Entrena a tu primer agente de RL basado en Deep Q Learning Una guía paso a paso
Entrena a tu primer agente de RL basado en Deep Q Learning
Introducción:
El Aprendizaje por Refuerzo (RL) es un campo fascinante de la Inteligencia Artificial (IA) que permite a las máquinas aprender y tomar decisiones a través de la interacción con su entorno. El entrenamiento de un agente de RL implica un proceso de prueba y error en el que el agente aprende de sus acciones y las recompensas o penalizaciones subsiguientes que recibe. En este blog, exploraremos los pasos involucrados en el entrenamiento de tu primer agente de RL, junto con fragmentos de código para ilustrar el proceso.
Paso 1: Definir el Entorno
El primer paso en el entrenamiento de un agente de RL es definir el entorno en el que operará. El entorno puede ser una simulación o un escenario del mundo real. Proporciona al agente observaciones y recompensas, permitiéndole aprender y tomar decisiones. OpenAI Gym es una popular biblioteca de Python que proporciona una amplia gama de entornos preconstruidos. Consideremos el clásico entorno “CartPole” para este ejemplo.
import gymenv = gym.make('CartPole-v1')Paso 2: Comprender la Interacción Agente-Entorno
En RL, el agente interactúa con el entorno tomando acciones basadas en sus observaciones. Recibe retroalimentación en forma de recompensas o penalizaciones, que se utilizan para guiar su proceso de aprendizaje. El objetivo del agente es maximizar las recompensas acumulativas a lo largo del tiempo. Para hacer esto, el agente aprende una política, una asignación de observaciones a acciones, que le ayuda a tomar las mejores decisiones.
Paso 3: Elegir un Algoritmo de RL
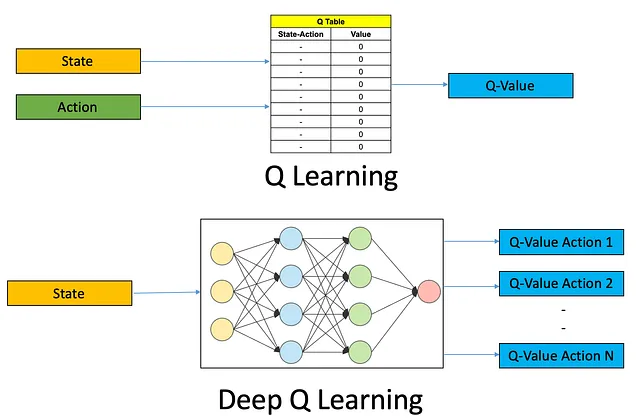
Existen diversos algoritmos de RL, cada uno con sus fortalezas y debilidades. Un algoritmo popular es Q-Learning, que es adecuado para espacios de acciones discretas. Otro algoritmo comúnmente utilizado es Deep Q-Networks (DQN), que utiliza redes neuronales profundas para manejar entornos complejos. Para este ejemplo, usemos el algoritmo DQN.
- Introducción a la Estadística utilizando el lenguaje de programación R
- Investigadores de Alibaba presentan la serie Qwen-VL un conjunto de modelos de visión-lenguaje a gran escala diseñados para percibir y comprender tanto texto como imágenes
- Escalando la Agrupación Aglomerativa para Grandes Volúmenes de Datos

Paso 4: Construir el Agente de RL
Para construir un agente de RL utilizando el algoritmo DQN, necesitamos definir una red neuronal como el aproximador de funciones. La red toma observaciones como entrada y produce valores Q para cada acción posible. También necesitamos implementar una memoria de repetición para almacenar y muestrear experiencias para el entrenamiento.
import torchimport torch.nn as nnimport torch.optim as optimclass DQN(nn.Module): def __init__(self, input_dim, output_dim): super(DQN, self).__init__() self.fc1 = nn.Linear(input_dim, 64) self.fc2 = nn.Linear(64, 64) self.fc3 = nn.Linear(64, output_dim) def forward(self, x): x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) x = self.fc3(x) return x# Crear una instancia del agente DQNinput_dim = env.observation_space.shape[0]output_dim = env.action_space.nagent = DQN(input_dim, output_dim) Paso 5: Entrenar el Agente de RL
Ahora, podemos entrenar el agente de RL utilizando el algoritmo DQN. El agente interactúa con el entorno, observa el estado actual, selecciona una acción basada en su política, recibe una recompensa y actualiza sus valores Q en consecuencia. Este proceso se repite durante un número especificado de episodios o hasta que el agente alcance un nivel satisfactorio de rendimiento.
optimizer = optim.Adam(agent.parameters(), lr=0.001)def train_agent(agent, env, episodes): for episode in range(episodes): state = env.reset() done = False episode_reward = 0 while not done: action = agent.select_action(state) next_state, reward, done, _ = env.step(action) agent.store_experience(state, action, reward, next_state, done) agent
Conclusión:
En este blog, exploramos el proceso de entrenar tu primer agente de RL. Comenzamos definiendo el entorno utilizando OpenAI Gym, que proporciona una variedad de entornos predefinidos para tareas de RL. Luego, discutimos la interacción agente-entorno y el objetivo del agente de maximizar las recompensas acumulativas.
A continuación, elegimos el algoritmo DQN como nuestro algoritmo de RL preferido, que combina redes neuronales profundas con Q-learning para manejar entornos complejos. Construimos un agente de RL utilizando una red neuronal como aproximador de funciones e implementamos una memoria de repetición para almacenar y muestrear experiencias para el entrenamiento.
Finalmente, entrenamos el agente de RL haciéndolo interactuar con el entorno, observar estados, seleccionar acciones basadas en su política, recibir recompensas y actualizar sus valores Q. Este proceso se repitió durante un número especificado de episodios, lo que permitió al agente aprender y mejorar sus capacidades de toma de decisiones.
El Aprendizaje por Refuerzo abre un mundo de posibilidades para entrenar agentes inteligentes que puedan aprender y tomar decisiones de manera autónoma en entornos dinámicos. Siguiendo los pasos descritos en este blog, puedes embarcarte en tu viaje de entrenamiento de agentes de RL y explorar diversos algoritmos, entornos y aplicaciones.
Recuerda que el entrenamiento de RL requiere experimentación, ajustes y paciencia. A medida que te adentres más en RL, podrás explorar técnicas avanzadas como RL profundo, gradientes de políticas y sistemas multiagente. Así que sigue aprendiendo, iterando y empujando los límites de lo que tus agentes de RL pueden lograr.
¡Feliz entrenamiento!
LinkedIn: https://www.linkedin.com/in/smit-kumbhani-44b07615a/
My Google Scholar: https://scholar.google.com/citations?hl=en&user=5KPzARoAAAAJ
Blog sobre “Segmentación semántica para detección y segmentación de neumotórax” https://medium.com/becoming-human/semantic-segmentation-for-pneumothorax-detection-segmentation-9b93629ba5fa

We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Diferenciación automática con Python y C++ para el aprendizaje profundo
- Este artículo de IA de GSAi China presenta un estudio exhaustivo de agentes autónomos basados en LLM
- Revolucionando la Interacción Humano-Máquina La Emergencia de la Ingeniería de Instrucciones
- Router Langchain Cómo crear asistencia de programación utilizando Langchain
- ¿Qué es EDI? Sobre el Intercambio Electrónico de Datos (EDI)
- Amplios horizontes La presentación de NVIDIA señala el camino hacia nuevos avances en Inteligencia Artificial
- Estas herramientas podrían ayudar a proteger nuestras imágenes de la IA






