Modelos del Codificador-Decodificador basados en Transformadores
'Encoder-Decoder Models based on Transformers'
![]()
!pip install transformers==4.2.1
!pip install sentencepiece==0.1.95El modelo codificador-decodificador basado en transformadores fue introducido por Vaswani et al. en el famoso artículo Attention is all you need y hoy en día es la arquitectura codificador-decodificador estándar de facto en el procesamiento del lenguaje natural (NLP, por sus siglas en inglés).
Recientemente, ha habido mucha investigación sobre diferentes objetivos de pre-entrenamiento para modelos codificador-decodificador basados en transformadores, como T5, Bart, Pegasus, ProphetNet, Marge, etc. …, pero la arquitectura del modelo ha permanecido en gran parte igual.
El objetivo de la publicación del blog es dar una explicación detallada de cómo los modelos de arquitectura codificador-decodificador basados en transformadores resuelven problemas de secuencia a secuencia. Nos enfocaremos en el modelo matemático definido por la arquitectura y cómo se puede utilizar el modelo en la inferencia. En el camino, daremos algunos antecedentes sobre los modelos de secuencia a secuencia en NLP y desglosaremos la arquitectura codificador-decodificador basada en transformadores en sus partes de codificador y decodificador. Proporcionaremos muchas ilustraciones y estableceremos el vínculo entre la teoría de los modelos codificador-decodificador basados en transformadores y su uso práctico en 🤗Transformers para inferencia. Tenga en cuenta que esta publicación de blog no explica cómo se pueden entrenar tales modelos, esto será tema de una futura publicación de blog.
- Portando el sistema de traducción fairseq wmt19 a transformers
- Aprovechando los puntos de control de modelos de lenguaje pre-entrenados para modelos codificador-decodificador.
- Cómo aceleramos la inferencia del transformador 100 veces para los clientes de la API de 🤗
Los modelos codificador-decodificador basados en transformadores son el resultado de años de investigación en aprendizaje de representaciones y arquitecturas de modelos. Este cuaderno proporciona un breve resumen de la historia de los modelos codificador-decodificador neuronales. Para obtener más contexto, se recomienda al lector leer esta increíble publicación de blog de Sebastion Ruder. Además, se recomienda tener una comprensión básica de la arquitectura de autoatención. La siguiente publicación de blog de Jay Alammar sirve como un buen repaso del modelo Transformer original aquí.
En el momento de escribir este cuaderno, 🤗Transformers incluye los modelos codificador-decodificador T5, Bart, MarianMT y Pegasus, que se resumen en la documentación bajo resúmenes de modelos.
El cuaderno se divide en cuatro partes:
- Antecedentes: Se presenta una breve historia de los modelos codificador-decodificador neuronales con un enfoque en los modelos basados en RNN.
- Codificador-Decodificador: Se presenta el modelo codificador-decodificador basado en transformadores y se explica cómo se utiliza el modelo para inferencia.
- Codificador: Se explica en detalle la parte del codificador del modelo.
- Decodificador: Se explica en detalle la parte del decodificador del modelo.
Cada parte se basa en la parte anterior, pero también se puede leer por separado.
Antecedentes
Las tareas de generación de lenguaje natural (NLG, por sus siglas en inglés), un subcampo de NLP, se expresan mejor como problemas de secuencia a secuencia. Estas tareas se pueden definir como encontrar un modelo que mapea una secuencia de palabras de entrada a una secuencia de palabras objetivo. Algunos ejemplos clásicos son la sumarización y la traducción. A continuación, asumimos que cada palabra se codifica en una representación vectorial. n palabras de entrada se pueden representar como una secuencia de n vectores de entrada:
X 1 : n = { x 1 , … , x n } . \mathbf{X}_{1:n} = \{\mathbf{x}_1, \ldots, \mathbf{x}_n\}. X 1 : n = { x 1 , … , x n } .
Consecuentemente, los problemas de secuencia a secuencia se pueden resolver encontrando una función de mapeo f f f desde una secuencia de entrada de n vectores X 1 : n \mathbf{X}_{1:n} X 1 : n a una secuencia de m vectores objetivo Y 1 : m \mathbf{Y}_{1:m} Y 1 : m , donde el número de vectores objetivo m m m es desconocido de antemano y depende de la secuencia de entrada:
- f : X 1 : n → Y 1 : m . f: \mathbf{X}_{1:n} \to \mathbf{Y}_{1:m}. f
- X 1 : n → Y 1 : m .
Sutskever et al. (2014) señalaron que las redes neuronales profundas, “*a pesar de su flexibilidad y poder, solo pueden definir un mapeo cuyas entradas y objetivos se puedan codificar de manera sensata con vectores de dimensionalidad fija.*” 1 {}^1 1
Usar un modelo DNN 2 {}^2 2 para resolver problemas de secuencia a secuencia significaría que el número de vectores objetivo m m m tendría que ser conocido de antemano y tendría que ser independiente de la entrada X 1 : n \mathbf{X}_{1:n} X 1 : n . Esto es subóptimo porque, para tareas en NLG, el número de palabras objetivo generalmente depende de la entrada X 1 : n \mathbf{X}_{1:n} X 1 : n y no solo de la longitud de la entrada n n n . Por ejemplo, un artículo de 1000 palabras se puede resumir tanto a 200 palabras como a 100 palabras dependiendo de su contenido.
En 2014, Cho et al. y Sutskever et al. propusieron usar un modelo codificador-decodificador basado puramente en redes neuronales recurrentes (RNNs) para tareas de secuencia a secuencia. A diferencia de los DNNs, las RNNs son capaces de modelar una asignación a un número variable de vectores objetivo. Ahondemos un poco más en el funcionamiento de los modelos codificador-decodificador basados en RNNs.
En la inferencia, la RNN codificadora codifica una secuencia de entrada X 1 : n \mathbf{X}_{1:n} X 1 : n actualizando su estado oculto 3 {}^3 3 sucesivamente. Después de procesar el último vector de entrada x n \mathbf{x}_n x n , el estado oculto del codificador define la codificación de la entrada c \mathbf{c} c . Por lo tanto, el codificador define la asignación:
f θ e n c : X 1 : n → c . f_{\theta_{enc}}: \mathbf{X}_{1:n} \to \mathbf{c}. f θ e n c : X 1 : n → c .
Luego, el estado oculto del decodificador se inicializa con la codificación de entrada y durante la inferencia, la RNN del decodificador se utiliza para generar de manera auto-regresiva la secuencia objetivo. Explicaremos esto.
Matemáticamente, el decodificador define la distribución de probabilidad de una secuencia objetivo Y 1 : m \mathbf{Y}_{1:m} Y 1 : m dado el estado oculto c \mathbf{c} c :
p θ d e c ( Y 1 : m ∣ c ) . p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c}). p θ d e c ( Y 1 : m ∣ c ) .
Usando la regla de Bayes, la distribución se puede descomponer en distribuciones condicionales de vectores objetivo individuales de la siguiente manera:
p θ d e c ( Y 1 : m ∣ c ) = ∏ i = 1 m p θ dec ( y i ∣ Y 0 : i − 1 , c ) . p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c}) = \prod_{i=1}^{m} p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}). p θ d e c ( Y 1 : m ∣ c ) = i = 1 ∏ m p θ dec ( y i ∣ Y 0 : i − 1 , c ) .
Por lo tanto, si la arquitectura puede modelar la distribución condicional del siguiente vector objetivo, dado todos los vectores objetivo anteriores:
p θ dec ( y i ∣ Y 0 : i − 1 , c ) , ∀ i ∈ { 1 , … , m } , p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}), \forall i \in \{1, \ldots, m\}, p θ dec ( y i ∣ Y 0 : i − 1 , c ) , ∀ i ∈ { 1 , … , m } ,
entonces puede modelar la distribución de cualquier secuencia de vectores objetivo dada el estado oculto c \mathbf{c} c simplemente multiplicando todas las probabilidades condicionales.
- Entonces, ¿cómo modela la arquitectura del decodificador basado en RNN p θ dec ( y i ∣ Y 0
- : i − 1 , c ) p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}) p θ dec ( y i ∣ Y 0 : i − 1 , c ) ?
En términos computacionales, el modelo mapea secuencialmente el estado oculto interno anterior c i − 1 \mathbf{c}_{i-1} c i − 1 y el vector objetivo anterior y i − 1 \mathbf{y}_{i-1} y i − 1 al estado oculto interno actual c i \mathbf{c}_i c i y a un vector de logitos l i \mathbf{l}_i l i (mostrado en rojo oscuro abajo):
f θ dec ( y i − 1 , c i − 1 ) → l i , c i . f_{\theta_{\text{dec}}}(\mathbf{y}_{i-1}, \mathbf{c}_{i-1}) \to \mathbf{l}_i, \mathbf{c}_i. f θ dec ( y i − 1 , c i − 1 ) → l i , c i . c 0 \mathbf{c}_0 c 0 se define como c \mathbf{c} c siendo el estado oculto de salida del codificador basado en RNN. Posteriormente, se utiliza la operación softmax para transformar el vector de logitos l i \mathbf{l}_i l i en una distribución de probabilidad condicional del próximo vector objetivo:
p ( y i ∣ l i ) = Softmax ( l i ) , con l i = f θ dec ( y i − 1 , c prev ) . p(\mathbf{y}_i | \mathbf{l}_i) = \textbf{Softmax}(\mathbf{l}_i), \text{ con } \mathbf{l}_i = f_{\theta_{\text{dec}}}(\mathbf{y}_{i-1}, \mathbf{c}_{\text{prev}}). p ( y i ∣ l i ) = Softmax ( l i ) , con l i = f θ dec ( y i − 1 , c prev ) .
Para más detalles sobre el vector de logitos y la distribución de probabilidad resultante, consulte la nota al pie 4 {}^4 4 . A partir de la ecuación anterior, se puede ver que la distribución del vector objetivo actual y i \mathbf{y}_i y i está directamente condicionada por el vector objetivo anterior y i − 1 \mathbf{y}_{i-1} y i − 1 y el estado oculto anterior c i − 1 \mathbf{c}_{i-1} c i − 1 . Debido a que el estado oculto anterior c i − 1 \mathbf{c}_{i-1} c i − 1 depende de todos los vectores objetivo anteriores y 0 , … , y i − 2 \mathbf{y}_0, \ldots, \mathbf{y}_{i-2} y 0 , … , y i − 2 , se puede afirmar que el decodificador basado en RNN modela implícitamente (por ejemplo, indirectamente) la distribución condicional p θ dec ( y i ∣ Y 0 : i − 1 , c ) p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}) p θ dec ( y i ∣ Y 0 : i − 1 , c ) .
El espacio de posibles secuencias de vectores objetivo Y 1 : m \mathbf{Y}_{1:m} Y 1 : m es prohibitivamente grande, por lo que en la inferencia, uno debe confiar en métodos de decodificación 5 {}^5 5 que muestren eficientemente secuencias de vectores objetivo de alta probabilidad de p θ d e c ( Y 1 : m ∣ c ) p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c}) p θ d e c ( Y 1 : m ∣ c ) .
Dado dicho método de decodificación, durante la inferencia, el siguiente vector de entrada y i \mathbf{y}_i y i se puede muestrear de p θ dec ( y i ∣ Y 0 : i − 1 , c ) p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}) p θ dec ( y i ∣ Y 0 : i − 1 , c ) y se agrega consecuentemente a la secuencia de entrada para que el RNN del decodificador modele p θ dec ( y i + 1 ∣ Y 0 : i , c ) p_{\theta_{\text{dec}}}(\mathbf{y}_{i+1} | \mathbf{Y}_{0: i}, \mathbf{c}) p θ dec ( y i + 1 ∣ Y 0 : i , c ) para muestrear el siguiente vector de entrada y i + 1 \mathbf{y}_{i+1} y i + 1 y así sucesivamente de manera auto-regresiva.
Una característica importante de los modelos codificador-decodificador basados en RNN es la definición de vectores especiales, como el vector EOS \text{EOS} EOS y el vector BOS \text{BOS} BOS. El vector EOS \text{EOS} EOS representa a menudo el vector de entrada final x n \mathbf{x}_n x n para “indicar” al codificador que la secuencia de entrada ha terminado y también define el final de la secuencia objetivo. Tan pronto como el EOS \text{EOS} EOS se muestrea de un vector de logits, la generación está completa. El vector BOS \text{BOS} BOS representa el vector de entrada y 0 \mathbf{y}_0 y 0 que se alimenta al RNN del decodificador en el primer paso de decodificación. Para generar el primer logit l 1 \mathbf{l}_1 l 1 , se requiere una entrada y como no se ha generado ninguna entrada en el primer paso, se alimenta al RNN del decodificador un vector de entrada especial BOS \text{BOS} BOS. ¡Ok, bastante complicado! Vamos a ilustrar y pasar por un ejemplo.
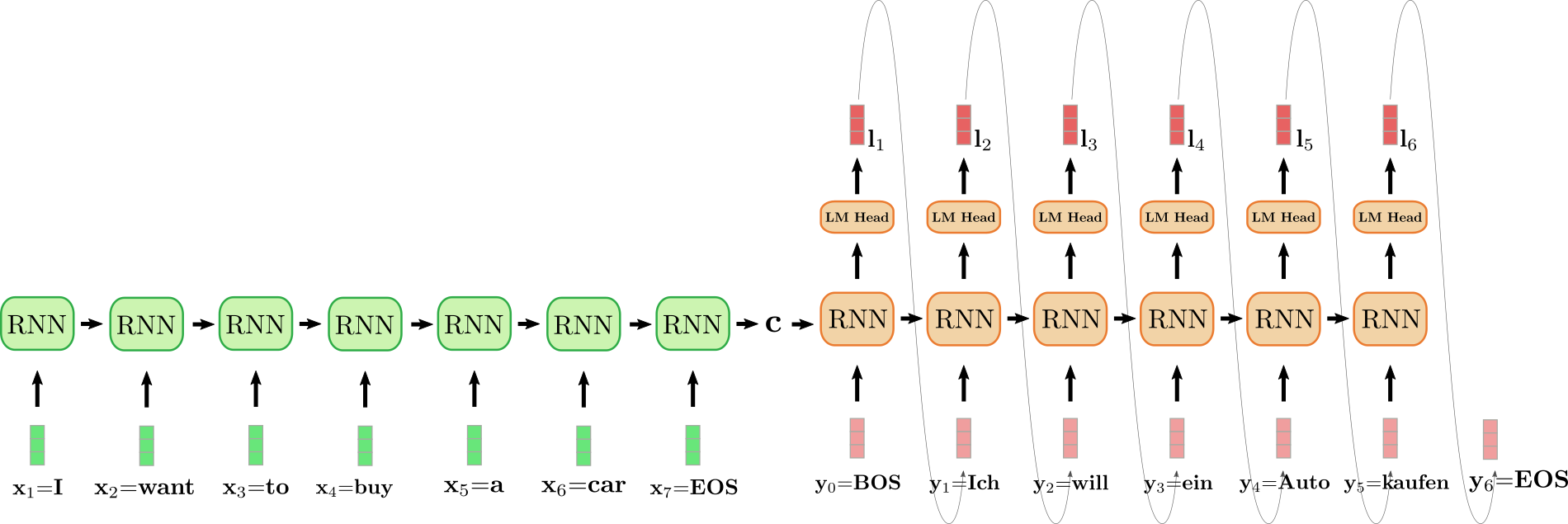
El codificador RNN desplegado está coloreado en verde y el decodificador RNN desplegado está coloreado en rojo.
La frase en inglés “I want to buy a car” (“Quiero comprar un coche”), representada por x 1 = I \mathbf{x}_1 = \text{I} x 1 = I , x 2 = want \mathbf{x}_2 = \text{want} x 2 = want , x 3 = to \mathbf{x}_3 = \text{to} x 3 = to , x 4 = buy \mathbf{x}_4 = \text{buy} x 4 = buy , x 5 = a \mathbf{x}_5 = \text{a} x 5 = a , x 6 = car \mathbf{x}_6 = \text{car} x 6 = car y x 7 = EOS \mathbf{x}_7 = \text{EOS} x 7 = EOS se traduce al alemán como “Ich will ein Auto kaufen” (“Quiero comprar un coche”) y se define como y 0 = BOS \mathbf{y}_0 = \text{BOS} y 0 = BOS , y 1 = Ich \mathbf{y}_1 = \text{Ich} y 1 = Ich , y 2 = will \mathbf{y}_2 = \text{will} y 2 = will , y 3 = ein \mathbf{y}_3 = \text{ein} y 3 = ein , y 4 = Auto , y 5 = kaufen \mathbf{y}_4 = \text{Auto}, \mathbf{y}_5 = \text{kaufen} y 4 = Auto , y 5 = kaufen y y 6 = EOS \mathbf{y}_6 = \text{EOS} y 6 = EOS . Para comenzar, el vector de entrada x 1 = I \mathbf{x}_1 = \text{I} x 1 = I es procesado por el RNN del codificador y actualiza su estado oculto. Hay que tener en cuenta que, dado que solo nos interesa el estado oculto final del codificador c \mathbf{c} c , podemos ignorar el vector objetivo del RNN del codificador. Luego, el RNN del codificador procesa el resto de la frase de entrada want \text{want} want , to \text{to} to , buy \text{buy} buy , a \text{a} a , car \text{car} car , EOS \text{EOS} EOS de la misma manera, actualizando su estado oculto en cada paso hasta que se alcanza el vector x 7 = E O S \mathbf{x}_7={EOS} x 7 = E O S 6 {}^6 6 . En la ilustración anterior, la flecha horizontal que conecta el RNN del codificador desplegado representa las actualizaciones secuenciales del estado oculto. El estado oculto final del RNN del codificador, representado por c \mathbf{c} c , luego define completamente la codificación de la secuencia de entrada y se utiliza como el estado oculto inicial del RNN del decodificador. Esto se puede ver como la condición del RNN del decodificador en la entrada codificada.
Para generar el primer vector objetivo, al decodificador se le alimenta el vector BOS \text{BOS} BOS, ilustrado como y 0 \mathbf{y}_0 y 0 en el diseño anterior. Luego, el vector objetivo del RNN se asigna al vector de logits l 1 \mathbf{l}_1 l 1 a través de la capa de alimentación hacia adelante de la cabeza del LM para definir la distribución condicional del primer vector objetivo, como se explicó anteriormente:
p θ d e c ( y ∣ BOS , c ) . p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \mathbf{c}). p θ d e c ( y ∣ BOS , c ) .
La palabra Ich \text{Ich} Ich se selecciona al azar (se muestra mediante la flecha gris, conectando l 1 \mathbf{l}_1 l 1 y y 1 \mathbf{y}_1 y 1 ) y, en consecuencia, se puede seleccionar el segundo vector objetivo:
will ∼ p θ d e c ( y ∣ BOS , Ich , c ) . \text{will} \sim p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \text{Ich}, \mathbf{c}). will ∼ p θ d e c ( y ∣ BOS , Ich , c ) .
Y así sucesivamente hasta que en el paso i = 6 i=6 i = 6 , se selecciona el vector EOS \text{EOS} EOS a partir de l 6 \mathbf{l}_6 l 6 y se finaliza la decodificación. La secuencia objetivo resultante es Y 1 : 6 = { y 1 , … , y 6 } \mathbf{Y}_{1:6} = \{\mathbf{y}_1, \ldots, \mathbf{y}_6\} Y 1 : 6 = { y 1 , … , y 6 } , que en nuestro ejemplo anterior es “Ich will ein Auto kaufen”.
En resumen, un modelo codificador-decodificador basado en RNN, representado por f θ enc f_{\theta_{\text{enc}}} f θ enc y p θ dec p_{\theta_{\text{dec}}} p θ dec define la distribución p ( Y 1 : m ∣ X 1 : n ) p(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n}) p ( Y 1 : m ∣ X 1 : n ) mediante factorización:
p θ enc , θ dec ( Y 1 : m ∣ X 1 : n ) = ∏ i = 1 m p θ enc , θ dec ( y i ∣ Y 0 : i − 1 , X 1 : n ) = ∏ i = 1 m p θ dec ( y i ∣ Y 0 : i − 1 , c ) , con c = f θ e n c ( X ) . p_{\theta_{\text{enc}}, \theta_{\text{dec}}}(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{\text{enc}}, \theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{X}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}), \text{ con } \mathbf{c}=f_{\theta_{enc}}(X). p θ enc , θ dec ( Y 1 : m ∣ X 1 : n ) = i = 1 ∏ m p θ enc , θ dec ( y i ∣ Y 0 : i − 1 , X 1 : n ) = i = 1 ∏ m p θ dec ( y i ∣ Y 0 : i − 1 , c ) , con c = f θ e n c ( X ) .
Durante la inferencia, se pueden generar de forma auto-regresiva métodos eficientes de decodificación para la secuencia objetivo Y 1 : m \mathbf{Y}_{1:m} Y 1 : m .
El modelo codificador-decodificador basado en RNN sorprendió a la comunidad de NLG. En 2016, Google anunció que sustituiría por completo su servicio de traducción altamente diseñado por características mediante un único modelo codificador-decodificador basado en RNN (ver aquí ).
No obstante, los modelos codificador-decodificador basados en RNN tienen dos problemas. En primer lugar, las RNN sufren el problema del gradiente desvaneciente, lo que hace muy difícil capturar dependencias a largo plazo, cf. Hochreiter et al. (2001) . En segundo lugar, la arquitectura recurrente inherente de las RNN impide la paralelización eficiente durante la codificación, cf. Vaswani et al. (2017) .
1 {}^1 1 La cita original del artículo es “A pesar de su flexibilidad y poder, las DNN solo se pueden aplicar a problemas cuyas entradas y objetivos se pueden codificar de manera sensata con vectores de dimensionalidad fija”, la cual se adapta ligeramente aquí.
2 {}^2 2 Lo mismo es esencialmente cierto para las redes neuronales convolucionales (CNN). Si bien una secuencia de entrada de longitud variable se puede alimentar a una CNN, la dimensionalidad del objetivo siempre dependerá de la dimensionalidad de la entrada o se fijará en un valor específico.
3 {}^3 3 En el primer paso, el estado oculto se inicializa como un vector cero y se alimenta a la RNN junto con el primer vector de entrada x 1 \mathbf{x}_1 x 1 .
4 {}^4 4 Una red neuronal puede definir una distribución de probabilidad sobre todas las palabras, es decir, p ( y ∣ c , Y 0 : i − 1 ) p(\mathbf{y} | \mathbf{c}, \mathbf{Y}_{0: i-1}) p ( y ∣ c , Y 0 : i − 1 ) de la siguiente manera. Primero, la red define una asignación de las entradas c , Y 0 : i − 1 \mathbf{c}, \mathbf{Y}_{0: i-1} c , Y 0 : i − 1 a una representación vectorial incrustada y ′ \mathbf{y’} y ′ , que corresponde al vector objetivo de la RNN. La representación vectorial incrustada y ′ \mathbf{y’} y ′ se pasa entonces a la capa “modelo de lenguaje”, lo que significa que se multiplica por la matriz de incrustación de palabras , es decir, Y vocab \mathbf{Y}^{\text{vocab}} Y vocab , de modo que se calcula una puntuación entre y ′ \mathbf{y’} y ′ y cada vector codificado y ∈ Y vocab \mathbf{y} \in \mathbf{Y}^{\text{vocab}} y ∈ Y vocab . El vector resultante se llama vector de logit l = Y vocab y ′ \mathbf{l} = \mathbf{Y}^{\text{vocab}} \mathbf{y’} l = Y vocab y ′ y se puede asignar a una distribución de probabilidad sobre todas las palabras aplicando una operación softmax: p ( y ∣ c ) = Softmax ( Y vocab y ′ ) = Softmax ( l ) p(\mathbf{y} | \mathbf{c}) = \text{Softmax}(\mathbf{Y}^{\text{vocab}} \mathbf{y’}) = \text{Softmax}(\mathbf{l}) p ( y ∣ c ) = Softmax ( Y vocab y ′ ) = Softmax ( l ) .
5 {}^5 5 La decodificación de búsqueda en haz (beam-search) es un ejemplo de este tipo de método de decodificación. Otros métodos de decodificación están fuera del alcance de este cuaderno. Se recomienda al lector que consulte este cuaderno interactivo sobre los métodos de decodificación.
6 {}^6 6 Sutskever et al. (2014) invierte el orden de la entrada para que, en el ejemplo anterior, los vectores de entrada correspondan a x 1 = car \mathbf{x}_1 = \text{car} x 1 = car , x 2 = a \mathbf{x}_2 = \text{a} x 2 = a , x 3 = buy \mathbf{x}_3 = \text{buy} x 3 = buy , x 4 = to \mathbf{x}_4 = \text{to} x 4 = to , x 5 = want \mathbf{x}_5 = \text{want} x 5 = want , x 6 = I \mathbf{x}_6 = \text{I} x 6 = I y x 7 = EOS \mathbf{x}_7 = \text{EOS} x 7 = EOS . La motivación es permitir una conexión más corta entre los pares de palabras correspondientes, como x 6 = I \mathbf{x}_6 = \text{I} x 6 = I y y 1 = Ich \mathbf{y}_1 = \text{Ich} y 1 = Ich . El grupo de investigación enfatiza que la inversión de la secuencia de entrada fue una razón clave para el mejor rendimiento de su modelo en la traducción automática.
Codificador-Decodificador
En 2017, Vaswani et al. introdujeron el Transformer y así dieron origen a los modelos codificador-decodificador basados en transformadores.
Análogo a los modelos de codificador-decodificador basados en RNN, los modelos de codificador-decodificador basados en transformer consisten en un codificador y un decodificador que son ambos pilas de bloques de atención residual. La innovación clave de los modelos de codificador-decodificador basados en transformer es que dichos bloques de atención residual pueden procesar una secuencia de entrada X 1 : n de longitud variable sin mostrar una estructura recurrente. No depender de una estructura recurrente permite que los codificadores-decodificadores basados en transformer sean altamente paralelizables, lo que hace que el modelo sea ordenes de magnitud más eficiente computacionalmente que los modelos de codificador-decodificador basados en RNN en hardware moderno.
Como recordatorio, para resolver un problema de secuencia a secuencia, necesitamos encontrar una asignación de una secuencia de entrada X 1 : n a una secuencia de salida Y 1 : m de longitud variable. Veamos cómo se utilizan los modelos de codificador-decodificador basados en transformer para encontrar dicha asignación.
Similar a los modelos de codificador-decodificador basados en RNN, los modelos de codificador-decodificador basados en transformer definen una distribución condicional de vectores objetivo Y 1 : m dados una secuencia de entrada X 1 : n:
p θ enc , θ dec ( Y 1 : m ∣ X 1 : n ) .
La parte del codificador basado en transformer codifica la secuencia de entrada X 1 : n a una secuencia de estados ocultos X ‾ 1 : n, definiendo así la asignación:
f θ enc: X 1 : n → X ‾ 1 : n.
Luego, la parte del decodificador basado en transformer modela la distribución de probabilidad condicional de la secuencia de vectores objetivo Y 1 : n dada la secuencia de estados ocultos codificados X ‾ 1 : n:
p θ dec ( Y 1 : n ∣ X ‾ 1 : n ) .
Por la regla de Bayes, esta distribución se puede factorizar en un producto de distribuciones de probabilidad condicionales del vector objetivo y i dado los estados ocultos codificados X ‾ 1 : n y todos los vectores objetivo anteriores Y 0 : i − 1:
p θ dec ( Y 1 : n ∣ X ‾ 1 : n ) = ∏ i = 1 n p θ dec ( y i ∣ Y 0 : i − 1 , X ‾ 1 : n ) .
El decodificador basado en transformadores mapea la secuencia de estados ocultos codificados X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n y todos los vectores objetivo anteriores Y 0 : i − 1 \mathbf{Y}_{0:i-1} Y 0 : i − 1 al vector logit l i \mathbf{l}_i l i . Luego, el vector logit l i \mathbf{l}_i l i se procesa mediante la operación softmax para definir la distribución condicional p θ dec ( y i ∣ Y 0 : i − 1 , X ‾ 1 : n ) p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}) p θ dec ( y i ∣ Y 0 : i − 1 , X 1 : n ) , al igual que se hace para los decodificadores basados en RNN. Sin embargo, a diferencia de los decodificadores basados en RNN, la distribución del vector objetivo y i \mathbf{y}_i y i está explícitamente (o directamente) condicionada a todos los vectores objetivo anteriores y 0 , … , y i − 1 \mathbf{y}_0, \ldots, \mathbf{y}_{i-1} y 0 , … , y i − 1 como veremos más adelante en más detalle. El vector objetivo y 0 \mathbf{y}_0 y 0 está representado aquí por un vector especial “begin-of-sentence” BOS \text{BOS} BOS.
Habiendo definido la distribución condicional p θ dec ( y i ∣ Y 0 : i − 1 , X ‾ 1 : n ) p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}) p θ dec ( y i ∣ Y 0 : i − 1 , X 1 : n ) , ahora podemos generar de manera auto-regresiva la salida y así definir una asignación de una secuencia de entrada X 1 : n \mathbf{X}_{1:n} X 1 : n a una secuencia de salida Y 1 : m \mathbf{Y}_{1:m} Y 1 : m durante la inferencia.
Visualicemos el proceso completo de generación auto-regresiva de modelos de codificador-decodificador basados en transformadores.
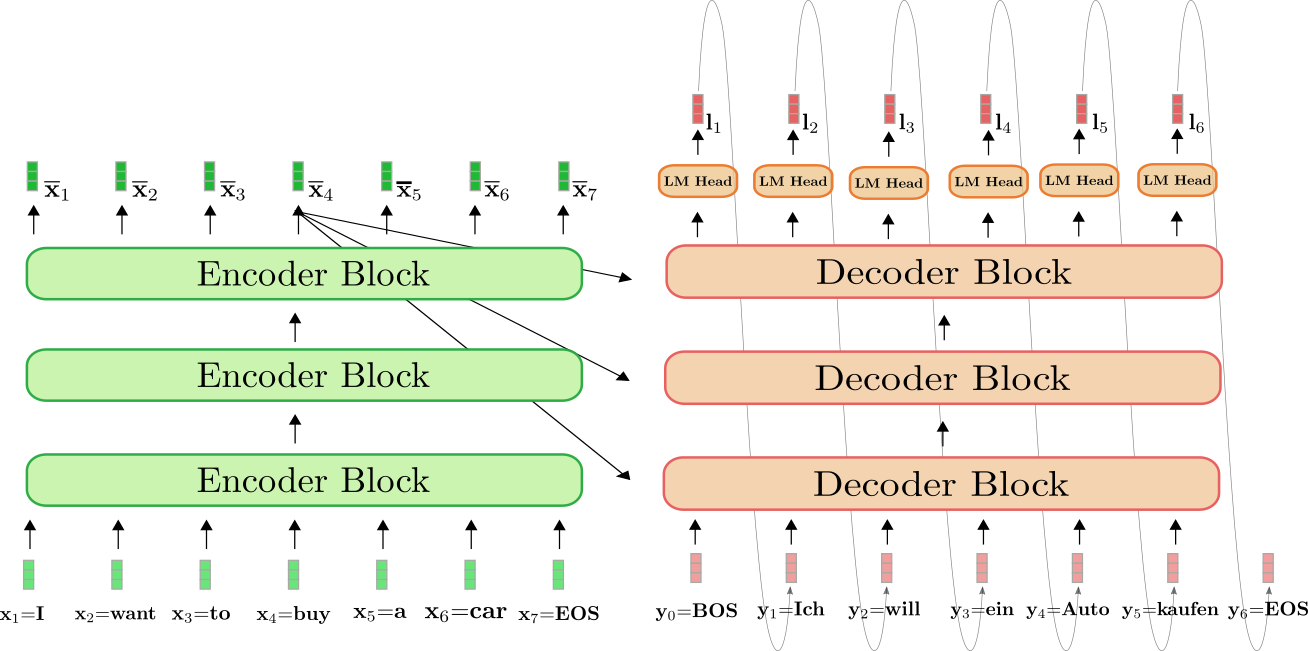
El codificador basado en transformadores está coloreado en verde y el decodificador basado en transformadores está coloreado en rojo. Como en la sección anterior, mostramos cómo se traduce la oración en inglés “I want to buy a car”, representada por x 1 = I \mathbf{x}_1 = \text{I} x 1 = I , x 2 = want \mathbf{x}_2 = \text{want} x 2 = want , x 3 = to \mathbf{x}_3 = \text{to} x 3 = to , x 4 = buy \mathbf{x}_4 = \text{buy} x 4 = buy , x 5 = a \mathbf{x}_5 = \text{a} x 5 = a , x 6 = car \mathbf{x}_6 = \text{car} x 6 = car , y x 7 = EOS \mathbf{x}_7 = \text{EOS} x 7 = EOS al alemán: “Ich will ein Auto kaufen” definido como y 0 = BOS \mathbf{y}_0 = \text{BOS} y 0 = BOS , y 1 = Ich \mathbf{y}_1 = \text{Ich} y 1 = Ich , y 2 = will \mathbf{y}_2 = \text{will} y 2 = will , y 3 = ein \mathbf{y}_3 = \text{ein} y 3 = ein , y 4 = Auto , y 5 = kaufen \mathbf{y}_4 = \text{Auto}, \mathbf{y}_5 = \text{kaufen} y 4 = Auto , y 5 = kaufen , y y 6 = EOS \mathbf{y}_6=\text{EOS} y 6 = EOS .
Para empezar, el codificador procesa la secuencia completa de entrada X 1 : 7 \mathbf{X}_{1:7} X 1 : 7 = “Quiero comprar un coche” (representada por los vectores de color verde claro) a una secuencia codificada contextualizada X ‾ 1 : 7 \mathbf{\overline{X}}_{1:7} X 1 : 7 . Por ejemplo, x ‾ 4 \mathbf{\overline{x}}_4 x 4 define una codificación que depende no solo de la entrada x 4 \mathbf{x}_4 x 4 = “comprar”, sino también de todas las demás palabras “Quiero”, “comprar”, “un”, “coche” y “EOS”, es decir, del contexto.
A continuación, la codificación de entrada X ‾ 1 : 7 \mathbf{\overline{X}}_{1:7} X 1 : 7 junto con el vector BOS, es decir, y 0 \mathbf{y}_0 y 0 , se alimenta al decodificador. El decodificador procesa las entradas X ‾ 1 : 7 \mathbf{\overline{X}}_{1:7} X 1 : 7 y y 0 \mathbf{y}_0 y 0 para obtener el primer logit l 1 \mathbf{l}_1 l 1 (mostrado en rojo oscuro) para definir la distribución condicional del primer vector objetivo y 1 \mathbf{y}_1 y 1 :
p θ e n c , d e c ( y ∣ y 0 , X 1 : 7 ) = p θ e n c , d e c ( y ∣ BOS , Quiero comprar un coche EOS ) = p θ d e c ( y ∣ BOS , X ‾ 1 : 7 ) . p_{\theta_{enc, dec}}(\mathbf{y} | \mathbf{y}_0, \mathbf{X}_{1:7}) = p_{\theta_{enc, dec}}(\mathbf{y} | \text{BOS}, \text{Quiero comprar un coche EOS}) = p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \mathbf{\overline{X}}_{1:7}). p θ e n c , d e c ( y ∣ y 0 , X 1 : 7 ) = p θ e n c , d e c ( y ∣ BOS , Quiero comprar un coche EOS ) = p θ d e c ( y ∣ BOS , X 1 : 7 ) .
A continuación, el primer vector objetivo y 1 \mathbf{y}_1 y 1 = Ich \text{Ich} Ich se obtiene de la distribución (representada por las flechas grises) y ahora se puede alimentar nuevamente al decodificador. El decodificador ahora procesa tanto y 0 \mathbf{y}_0 y 0 = “BOS” como y 1 \mathbf{y}_1 y 1 = “Ich” para definir la distribución condicional del segundo vector objetivo y 2 \mathbf{y}_2 y 2 :
p θ d e c ( y ∣ BOS Ich , X ‾ 1 : 7 ) . p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich}, \mathbf{\overline{X}}_{1:7}). p θ d e c ( y ∣ BOS Ich , X 1 : 7 ) .
Podemos muestrear nuevamente y obtener el vector objetivo y 2 \mathbf{y}_2 y 2 = “will”. Continuamos de manera auto-regresiva hasta que en el paso 6 se muestrea el vector EOS de la distribución condicional:
EOS ∼ p θ d e c ( y ∣ BOS Ich will ein Auto kaufen , X ‾ 1 : 7 ) . \text{EOS} \sim p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich will ein Auto kaufen}, \mathbf{\overline{X}}_{1:7}). EOS ∼ p θ d e c ( y ∣ BOS Ich will ein Auto kaufen , X 1 : 7 ) .
Y así sucesivamente en forma auto-regresiva.
Es importante entender que el codificador solo se utiliza en el primer pase hacia adelante para mapear X 1 : n \mathbf{X}_{1:n} X 1 : n a X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n . A partir del segundo pase hacia adelante, el decodificador puede hacer uso directamente de la codificación calculada previamente X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n . Para mayor claridad, ilustremos el primer y el segundo pase hacia adelante para nuestro ejemplo anterior.
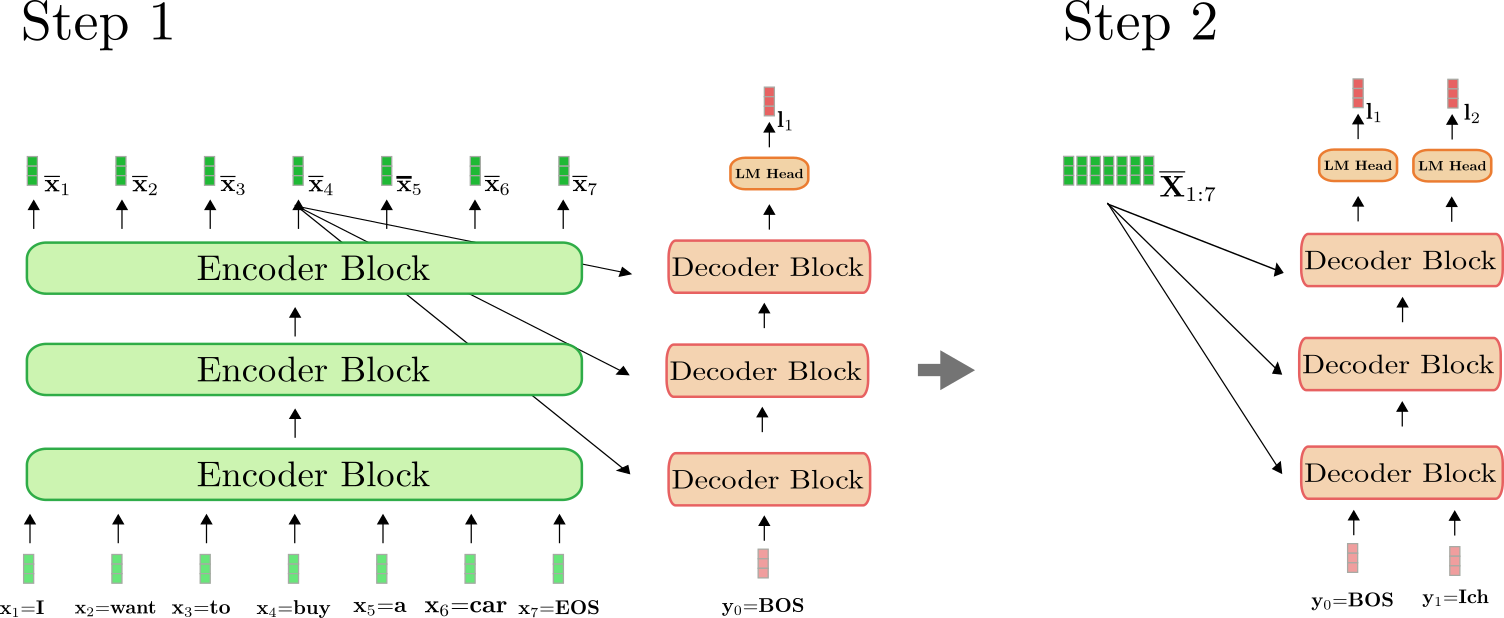
Como se puede ver, solo en el paso i = 1 i=1 i = 1 tenemos que codificar “Quiero comprar un auto EOS” a X ‾ 1 : 7 \mathbf{\overline{X}}_{1:7} X 1 : 7 . En el paso i = 2 i=2 i = 2 , las codificaciones contextualizadas de “Quiero comprar un auto EOS” simplemente son reutilizadas por el decodificador.
En 🤗Transformers, esta generación auto-regresiva se realiza automáticamente al llamar al método .generate(). Veamos esto en acción utilizando uno de nuestros modelos de traducción.
from transformers import MarianMTModel, MarianTokenizer
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
# crear ids de vectores de entrada codificados
input_ids = tokenizer("Quiero comprar un auto", return_tensors="pt").input_ids
# traducir ejemplo
output_ids = model.generate(input_ids)[0]
# decodificar e imprimir
print(tokenizer.decode(output_ids))Salida:
<pad> Ich will ein Auto kaufenLlamar a .generate() hace muchas cosas automáticamente. Primero, pasa los input_ids al codificador. Segundo, pasa un token predefinido, que es el símbolo <pad> \text{<pad>} <pad> en el caso de MarianMTModel, junto con los input_ids codificados al decodificador. Tercero, aplica el mecanismo de decodificación de búsqueda en haz para muestrear de forma auto-regresiva la siguiente palabra de salida de la última salida del decodificador 1 {}^1 1 . Para más detalles sobre cómo funciona la decodificación de búsqueda en haz, se recomienda leer esta publicación de blog.
En el Apéndice, hemos incluido un fragmento de código que muestra cómo se puede implementar un método de generación simple “desde cero”. Para comprender completamente cómo funciona la generación auto-regresiva automáticamente, se recomienda leer el Apéndice.
En resumen:
- El codificador basado en transformadores define una asignación desde la secuencia de entrada X 1 : n \mathbf{X}_{1:n} X 1 : n a una secuencia de codificación contextualizada X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n .
- El decodificador basado en transformadores define la distribución condicional p θ dec ( y i ∣ Y 0 : i − 1 , X ‾ 1 : n ) p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}) p θ dec ( y i ∣ Y 0 : i − 1 , X 1 : n ) .
- Dado un mecanismo de decodificación adecuado, la secuencia de salida Y 1 : m \mathbf{Y}_{1:m} Y 1 : m se puede muestrear de forma auto-regresiva a partir de p θ dec ( y i ∣ Y 0 : i − 1 , X ‾ 1 : n ) , ∀ i ∈ { 1 , … , m } p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}), \forall i \in \{1, \ldots, m\} p θ dec ( y i ∣ Y 0 : i − 1 , X 1 : n ) , ∀ i ∈ { 1 , … , m } .
Genial, ahora que hemos obtenido una visión general de cómo funcionan los modelos codificador-decodificador basados en transformadores, podemos profundizar en la parte del codificador y decodificador del modelo. Más específicamente, veremos exactamente cómo el codificador utiliza la capa de auto-atención para generar una secuencia de codificaciones vectoriales dependientes del contexto y cómo las capas de auto-atención permiten una paralelización eficiente. Luego, explicaremos en detalle cómo funciona la capa de auto-atención en el modelo decodificador y cómo el decodificador se condiciona a la salida del codificador con capas de atención cruzada para definir la distribución condicional p θ dec ( y i ∣ Y 0 : i − 1 , X ‾ 1 : n ) p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}) p θ dec ( y i ∣ Y 0 : i − 1 , X 1 : n ) . A lo largo del camino, se hará evidente cómo los modelos codificador-decodificador basados en transformadores resuelven el problema de las dependencias a largo plazo de los modelos codificador-decodificador basados en RNN.
1 {}^1 1 En el caso de "Helsinki-NLP/opus-mt-en-de", los parámetros de decodificación se pueden acceder aquí, donde podemos ver que el modelo aplica la búsqueda en haz con num_beams=6.
Codificador
Como se mencionó en la sección anterior, el codificador basado en transformadores mapea la secuencia de entrada a una secuencia de codificación contextualizada:
f θ enc : X 1 : n → X ‾ 1 : n . f_{\theta_{\text{enc}}}: \mathbf{X}_{1:n} \to \mathbf{\overline{X}}_{1:n}. f θ enc : X 1 : n → X 1 : n .
Al observar más de cerca la arquitectura, el codificador basado en transformadores es una pila de bloques de codificación residual. Cada bloque de codificación consta de una capa de auto-atención bidireccional, seguida de dos capas de alimentación directa. Para simplificar, no consideraremos las capas de normalización en este cuaderno. Además, no discutiremos más el papel de las dos capas de alimentación directa, sino que simplemente lo veremos como una transformación final de vector a vector requerida en cada bloque de codificación 1 {}^1 1 . La capa de auto-atención bidireccional relaciona cada vector de entrada x ′ j , ∀ j ∈ { 1 , … , n } \mathbf{x’}_j, \forall j \in \{1, \ldots, n\} x ′ j , ∀ j ∈ { 1 , … , n } con todos los vectores de entrada x ′ 1 , … , x ′ n \mathbf{x’}_1, \ldots, \mathbf{x’}_n x ′ 1 , … , x ′ n y, al hacerlo, transforma el vector de entrada x ′ j \mathbf{x’}_j x ′ j en una representación contextual más “refinada” de sí mismo, definida como x ′ ′ j \mathbf{x”}_j x ′ ′ j . De esta manera, el primer bloque de codificación transforma cada vector de entrada de la secuencia de entrada X 1 : n \mathbf{X}_{1:n} X 1 : n (mostrado en verde claro a continuación) de una representación vectorial independiente del contexto a una representación vectorial dependiente del contexto, y los siguientes bloques de codificación refinan aún más esta representación contextual hasta que el último bloque de codificación produce la codificación contextual final X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n (mostrado en verde oscuro a continuación).
Veamos cómo el codificador procesa la secuencia de entrada “Quiero comprar un coche EOS” a una secuencia de codificación contextualizada. Al igual que los codificadores basados en RNN, los codificadores basados en transformadores también agregan un vector de entrada especial “fin-de-secuencia” a la secuencia de entrada para indicar al modelo que la secuencia de vectores de entrada ha finalizado 2 {}^2 2 .
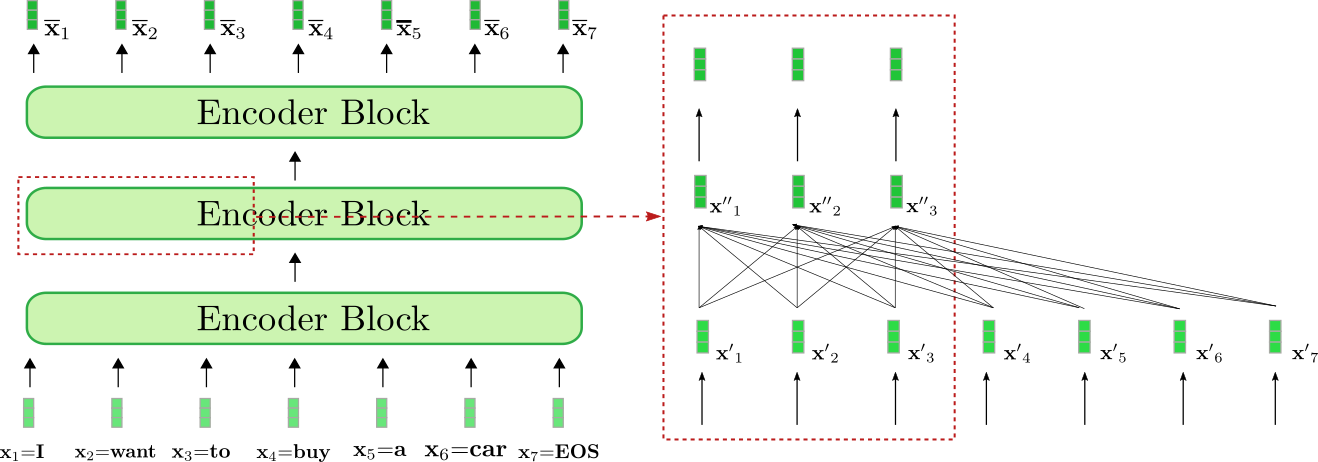
Nuestro ejemplo de codificador basado en transformadores está compuesto por tres bloques de codificación, siendo que el segundo bloque de codificación se muestra con más detalle en el recuadro rojo a la derecha para los primeros tres vectores de entrada x 1 , x 2 y x 3 \mathbf{x}_1, \mathbf{x}_2 y \mathbf{x}_3 x 1 , x 2 y x 3 . El mecanismo de auto-atención bidireccional se ilustra mediante el grafo completamente conectado en la parte inferior del recuadro rojo y las dos capas de alimentación directa se muestran en la parte superior del recuadro rojo. Como se mencionó anteriormente, nos centraremos solo en el mecanismo de auto-atención bidireccional.
Como se puede ver, cada vector de salida de la capa de autoatención x ′ ′ i , ∀ i ∈ { 1 , … , 7 } \mathbf{x”}_i, \forall i \in \{1, \ldots, 7\} x ′ ′ i , ∀ i ∈ { 1 , … , 7 } depende directamente de todos los vectores de entrada x ′ 1 , … , x ′ 7 \mathbf{x’}_1, \ldots, \mathbf{x’}_7 x ′ 1 , … , x ′ 7 . Esto significa, por ejemplo, que la representación vectorial de entrada de la palabra “want”, es decir, x ′ 2 \mathbf{x’}_2 x ′ 2 , está directamente relacionada con la palabra “buy”, es decir, x ′ 4 \mathbf{x’}_4 x ′ 4 , pero también con la palabra “I”, es decir, x ′ 1 \mathbf{x’}_1 x ′ 1 . Por lo tanto, el vector de salida de la representación de “want”, es decir, x ′ ′ 2 \mathbf{x”}_2 x ′ ′ 2 , representa una representación contextual más refinada para la palabra “want”.
Echemos un vistazo más profundo a cómo funciona la autoatención bidireccional. Cada vector de entrada x ′ i \mathbf{x’}_i x ′ i de una secuencia de entrada X ′ 1 : n \mathbf{X’}_{1:n} X ′ 1 : n de un bloque del codificador se proyecta en un vector clave k i \mathbf{k}_i k i , un vector de valor v i \mathbf{v}_i v i y un vector de consulta q i \mathbf{q}_i q i (mostrados en naranja, azul y morado respectivamente a continuación) a través de tres matrices de pesos entrenables W q , W v , W k \mathbf{W}_q, \mathbf{W}_v, \mathbf{W}_k W q , W v , W k :
q i = W q x ′ i , \mathbf{q}_i = \mathbf{W}_q \mathbf{x’}_i, q i = W q x ′ i , v i = W v x ′ i , \mathbf{v}_i = \mathbf{W}_v \mathbf{x’}_i, v i = W v x ′ i , k i = W k x ′ i , \mathbf{k}_i = \mathbf{W}_k \mathbf{x’}_i, k i = W k x ′ i , ∀ i ∈ { 1 , … n } . \forall i \in \{1, \ldots n \}. ∀ i ∈ { 1 , … n } .
Observa que las mismas matrices de pesos se aplican a cada vector de entrada x i , ∀ i ∈ { i , … , n } \mathbf{x}_i, \forall i \in \{i, \ldots, n\} x i , ∀ i ∈ { i , … , n } . Después de proyectar cada vector de entrada x i \mathbf{x}_i x i en un vector de consulta, clave y valor, cada vector de consulta q j , ∀ j ∈ { 1 , … , n } \mathbf{q}_j, \forall j \in \{1, \ldots, n\} q j , ∀ j ∈ { 1 , … , n } se compara con todos los vectores clave k 1 , … , k n \mathbf{k}_1, \ldots, \mathbf{k}_n k 1 , … , k n . Cuanto más similar sea uno de los vectores clave k 1 , … k n \mathbf{k}_1, \ldots \mathbf{k}_n k 1 , … k n a un vector de consulta q j \mathbf{q}_j q j , más importante es el vector de valor correspondiente v j \mathbf{v}_j v j para el vector de salida x ′ ′ j \mathbf{x”}_j x ′ ′ j . Más específicamente, un vector de salida x ′ ′ j \mathbf{x”}_j x ′ ′ j se define como la suma ponderada de todos los vectores de valor v 1 , … , v n \mathbf{v}_1, \ldots, \mathbf{v}_n v 1 , … , v n más el vector de entrada x ′ j \mathbf{x’}_j x ′ j . De esta manera, los pesos son proporcionales a la similitud coseno entre q j \mathbf{q}_j q j y los respectivos vectores clave k 1 , … , k n \mathbf{k}_1, \ldots, \mathbf{k}_n k 1 , … , k n , lo cual se expresa matemáticamente mediante Softmax ( K 1 : n ⊺ q j ) \textbf{Softmax}(\mathbf{K}_{1:n}^\intercal \mathbf{q}_j) Softmax ( K 1 : n ⊺ q j ) como se ilustra en la ecuación a continuación. Para una descripción completa de la capa de autoatención, se recomienda al lector que consulte esta publicación de blog o el artículo original.
Bien, esto suena bastante complicado. Vamos a ilustrar la capa de autoatención bidireccional para uno de los vectores de consulta de nuestro ejemplo anterior. Para simplificar, se asume que nuestro decodificador basado en transformadores utiliza solo una única atención config.num_heads = 1 y que no se aplica ninguna normalización.
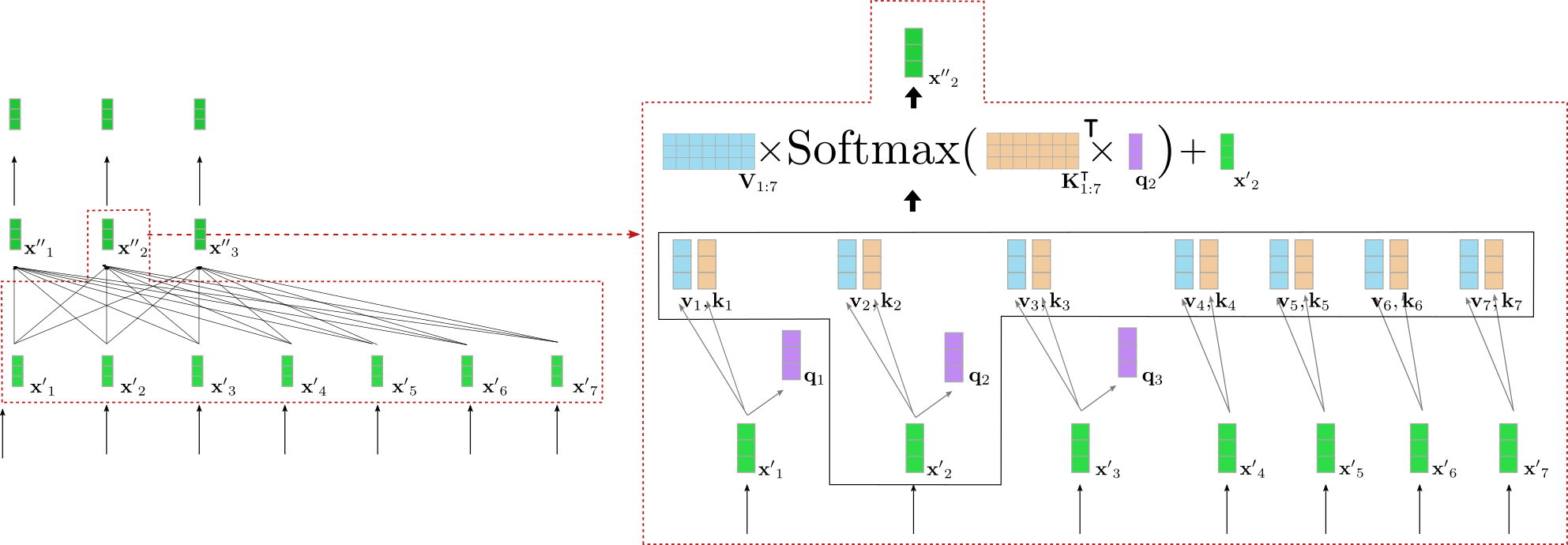
A la izquierda, se muestra nuevamente el segundo bloque codificador ilustrado anteriormente y a la derecha, se proporciona una visualización detallada del mecanismo de autoatención bidireccional para el segundo vector de entrada x ′ 2 \mathbf{x’}_2 x ′ 2 que corresponde a la palabra de entrada “want”. Al principio, todos los vectores de entrada x ′ 1 , … , x ′ 7 \mathbf{x’}_1, \ldots, \mathbf{x’}_7 x ′ 1 , … , x ′ 7 se proyectan en sus respectivos vectores de consulta q 1 , … , q 7 \mathbf{q}_1, \ldots, \mathbf{q}_7 q 1 , … , q 7 (solo se muestran los primeros tres vectores de consulta en morado arriba), vectores de valor v 1 , … , v 7 \mathbf{v}_1, \ldots, \mathbf{v}_7 v 1 , … , v 7 (mostrados en azul) y vectores clave k 1 , … , k 7 \mathbf{k}_1, \ldots, \mathbf{k}_7 k 1 , … , k 7 (mostrados en naranja). Luego, el vector de consulta q 2 \mathbf{q}_2 q 2 se multiplica por la transposición de todos los vectores clave, es decir, K 1 : 7 ⊺ \mathbf{K}_{1:7}^{\intercal} K 1 : 7 ⊺ seguido de la operación softmax para obtener los pesos de autoatención . Los pesos de autoatención se multiplican finalmente por los respectivos vectores de valor y se agrega el vector de entrada x ′ 2 \mathbf{x’}_2 x ′ 2 para obtener la representación “refinada” de la palabra “want”, es decir, x ′ ′ 2 \mathbf{x”}_2 x ′ ′ 2 (mostrado en verde oscuro a la derecha). Toda la ecuación se ilustra en la parte superior del cuadro a la derecha. La multiplicación de K 1 : 7 ⊺ \mathbf{K}_{1:7}^{\intercal} K 1 : 7 ⊺ y q 2 \mathbf{q}_2 q 2 permite comparar la representación vectorial de “want” con todas las demás representaciones vectoriales de entrada “I”, “to”, “buy”, “a”, “car”, “EOS” para que los pesos de autoatención reflejen la importancia de cada una de las demás representaciones vectoriales de entrada x ′ j , con j ≠ 2 \mathbf{x’}_j \text{, con } j \ne 2 x ′ j , con j = 2 para la representación refinada x ′ ′ 2 \mathbf{x”}_2 x ′ ′ 2 de la palabra “want”.
Para comprender mejor las implicaciones de la capa de autoatención bidireccional, supongamos que se procesa la siguiente oración: “La casa es hermosa y está bien ubicada en el centro de la ciudad, donde es fácilmente accesible en transporte público”. La palabra “it” se refiere a “casa”, que se encuentra a 12 “posiciones de distancia”. En los codificadores basados en transformadores, la capa de autoatención bidireccional realiza una única operación matemática para relacionar el vector de entrada de “casa” con el vector de entrada de “it” (comparar con la primera ilustración de esta sección). En cambio, en un codificador basado en RNN, una palabra que se encuentra a 12 “posiciones de distancia” requeriría al menos 12 operaciones matemáticas, lo que significa que en un codificador basado en RNN se requiere un número lineal de operaciones matemáticas. Esto hace que sea mucho más difícil para un codificador basado en RNN modelar representaciones contextuales de largo alcance. Además, queda claro que un codificador basado en transformadores es mucho menos propenso a perder información importante que un modelo codificador-decodificador basado en RNN porque la longitud de la secuencia de codificación se mantiene igual, es decir, len ( X 1 : n ) = len ( X ‾ 1 : n ) = n \textbf{len}(\mathbf{X}_{1:n}) = \textbf{len}(\mathbf{\overline{X}}_{1:n}) = n len ( X 1 : n ) = len ( X 1 : n ) = n , mientras que un RNN comprime la longitud de ∗ len ( ( X 1 : n ) = n *\textbf{len}((\mathbf{X}_{1:n}) = n ∗ len ( ( X 1 : n ) = n a solo len ( c ) = 1 \textbf{len}(\mathbf{c}) = 1 len ( c ) = 1 , lo que dificulta mucho que los RNN codifiquen efectivamente dependencias de largo alcance entre las palabras de entrada.
Además de hacer que las dependencias a largo plazo sean más fáciles de aprender, podemos ver que la arquitectura Transformer es capaz de procesar texto en paralelo. Matemáticamente, esto se puede demostrar fácilmente escribiendo la fórmula de autoatención como un producto de las matrices de consulta, clave y valor:
X ′ ′ 1 : n = V 1 : n Softmax ( Q 1 : n ⊺ K 1 : n ) + X ′ 1 : n .
La salida X ′ ′ 1 : n = x ′ ′ 1 , … , x ′ ′ n se calcula mediante una serie de multiplicaciones de matrices y una operación softmax, que se pueden paralelizar de manera efectiva. Sin embargo, en un modelo de codificador basado en RNN, el cálculo del estado oculto c debe hacerse de manera secuencial: calcular el estado oculto del primer vector de entrada x 1 , luego calcular el estado oculto del segundo vector de entrada que depende del estado oculto del primer vector oculto, etc. La naturaleza secuencial de las RNNs impide una paralelización efectiva y las hace mucho más ineficientes en comparación con los modelos de codificador basados en Transformer en hardware GPU moderno.
Genial, ahora deberíamos tener una mejor comprensión de a) cómo los modelos de codificador basados en Transformer modelan de manera efectiva representaciones contextuales a largo plazo y b) cómo procesan de manera eficiente secuencias largas de vectores de entrada.
Ahora, codifiquemos un breve ejemplo de la parte del codificador de nuestros modelos codificador-decodificador MarianMT para verificar que la teoría explicada se cumple en la práctica.
1 {}^1 Una explicación detallada del papel que desempeñan las capas de avance de alimentación en los modelos basados en Transformer está fuera del alcance de este cuaderno. Se argumenta en Yun et. al, (2017) que las capas de avance de alimentación son cruciales para mapear cada vector contextual x ′ i individualmente al espacio de salida deseado, lo cual la capa de autoatención no logra hacer por sí sola. Cabe señalar aquí que cada token de salida x ′ es procesado por la misma capa de avance de alimentación. Para obtener más detalles, se recomienda al lector leer el artículo.
2 {}^2 Sin embargo, el vector de entrada EOS no tiene que ser agregado a la secuencia de entrada, pero se ha demostrado que mejora el rendimiento en muchos casos. A diferencia del vector objetivo BOS 0 del decodificador basado en Transformer, se requiere como un vector de entrada inicial para predecir un primer vector objetivo.
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
embeddings = model.get_input_embeddings()
# crear ids de vectores de entrada codificados
input_ids = tokenizer("Quiero comprar un coche", return_tensors="pt").input_ids
# pasar input_ids al codificador
encoder_hidden_states = model.base_model.encoder(input_ids, return_dict=True).last_hidden_state
# cambiar ligeramente la entrada y pasarla al codificador
input_ids_perturbed = tokenizer("Quiero comprar una casa", return_tensors="pt").input_ids
encoder_hidden_states_perturbed = model.base_model.encoder(input_ids_perturbed, return_dict=True).last_hidden_state
# comparar forma y codificación del primer vector
print(f"Longitud de los embeddings de entrada {embeddings(input_ids).shape[1]}. Longitud de encoder_hidden_states {encoder_hidden_states.shape[1]}")
# comparar valores de la incrustación de la palabra "I" para input_ids y input_ids_perturbed
print("¿La codificación de `I` es igual a su versión perturbada?: ", torch.allclose(encoder_hidden_states[0, 0], encoder_hidden_states_perturbed[0, 0], atol=1e-3))Salidas:
Longitud de los embeddings de entrada 7. Longitud de los estados ocultos del codificador 7
¿Es la codificación para `I` igual a su versión perturbada?: FalsoComparamos la longitud de los embeddings de palabras de entrada, es decir, embeddings(input_ids) correspondiente a X 1 : n \mathbf{X}_{1:n} X 1 : n , con la longitud de los estados ocultos del codificador , correspondiente a X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n . Además, hemos pasado la secuencia de palabras “Quiero comprar un auto” y una versión ligeramente perturbada “Quiero comprar una casa” a través del codificador para comprobar si la primera codificación de salida, correspondiente a “I”, difiere cuando solo se cambia la última palabra en la secuencia de entrada.
Como era de esperar, la longitud de salida de los embeddings de palabras de entrada y las codificaciones de salida del codificador, es decir, len ( X 1 : n ) \textbf{len}(\mathbf{X}_{1:n}) len ( X 1 : n ) y len ( X ‾ 1 : n ) \textbf{len}(\mathbf{\overline{X}}_{1:n}) len ( X 1 : n ) , es igual. En segundo lugar, se puede observar que los valores del vector de salida codificado de x ‾ 1 = “I” \mathbf{\overline{x}}_1 = \text{“I”} x 1 = “I” son diferentes cuando la última palabra se cambia de “auto” a “casa”. Sin embargo, esto no debería ser una sorpresa si se ha comprendido la autoatención bidireccional.
En una nota aparte, los modelos de autoenconder, como BERT, tienen la misma arquitectura que los modelos codificadores basados en transformers. Los modelos de autoenconder aprovechan esta arquitectura para realizar un preentrenamiento masivo auto-supervisado en datos de texto de dominio abierto, de manera que puedan mapear cualquier secuencia de palabras a una representación bidireccional profunda. En Devlin et al. (2018), los autores demuestran que un modelo BERT preentrenado con una única capa de clasificación específica de tarea en la parte superior puede lograr resultados SOTA en once tareas de NLP. Todos los modelos de autoenconder de 🤗Transformers se pueden encontrar aquí.
Decodificador
Como se menciona en la sección de Codificador-Decodificador, el decodificador basado en transformers define la distribución de probabilidad condicional de una secuencia objetivo dada la secuencia de codificación contextualizada:
p θ d e c ( Y 1 : m ∣ X ‾ 1 : n ) , p_{\theta_{dec}}(\mathbf{Y}_{1: m} | \mathbf{\overline{X}}_{1:n}), p θ d e c ( Y 1 : m ∣ X 1 : n ) ,
que según la regla de Bayes se puede descomponer en un producto de distribuciones condicionales del siguiente vector objetivo dado la secuencia de codificación contextualizada y todos los vectores objetivo anteriores:
p θ d e c ( Y 1 : m ∣ X ‾ 1 : n ) = ∏ i = 1 m p θ d e c ( y i ∣ Y 0 : i − 1 , X ‾ 1 : n ) . p_{\theta_{dec}}(\mathbf{Y}_{1:m} | \mathbf{\overline{X}}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{dec}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}). p θ d e c ( Y 1 : m ∣ X 1 : n ) = i = 1 ∏ m p θ d e c ( y i ∣ Y 0 : i − 1 , X 1 : n ) .
Primero veamos cómo el decodificador basado en transformers define una distribución de probabilidad. El decodificador basado en transformers es una pila de bloques de decodificador seguidos por una capa densa, la “cabeza LM”. La pila de bloques de decodificador mapea la secuencia de codificación contextualizada X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n y una secuencia de vectores objetivo a la que se le ha añadido por delante el vector BOS \text{BOS} BOS y se ha cortado hasta el último vector objetivo, es decir, Y 0 : i − 1 \mathbf{Y}_{0:i-1} Y 0 : i − 1 , a una secuencia codificada de vectores objetivo Y ‾ 0 : i − 1 \mathbf{\overline{Y}}_{0: i-1} Y 0 : i − 1 . Luego, la “cabeza LM” mapea la secuencia codificada de vectores objetivo Y ‾ 0 : i − 1 \mathbf{\overline{Y}}_{0: i-1} Y 0 : i − 1 a una secuencia de vectores de logit L 1 : n = l 1 , … , l n \mathbf{L}_{1:n} = \mathbf{l}_1, \ldots, \mathbf{l}_n L 1 : n = l 1 , … , l n , mientras que la dimensionalidad de cada vector de logit l i \mathbf{l}_i l i corresponde al tamaño del vocabulario. De esta manera, para cada i ∈ { 1 , … , n } i \in \{1, \ldots, n\} i ∈ { 1 , … , n } se puede obtener una distribución de probabilidad sobre todo el vocabulario aplicando una operación softmax en l i \mathbf{l}_i l i . Estas distribuciones definen la distribución condicional:
p θ d e c ( y i ∣ Y 0 : i − 1 , X ‾ 1 : n ) , ∀ i ∈ { 1 , … , n } , p_{\theta_{dec}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}), \forall i \in \{1, \ldots, n\}, p θ d e c ( y i ∣ Y 0 : i − 1 , X 1 : n ) , ∀ i ∈ { 1 , … , n } ,
respectivamente. La “cabeza LM” a menudo se asocia a la transpuesta de la matriz de incrustación de palabras, es decir, W emb ⊺ = [ y 1 , … , y vocab ] ⊺ \mathbf{W}_{\text{emb}}^{\intercal} = \left[\mathbf{y}^1, \ldots, \mathbf{y}^{\text{vocab}}\right]^{\intercal} W emb ⊺ = [ y 1 , … , y vocab ] ⊺ 1 {}^1 1 . Intuitivamente, esto significa que para todo i ∈ { 0 , … , n − 1 } i \in \{0, \ldots, n – 1\} i ∈ { 0 , … , n − 1 } la capa “Cabeza LM” compara el vector de salida codificado y ‾ i \mathbf{\overline{y}}_i y i con todas las incrustaciones de palabras en el vocabulario y 1 , … , y vocab \mathbf{y}^1, \ldots, \mathbf{y}^{\text{vocab}} y 1 , … , y vocab para que el vector de logit l i + 1 \mathbf{l}_{i+1} l i + 1 represente las puntuaciones de similitud entre el vector de salida codificado y cada incrustación de palabra. La operación de softmax simplemente transforma las puntuaciones de similitud en una distribución de probabilidad. Para cada i ∈ { 1 , … , n } i \in \{1, \ldots, n\} i ∈ { 1 , … , n } , se cumplen las siguientes ecuaciones:
p θ d e c ( y ∣ X ‾ 1 : n , Y 0 : i − 1 ) p_{\theta_{dec}}(\mathbf{y} | \mathbf{\overline{X}}_{1:n}, \mathbf{Y}_{0:i-1}) p θ d e c ( y ∣ X 1 : n , Y 0 : i − 1 ) = Softmax ( f θ dec ( X ‾ 1 : n , Y 0 : i − 1 ) ) = \text{Softmax}(f_{\theta_{\text{dec}}}(\mathbf{\overline{X}}_{1:n}, \mathbf{Y}_{0:i-1})) = Softmax ( f θ dec ( X 1 : n , Y 0 : i − 1 ) ) = Softmax ( W emb ⊺ y ‾ i − 1 ) = \text{Softmax}(\mathbf{W}_{\text{emb}}^{\intercal} \mathbf{\overline{y}}_{i-1}) = Softmax ( W emb ⊺ y i − 1 ) = Softmax ( l i ) . = \text{Softmax}(\mathbf{l}_i). = Softmax ( l i ) .
Poniéndolo todo junto, para modelar la distribución condicional de una secuencia de vectores objetivo Y 1 : m \mathbf{Y}_{1: m} Y 1 : m , los vectores objetivo Y 1 : m − 1 \mathbf{Y}_{1:m-1} Y 1 : m − 1 precedidos por el vector especial BOS \text{BOS} BOS, es decir, y 0 \mathbf{y}_0 y 0 , se mapean primero junto con la secuencia de codificación contextualizada X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n al vector de logit secuencia L 1 : m \mathbf{L}_{1:m} L 1 : m . En consecuencia, cada vector objetivo de logit l i \mathbf{l}_i l i se transforma en una distribución de probabilidad condicional del vector objetivo y i \mathbf{y}_i y i utilizando la operación de softmax. Finalmente, las probabilidades condicionales de todos los vectores objetivo y 1 , … , y m \mathbf{y}_1, \ldots, \mathbf{y}_m y 1 , … , y m se multiplican para obtener la probabilidad condicional de la secuencia completa de vectores objetivo:
p θ dec (Y1:m | X̄1:n) = ∏ i = 1 m p θ dec (yi | Y0:i-1, X̄1:n).
A diferencia de los codificadores basados en transformadores, en los decodificadores basados en transformadores, el vector de salida codificado ȳi debe ser una buena representación del siguiente vector objetivo yi+1 y no del vector de entrada en sí mismo. Además, el vector de salida codificado ȳi debe estar condicionado por toda la secuencia de codificación contextualizada X̄1:n. Para cumplir con estos requisitos, cada bloque del decodificador consiste en una capa de auto-atención unidireccional, seguida de una capa de atención cruzada y dos capas de alimentación hacia adelante.
La capa de auto-atención unidireccional relaciona cada uno de sus vectores de entrada y̓j solo con todos los vectores de entrada anteriores y̓i, con i ≤ j, para modelar la distribución de probabilidad de los siguientes vectores objetivo. La capa de atención cruzada relaciona cada uno de sus vectores de entrada y̓̓j con todos los vectores de codificación contextualizados X̄1:n para condicionar la distribución de probabilidad de los siguientes vectores objetivo tanto en la entrada del codificador como en el decodificador.
Muy bien, visualicemos el decodificador basado en transformadores para nuestro ejemplo de traducción del inglés al alemán.
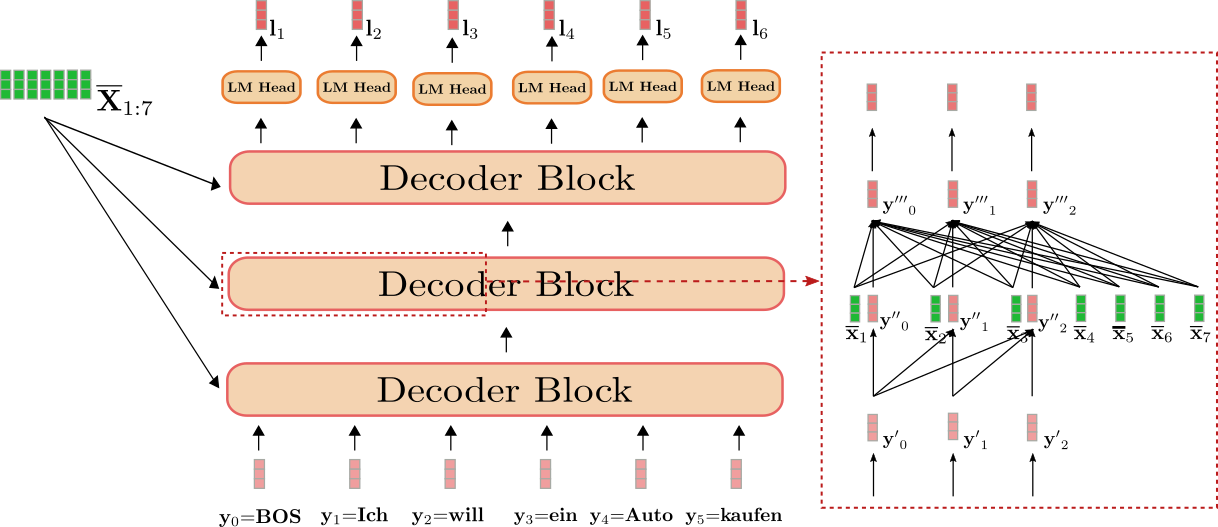
Podemos ver que el decodificador mapea la entrada Y0:5 “BOS”, “Ich”, “will”, “ein”, “Auto”, “kaufen” (mostrado en rojo claro) junto con la secuencia contextualizada de “I”, “want”, “to”, “buy”, “a”, “car”, “EOS”, es decir, X̄1:7 (mostrado en verde oscuro) a los vectores logit L1:6 (mostrado en rojo oscuro).
Aplicando una operación softmax en cada l1, l2, …, l5 se puede definir las distribuciones de probabilidad condicionales:
p θ dec (y | BOS, X̄1:7), p θ dec (y | BOS Ich, X̄1:7), …, p θ dec (y | BOS Ich will ein Auto kaufen, X̄1:7).
La probabilidad condicional general de:
p θ d e c ( Ich will ein Auto kaufen EOS ∣ X ‾ 1 : n ) p_{\theta_{dec}}(\text{Ich will ein Auto kaufen EOS} | \mathbf{\overline{X}}_{1:n}) p θ d e c ( Ich will ein Auto kaufen EOS ∣ X 1 : n )
se puede calcular como el siguiente producto:
p θ d e c ( Ich ∣ BOS , X ‾ 1 : 7 ) × … × p θ d e c ( EOS ∣ BOS Ich will ein Auto kaufen , X ‾ 1 : 7 ) . p_{\theta_{dec}}(\text{Ich} | \text{BOS}, \mathbf{\overline{X}}_{1:7}) \times \ldots \times p_{\theta_{dec}}(\text{EOS} | \text{BOS Ich will ein Auto kaufen}, \mathbf{\overline{X}}_{1:7}). p θ d e c ( Ich ∣ BOS , X 1 : 7 ) × … × p θ d e c ( EOS ∣ BOS Ich will ein Auto kaufen , X 1 : 7 ) .
El recuadro rojo a la derecha muestra un bloque decodificador para los tres primeros vectores objetivo y 0 , y 1 , y 2 \mathbf{y}_0, \mathbf{y}_1, \mathbf{y}_2 y 0 , y 1 , y 2 . En la parte inferior, se ilustra el mecanismo de auto-atención unidireccional y en el medio, se ilustra el mecanismo de atención cruzada. Enfoquémonos primero en la auto-atención unidireccional.
Al igual que en la auto-atención bidireccional, en la auto-atención unidireccional, los vectores de consulta q 0 , … , q m − 1 \mathbf{q}_0, \ldots, \mathbf{q}_{m-1} q 0 , … , q m − 1 (mostrados en morado abajo), los vectores clave k 0 , … , k m − 1 \mathbf{k}_0, \ldots, \mathbf{k}_{m-1} k 0 , … , k m − 1 (mostrados en naranja abajo) y los vectores de valor v 0 , … , v m − 1 \mathbf{v}_0, \ldots, \mathbf{v}_{m-1} v 0 , … , v m − 1 (mostrados en azul abajo) se proyectan a partir de sus respectivos vectores de entrada y ′ 0 , … , y ′ m − 1 \mathbf{y’}_0, \ldots, \mathbf{y’}_{m-1} y ′ 0 , … , y ′ m − 1 (mostrados en rojo claro abajo). Sin embargo, en la auto-atención unidireccional, cada vector de consulta q i \mathbf{q}_i q i se compara solo con su respectivo vector clave y todos los anteriores, es decir, k 0 , … , k i \mathbf{k}_0, \ldots, \mathbf{k}_i k 0 , … , k i para obtener los respectivos pesos de atención . Esto evita que un vector de salida y ′ ′ j \mathbf{y”}_j y ′ ′ j (mostrado en rojo oscuro abajo) incluya información sobre el siguiente vector de entrada y i , con i > j \mathbf{y}_i, \text{ con } i > j y i , con i > j para todo j ∈ { 0 , … , m − 1 } j \in \{0, \ldots, m – 1 \} j ∈ { 0 , … , m − 1 } . Al igual que en la auto-atención bidireccional, los pesos de atención se multiplican por sus respectivos vectores de valor y se suman.
Podemos resumir la auto-atención unidireccional de la siguiente manera:
y ′ ′ i = V 0 : i Softmax ( K 0 : i ⊺ q i ) + y ′ i . \mathbf{y”}_i = \mathbf{V}_{0: i} \textbf{Softmax}(\mathbf{K}_{0: i}^\intercal \mathbf{q}_i) + \mathbf{y’}_i. y ′ ′ i = V 0 : i Softmax ( K 0 : i ⊺ q i ) + y ′ i .
Ten en cuenta que el rango de índices de los vectores clave y valor es 0 : i 0:i 0 : i en lugar de 0 : m − 1 0: m-1 0 : m − 1 que sería el rango de los vectores clave en la autoatención bidireccional.
Vamos a ilustrar la autoatención unidireccional para el vector de entrada y ′ 1 \mathbf{y’}_1 y ′ 1 en nuestro ejemplo anterior.
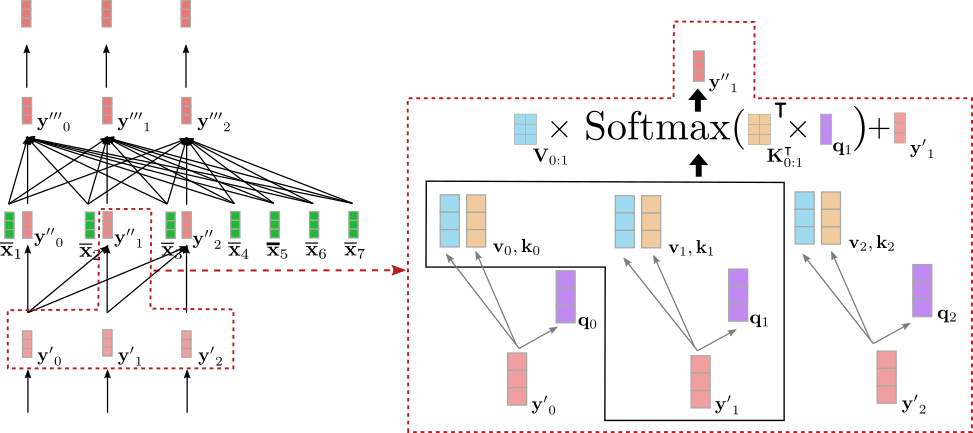
Como se puede ver, y ′ ′ 1 \mathbf{y”}_1 y ′ ′ 1 solo depende de y ′ 0 \mathbf{y’}_0 y ′ 0 y y ′ 1 \mathbf{y’}_1 y ′ 1 . Por lo tanto, relacionamos la representación vectorial de la palabra “Ich”, es decir, y ′ 1 \mathbf{y’}_1 y ′ 1 , solo con ella misma y con el vector objetivo “BOS”, es decir, y ′ 0 \mathbf{y’}_0 y ′ 0 , pero no con la representación vectorial de la palabra “will”, es decir, y ′ 2 \mathbf{y’}_2 y ′ 2 .
Entonces, ¿por qué es importante usar la autoatención unidireccional en el decodificador en lugar de la autoatención bidireccional? Como se mencionó anteriormente, un decodificador basado en transformadores define una asignación de una secuencia de vectores de entrada Y 0 : m − 1 \mathbf{Y}_{0: m-1} Y 0 : m − 1 a los logitos correspondientes a los vectores de entrada del decodificador siguientes, es decir, L 1 : m \mathbf{L}_{1:m} L 1 : m . En nuestro ejemplo, esto significa, por ejemplo, que el vector de entrada y 1 \mathbf{y}_1 y 1 = “Ich” se asigna al vector logito l 2 \mathbf{l}_2 l 2 , que luego se utiliza para predecir el vector de entrada y 2 \mathbf{y}_2 y 2 . Por lo tanto, si y ′ 1 \mathbf{y’}_1 y ′ 1 tuviera acceso a los siguientes vectores de entrada Y ′ 2 : 5 \mathbf{Y’}_{2:5} Y ′ 2 : 5 , el decodificador simplemente copiaría la representación vectorial de “will”, es decir, y ′ 2 \mathbf{y’}_2 y ′ 2 , para que sea su salida y ′ ′ 1 \mathbf{y”}_1 y ′ ′ 1 . Esto se enviaría a la última capa de manera que el vector de salida codificado y ‾ 1 \mathbf{\overline{y}}_1 y 1 esencialmente solo correspondería a la representación vectorial y 2 \mathbf{y}_2 y 2 .
Esto claramente es desventajoso ya que el decodificador basado en transformadores nunca aprendería a predecir la siguiente palabra dadas todas las palabras anteriores, sino que simplemente copiaría el vector objetivo y i \mathbf{y}_i y i a través de la red a y ‾ i − 1 \mathbf{\overline{y}}_{i-1} y i − 1 para todos los i ∈ { 1 , … , m } i \in \{1, \ldots, m \} i ∈ { 1 , … , m } . Para definir una distribución condicional del siguiente vector objetivo, la distribución no puede estar condicionada en el propio vector objetivo. No tiene mucho sentido predecir y i \mathbf{y}_i y i a partir de p ( y ∣ Y 0 : i , X ‾ ) p(\mathbf{y} | \mathbf{Y}_{0:i}, \mathbf{\overline{X}}) p ( y ∣ Y 0 : i , X ) porque la distribución está condicionada en el vector objetivo que se supone que modela. Por lo tanto, la arquitectura de autoatención unidireccional nos permite definir una distribución de probabilidad causal, que es necesaria para modelar eficazmente una distribución condicional del siguiente vector objetivo.
¡Genial! Ahora podemos pasar a la capa que conecta el codificador y el decodificador: ¡el mecanismo de atención cruzada!
La capa de atención cruzada toma dos secuencias de vectores como entradas: las salidas de la capa de autoatención unidireccional, es decir, Y ′ ′ 0 : m − 1 \mathbf{Y”}_{0: m-1} Y ′ ′ 0 : m − 1 y los vectores de codificación contextualizados X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n . Al igual que en la capa de autoatención, los vectores de consulta q 0 , … , q m − 1 \mathbf{q}_0, \ldots, \mathbf{q}_{m-1} q 0 , … , q m − 1 son proyecciones de los vectores de salida de la capa anterior, es decir, Y ′ ′ 0 : m − 1 \mathbf{Y”}_{0: m-1} Y ′ ′ 0 : m − 1 . Sin embargo, los vectores clave y valor k 0 , … , k m − 1 \mathbf{k}_0, \ldots, \mathbf{k}_{m-1} k 0 , … , k m − 1 y v 0 , … , v m − 1 \mathbf{v}_0, \ldots, \mathbf{v}_{m-1} v 0 , … , v m − 1 son proyecciones de los vectores de codificación contextualizados X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n . Una vez que se han definido los vectores clave, valor y consulta, se compara un vector de consulta q i \mathbf{q}_i q i con todos los vectores clave y se utiliza el puntaje correspondiente para ponderar los respectivos vectores valor, tal como se hace en el caso de la autoatención bidireccional para obtener el vector de salida y ′ ′ ′ i \mathbf{y”’}_i y ′ ′ ′ i para todos los i ∈ 0 , … , m − 1 i \in {0, \ldots, m-1} i ∈ 0 , … , m − 1 . La atención cruzada se puede resumir de la siguiente manera:
y ′ ′ ′ i = V 1 : n Softmax ( K 1 : n ⊺ q i ) + y ′ ′ i.
Ten en cuenta que el rango de índices de los vectores de clave y valor es 1 : n, correspondiente al número de vectores de codificación contextualizados.
Visualicemos el mecanismo de atención cruzada para el vector de entrada y ′ ′ 1 en nuestro ejemplo anterior.
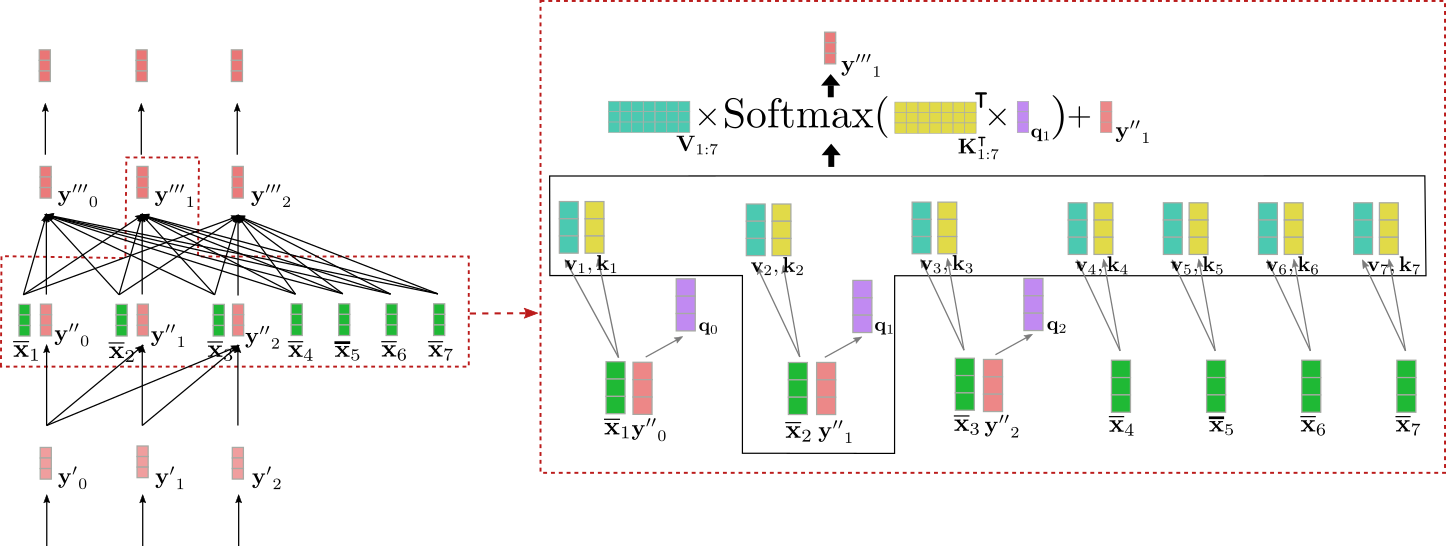
Podemos ver que el vector de consulta q 1 (mostrado en morado) se deriva de y ′ ′ 1 (mostrado en rojo) y, por lo tanto, depende de una representación vectorial de la palabra “Ich”. Luego, el vector de consulta q 1 se compara con los vectores de clave k 1 , … , k 7 (mostrados en amarillo) correspondientes a la representación de codificación contextual de todos los vectores de entrada del codificador X 1 : n = “Quiero comprar un coche EOS”. Esto pone la representación vectorial de “Ich” en relación directa con todos los vectores de entrada del codificador. Finalmente, los pesos de atención se multiplican por los vectores de valor v 1 , … , v 7 (mostrados en turquesa) para obtener, además del vector de entrada y ′ ′ 1 , el vector de salida y ′ ′ ′ 1 (mostrado en rojo oscuro).
Entonces, ¿qué sucede aquí exactamente de manera intuitiva? Cada vector de salida y ′ ′ ′ i es una suma ponderada de todas las proyecciones de valor de las entradas del codificador v 1 , … , v 7 más el vector de entrada en sí y ′ ′ i (ver fórmula ilustrada anteriormente). El mecanismo clave a entender es lo siguiente: dependiendo de qué tan similar sea una proyección de consulta del vector de entrada del decodificador q i a una proyección clave del vector de entrada del codificador k j , más importante es la proyección de valor del vector de entrada del codificador v j . En términos generales, esto significa que cuanto más “relacionada” sea una representación de entrada del decodificador con una representación de entrada del codificador, más influirá la representación de entrada en la representación de salida del decodificador.
¡Genial! Ahora podemos ver cómo esta arquitectura condiciona de manera agradable cada vector de salida y ′ ′ ′ i a partir de la interacción entre los vectores de entrada del codificador X ‾ 1 : n y el vector de entrada y ′ ′ i . Otra observación importante en este punto es que la arquitectura es completamente independiente del número n de vectores de codificación contextualizados X ‾ 1 : n en los que se condiciona el vector de salida y ′ ′ ′ i . Todas las matrices de proyección W k cross y W v cross para derivar los vectores de clave k 1 , … , k n y los vectores de valor v 1 , … , v n respectivamente se comparten en todas las posiciones 1 , … , n y todos los vectores de valor v 1 , … , v n se suman para obtener un único vector promediado ponderado. Ahora también se vuelve obvio por qué el decodificador basado en Transformer no sufre el problema de dependencia de largo alcance que sufre el decodificador basado en RNN. Debido a que cada vector de logit del decodificador depende directamente de cada vector de salida codificado, el número de operaciones matemáticas para comparar el primer vector de salida codificado y el último vector de logit del decodificador se reduce esencialmente a solo una operación.
Para concluir, la capa de atención unidireccional es responsable de condicionar cada vector de salida en todos los vectores de entrada del decodificador anteriores y el vector de entrada actual, y la capa de atención cruzada es responsable de condicionar aún más cada vector de salida en todos los vectores de entrada codificados.
Para verificar nuestra comprensión teórica, sigamos nuestro ejemplo de código de la sección del codificador anterior.
1 {}^1 1 La matriz de incrustación de palabras W emb \mathbf{W}_{\text{emb}} W emb le da a cada palabra de entrada una representación única de vector independiente del contexto. Esta matriz a menudo se fija como la capa “LM Head”. Sin embargo, la capa “LM Head” puede consistir muy bien en un mapeo de pesos completamente independiente de “vector codificado a logito”.
2 {}^2 2 Nuevamente, una explicación detallada del papel que juegan las capas de alimentación directa en modelos basados en transformadores está fuera del alcance de este cuaderno. Se argumenta en Yun et. al, (2017) que las capas de alimentación directa son cruciales para mapear cada vector contextual x ′ i \mathbf{x’}_i x ′ i individualmente al espacio de salida deseado, lo cual la capa de atención propia no logra hacer por sí sola. Cabe señalar aquí que cada token de salida x ′ \mathbf{x’} x ′ es procesado por la misma capa de alimentación directa. Para obtener más detalles, se recomienda al lector leer el artículo.
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
embeddings = model.get_input_embeddings()
# create token ids for encoder input
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# pass input token ids to encoder
encoder_output_vectors = model.base_model.encoder(input_ids, return_dict=True).last_hidden_state
# create token ids for decoder input
decoder_input_ids = tokenizer("<pad> Ich will ein", return_tensors="pt", add_special_tokens=False).input_ids
# pass decoder input ids and encoded input vectors to decoder
decoder_output_vectors = model.base_model.decoder(decoder_input_ids, encoder_hidden_states=encoder_output_vectors).last_hidden_state
# derive embeddings by multiplying decoder outputs with embedding weights
lm_logits = torch.nn.functional.linear(decoder_output_vectors, embeddings.weight, bias=model.final_logits_bias)
# change the decoder input slightly
decoder_input_ids_perturbed = tokenizer("<pad> Ich will das", return_tensors="pt", add_special_tokens=False).input_ids
decoder_output_vectors_perturbed = model.base_model.decoder(decoder_input_ids_perturbed, encoder_hidden_states=encoder_output_vectors).last_hidden_state
lm_logits_perturbed = torch.nn.functional.linear(decoder_output_vectors_perturbed, embeddings.weight, bias=model.final_logits_bias)
# compare shape and encoding of first vector
print(f"Shape of decoder input vectors {embeddings(decoder_input_ids).shape}. Shape of decoder logits {lm_logits.shape}")
# compare values of word embedding of "I" for input_ids and perturbed input_ids
print("Is encoding for `Ich` equal to its perturbed version?: ", torch.allclose(lm_logits[0, 0], lm_logits_perturbed[0, 0], atol=1e-3))Salida:
Shape of decoder input vectors torch.Size([1, 5, 512]). Shape of decoder logits torch.Size([1, 5, 58101])
¿Es la codificación de `Ich` igual a su versión perturbada?: VerdaderoComparamos la forma de salida de las incrustaciones de palabras de entrada del decodificador, es decir, embeddings(decoder_input_ids) (corresponde a Y 0 : 4 \mathbf{Y}_{0: 4} Y 0 : 4 , aquí <pad> corresponde a BOS y “Ich will das” se tokeniza en 4 tokens) con la dimensionalidad de los lm_logits (corresponde a L 1 : 5 \mathbf{L}_{1:5} L 1 : 5 ). Además, hemos pasado la secuencia de palabras ” <pad> Ich will ein” y una versión ligeramente perturbada ” <pad> Ich will das” junto con los encoder_output_vectors a través del decodificador para verificar si el segundo lm_logit, correspondiente a “Ich”, difiere cuando solo se cambia la última palabra en la secuencia de entrada (“ein” -> “das”).
Como se esperaba, las formas de salida de los embeddings de palabras de entrada del decodificador y de lm_logits, es decir, la dimensionalidad de Y 0: 4 \mathbf{Y}_{0: 4} Y 0: 4 y L 1: 5 \mathbf{L}_{1:5} L 1: 5 son diferentes en la última dimensión. Mientras que la longitud de la secuencia es la misma (=5), la dimensionalidad de un embedding de palabra de entrada del decodificador corresponde a model.config.hidden_size, mientras que la dimensionalidad de un lm_logit corresponde al tamaño del vocabulario model.config.vocab_size, como se explicó anteriormente. En segundo lugar, se puede observar que los valores del vector de salida codificado de l 1 = “Ich” \mathbf{l}_1 = \text{“Ich”} l 1 = “Ich” son los mismos cuando se cambia la última palabra de “ein” a “das”. Sin embargo, esto no debería ser una sorpresa si se ha entendido la auto-atención unidireccional.
En una nota final, los modelos auto-regresivos, como GPT2, tienen la misma arquitectura que los modelos decodificadores basados en transformadores si se elimina la capa de atención cruzada porque los modelos auto-regresivos independientes no están condicionados a ninguna salida del codificador. Por lo tanto, los modelos auto-regresivos son esencialmente iguales a los modelos de auto-encoding, pero reemplazan la atención bidireccional por la atención unidireccional. Estos modelos también pueden ser pre-entrenados en grandes conjuntos de datos de texto de dominio abierto para mostrar un rendimiento impresionante en tareas de generación de lenguaje natural (NLG). En Radford et al. (2019), los autores demuestran que un modelo pre-entrenado de GPT2 puede lograr resultados SOTA o cercanos a SOTA en una variedad de tareas de NLG sin mucho ajuste fino. Todos los modelos auto-regresivos de 🤗Transformers se pueden encontrar aquí.
¡Bien, eso es todo! Ahora deberías tener una buena comprensión de los modelos codificador-decodificador basados en transformadores y cómo usarlos con la biblioteca 🤗Transformers.
Gracias a Victor Sanh, Sasha Rush, Sam Shleifer, Oliver Åstrand, Ted Moskovitz y Kristian Kyvik por sus valiosos comentarios.
Apéndice
Como se mencionó anteriormente, el siguiente fragmento de código muestra cómo se puede programar un método de generación simple para modelos codificador-decodificador basados en transformadores. Aquí, implementamos un método de decodificación codicioso simple utilizando torch.argmax para muestrear el vector objetivo.
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
# crear ids de vectores de entrada codificados
input_ids = tokenizer("Quiero comprar un coche", return_tensors="pt").input_ids
# crear token BOS
decoder_input_ids = tokenizer("<pad>", add_special_tokens=False, return_tensors="pt").input_ids
assert decoder_input_ids[0, 0].item() == model.config.decoder_start_token_id, "`decoder_input_ids` debe corresponder a `model.config.decoder_start_token_id`"
# PASO 1
# pasar input_ids al codificador y al decodificador y pasar el token BOS al decodificador para obtener el primer logit
outputs = model(input_ids, decoder_input_ids=decoder_input_ids, return_dict=True)
# obtener secuencia codificada
encoded_sequence = (outputs.encoder_last_hidden_state,)
# obtener logits
lm_logits = outputs.logits
# muestrear el último token con la probabilidad más alta
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
# concatenar
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# PASO 2
# reutilizar encoded_inputs y pasar BOS + "Ich" al decodificador para obtener el segundo logit
lm_logits = model(None, encoder_outputs=encoded_sequence, decoder_input_ids=decoder_input_ids, return_dict=True).logits
# muestrear el último token con la probabilidad más alta nuevamente
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
# concatenar de nuevo
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# PASO 3
lm_logits = model(None, encoder_outputs=encoded_sequence, decoder_input_ids=decoder_input_ids, return_dict=True).logits
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# ¡veamos qué hemos generado hasta ahora!
print(f"Generado hasta ahora: {tokenizer.decode(decoder_input_ids[0], skip_special_tokens=True)}")
# Esto también se puede escribir en un bucle.Salida:
Generado hasta ahora: Ich will einEn este ejemplo de código, mostramos exactamente lo que se describió anteriormente. Pasamos una entrada “Quiero comprar un coche” junto con el token BOS \text{BOS} BOS al modelo codificador-decodificador y muestreamos a partir del primer logit l 1 \mathbf{l}_1 l 1 (es decir, la primera línea lm_logits). Nuestra estrategia de muestreo es simple: elegir de forma codiciosa el siguiente vector de entrada del decodificador que tenga la probabilidad más alta. De manera autoregresiva, luego pasamos el vector de entrada del decodificador muestreado junto con las entradas anteriores al modelo codificador-decodificador y volvemos a muestrear. Repetimos esto una tercera vez. Como resultado, el modelo ha generado las palabras “Ich will ein”. El resultado es exacto, este es el comienzo de la traducción correcta de la entrada.
En la práctica, se utilizan métodos de decodificación más complicados para muestrear los lm_logits. La mayoría de ellos se cubren en esta publicación de blog.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Ajusta más y entrena más rápido con ZeRO a través de DeepSpeed y FairScale
- Recuperación Mejorada de Generación con Huggingface Transformers y Ray
- Hugging Face Reads, Feb. 2021 – Transformers de largo alcance
- Comprendiendo la Atención Esparsa por Bloques de BigBird
- Entrenamiento distribuido Entrena BART/T5 para resumir utilizando 🤗 Transformers y Amazon SageMaker
- Escalando la inferencia de BERT en CPU (Parte 1)
- Utilizando y mezclando modelos de Hugging Face con Gradio 2.0






