Moldeando el Futuro de la IA Una Encuesta Exhaustiva sobre Modelos de Pre-Entrenamiento Visión-Lenguaje y su Papel en Tareas Uni-Modales y Multi-Modales.
Encuesta exhaustiva sobre modelos de pre-entrenamiento visión-lenguaje y su papel en tareas uni-modales y multi-modales para moldear el futuro de la IA.


En la última publicación de artículos en investigación de inteligencia artificial, un equipo de investigadores profundiza en el área de preentrenamiento de visión-idioma (VLP) y sus aplicaciones en tareas multimodales. El documento explora la idea de un entrenamiento uni-modal y cómo difiere de las adaptaciones multimodales. Luego, el informe demuestra las cinco áreas importantes de VLP: extracción de características, arquitectura del modelo, objetivos de preentrenamiento, conjuntos de datos de preentrenamiento y tareas secundarias. Los investigadores revisan los modelos VLP existentes y cómo se adaptan y emergen en el campo en diferentes frentes.
El campo de la inteligencia artificial siempre ha intentado entrenar los modelos de manera que perciban, piensen y comprendan los patrones y matices como lo hacen los humanos. Se han hecho varios intentos para incorporar tantos campos de entrada de datos como sea posible, como datos visuales, de audio o de texto. Pero la mayoría de estos enfoques han intentado resolver el problema de “comprensión” en un sentido uni-modal.
Un enfoque uni-modal es un enfoque en el que se evalúa una situación teniendo en cuenta solo un aspecto de ella, como en un video, solo te enfocas en el audio o en la transcripción, mientras que en un enfoque multimodal, intentas abordar tantas características disponibles como puedas e incorporarlas al modelo. Por ejemplo, al analizar un video, se toma en cuenta el audio, la transcripción y la expresión facial del hablante para “comprender” verdaderamente el contexto.
- Implemente un punto final de inferencia de ML sin servidor para modelos de lenguaje grandes utilizando FastAPI, AWS Lambda y AWS CDK.
- GPT vs BERT ¿Cuál es mejor?
- Inmersión teórica profunda en la Regresión Lineal
El enfoque multimodal se vuelve desafiante porque es intensivo en recursos y también porque ha sido difícil obtener grandes cantidades de datos etiquetados para entrenar modelos capaces. Los modelos de preentrenamiento basados en estructuras transformadoras han abordado este problema aprovechando el aprendizaje auto-supervisado y tareas adicionales para aprender representaciones universales a partir de datos no etiquetados a gran escala.
Los modelos de preentrenamiento de manera uni-modal, comenzando con BERT en NLP, han demostrado una efectividad notable al ajustarse con datos etiquetados limitados para tareas secundarias. Los investigadores han explorado la viabilidad del preentrenamiento de visión-idioma (VLP) extendiendo la misma filosofía de diseño al campo multimodal. VLP utiliza modelos de preentrenamiento en conjuntos de datos a gran escala para aprender correspondencias semánticas entre modalidades.
Los investigadores revisan los avances realizados en el enfoque VLP en cinco áreas principales. En primer lugar, discuten cómo los modelos VLP procesan y representan imágenes, videos y texto para obtener características correspondientes, destacando varios modelos empleados. En segundo lugar, también exploran y examinan la perspectiva de un solo flujo y su usabilidad frente a la fusión de doble flujo y el diseño de solo codificador frente a codificador-decodificador.
El documento explora más sobre el preentrenamiento de modelos VLP, categorizándolos en tipos de completado, coincidencia y particulares. Estos objetivos son importantes ya que ayudan a definir representaciones universales de visión-idioma. Los investigadores luego brindan una descripción general de las dos principales categorías de preentrenamiento de conjuntos de datos, modelos de lenguaje de imagen y modelos de lenguaje de video. El documento enfatiza cómo el enfoque multimodal ayuda a lograr una mejor comprensión y precisión en términos de comprensión del contexto y producción de contenido mejor mapeado. Por último, el artículo presenta los objetivos y detalles de las tareas secundarias en VLP, enfatizando su importancia en la evaluación de la efectividad de los modelos preentrenados.
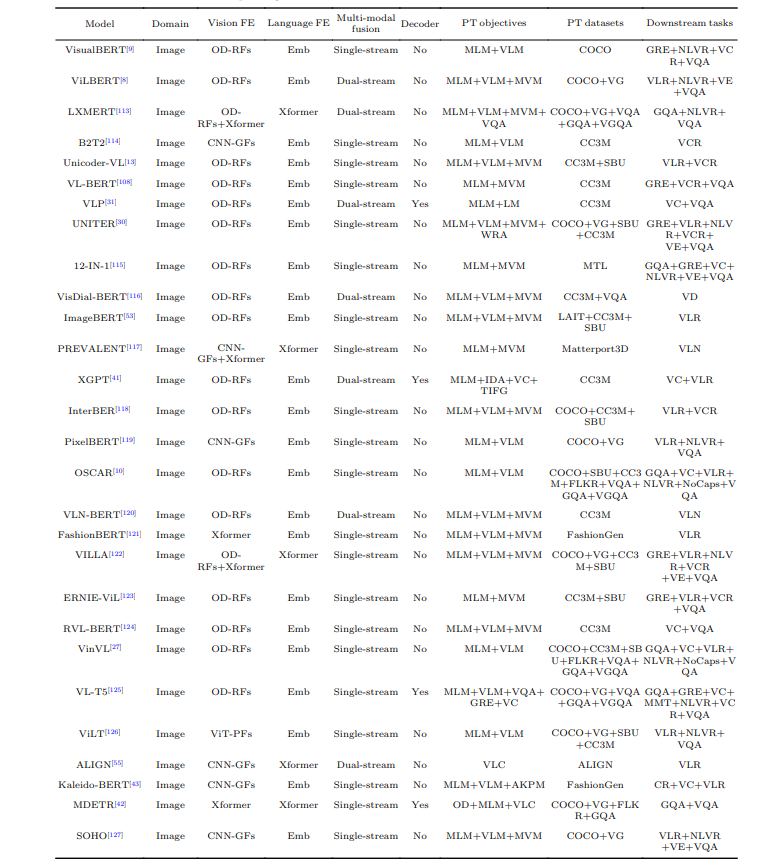
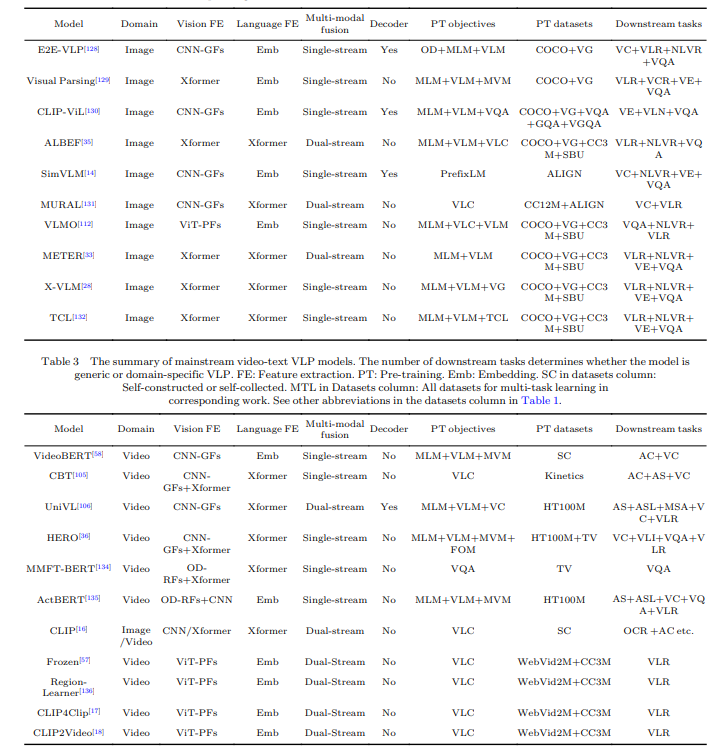
El artículo proporciona una descripción detallada de los modelos de VLP SOTA. Enumera dichos modelos y destaca sus características clave y rendimiento. Los modelos mencionados y cubiertos son una base sólida para el avance tecnológico de vanguardia y pueden servir como referencia para el desarrollo futuro.
Según el artículo de investigación, el futuro de la arquitectura de VLP parece prometedor y confiable. Han propuesto varias áreas de mejora, como la incorporación de información acústica, el aprendizaje cognitivo y conocedor, la sintonización rápida, la compresión y aceleración del modelo y el preentrenamiento fuera del dominio. Estas áreas de mejora están destinadas a inspirar a la nueva era de investigadores a avanzar en el campo de VLP y a presentar enfoques innovadores.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Conoce BITE Un Nuevo Método Que Reconstruye la Forma y Poses 3D de un Perro a Partir de una Imagen, Incluso con Poses Desafiantes como Sentado y Acostado.
- Conoce Paella Un Nuevo Modelo de IA Similar a Difusión que Puede Generar Imágenes de Alta Calidad Mucho Más Rápido que Usando Difusión Estable.
- Usando ChatGPT para Debugging Eficiente
- Científicos mejoran la detección de delirio utilizando Inteligencia Artificial y electroencefalogramas de respuesta rápida.
- Cómo Light & Wonder construyó una solución de mantenimiento predictivo para máquinas de juego en AWS.
- Revolucionando el descubrimiento de medicamentos modelo de aprendizaje automático identifica compuestos potenciales antienvejecimiento y allana el camino para futuros tratamientos de enfermedades complejas.
- De Sonido a Vista Conoce AudioToken para la Síntesis de Audio a Imagen.