Comportamiento emergente de trueque en el aprendizaje por refuerzo de múltiples agentes
'Emergent bartering behavior in multi-agent reinforcement learning'
En nuestro reciente artículo, exploramos cómo las poblaciones de agentes de aprendizaje por refuerzo profundo (deep RL) pueden aprender comportamientos microeconómicos, como la producción, el consumo y el comercio de bienes. Descubrimos que los agentes artificiales aprenden a tomar decisiones económicamente racionales sobre la producción, el consumo y los precios, y reaccionan adecuadamente a los cambios en la oferta y la demanda. La población converge hacia precios locales que reflejan la abundancia de recursos cercanos, y algunos agentes aprenden a transportar bienes entre estas áreas para “comprar barato y vender caro”. Este trabajo avanza en la agenda de investigación más amplia del aprendizaje por refuerzo multiagente al introducir nuevos desafíos sociales para que los agentes aprendan a resolver.
En la medida en que el objetivo de la investigación en aprendizaje por refuerzo multiagente es eventualmente producir agentes que funcionen en toda la gama y complejidad de la inteligencia social humana, el conjunto de dominios considerados hasta ahora ha sido lamentablemente incompleto. Aún faltan dominios cruciales en los que la inteligencia humana destaca y en los que los humanos dedican cantidades significativas de tiempo y energía. El tema de la economía es uno de esos dominios. Nuestro objetivo en este trabajo es establecer entornos basados en los temas del comercio y la negociación para que los investigadores los utilicen en el aprendizaje por refuerzo multiagente.
La economía utiliza modelos basados en agentes para simular cómo se comportan las economías. Estos modelos a menudo incorporan suposiciones económicas sobre cómo deben actuar los agentes. En este trabajo, presentamos un mundo simulado multiagente donde los agentes pueden aprender comportamientos económicos desde cero, de manera familiar para cualquier estudiante de Microeconomía 101: decisiones sobre producción, consumo y precios. Pero nuestros agentes también deben tomar otras decisiones que se derivan de una forma de pensar más físicamente encarnada. Deben navegar por un entorno físico, encontrar árboles para recoger frutas y socios para intercambiarlas. Los avances recientes en técnicas de deep RL ahora hacen posible crear agentes que pueden aprender estos comportamientos por sí mismos, sin necesidad de que un programador codifique conocimiento específico del dominio.
Nuestro entorno, llamado Fruit Market, es un entorno multijugador donde los agentes producen y consumen dos tipos de frutas: manzanas y plátanos. Cada agente es hábil en la producción de un tipo de fruta, pero tiene preferencia por el otro: si los agentes pueden aprender a regatear e intercambiar bienes, ambas partes saldrían beneficiadas.
- Aprendizaje de física intuitiva en un modelo de aprendizaje profundo inspirado en la psicología del desarrollo
- El ciclo virtuoso de la investigación en IA
- De control de motor a inteligencia encarnada

En nuestros experimentos, demostramos que los actuales agentes de deep RL pueden aprender a comerciar, y sus comportamientos en respuesta a cambios en la oferta y la demanda se alinean con lo que predice la teoría microeconómica. Luego, ampliamos este trabajo para presentar escenarios que serían muy difíciles de resolver utilizando modelos analíticos, pero que son sencillos para nuestros agentes de deep RL. Por ejemplo, en entornos donde cada tipo de fruta crece en una área diferente, observamos la aparición de diferentes regiones de precios relacionadas con la abundancia local de frutas, así como el posterior aprendizaje de comportamientos de arbitraje por parte de algunos agentes, que comienzan a especializarse en transportar frutas entre estas regiones.
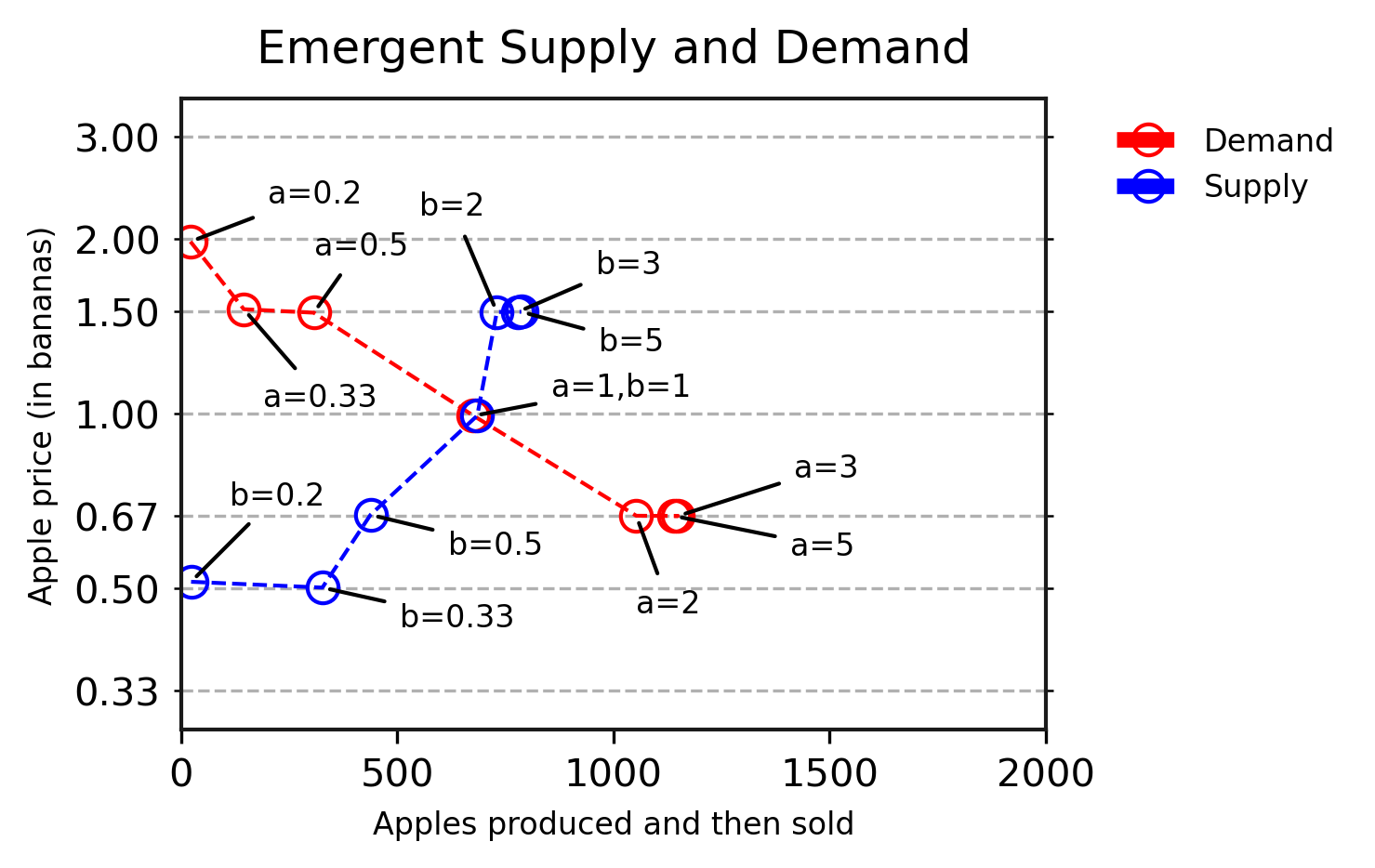
El campo de la economía computacional basada en agentes utiliza simulaciones similares para la investigación en economía. En este trabajo, también demostramos que las técnicas de deep RL de vanguardia pueden aprender de manera flexible a actuar en estos entornos a partir de su propia experiencia, sin necesidad de que se incorpore conocimiento económico. Esto resalta el progreso reciente de la comunidad de aprendizaje por refuerzo en el aprendizaje por refuerzo multiagente y el deep RL, y demuestra el potencial de las técnicas multiagente como herramientas para avanzar en la investigación económica simulada.
Como camino hacia la inteligencia artificial general (AGI), la investigación en aprendizaje por refuerzo multiagente debería abarcar todos los dominios críticos de la inteligencia social. Sin embargo, hasta ahora no ha incorporado fenómenos económicos tradicionales como el comercio, la negociación, la especialización, el consumo y la producción. Este artículo cubre esta brecha y proporciona una plataforma para futuras investigaciones. Para ayudar a la investigación futura en esta área, el entorno de Fruit Market se incluirá en la próxima versión de la suite de entornos Melting Pot.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- En conversación con la IA construyendo mejores modelos de lenguaje
- Mi viaje desde ser pasante de DeepMind hasta mentor
- Maximizando el impacto de nuestros avances
- Cómo nuestros principios ayudaron a definir el lanzamiento de AlphaFold
- Descubriendo algoritmos novedosos con AlphaTensor
- Medición de la percepción en modelos de IA
- Transformación digital con Google Cloud






