo SumTo100
El juego
El juego del que vamos a hablar es SumTo100. El objetivo del juego es alcanzar una suma de 100 sumando números entre 1 y 10. Aquí están las reglas:
- Inicializar sum = 0.
- Elegir un primer jugador. Los dos jugadores se turnan.
- Mientras sum < 100:
- El jugador elige un número entre 1 y 10 inclusivamente. El número seleccionado se suma a la suma sin exceder 100.
- Si sum < 100, el otro jugador juega (es decir, volvemos al punto 3).
4. El jugador que agregó el último número (alcanzando 100) gana.

Comenzar con un juego tan simple tiene muchas ventajas:
- El espacio de estados tiene solo 101 valores posibles.
- Los estados se pueden representar en una cuadrícula 1D. Esta peculiaridad nos permitirá representar la función de valor de estado aprendida por el agente como un gráfico de barras 1D.
- La estrategia óptima es conocida: alcanzar una suma de 11n + 1, donde n ∈ {0, 1, 2, …, 9}
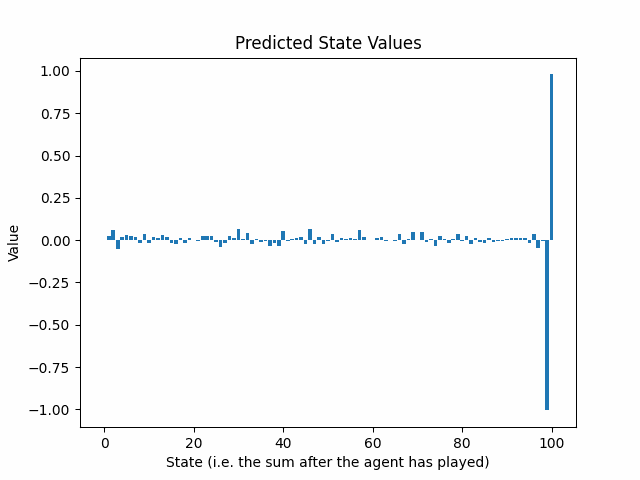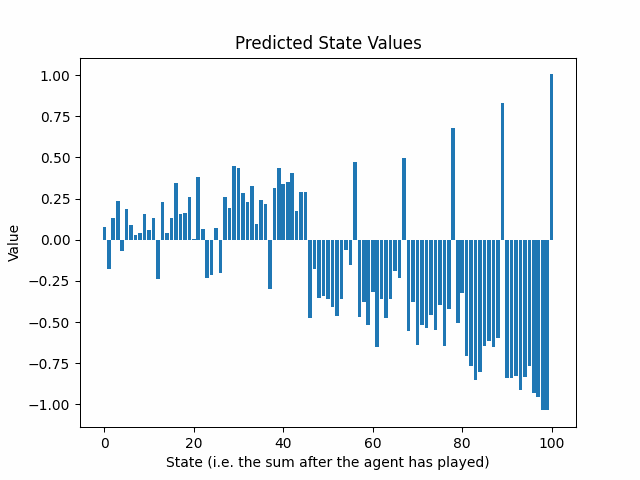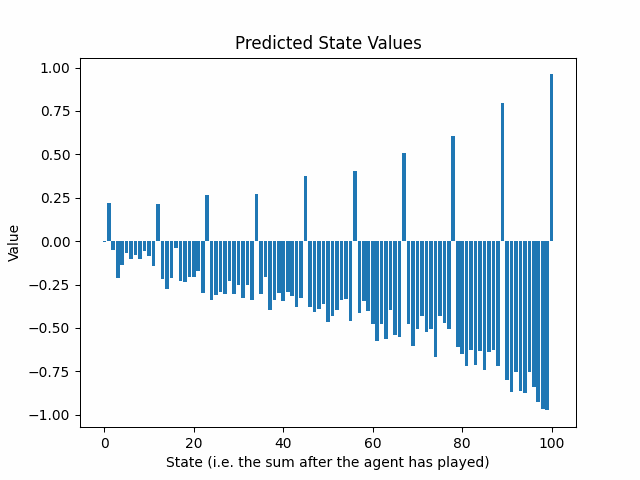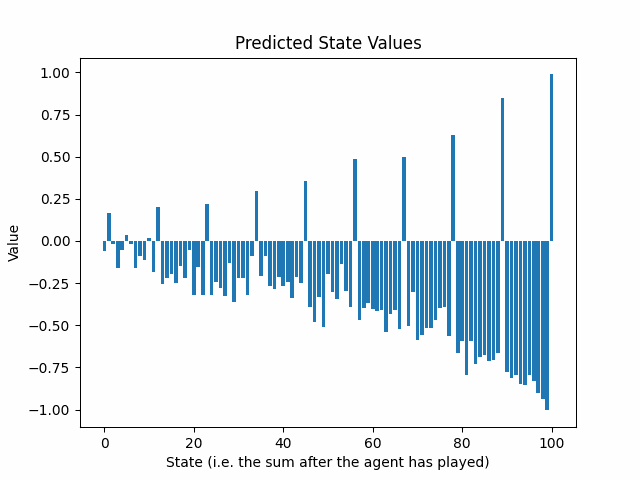
Podemos visualizar el valor de estado de la estrategia óptima:
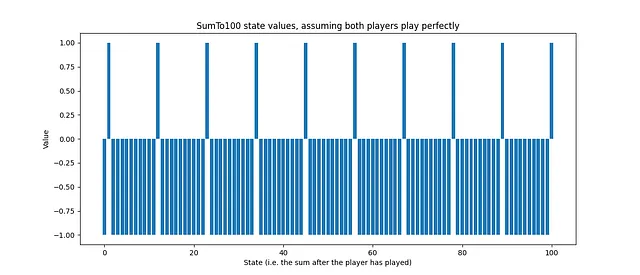
El estado del juego es la suma después de que un agente haya completado su turno. Un valor de 1.0 significa que el agente está seguro de ganar (o ha ganado), mientras que un valor de -1.0 significa que el agente está seguro de perder (asumiendo que el oponente juega de manera óptima). Un valor intermedio representa el retorno estimado. Por ejemplo, un valor de estado de 0.2 significa un estado ligeramente positivo, mientras que un valor de estado de -0.8 representa una posible pérdida.
Si quieres sumergirte en el código, el script que realiza todo el procedimiento de entrenamiento es learn_sumTo100.sh, en este repositorio. De lo contrario, acompáñame mientras repasamos una descripción a alto nivel de cómo nuestro agente aprende mediante el autojuego.
Generación de juegos jugados por jugadores aleatorios
Queremos que nuestro agente aprenda de los juegos jugados por versiones anteriores de sí mismo, pero en la primera iteración, dado que el agente aún no ha aprendido nada, tendremos que simular juegos jugados por jugadores aleatorios. En cada turno, los jugadores recibirán la lista de movimientos legales de la autoridad del juego (la clase que codifica las reglas del juego), dada la situación actual del juego. Los jugadores aleatorios seleccionarán un movimiento al azar de esta lista.
La Figura 2 es un ejemplo de un juego jugado por dos jugadores aleatorios:

En este caso, el segundo jugador ganó el juego al alcanzar una suma de 100.
Implementaremos un agente que tiene acceso a una red neuronal que toma como entrada el estado del juego (después de que el agente ha jugado) y que devuelve el retorno esperado de este juego. Para cualquier estado dado (antes de que el agente haya jugado), el agente obtiene la lista de acciones legales y sus correspondientes estados candidatos (solo consideramos juegos con transiciones deterministas).
La Figura 3 muestra las interacciones entre el agente, el oponente (cuyo mecanismo de selección de movimientos es desconocido) y la autoridad del juego:

En esta configuración, el agente se basa en su red neuronal de regresión para predecir el retorno esperado de los estados del juego. Cuanto mejor pueda predecir la red neuronal qué movimiento candidato produce el mayor retorno, mejor jugará el agente.
Nuestra lista de partidas jugadas al azar nos proporcionará el conjunto de datos para nuestra primera pasada de entrenamiento. Tomando el juego de ejemplo de la Figura 2, queremos castigar los movimientos realizados por el jugador 1, ya que su comportamiento condujo a una derrota. El estado resultante de la última acción obtiene un valor de -1.0, ya que permitió al oponente ganar. Los otros estados obtienen valores negativos descontados por un factor de γᵈ , donde d es la distancia con respecto al último estado alcanzado por el agente. γ (gamma) es el factor de descuento, un número ∈ [0, 1], que expresa la incertidumbre en la evolución de un juego: no queremos castigar las decisiones tempranas tan duramente como las últimas decisiones. La Figura 4 muestra los valores de estado asociados con las decisiones tomadas por el jugador 1:

Los juegos aleatorios generan estados con su retorno esperado objetivo. Por ejemplo, alcanzar una suma de 97 tiene un retorno esperado objetivo de -1.0, y una suma de 73 tiene un retorno esperado objetivo de -γ³. La mitad de los estados toman el punto de vista del jugador 1 y la otra mitad toman el punto de vista del jugador 2 (aunque no importa en el caso del juego SumTo100). Cuando un juego termina con una victoria para el agente, los estados correspondientes obtienen valores positivos descontados de manera similar.
Entrenamiento de un agente para predecir el retorno de los juegos
Tenemos todo lo necesario para comenzar nuestro entrenamiento: una red neuronal (utilizaremos un perceptrón de dos capas) y un conjunto de datos de pares (estado, retorno esperado). Veamos cómo evoluciona la pérdida en el retorno esperado predicho:

No deberíamos sorprendernos de que la red neuronal no muestre mucho poder predictivo sobre el resultado de los juegos jugados por jugadores aleatorios.
¿La red neuronal aprendió algo en absoluto?
Afortunadamente, debido a que los estados se pueden representar como una cuadrícula unidimensional de números entre 0 y 100, podemos trazar las predicciones de retorno de la red neuronal después de la primera ronda de entrenamiento y compararlas con los valores óptimos de los estados de la Figura 1:
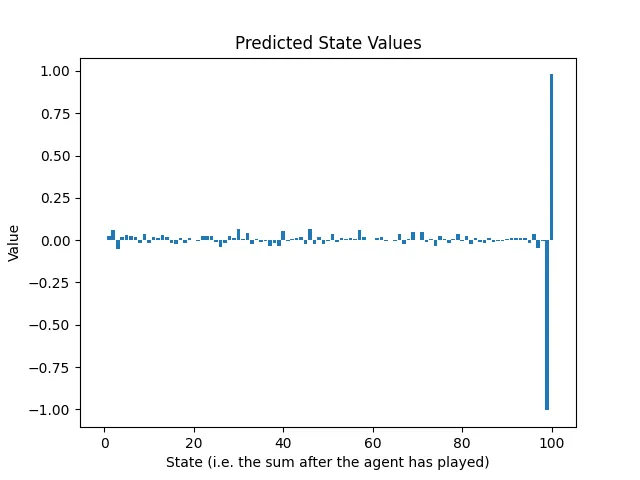
Resulta que, a través del caos de los juegos aleatorios, la red neuronal aprendió dos cosas:
- Si puedes alcanzar una suma de 100, hazlo. Eso es bueno saberlo, considerando que es el objetivo del juego.
- Si alcanzas una suma de 99, seguramente perderás. De hecho, en esta situación, el oponente solo tiene una acción legal y esa acción conduce a una pérdida para el agente.
La red neuronal aprendió básicamente a terminar el juego.
Para aprender a jugar un poco mejor, debemos reconstruir el conjunto de datos simulando juegos jugados entre copias del agente con su red neuronal recién entrenada. Para evitar generar juegos idénticos, los jugadores juegan un poco al azar. Un enfoque que funciona bien es elegir movimientos con el algoritmo epsilon-greedy, usando ε = 0.5 para el primer movimiento de cada jugador, luego ε = 0.1 para el resto del juego.
Repitiendo el ciclo de entrenamiento con jugadores cada vez mejores
Dado que ambos jugadores ahora saben que deben llegar a 100, alcanzar una suma entre 90 y 99 debe ser castigado, porque el oponente aprovecharía la oportunidad para ganar el partido. Este fenómeno es visible en los valores de estado predichos después de la segunda ronda de entrenamiento:
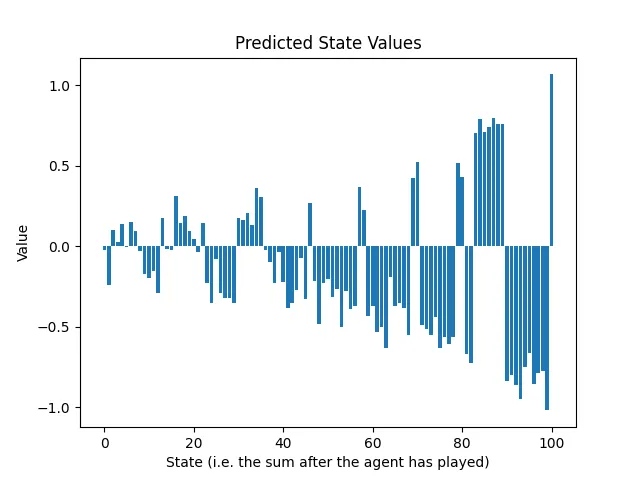
Vemos un patrón emergente. La primera ronda de entrenamiento informa a la red neuronal sobre la última acción; la segunda ronda de entrenamiento informa sobre la penúltima acción, y así sucesivamente. Debemos repetir el ciclo de generación de juegos y entrenamiento en predicción al menos tantas veces como acciones hay en un juego.
La siguiente animación muestra la evolución de los valores de estado predichos después de 25 rondas de entrenamiento:
El sobre de los retornos predichos decae exponencialmente, a medida que avanzamos desde el final hacia el comienzo del juego. ¿Es esto un problema?
Dos factores contribuyen a este fenómeno:
- γ amortigua directamente los retornos esperados objetivo, a medida que nos alejamos del final del juego.
- El algoritmo epsilon-greedy inyecta aleatoriedad en los comportamientos de los jugadores, haciendo que los resultados sean más difíciles de predecir. Existe un incentivo para predecir un valor cercano a cero para protegerse contra casos de pérdidas extremadamente altas. Sin embargo, la aleatoriedad es deseable porque no queremos que la red neuronal aprenda una sola línea de juego. Queremos que la red neuronal presencie errores y movimientos buenos inesperados, tanto del agente como del oponente.
En la práctica, no debería ser un problema porque en cualquier situación, compararemos los valores entre los movimientos legales en un estado dado, los cuales comparten escalas comparables, al menos para el juego SumTo100. La escala de los valores no importa cuando elegimos el movimiento codicioso.
Conclusión
Nos desafiamos a nosotros mismos para crear un agente que pueda aprender a dominar un juego de información perfecta que involucre a dos jugadores, con transiciones deterministas de un estado al siguiente, dada una acción. No se permitieron estrategias ni tácticas codificadas a mano: todo debía ser aprendido mediante el juego autónomo.
Pudimos resolver el juego simple de SumTo100 ejecutando múltiples rondas de enfrentamiento entre copias del agente y entrenando una red neuronal de regresión para predecir el retorno esperado de los juegos generados.
La perspectiva adquirida nos prepara bien para la siguiente escalera en la complejidad del juego, ¡pero eso será para mi próxima publicación! 😊
Gracias por su tiempo.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Cómo StackOverflow se está adaptando frente a la IA generativa
- HubSpot presenta HubSpot AI y el nuevo Sales Hub en INBOUND 2023
- Aumentar la eficiencia matemática Navegando por las operaciones de matrices Numpy
- ¿Puede la IA realmente restaurar detalles faciales de imágenes de baja calidad? Conozca DAEFR un marco de doble rama para mejorar la calidad
- Este artículo de IA propone un método de generación de memoria recursivo para mejorar la consistencia conversacional a largo plazo en modelos de lenguaje grandes
- ¿Se entienden Do Flamingo y DALL-E? Explorando la simbiosis entre los modelos de generación de subtítulos de imágenes y síntesis de texto a imagen
- Investigadores de UCSC y TU Munich proponen RECAST un nuevo modelo basado en el aprendizaje profundo para predecir réplicas