Dominando Stratego, el clásico juego de información imperfecta
'Dominating Stratego, the classic game of imperfect information'
DeepNash aprende a jugar Stratego desde cero combinando teoría de juegos y aprendizaje profundo de refuerzo sin modelo
Los sistemas de inteligencia artificial (IA) para jugar juegos han avanzado hacia una nueva frontera. Stratego, el clásico juego de mesa más complejo que el ajedrez y Go, y más astuto que el póker, ha sido dominado. Publicado en la revista Science, presentamos a DeepNash, un agente de IA que aprendió el juego desde cero hasta alcanzar el nivel de experto humano jugando contra sí mismo.
DeepNash utiliza un enfoque novedoso basado en teoría de juegos y aprendizaje profundo de refuerzo sin modelo. Su estilo de juego converge hacia un equilibrio de Nash, lo que significa que su juego es muy difícil de explotar por un oponente. De hecho, DeepNash ha alcanzado el ranking de los tres mejores jugadores de todos los tiempos entre expertos humanos en la plataforma de Stratego en línea más grande del mundo, Gravon.
Los juegos de mesa han sido históricamente una medida del progreso en el campo de la IA, permitiéndonos estudiar cómo los humanos y las máquinas desarrollan y ejecutan estrategias en un entorno controlado. A diferencia del ajedrez y Go, Stratego es un juego de información imperfecta: los jugadores no pueden observar directamente las identidades de las piezas de su oponente.
Esta complejidad ha significado que otros sistemas de IA basados en Stratego han tenido dificultades para superar el nivel amateur. También significa que una técnica de IA muy exitosa llamada “búsqueda del árbol de juego”, utilizada previamente para dominar muchos juegos de información perfecta, no es lo suficientemente escalable para Stratego. Por esta razón, DeepNash va mucho más allá de la búsqueda del árbol de juego en su totalidad.
- AI para el juego de mesa Diplomacy
- Programación competitiva con AlphaCode
- ¿Cómo podemos incorporar valores humanos en la IA?
El valor de dominar Stratego va más allá del juego. En busca de nuestra misión de resolver la inteligencia para avanzar en la ciencia y beneficiar a la humanidad, necesitamos construir sistemas avanzados de IA que puedan operar en situaciones complejas del mundo real con información limitada sobre otros agentes y personas. Nuestro artículo muestra cómo DeepNash puede aplicarse en situaciones de incertidumbre y equilibrar con éxito los resultados para ayudar a resolver problemas complejos.
Conociendo a Stratego
Stratego es un juego por turnos para capturar la bandera. Es un juego de bluff y tácticas, de recolección de información y maniobras sutiles. Y es un juego de suma cero, por lo que cualquier ganancia de un jugador representa una pérdida de la misma magnitud para su oponente.
Stratego es desafiante para la IA, en parte, porque es un juego de información imperfecta. Ambos jugadores comienzan organizando sus 40 piezas de juego en la formación inicial que prefieran, inicialmente ocultas entre sí al comenzar el juego. Dado que ambos jugadores no tienen acceso al mismo conocimiento, necesitan equilibrar todos los resultados posibles al tomar una decisión, lo que proporciona un desafío para estudiar interacciones estratégicas. Los tipos de piezas y sus clasificaciones se muestran a continuación.

La información en Stratego se gana con dificultad. La identidad de una pieza del oponente se revela típicamente solo cuando se encuentra con el otro jugador en el campo de batalla. Esto contrasta fuertemente con los juegos de información perfecta como el ajedrez o Go, en los que la ubicación e identidad de cada pieza es conocida por ambos jugadores.
Los enfoques de aprendizaje automático que funcionan tan bien en juegos de información perfecta, como AlphaZero de DeepMind, no se transfieren fácilmente a Stratego. La necesidad de tomar decisiones con información imperfecta y la posibilidad de bluff hacen que Stratego se asemeje más al póker Texas hold’em y requiere una capacidad similar a la humana, como señaló una vez el escritor estadounidense Jack London: “La vida no siempre es cuestión de tener buenas cartas, sino a veces, jugar bien una mala mano”.
Las técnicas de inteligencia artificial que funcionan tan bien en juegos como el Texas hold’em no se transfieren a Stratego, sin embargo, debido a la gran duración del juego, a menudo cientos de movimientos antes de que un jugador gane. El razonamiento en Stratego debe hacerse sobre un gran número de acciones secuenciales sin una visión clara de cómo cada acción contribuye al resultado final.
Finalmente, el número de posibles estados del juego (expresado como “complejidad del árbol de juego”) está fuera de escala en comparación con el ajedrez, Go y el póker, lo que lo hace increíblemente difícil de resolver. Esto es lo que nos emociona de Stratego y por qué ha representado un desafío de décadas para la comunidad de inteligencia artificial.
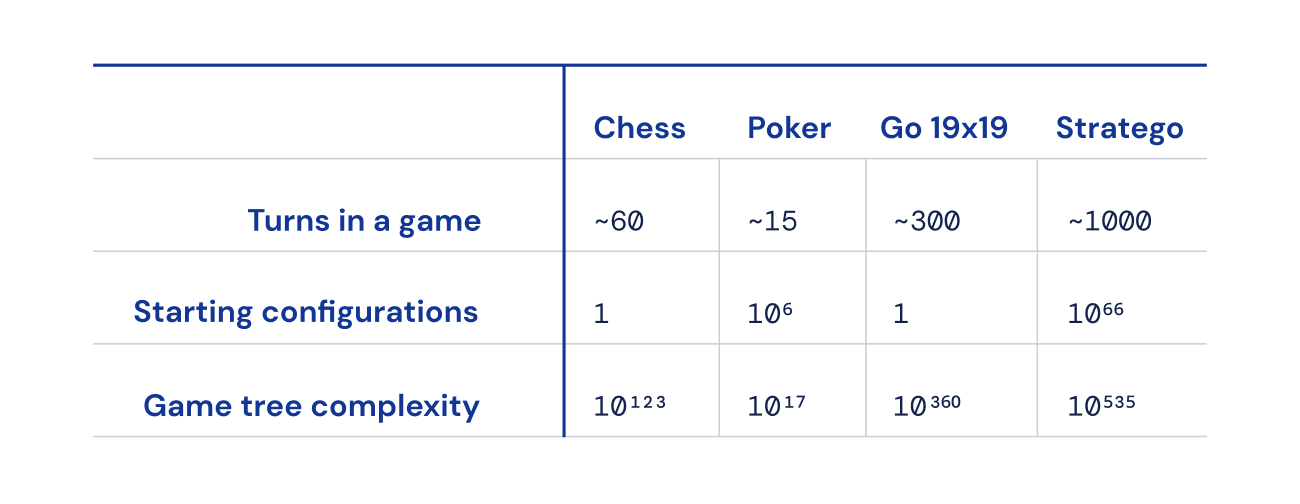
Buscando un equilibrio
DeepNash utiliza un enfoque novedoso basado en una combinación de teoría de juegos y aprendizaje por refuerzo profundo sin modelos. “Sin modelos” significa que DeepNash no intenta modelar explícitamente el estado de juego privado de su oponente durante el juego. Especialmente en las primeras etapas del juego, cuando DeepNash sabe poco sobre las piezas de su oponente, ese modelado sería inefectivo, si no imposible.
Y debido a la vasta complejidad del árbol de juego de Stratego, DeepNash no puede utilizar un enfoque firme basado en la búsqueda de árbol de Monte Carlo, que ha sido un ingrediente clave en muchos logros importantes en inteligencia artificial para juegos de mesa menos complejos, como el ajedrez y el póker.
En cambio, DeepNash se basa en una nueva idea algorítmica de teoría de juegos que llamamos Dinámica Nash Regularizada (R-NaD). Trabajando a una escala sin precedentes, R-NaD dirige el comportamiento de aprendizaje de DeepNash hacia lo que se conoce como un equilibrio de Nash (profundice en los detalles técnicos en nuestro artículo).
El comportamiento de juego que resulta en un equilibrio de Nash es inexplorable con el tiempo. Si una persona o una máquina jugara de manera perfectamente inexplorable en Stratego, la peor tasa de victorias que podrían lograr sería del 50%, y solo si se enfrentaran a un oponente igualmente perfecto.
En las partidas contra los mejores bots de Stratego, incluyendo varios ganadores del Campeonato Mundial de Stratego de Computadoras, la tasa de victorias de DeepNash superó el 97%, y frecuentemente alcanzó el 100%. Contra los mejores jugadores humanos expertos en la plataforma de juegos Gravon, DeepNash logró una tasa de victorias del 84%, lo que le valió un puesto entre los tres primeros de todos los tiempos.
Esperar lo inesperado
Para lograr estos resultados, DeepNash demostró algunos comportamientos notables tanto durante su fase inicial de despliegue de piezas como en la fase de juego. Para ser difícil de explotar, DeepNash desarrolló una estrategia impredecible. Esto significa crear despliegues iniciales lo suficientemente variados como para evitar que su oponente detecte patrones a lo largo de una serie de juegos. Y durante la fase de juego, DeepNash se aleatoriza entre acciones aparentemente equivalentes para evitar tendencias explotables.
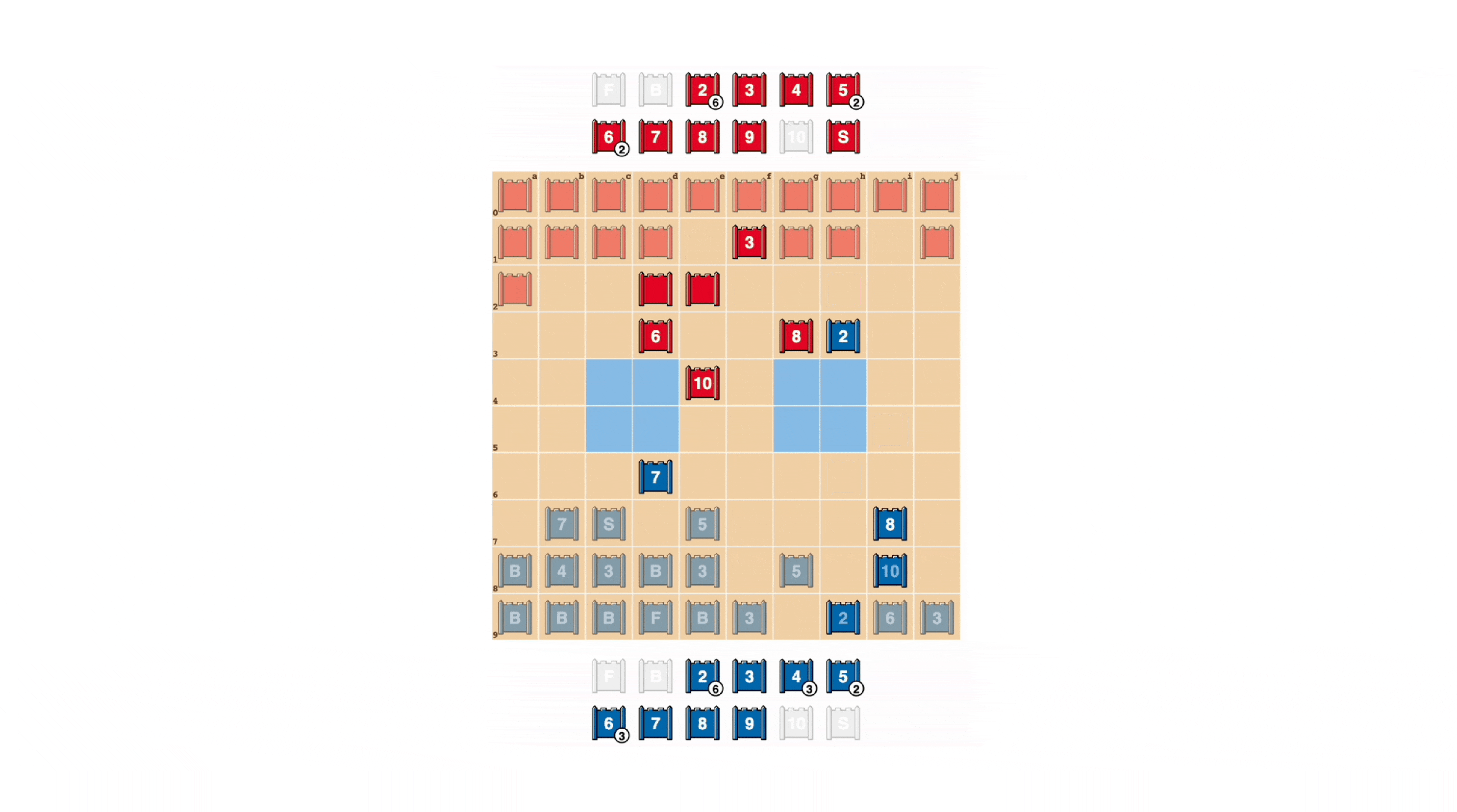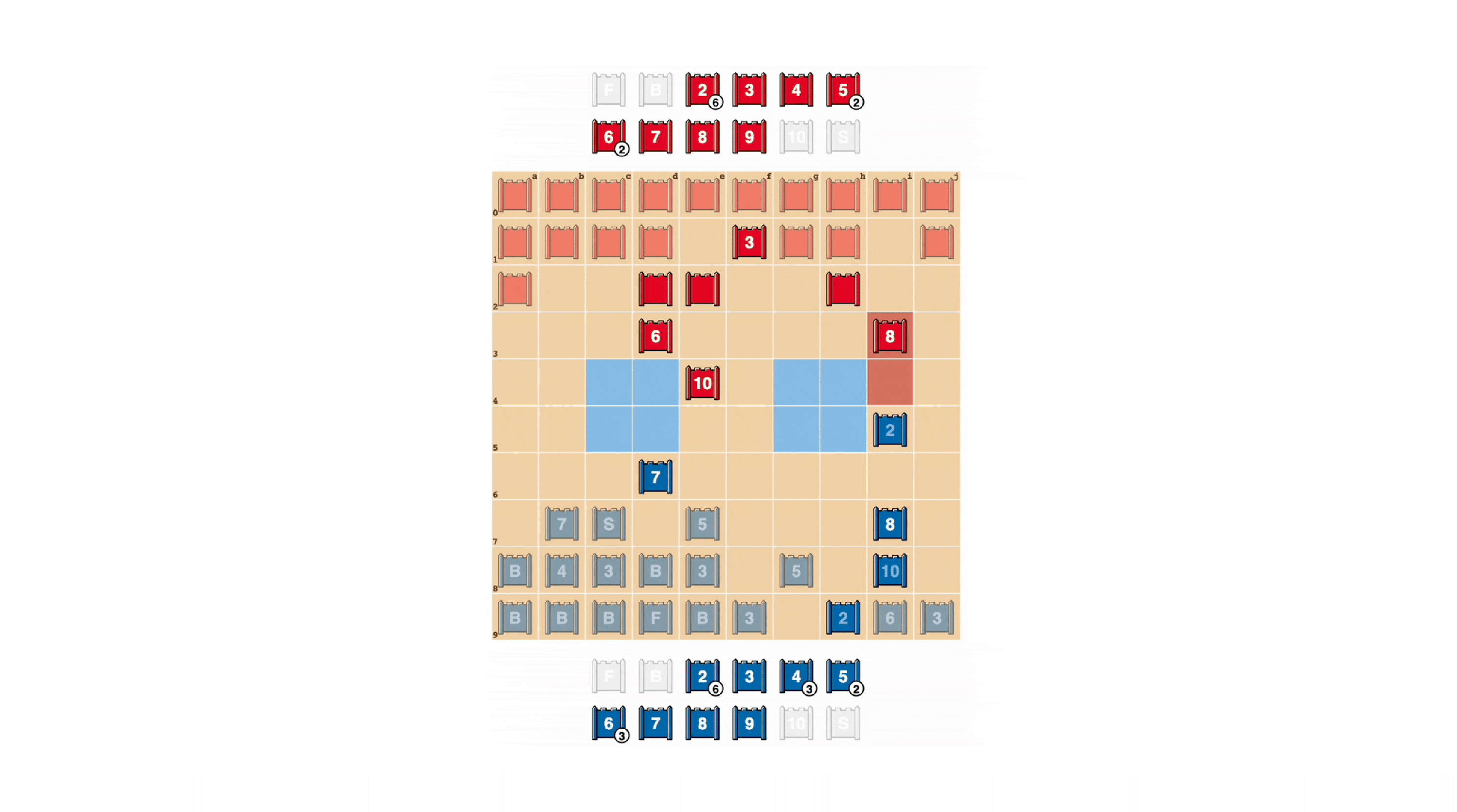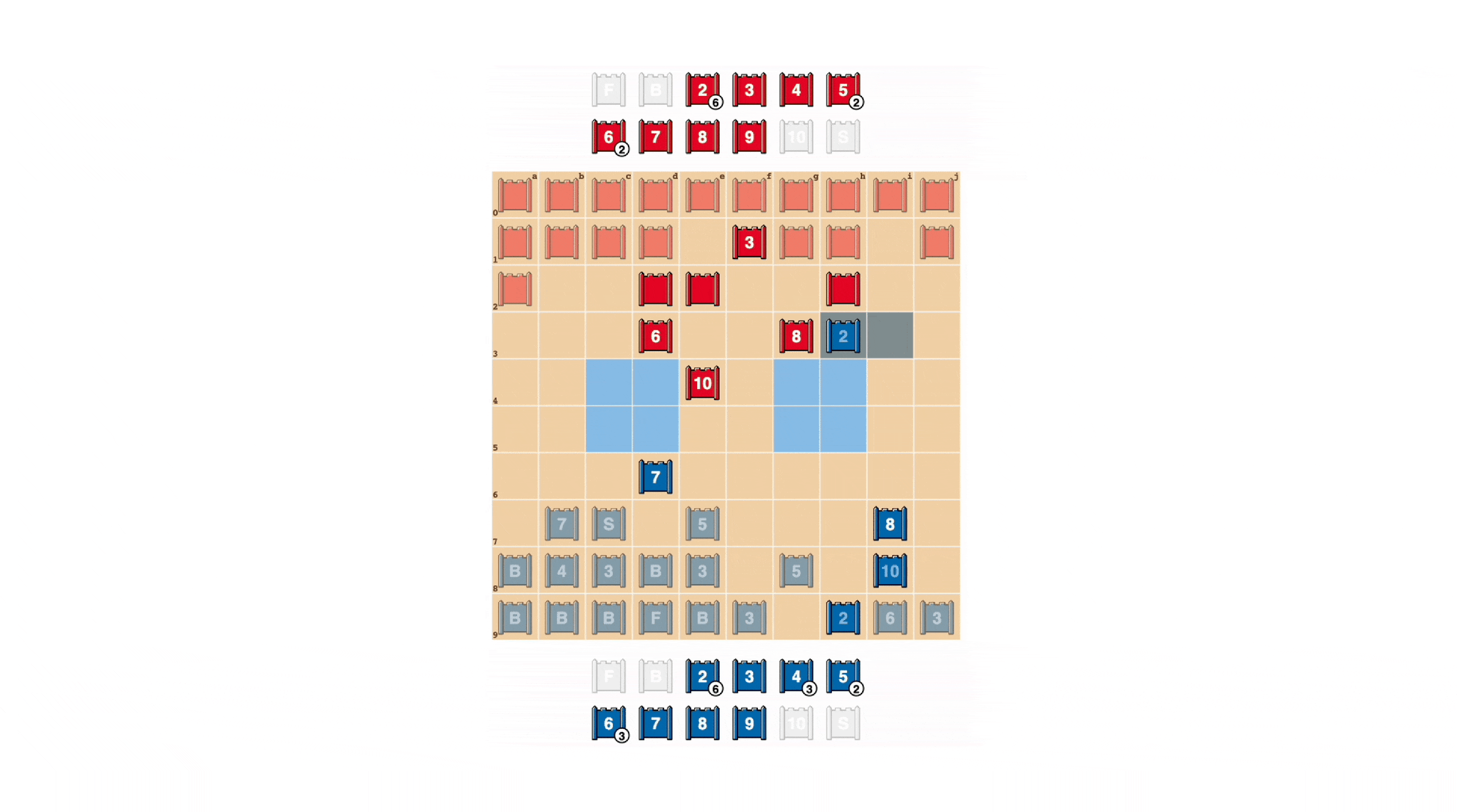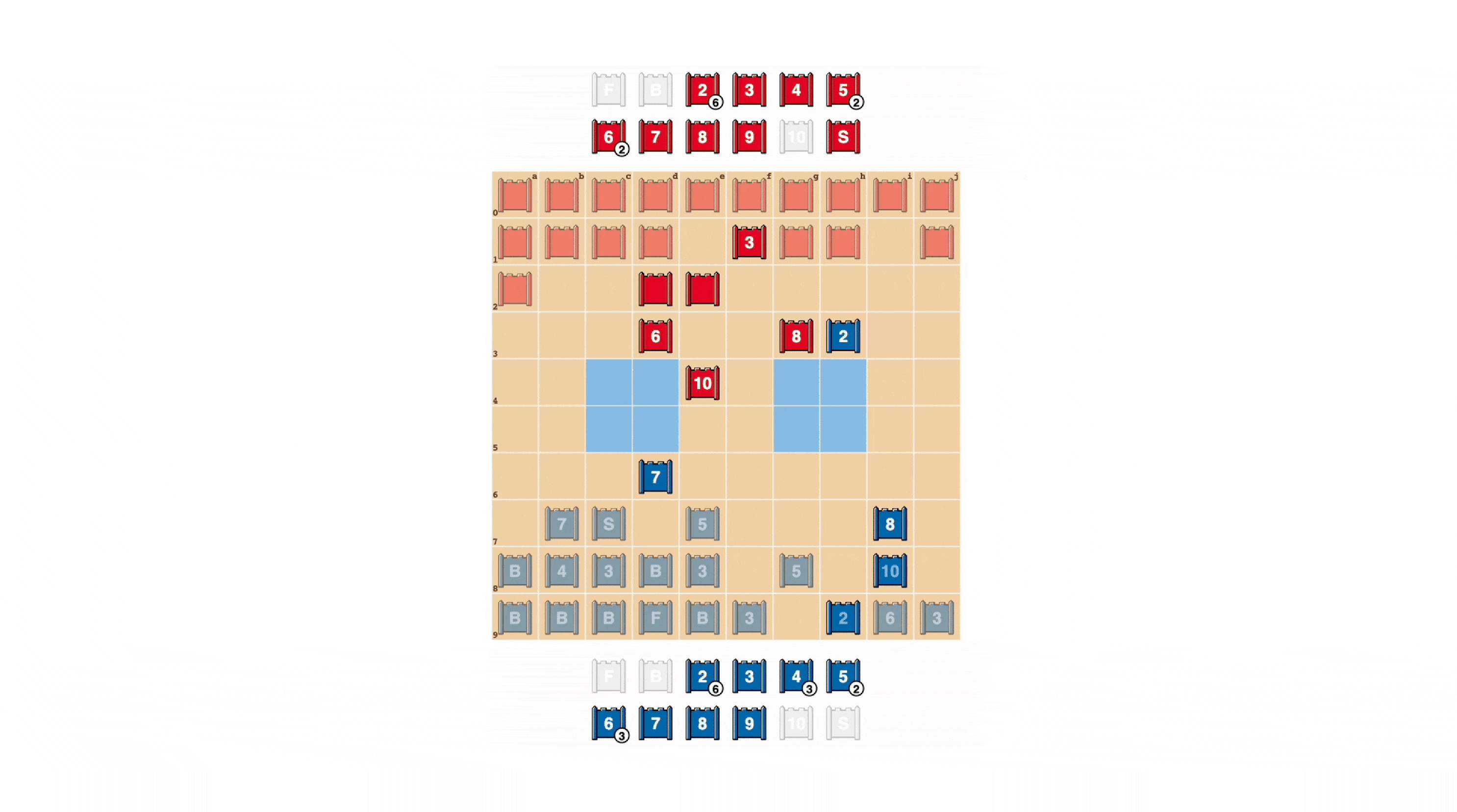
Los jugadores de Stratego se esfuerzan por ser impredecibles, por lo que hay valor en mantener la información oculta. DeepNash demuestra cómo valora la información de manera bastante sorprendente. En el ejemplo a continuación, contra un jugador humano, DeepNash (azul) sacrificó, entre otras piezas, un 7 (Mayor) y un 8 (Coronel) al comienzo del juego y como resultado fue capaz de localizar el 10 (Mariscal), el 9 (General), un 8 y dos 7 de su oponente.
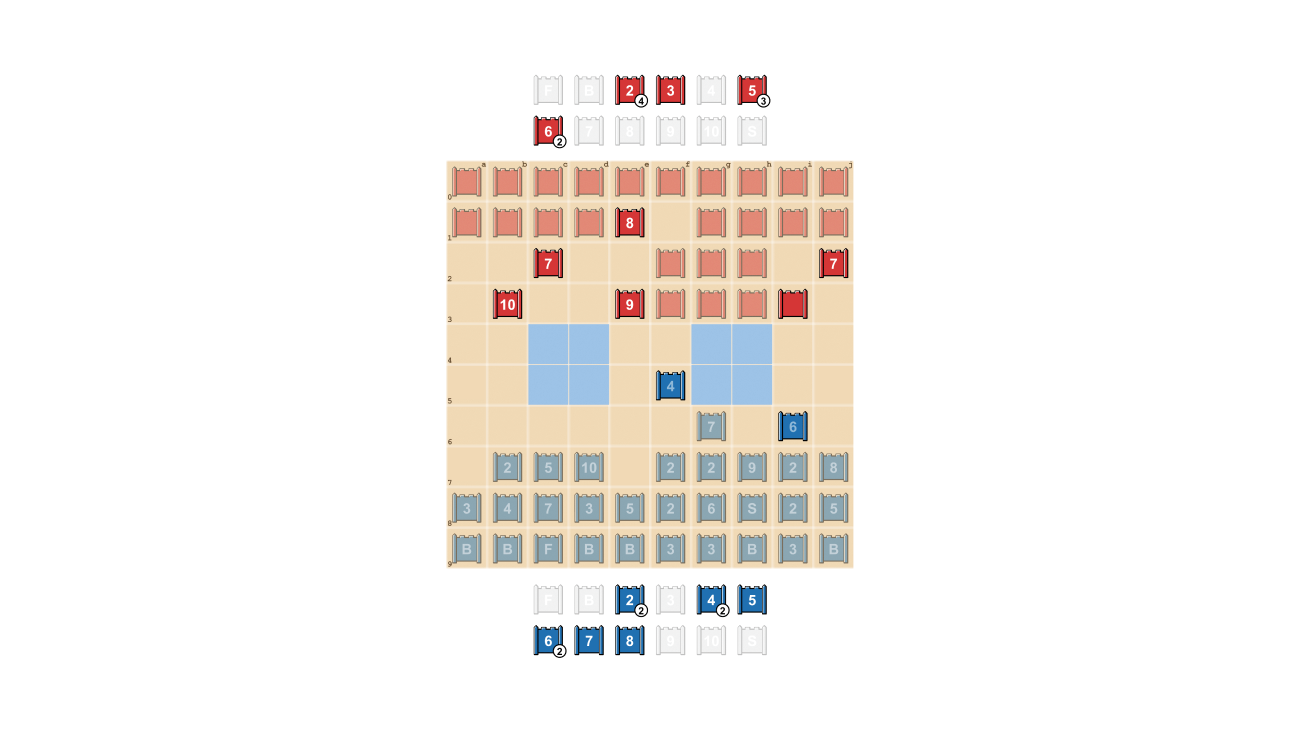
Estos esfuerzos dejaron a DeepNash en una desventaja material significativa; perdió un 7 y un 8 mientras que su oponente humano preservó todas sus piezas clasificadas con 7 o más. Sin embargo, teniendo información sólida sobre los principales miembros de su oponente, DeepNash evaluó sus posibilidades de ganar en un 70% y ganó.
El arte del engaño
Al igual que en el póker, un buen jugador de Stratego a veces debe representar fuerza, incluso cuando es débil. DeepNash aprendió una variedad de tácticas de engaño. En el siguiente ejemplo, DeepNash utiliza un 2 (un Scout débil, desconocido para su oponente) como si fuera una pieza de alto rango, persiguiendo el conocido 8 de su oponente. El oponente humano decide que el perseguidor es muy probablemente un 10, y por lo tanto intenta atraerlo hacia una emboscada con su Espía. Esta táctica de DeepNash, arriesgando solo una pieza menor, tiene éxito al descubrir y eliminar el Espía de su oponente, una pieza crítica.
Mira más viendo estos cuatro videos de juegos completos jugados por DeepNash contra expertos humanos (anonimizados): Juego 1 , Juego 2 , Juego 3 , Juego 4.
“El nivel de juego de DeepNash me sorprendió. Nunca había oído hablar de un jugador artificial de Stratego que se acercara al nivel necesario para ganar una partida contra un jugador humano experimentado. Pero después de jugar contra DeepNash yo mismo, no me sorprendió que alcanzara el tercer puesto en la plataforma Gravon. Espero que le vaya muy bien si se le permite participar en los Campeonatos Mundiales de humanos.” – Vincent de Boer, coautor del documento y ex Campeón Mundial de Stratego
Direcciones futuras
Aunque desarrollamos DeepNash para el mundo altamente definido de Stratego, nuestro novedoso método R-NaD se puede aplicar directamente a otros juegos de suma cero de dos jugadores, tanto de información perfecta como imperfecta. R-NaD tiene el potencial de generalizarse mucho más allá de los entornos de juego de dos jugadores para abordar problemas del mundo real a gran escala, que a menudo se caracterizan por información imperfecta y espacios de estado astronómicos.
También esperamos que R-NaD pueda ayudar a desbloquear nuevas aplicaciones de IA en dominios que cuentan con un gran número de participantes humanos o de IA con diferentes objetivos y que pueden no tener información sobre las intenciones de los demás o lo que está ocurriendo en su entorno, como en la optimización a gran escala de la gestión del tráfico para reducir los tiempos de viaje de los conductores y las emisiones de los vehículos asociadas.
Al crear un sistema de IA generalizable que sea robusto frente a la incertidumbre, esperamos llevar las capacidades de resolución de problemas de la IA aún más lejos en nuestro mundo inherentemente impredecible.
Obtén más información sobre DeepNash leyendo nuestro artículo en Science .
Para los investigadores interesados en probar R-NaD o trabajar con nuestro método recién propuesto, hemos puesto nuestro código a disposición en código abierto .
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- La última investigación de DeepMind en ICLR 2023
- Conoce DragonDiffusion un método de edición de imágenes de granulación fina que permite la manipulación estilo arrastrar en modelos de difusión.
- ¿Qué tan arriesgado es tu proyecto de LLM de código abierto? Una nueva investigación explica los factores de riesgo asociados con los LLM de código abierto.
- AI Ayuda al Gobierno en Prohibir las Conexiones Móviles Falsas
- OpenAI presenta Super Alignment Abriendo el camino para una IA segura y alineada
- Conoce a KITE Un marco de inteligencia artificial para la manipulación semántica utilizando puntos clave como representación para el enlace visual y la inferencia precisa de acciones.
- El costo oculto de los problemas de calidad de datos en el retorno de la inversión publicitaria.






