Este artículo de Inteligencia Artificial (IA) de Corea del Sur propone FFNeRV una nueva representación de video por cuadros utilizando mapas de flujo por cuadros y cuadrículas temporales de múltiple resolución
El artículo propone FFNeRV, una nueva representación de video utilizando mapas de flujo por cuadros y cuadrículas temporales de múltiple resolución.


La investigación en campos neuronales, que representan señales mediante la asignación de coordenadas a sus cantidades (por ejemplo, escalares o vectores) con redes neuronales, ha explotado recientemente. Esto ha despertado un mayor interés en utilizar esta tecnología para manejar una variedad de señales, incluyendo audio, imagen, forma 3D y video. El teorema de aproximación universal y las técnicas de codificación de coordenadas proporcionan las bases teóricas para una representación precisa de señales en campos cerebrales. Investigaciones recientes han demostrado su adaptabilidad en compresión de datos, modelos generativos, manipulación de señales y representación básica de señales.
La investigación en campos neuronales, que representan señales mediante la asignación de coordenadas a sus cantidades (por ejemplo, escalares o vectores) con redes neuronales, ha explotado recientemente. Esto ha despertado un mayor interés en utilizar esta tecnología para manejar una variedad de señales, incluyendo audio, imagen, forma 3D y video. El teorema de aproximación universal y las técnicas de codificación de coordenadas proporcionan las bases teóricas para una representación precisa de señales en campos cerebrales. Investigaciones recientes han demostrado su adaptabilidad en compresión de datos, modelos generativos, manipulación de señales y representación básica de señales.
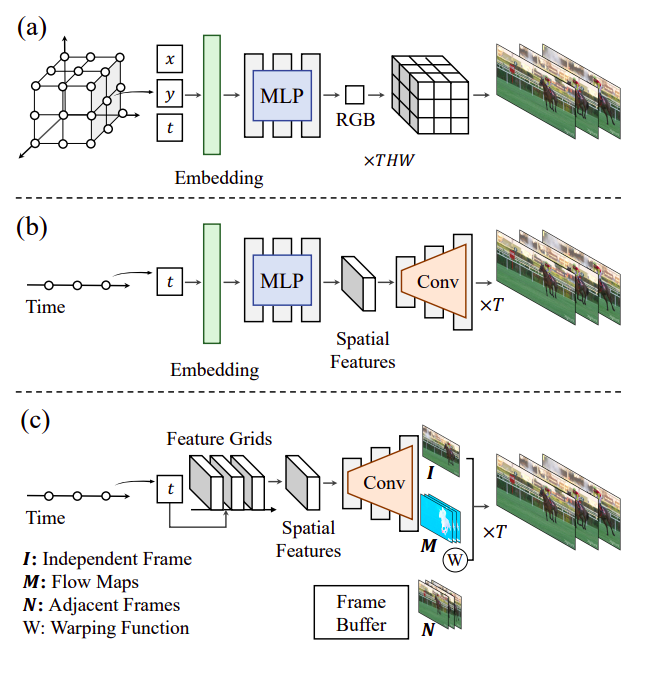
Cada coordenada de tiempo se representa mediante un cuadro de video creado por una pila de capas MLP y convolucionales. En comparación con el diseño básico de campo neuronal, nuestro método reduce considerablemente el tiempo de codificación y supera a las técnicas comunes de compresión de video. Este paradigma es seguido por el recientemente propuesto E-NeRV, al tiempo que mejora la calidad del video. Como se muestra en la Figura 1, ofrecen representaciones neuronales guiadas por flujo para películas (FFNeRV). Insertan flujos ópticos en la representación por cuadros para utilizar la redundancia temporal, inspirándose en los códecs de video comunes. Al combinar cuadros cercanos dirigidos por flujos, FFNeRV crea un cuadro de video que obliga a reutilizar los píxeles de los cuadros anteriores. Alentar a la red a evitar recordar los mismos valores de píxeles en cuadros sucesivos mejora drásticamente la eficiencia de los parámetros.
- Conoce a Rodin un nuevo marco de inteligencia artificial (IA) para generar avatares digitales en 3D a partir de diversas fuentes de entrada.
- Los creativos están luchando contra la inteligencia artificial con demandas legales
- Potenciando la IA en Dispositivos Qualcomm y Meta colaboran con la tecnología Llama 2
FFNeRV supera a los algoritmos alternativos por cuadros en compresión de video e interpolación de cuadros, según los resultados experimentales en el conjunto de datos UVG. Sugieren utilizar rejillas temporales de múltiples resoluciones con una resolución espacial fija en lugar de MLP para asignar coordenadas temporales continuas a características latentes correspondientes, para mejorar aún más el rendimiento de compresión. Esto está motivado por las representaciones neuronales basadas en rejillas. Además, sugieren utilizar una arquitectura convolucional más condensada. Utilizan convoluciones grupales y puntuales en las representaciones recomendadas de flujo por cuadros, impulsadas por modelos generativos que producen imágenes de alta calidad y redes neuronales livianas. FFNeRV supera a los códecs de video populares (H.264 y HEVC) y tiene un rendimiento comparable a los algoritmos de compresión de video de vanguardia utilizando entrenamiento consciente de cuantización y codificación de entropía. La implementación del código se basa en NeRV y está disponible en GitHub.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Microsoft lanza TypeChat una biblioteca de IA que facilita la creación de interfaces de lenguaje natural utilizando tipos.
- Las GPUs NVIDIA H100 ahora están disponibles en la nube de AWS
- El futuro de la guerra totalmente autónoma impulsado por IA está aquí
- Construye una estrategia exitosa de lanzamiento de productos con ChatGPT
- ¿Dónde están todas las mujeres?
- Investigadores de UBC Canadá presentan un nuevo algoritmo de IA que mapea las rutas más seguras para los conductores en la ciudad
- Cómo navegar por el actual mercado laboral de la ciencia de datos